数据结构与算法之美-14 动态规划
目录
40 | 初识动态规划
动态规划(DP, Dynamic Programming)
动态规划比较适合用来求解最优问题,比如求最大值、最小值等等。它可以非常显著地降低时间复杂度,提高代码的执行效率。不过,它也是出了名的难学。它的主要学习难点跟递归类似,那就是,求解问题的过程不太符合人类常规的思维方式。对于新手来说,要想入门确实不容易。不过,等你掌握了之后,你会发现,实际上并没有想象中那么难。
- 第一节,通过两个经典的动态规划问题模型,向你展示为什么需要动态规划,以及动态规划解题方法是如何演化出来的
- 第二节,总结动态规划适合解决的问题的特征,以及动态规划解题思路
- 第三节,实战解决三个经典的动态规划问题
0-1 背包问题
问题:对于一组不同重量、不可分割的物品,我们需要选择一些装入背包,在满足背包最大重量限制的前提下,背包中物品总重量的最大值是多少?
回溯 + 备忘录
上一节讲了回溯的解决方法,也就是穷举搜索所有可能的装法,然后找出满足条件的最大值。不过,回溯算法的复杂度比较高,是指数级别的。那有没有什么规律,可以有效降低时间复杂度呢?我们一起来看看。
规律是不是不好找?那我们就举个例子、画个图看看。我们假设背包的最大承载重量是 9。我们有 5 个不同的物品,每个物品的重量分别是 2,2,4,6,3。如果我们把这个例子的回溯求解过程用递归树画出来,就是下面这个样子:
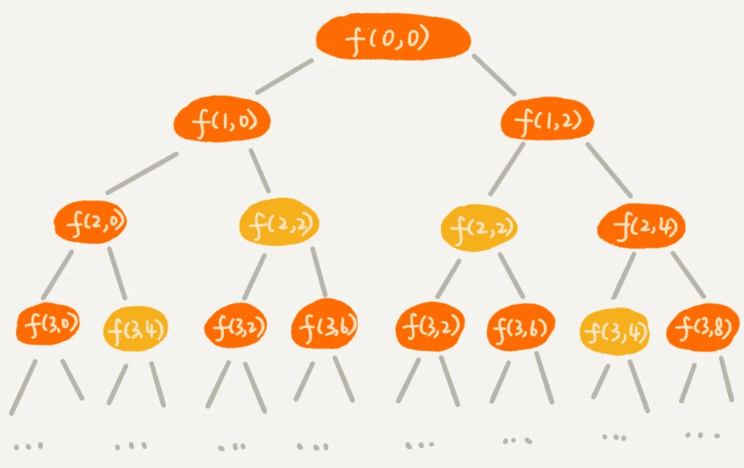
递归树中的每个节点表示一种状态,我们用
(i, cw)来表示
- 参数 i 表示将要决策第 i 个物品是否装入背包(注意,i 是从 0 开始的)
- 参数 cw 表示当前背包中物品的总重量
- 比如,
(2, 2)表示我们将要决策第 2 个物品是否装入背包,在决策前,背包中物品的总重量是 2
从递归树中可以发现,有些子问题的求解是重复的(即图中黄色的节点)。我们可以借助备忘录记录已经计算好的 f(i, cw),当再次计算到重复的 f(i, cw) 的时候,可以直接从备忘录中取出来用,就不用再递归计算了,这样就可以避免冗余计算。
这种解决方法非常好。实际上,它已经跟动态规划的执行效率基本上没有差别。
private int maxW = Integer.MIN_VALUE; // 结果放到 maxW 中
private int[] weight = {2, 2, 4, 6, 3}; // 物品重量
private int n = 5; // 物品个数
private int w = 9; // 背包承受的最大重量
private boolean[][] mem = new boolean[5][10]; // 备忘录,默认值 false
// 调用f(0, 0)
public void f(int i, int cw) {
