集合 ListIterator 双向链表
目录
LinkedList 源码解析
LinkedList 适用于集合元素先入先出和先入后出的场景,在队列源码中被频繁使用。
LinkedList 适用于要求有顺序、并且会按照顺序进行迭代的场景,主要是依赖于底层的链表结构。
LinkedList 底层数据结构是一个双向链表,整体结构如下图所示:
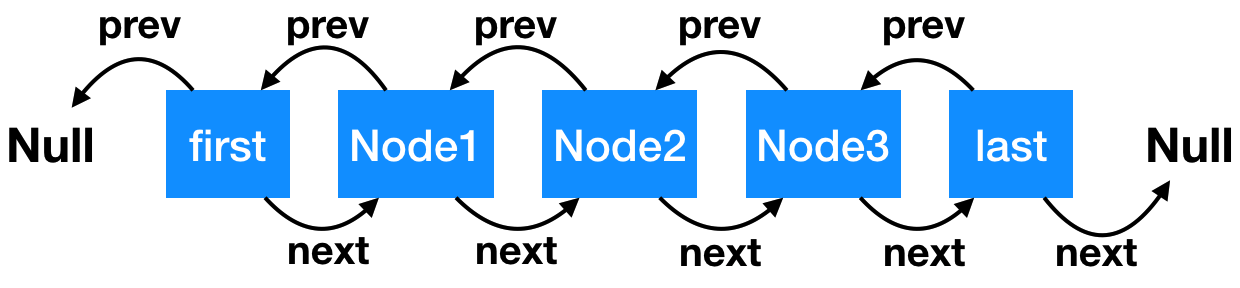
上图代表了一个双向链表结构,链表中的每个节点都可以向前或者向后追溯,我们有几个概念如下:
- 链表每个节点我们叫做 Node,Node 有 prev 属性,代表前一个节点的位置,next 属性,代表后一个节点的位置;
- first 是双向链表的
头节点,它的前一个节点是 null - last 是双向链表的
尾节点,它的后一个节点是 null - 当链表中没有数据时,first 和 last 是同一个节点,前后指向都是 null
- 因为是个双向链表,只要机器内存足够强大,是没有大小限制的
Node
链表中的元素叫做 Node,我们看下 Node 的组成部分:
private static class Node<E> {
E item;// 节点值
Node<E> next; // 指向的下一个节点
Node<E> prev; // 指向的前一个节点
// 初始化参数顺序分别是:前一个节点、本身节点值、后一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
追加 add/offer
追加节点时,我们可以选择追加到链表头部,还是追加到链表尾部,add 方法默认是从尾部开始追加,addFirst 方法是从头部开始追加,我们分别来看下两种不同的追加方式:
从尾部追加
public boolean add(E e) {
linkLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
// 从尾部开始追加节点
void linkLast(E e) {
final Node<E> l = last; // 把尾节点数据暂存
// 新建新的节点,初始化入参含义:
// l 是新节点的前一个节点,当前值是尾节点值
// e 表示当前新增节点,当前新增节点后一个节点是 null
final Node<E> newNode = new Node<>(l, e, null);
last = newNode; // 新建节点追加到尾部
//如果链表为空(l 是尾节点,尾节点为空,链表即空),头部和尾部是同一个节点,都是新建的节点
if (l == null) first = newNode;
//否则把前尾节点的下一个节点,指向当前尾节点
else l.next = newNode;
//大小和版本更改
size++;
modCount++;
}
从源码上来看,尾部追加节点比较简单,只需要简单地把指向位置修改下即可。
从头部追加
// 从头部追加
private void linkFirst(E e) {
final Node<E> f = first; // 头节点赋值给临时变量
// 新建节点,前一个节点指向null,e 是新建节点,f 是新建节点的下一个节点,目前值是头节点的值
final Node<E> newNode = new Node<>(null, e, f);
// 新建节点成为头节点
first = newNode;
// 头节点为空,就是链表为空,头尾节点是一个节点
if (f == null) last = newNode;
//上一个头节点的前一个节点指向当前节点
else f.prev = newNode;
size++;
modCount++;
}
头部追加节点和尾部追加节点非常类似,只是前者是移动头节点的 prev 指向,后者是移动尾节点的 next 指向。
删除 remove/poll
节点删除的方式和追加类似,我们可以选择从头部删除,也可以选择从尾部删除,删除操作会把节点的值,前后指向节点都置为 null,帮助 GC 进行回收。
从头部删除
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null) throw new NoSuchElementException();
return unlinkFirst(f);
}
//从头删除节点 f 是链表头节点
private E unlinkFirst(Node<E> f) {
final E element = f.item; // 拿出头节点的值,作为方法的返回值
final Node<E> next = f.next; // 拿出头节点的下一个节点
//帮助 GC 回收头节点
f.item = null;
f.next = null;
first = next; // 头节点的下一个节点成为头节点
//如果 next 为空,表明链表为空
if (next == null) last = null;
//链表不为空,头节点的前一个节点指向 null
else next.prev = null;
//修改链表大小和版本
size--;
modCount++;
return element;
}
从尾部删除节点代码也是类似的,就不贴了。
从源码中我们可以了解到,链表结构的节点新增、删除都非常简单,仅仅把前后节点的指向修改下就好了,所以 LinkedList 新增和删除速度很快。
查询 get
链表查询某一个节点是比较慢的,需要挨个循环查找才行,我们看看 LinkedList 的源码是如何寻找节点的:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 根据链表索引位置查询节点
Node<E> node(int index) {
// 如果 index 处于队列的前半部分,从头开始找,size >> 1 是 size 除以 2 的意思。
if (index < (size >> 1)) {
Node<E> x = first;
// 直到 for 循环到 index 的前一个 node 停止
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {// 如果 index 处于队列的后半部分,从尾开始找
Node<E> x = last;
// 直到 for 循环到 index 的后一个 node 停止
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
