强化学习概览
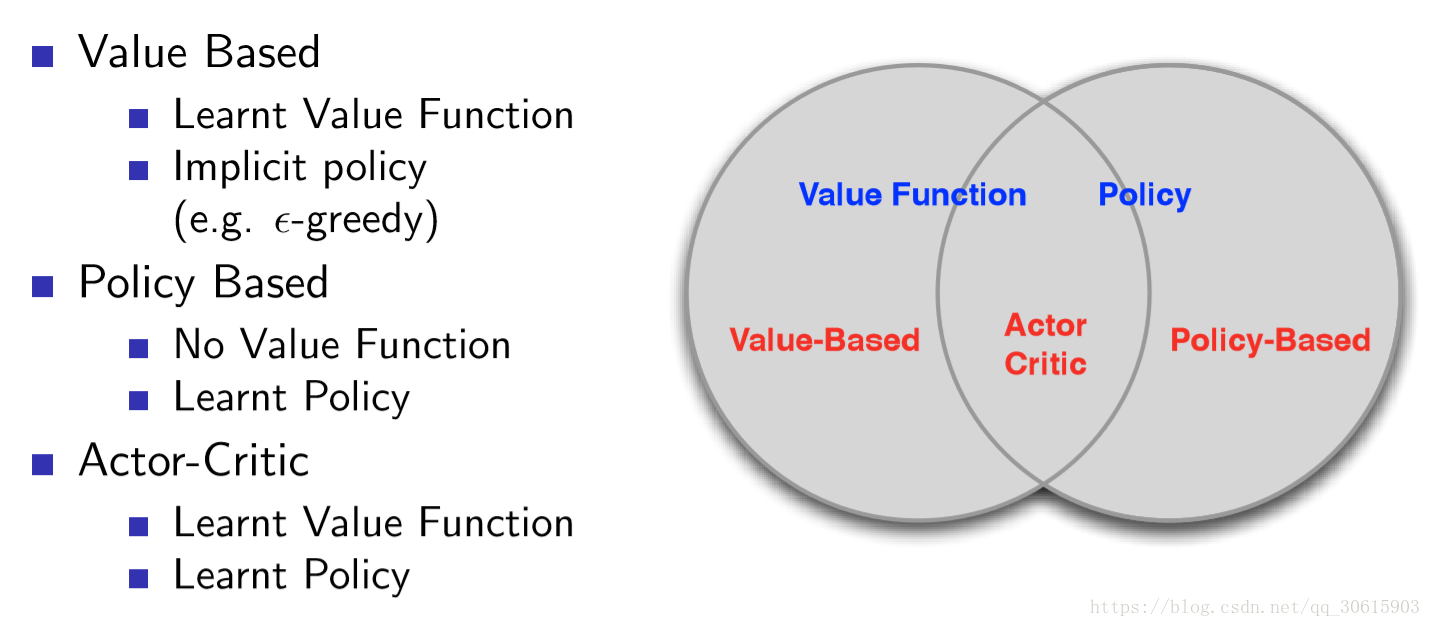
RL分类: value based, policy based, actor critic.
一、value based.
Q-learning
Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作。
更新公式 Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)], alpha 是学习率, \gamma 是衰减函数
Q learning 是一个off-policy 的RL 算法.
Sarsa: on-policy 算法
更新公式: Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*Q(S',a’)],
区别:Sarsa是保守的策略, Q-learning 是大胆,全局最优的策略
Deep Q network (DQN)
将 reward 值用neural network 来学习,而非用table 的方式存储。 输入为state, action, 输出为action value. 或者输入为state, 输出为action value.
experimence replay
target network
二、 policy based.
policy gredient:
Policy \pi可以看做是一个参数为\Theta的神经网络,以打游戏的例子来说,输入当前的状态(图像),输出可能的action的概率分布,选择概率最大的一个action作为要执行的操作。不同过reward 值选择action, 而是直接输出action.
Policy Gradient不通过误差反向传播,它通过观测信息选出一个行为直接进行反向传播,利用reward奖励直接对选择行为的可能性进行增强和减弱,好的行为会被增加下一次被选中的概率,不好的行为会被减弱下次被选中的概率。
policy gredient中强化学习的目标就是学习一个Policy,即一个网络,使其每看到一个画面,做出一个action, 并做到最终获得最大总reward。
三、actor critic.
actor: policy gredient
critic: Q-learning
训练两个不同的神经网络
参考链接:
RL 很好的资源:https://medium.com/@awjuliani/super-simple-reinforcement-learning-tutorial-part-1-fd544fab149
Q-learning
https://www.zhihu.com/question/26408259/answer/123230350
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
Sarsa
https://blog.csdn.net/qq_39004117/article/details/81705845
Deep Q network:
https://blog.csdn.net/qq_32690999/article/details/79302093
https://blog.csdn.net/qq_30615903/article/details/80744083
Policy gradient:
https://www.jianshu.com/p/e9d47bb2dab2?utm_source=oschina-app
https://blog.csdn.net/qq_30615903/article/details/80747380\
Actor critic:
https://blog.csdn.net/qq_30615903/article/details/80774384
https://www.jianshu.com/p/8750b3fb5d07

 浙公网安备 33010602011771号
浙公网安备 33010602011771号