if (cw == w || i == n) { // cw==w 表示装满了,i==n 表示物品都考察完了
if (cw > maxW) maxW = cw;
return;
}
if (mem[i][cw]) return; // 重复状态
mem[i][cw] = true; // 记录 (i, cw) 这个状态
f(i + 1, cw); // 选择不装第 i 个物品
if (cw + weight[i] <= w) {
f(i + 1, cw + weight[i]); // 选择装第 i 个物品
}
}
动态规划解法
我们把整个求解过程分为 n 个阶段,每个阶段会决策一个物品是否放到背包中。每个物品决策(放入或者不放入背包)完之后,背包中的物品的重量会有多种情况,也就是说,会达到多种不同的状态,对应到递归树中,就是有很多不同的节点。
我们把每一层重复的状态(节点)合并,只记录不同的状态,然后基于上一层的状态集合,来推导下一层的状态集合。通过合并每一层重复的状态,就可以保证每一层不同状态的个数都不会超过 w 个(w 表示背包的承载重量),也就是例子中的 9。于是,我们就成功避免了每层状态个数的指数级增长。
我们用一个二维数组 states[n][w+1] 来记录每层可以达到的不同状态(true 代表它存在这个状态)
- 第 0 个物品的重量是 2,要么装入背包,要么不装入背包,决策完之后,会对应背包的两种状态
- 背包中物品的总重量是 0,我们用
states[0][0]=true来表示这种状态 - 背包中物品的总重量是 2,我们用
states[0][2]=true来表示这种状态
- 背包中物品的总重量是 0,我们用
- 第 1 个物品的重量也是 2,基于之前的背包状态,在这个物品决策完之后,不同的状态有 3 个
- 背包中物品总重量是 0(0+0),我们用
states[1][0]=true来表示这种状态 - 背包中物品总重量是 2(0+2 或 2+0),我们用
states[1][2]=true来表示这种状态 - 背包中物品总重量是 0(2+2),我们用
states[1][4]=true来表示这种状态
- 背包中物品总重量是 0(0+0),我们用
- 以此类推,直到考察完所有的物品后,整个 states 状态数组就都计算好了
下图中 0 表示 false,1 表示 true。我们只需要在最后一层,找一个值为 true 的最接近 w 的值,就是背包中物品总重量的最大值。
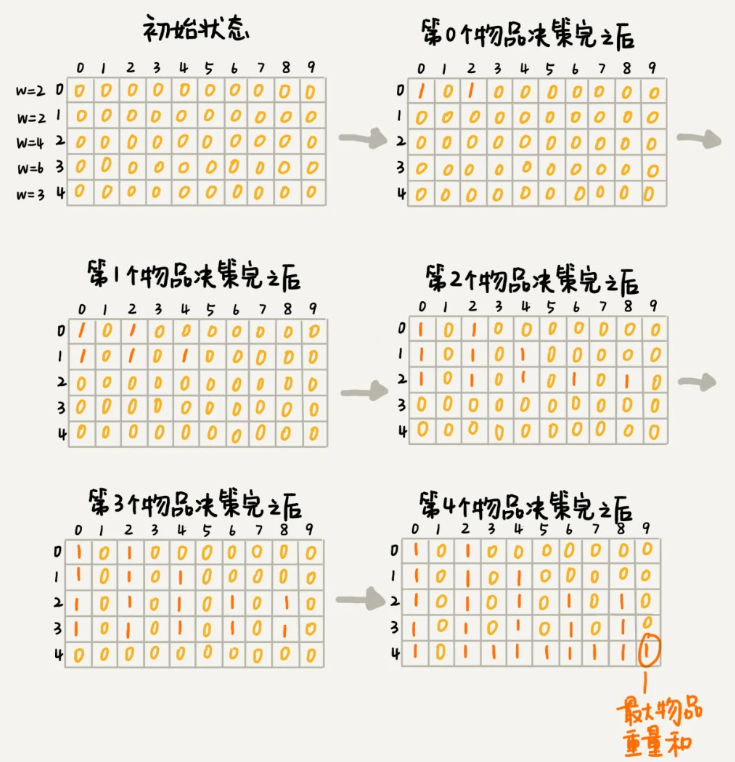
这就是一种用动态规划解决问题的思路。我们把问题分解为多个阶段,每个阶段对应一个决策。我们记录每一个阶段可达的状态集合(去掉重复的),然后通过当前阶段的状态集合,来推导下一个阶段的状态集合,动态地往前推进。这也是动态规划这个名字的由来,是不是还挺形象的?