从源码中我们可以发现,LinkedList 并没有采用从头循环到尾的做法,而是采取了简单二分法,首先看看 index 是在链表的前半部分,还是后半部分。如果是前半部分,就从头开始寻找,反之亦然。通过这种方式,使循环的次数至少降低了一半,提高了查找的性能,这种思想值得我们借鉴。
方法对比
LinkedList 实现了 Queue 接口,在新增、删除、查询等方面增加了很多新的方法,这些方法在平时特别容易混淆,在链表为空的情况下,返回值也不太一样,我们列一个表格,方便大家记录:
| 方法含义 | 返回异常 | 返回特殊值 | 底层实现 |
|---|---|---|---|
| 新增 | add(e) | offer(e) | 底层实现相同 |
| 删除 | remove() | poll(e) | 链表为空时,remove 会抛出异常,poll 返回 null |
| 查找 | element() | peek() | 链表为空时,element 会抛出异常,peek 返回 null |
PS:Queue 接口注释建议 add 方法操作失败时抛出异常,但 LinkedList 实现的 add 方法一直返回 true。
LinkedList 也实现了 Deque 接口,对新增、删除和查找都提供从头开始,还是从尾开始两种方向的方法,比如 remove 方法,Deque 提供了 removeFirst 和 removeLast 两种方向的使用方式,但当链表为空时的表现都和 remove 方法一样,都会抛出异常。
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
public interface Deque<E> extends Queue<E>
public interface Queue<E> extends Collection<E>
迭代器 ListIterator
因为 LinkedList 要实现双向的迭代访问,所以我们使用 Iterator 接口肯定不行了,因为 Iterator 只支持从头到尾的访问。Java 新增了一个迭代接口,叫做:ListIterator,这个接口提供了向前和向后的迭代方法,如下所示:
| 迭代顺序 | 方法 |
|---|---|
| 从尾到头迭代方法 | hasPrevious、previous、previousIndex |
| 从头到尾迭代方法 | hasNext、next、nextIndex |
LinkedList 可通过 ListIterator 迭代:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;//上一次执行 next() 或者 previos() 方法时的节点位置
private Node<E> next;//下一个节点
private int nextIndex;//下一个节点的位置
private int expectedModCount = modCount;//期望版本号、目前最新版本号
//……
}
我们先来看下从头到尾方向的迭代:
// 判断还有没有下一个元素
public boolean hasNext() {
return nextIndex < size;// 下一个节点的索引小于链表的大小,就有
}
// 取下一个元素
public E next() {
checkForComodification();//检查期望版本号有无发生变化
if (!hasNext()) throw new NoSuchElementException();//判断还有没有下一个元素
// next 是在上一次执行 next() 方法时被赋值的;第一次执行时是在初始化迭代器的时候被赋值的
lastReturned = next;
// next 是下一个节点了,为下次迭代做准备
next = next.next;
nextIndex++;
return lastReturned.item;
}
上述源码的思路就是直接取当前节点的下一个节点,从尾到头迭代需要判断 next 不为空和为空的场景:
// 如果上次节点索引位置大于 0,就还有节点可以迭代
public boolean hasPrevious() {
return nextIndex > 0;
}
// 取前一个节点
public E previous() {
checkForComodification();
if (!hasPrevious()) throw new NoSuchElementException();
// next 为空场景:1:说明是第一次迭代,取尾节点(last);2:上一次操作把尾节点删除掉了
// next 不为空场景:说明已经发生过迭代了,直接取前一个节点即可(next.prev)
lastReturned = next = (next == null) ? last : next.prev;
// 索引位置变化
nextIndex--;
return lastReturned.item;
}
迭代器删除
LinkedList 在删除元素时,也推荐通过迭代器进行删除,删除过程如下:
public void remove() {
checkForComodification();
// lastReturned 是本次迭代需要删除的值,分以下空和非空两种情况:
// lastReturned 为空,说明调用者没有主动执行过 next() 或者 previos(),直接报错
// lastReturned 不为空,是在上次执行 next() 或者 previos()方法时赋的值
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
//删除当前节点
unlink(lastReturned);
// next == lastReturned 的场景分析:从尾到头递归顺序,并且是第一次迭代,并且要删除最后一个元素的情况下
// 这种情况下,previous() 方法里面设置了 lastReturned = next = last,所以 next 和 lastReturned会相等
if (next == lastReturned)
// 这时候 lastReturned 是尾节点,lastNext 是 null,所以 next 也是 null,这样在 previous() 执行时,发现 next 是 null,就会把尾节点赋值给 next
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
2016-12-29
本文来自博客园,作者:白乾涛,转载请注明原文链接:https://www.cnblogs.com/baiqiantao/p/6234529.html
