BM25
BM25的作用
- BM25:best matching
- 在检索中,经常需要计算query与文本的相关性,而BM25就是这样一种算法,它是TF-IDF算法的延申
BM25的计算过程
- 针对一个query\(Q\),切词后包含\(q_1\),...,\(q_n\),query与某个文档\(D\)的BM25分数为:
\[score(D,Q) =\sum_{i=1}^n{IDF(q_i)}\frac{f(q_i,D)*(k_1+1)}{f(q_i,D)+k_1(1-b+b* \frac{|D|}{avgdl})}
\]
其中:
\({f(q_i,D)}\)表示单词\(q_i\)在文档\(D\)中的词频;
\(D\)表示文档\(D\)中单词数,即文档长度;
\(avgdl\)表示语料库中文档的平均长度;
\(k_1\)和\(b\)是两个参数,用于优化,\(k_1\in[1.2,2.0]\),\(b=0.75\)
\(IDF(q_i)=ln(\frac{N-n(q_i)+0.5}{n(q_i)+0.5})+1\)
BM25的原理分析
- BM25的计算包含两部分,一部分是IDF的计算,另一部分是TF的计算(类似IF-IDF,只是细节不同,考虑更全面,计算过程更加精细化)
TF的计算
- 传统的TF计算:\(tf_{score} = sqrt(tf)\)
- BM25的TF计算:\(tf_{score} = \frac{(k_1+1)*tf}{k+tf}\)
- \(K=k_1(1-b+b*\frac{|D|}{avgdl})\)
- 传统的TF理论值无限大;BM25在TF的计算中增加了一个常量\(k_1\)和\(K\),用来限制TF值的增长极限,BM25TF值的范围会控制在[0,k1+1],如下图
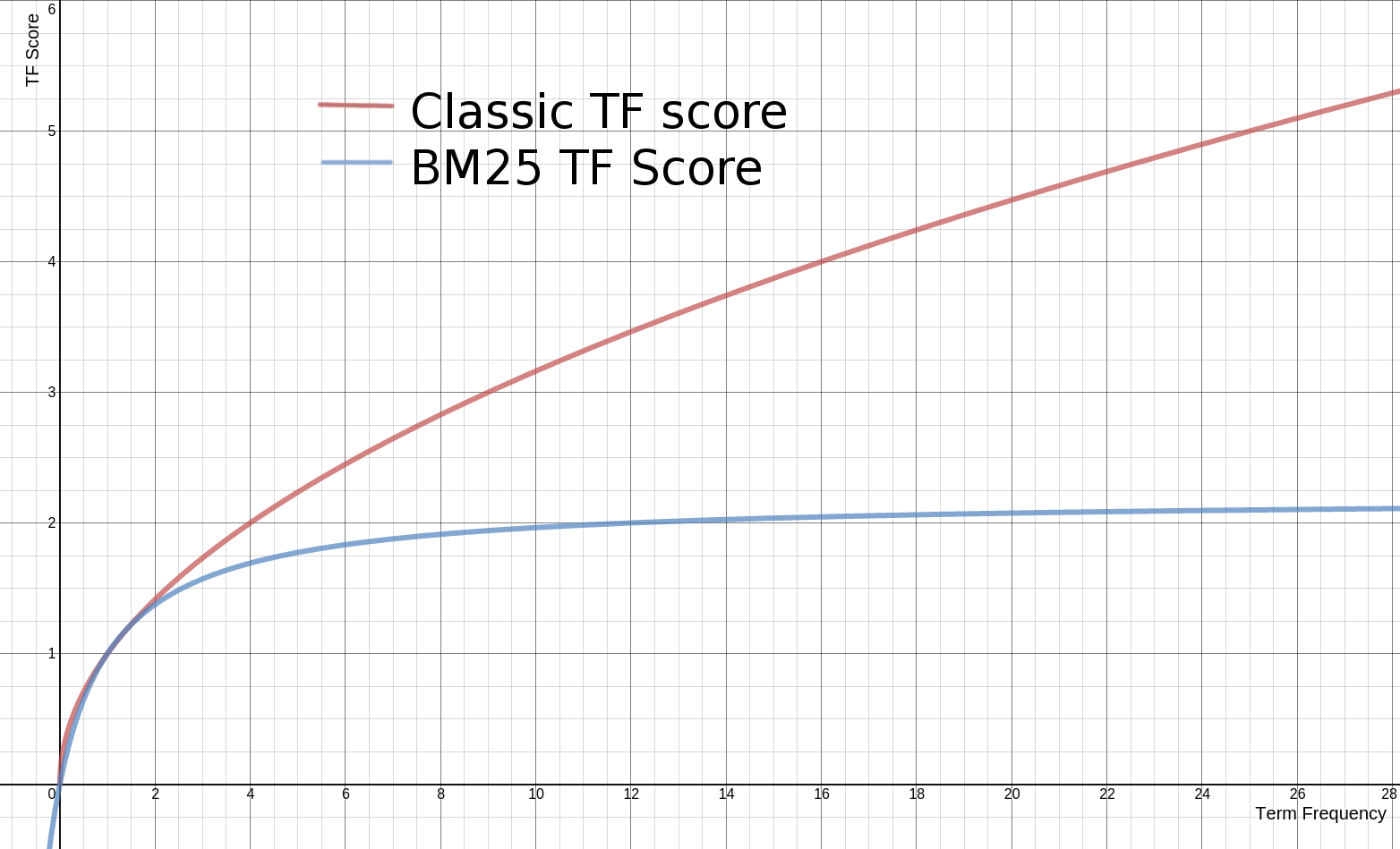
- 计算K的公式中\(k1\)和\(b\)是调节因子。\(k1\)是词频饱和度:通俗解释就是当多篇文章中某个词出现次数>某个阈值的时候,认为这几篇文章的重要性是一样的, 但是传统的TF并没有考虑这种情况,这是简单的认为某个词出现次数越多,相关性越大,TF值也就越大;而\(b\)用于控制文章长度对TF得分的影响,b值越大,L值对得分的影响越大(如果某个词语在短文档和长文档中的传统tf值一样,理论上短文章的相关度应该更高些,因此可以适当设置\(b\)的值小些,TF得分和文档长度的关系如下图)

IDF的计算
\[IDF(q_i)=ln(\frac{N-n(q_i)+0.5}{n(q_i)+0.5})+1=ln(\frac{N+1}{n(q_i)+0.5})
\]
其中:\(N\)是文档总数;\(n(q_i)\)是包含\({q_i}\)的文档数;
- 传统IDF和BM25 IDF的比较,从图中看,走势基本一致(不知道为何和传统IDF计算有区别,应该是调参吧)

BM25 VS TF-IDF
- BM25是在传统的TF-IDF的基础上添加了几个调节的参数,使得它在应用上更加灵活,具有较高的实用性
参考文档
- https://www.jianshu.com/p/1e498888f505
- https://zhuanlan.zhihu.com/p/79202151
- https://www.cnblogs.com/NaughtyBaby/p/9774836.html
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/pluggable-similarites.html#img-bm25-saturation
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://my.oschina.net/stanleysun/blog/1617727
- https://www.lishaowei.cn/1122.html
- http://qianjiasong.com/post/nlp-tf-idf-bm25/