动态规划代码
// weight:物品重量,n:物品个数,w:背包可承载重量
public int f(int[] weight, int n, int w) {
boolean[][] states = new boolean[n][w + 1]; // 默认值false
// 第一行的数据要特殊处理
states[0][0] = true; // 不把第1 个物品放入背包的情况
if (weight[0] <= w) {
states[0][weight[0]] = true; // 把第1个物品放入背包的情况
}
for (int i = 1; i < n; ++i) { // 动态规划状态转移
for (int j = 0; j <= w; ++j) { // 不把第i个物品放入背包
if (states[i - 1][j] == true) states[i][j] = true; //把上一层的状态赋值给当前层
}
for (int j = 0; j <= w - weight[i]; ++j) { // 把第i个物品放入背包
if (states[i - 1][j] == true) states[i][j + weight[i]] = true;
}
}
for (int i = w; i >= 0; --i) { // 输出结果
if (states[n - 1][i] == true) return i; // 从右往左找到最大可能的那个状态
}
return 0;
}
这个代码的时间复杂度非常好分析,是 O(n * w)
尽管动态规划的执行效率比较高,但是就刚刚的代码实现来说,我们需要额外申请一个二维数组,对空间的消耗比较多。所以,有时候,我们会说,动态规划是一种
空间换时间的解决思路。
动态规划代码优化
实际上,我们只需要一个大小为 w+1 的一维数组就可以解决这个问题。动态规划状态转移的过程,都可以基于这个一维数组来操作。
public static int knapsack2(int[] items, int n, int w) {
boolean[] states = new boolean[w + 1]; // 默认值false
states[0] = true; // 第一行的数据要特殊处理
if (items[0] <= w) {
states[items[0]] = true;
}
for (int i = 1; i < n; ++i) { // 动态规划
// 注意:j 需要从大到小来处理,否则会出现 for 循环重复计算的问题
for (int j = w - items[i]; j >= 0; --j) { // 把第 i 个物品放入背包(省略了拷贝上一层状态的操作)
if (states[j] == true) states[j + items[i]] = true;
}
}
for (int i = w; i >= 0; --i) { // 输出结果
if (states[i] == true) return i;
}
return 0;
}
0-1 背包问题升级版
我们刚刚讲的背包问题,只涉及背包重量和物品重量。我们现在引入物品价值这一变量。
问题:对于一组不同重量、不同价值、不可分割的物品,我们选择将某些物品装入背包,在满足背包最大重量限制的前提下,背包中可装入物品的总价值最大是多少呢?
回溯解法
这个问题依旧可以用回溯算法来解决。
private int maxV = 0; // 结果放到maxV中
private int[] weight = {2, 2, 4, 6, 3}; // 物品的重量
private int[] value = {3, 4, 8, 9, 6}; // 物品的价值
private int n = 5; // 物品个数
private int w = 9; // 背包承受的最大重量
// 调用 f(0, 0, 0)
public void f(int i, int cw, int cv) {
if (cw == w || i == n) {
if (cv > maxV) maxV = cv;
return;
}
f(i + 1, cw, cv); // 选择不装第i个物品
if (cw + weight[i] <= w) {
f(i + 1, cw + weight[i], cv + value[i]); // 选择装第i个物品
}
}
在下面的递归树中,每个节点表示一个状态。现在我们需要 3 个变量(i, cw, cv)来表示一个状态
- i 表示即将要决策第 i 个物品是否装入背包
- cw 表示当前背包中物品的总重量
- cv 表示当前背包中物品的总价值
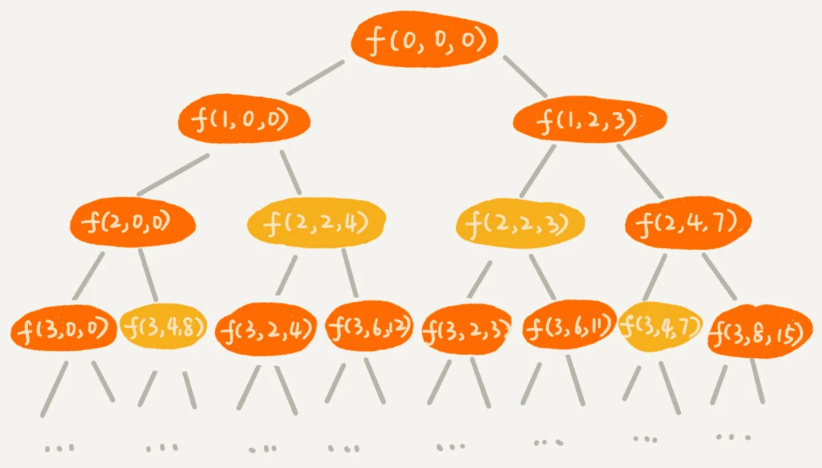
我们发现,在递归树中,有几个节点的 i 和 cw 是完全相同的,比如 f(2,2,4) 和 f(2,2,3)。在背包中物品总重量一样的情况下,f(2,2,4) 这种状态对应的物品总价值更大,我们可以舍弃 f(2,2,3) 这种状态,只需要沿着 f(2,2,4) 这条决策路线继续往下决策就可以。
也就是说,对于 (i, cw) 相同的不同状态,那我们只需要保留 cv 值最大的那个,继续递归处理,其他状态不予考虑。
这个问题就没法再用备忘录优化了
动态规划解法
我们还是把整个求解过程分为 n 个阶段,每个阶段会决策一个物品是否放到背包中。每个阶段决策完之后,背包中的物品的总重量以及总价值,会有多种情况,也就是会达到多种不同的状态。
我们用一个二维数组 states[n][w+1] 来记录每层可以达到的不同状态。不过这里数组存储的值不再是 boolean 类型的了,而是当前状态对应的最大总价值。我们把每一层中 (i, cw) 重复的状态(节点)合并,只记录 cv 值最大的那个状态,然后基于这些状态来推导下一层的状态。
public static int knapsack3(int[] weight, int[] value, int n, int w) {
int[][] states = new int[n][w + 1];
// 初始化 states
for (int i = 0; i < n; ++i) {
for (int j = 0; j < w + 1; ++j) {
states[i][j] = -1; // 感觉没必要,因为初始值用 0 也是可以的(当然后面判断是否初始化时要用 >0 代替 >=0)
}
}
// 第一行的数据要特殊处理
states[0][0] = 0; // 不把第 1 个物品放入背包的情况
if (weight[0] <= w) {
states[0][weight[0]] = value[0]; // 把第1 个物品放入背包的情况
}
for (int i = 1; i < n; ++i) { //动态规划,状态转移
for (int j = 0; j <= w; ++j) { // 不选择第 i 个物品
if (states[i - 1][j] >= 0) states[i][j] = states[i - 1][j]; // 下层状态利用上层的状态
}
for (int j = 0; j <= w - weight[i]; ++j) { // 选择第 i 个物品
if (states[i - 1][j] >= 0) {
int v = states[i - 1][j] + value[i]; // 当前位置在放入第 i 物品后的总价值
if (v > states[i][j + weight[i]]) { // 与之前此重量所处位置的价值比较(可能有重量相同、价值不同的情况)
states[i][j + weight[i]] = v; // 看看当前状态新算出的值是否能更大
}
}
}
}
// 找出最大值
int maxvalue = -1;
for (int j = 0; j <= w; ++j) {
if (states[n - 1][j] > maxvalue) maxvalue = states[n - 1][j];
}
return maxvalue;
}
这个问题的时间、空间复杂度及空间复杂度的优化方案,跟上一个例子大同小异。
购物时的凑单问题
淘宝的双十一购物节有 “满 w 元减 xx 元” 的促销活动,假设你的购物车中有 n 个想买的商品。
问题:如何从里面选几个,在【凑够】满减条件的前提下,让选出来的商品价格总和最大程度地接近 w 呢?
这个问题当然也可以利用回溯算法,穷举所有的排列组合,看大于等于 200 并且最接近 200 的组合是哪一个。但是,这样效率太低了点,时间复杂度非常高。
实际上,它跟第一个例子中讲的 0-1 背包问题很像,只不过是把重量换成了价格而已。购物车中有 n 个商品,我们针对每个商品都决策是否购买,每次决策之后,对应不同的状态集合,我们还是用一个二维数组 states[n][x] 来记录每次决策之后所有可达的状态。不过,这里的 x 值是多少呢?
0-1 背包问题中,我们找的是小于等于 w 的最大值,x 就是背包的最大承载重量 w+1。对于这个问题来说,我们要找的是大于等于 200 的最小值,所以就不能设置为 200+1 了。就这个实际的问题而言,我们可以限定 x 值为 200*3(或其他值也可以)。
不过,这个问题不仅要找出大于等于 200 的总价格中的最小的,我们还要找出这个最小总价格对应都要购买哪些商品。实际上,我们可以利用 states 数组,倒推出这个被选择的商品序列。
// items 商品价格(假设都是整数),n 商品个数, w 满减金额
public static void double11advance(int[] items, int n, int w) {
boolean[][] states = new boolean[n][3 * w + 1]; // 这只是预估的一个值
// 第一行的数据要特殊处理
states[0][0] = true;
if (items[0] <= 3 * w) {
states[0][items[0]] = true;
}
// 动态规划
for (int i = 1; i < n; ++i) {
for (int j = 0; j <= 3 * w; ++j) {
if (states[i - 1][j] == true) states[i][j] = true; // 不购买第i个商品
}
for (int j = 0; j <= 3 * w - items[i]; ++j) {
if (states[i - 1][j] == true) states[i][j + items[i]] = true; // 购买第i个商品
}
}
int j;
for (j = w; j < 3 * w + 1; ++j) {
if (states[n - 1][j] == true) break; // 输出结果大于等于 w 的最小值
}
if (j == 3 * w + 1) return; // 没有可行解
// 打印出选择购买的商品,i 表示二维数组中的行,j 表示列
for (int i = n - 1; i >= 1; --i) { // 倒推出这个被选择的商品序列
if (j - items[i] >= 0 && states[i - 1][j - items[i]] == true) { // 说明购买了这个商品
System.out.print(items[i] + " ");
j = j - items[i]; // 继续迭代地考察其他商品是否有选择购买
} // else 说明没有购买这个商品,j 不变
}
if (j != 0) System.out.print(items[0]);
}
状态 (i, j) 只有可能从 (i-1, j) 或者 (i-1, j - value[i]) 两个状态推导过来。所以,我们就检查这两个状态是否是可达的,也就是 states[i-1][j] 或者 states[i-1][j-value[i]] 是否是 true。
如果 states[i-1][j] 可达,就说明我们没有选择购买第 i 个商品,如果 states[i-1][j-value[i]] 可达,那就说明我们选择了购买第 i 个商品。我们从中选择一个可达的状态(如果两个都可达,就随意选择一个),然后,继续迭代地考察其他商品是否有选择购买。
41 | 动态规划理论
什么样的问题可以用动态规划解决
什么样的问题适合用动态规划来解决呢?换句话说,动态规划能解决的问题有什么规律可循呢?
我把这部分理论总结为一个模型、三个特征。
一个模型
一个模型指的是,动态规划适合解决的问题的模型:多阶段决策最优解模型。
我们一般是用动态规划来解决最优问题,而解决问题的过程需要经历多个决策阶段,每个决策阶段都对应着一组状态。然后我们寻找一组决策序列,经过这组决策序列,能够产生最终期望求解的最优值。
三个特征
三个特征分别是最优子结构、无后效性和重复子问题。
- 最优子结构
最优子结构指的是,问题的最优解包含
子问题的最优解
反过来说就是,我们可以通过子问题的最优解,推导出问题的最优解
也可以理解为,后面阶段的状态,可以通过前面阶段的状态,推导出来
- 无后效性
无后效性有两层含义,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的
第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响
无后效性是一个非常宽松的要求,只要满足前面提到的动态规划问题模型,其实基本上都会满足无后效性
- 重复子问题
用一句话概括就是,不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态
实例剖析
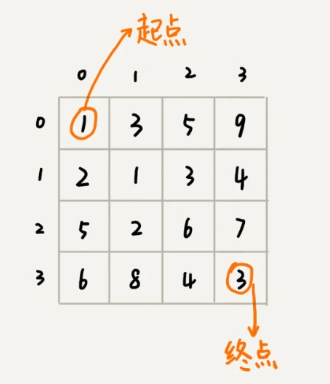
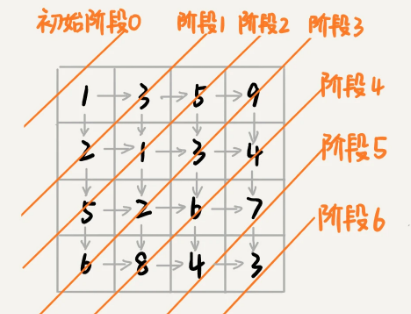
假设我们有一个 n 乘以 n 的矩阵 `w[n][n]`,矩阵存储的都是正整数。棋子起始位置在左上角,终止位置在右下角。我们将棋子从左上角移动到右下角,每次只能向右或者向下移动一位。从左上角到右下角,会有很多不同的路径可以走。我们把每条路径经过的数字加起来看作路径的长度。
问题:从左上角移动到右下角的最短路径长度是多少?
是否符合一个模型
- 多个决策阶段:从
(0, 0)走到(n-1, n-1),总共要走2*(n-1)步,也就对应着2*(n-1)个阶段。 - 寻找一组决策序列:每个阶段都有向右走或者向下走两种决策,并且每个阶段都会对应一个状态集合。
- 多阶段决策最优解模型:我们把状态定义为
min_dist(i, j),其中 i 表示行,j 表示列,min_dist 表达式的值表示从(0, 0)到达(i, j)的最短路径长度。所以,这个问题是一个多阶段决策最优解问题,符合动态规划的模型。
是否符合三个特征
- 重复子问题:我们可以用
回溯算法来解决这个问题。如果写一下代码,画一下递归树,就会发现,递归树中有重复的节点。重复的节点表示,从左上角到节点对应的位置,有多种路线,这也能说明这个问题中存在重复子问题。
-
无后效性:如果要走到
(i, j)这个位置,我们只能通过(i-1, j),(i, j-1)这两个位置移动过来。也就是说,如果想要计算(i, j)位置对应的状态,只需要关心(i-1, j),(i, j-1)两个位置对应的状态,并不关心棋子是通过什么样的路线到达这两个位置的。而且,我们仅仅允许往下和往右移动,不允许后退,所以,前面阶段的状态确定之后,不会被后面阶段的决策所改变,所以,这个问题符合无后效性这一特征。 -
最优子结构:刚刚定义状态的时候,我们把从起始位置
(0, 0)到(i, j)的最小路径,记作min_dist(i, j)。因为我们只能往右或往下移动,所以,我们只有可能从(i, j-1)或者(i-1, j)两个位置到达(i, j)。也就是说,到达(i, j)的最短路径要么经过(i, j-1),要么经过(i-1, j),而且到达(i, j)的最短路径肯定包含到达这两个位置的最短路径之一。换句话说就是,min_dist(i, j)可以通过min_dist(i, j-1)和min_dist(i-1, j)两个状态推导出来。这就说明,这个问题符合最优子结构。
min_dist(i, j) = w[i][j] + min(min_dist(i, j-1), min_dist(i-1, j))
动态规划问题的两种解题思路
解决动态规划问题一般有两种思路
状态转移表法:回溯算法实现 - 定义状态 - 画递归树 - 找重复子问题 - 画状态转移表 - 根据递推关系填表 - 将填表过程翻译成代码状态转移方程法:找最优子结构 - 写状态转移方程 - 将状态转移方程翻译成代码
不是每个问题都
同时适合这两种解题思路。有的问题可能用第一种思路更清晰,而有的问题可能用第二种思路更清晰。
两种方法,其实本质上是一种方法
- 熟悉的话,可以直接根据
状态转移方程去写代码:准备个可以存储每次决策后状态的数组,并初始化头部(如:第一行) - 不熟悉的题目,先画出
递归树,找出规律,设计出可以存储每次决策后状态的数组,写出大致的状态转移方程,再如上操作
状态转移表法
一般能用动态规划解决的问题,都可以使用回溯算法的暴力搜索解决。所以,当我们拿到问题的时候,我们可以:
- 回溯:先用简单的回溯算法解决
- 递归树:首先
定义状态,每个状态表示一个节点,然后对应画出递归树 - 重复子问题:看递归树中是否存在
重复子问题,以及重复子问题是如何产生的,以此来寻找规律,看是否能用动态规划解决 - 状态转移表法:先画出一个状态表,然后根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态
- 写动态规划代码:最后,我们将这个递推填表的过程翻译成代码,就是动态规划代码了
现在,我们来看一下,如何套用这个状态转移表法,来解决之前那个矩阵最短路径的问题。
写回溯代码
从起点到终点,我们有很多种不同的走法。我们可以穷举所有走法,然后对比找出一个最短走法。不过如何才能无重复又不遗漏地穷举出所有走法呢?我们可以用回溯算法这个比较有规律的穷举算法。
private int minDist = Integer.MAX_VALUE; // 全局变量或者成员变量
// 调用方式:minDistBacktracing(0, 0, 0, w, n);
public void minDistBT(int i, int j, int dist, int[][] w, int n) {
// 到达了n-1, n-1这个位置了,这里看着有点奇怪哈,你自己举个例子看下
if (i == n && j == n) {
if (dist < minDist) minDist = dist;
return;
}
if (i < n) { // 往下走,更新i=i+1, j=j
minDistBT(i + 1, j, dist+w[i][j], w, n);
}
if (j < n) { // 往右走,更新i=i, j=j+1
minDistBT(i, j+1, dist+w[i][j], w, n);
}
}
画递归树
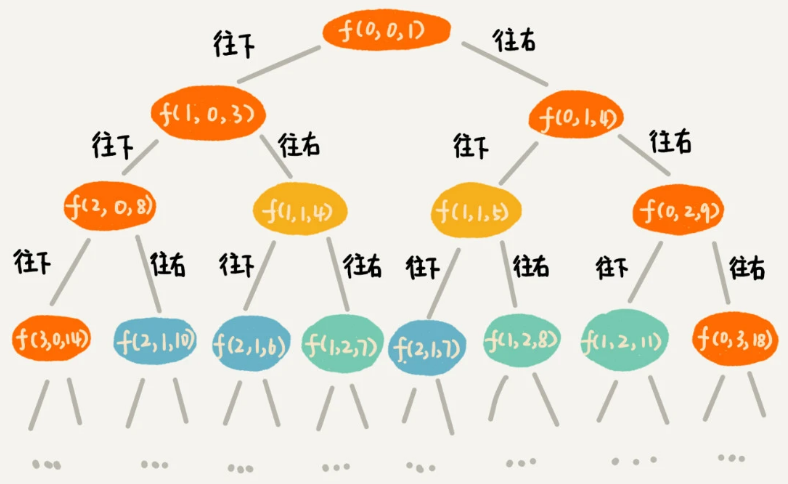
有了回溯代码之后,接下来,我们要画出递归树,以此来寻找重复子问题。
在递归树中,一个状态(也就是一个节点)包含三个变量 (i, j, dist),其中 i,j 分别表示行和列,dist 表示从起点到达 (i, j) 的路径长度。从图中,我们看出,尽管 (i, j, dist) 不存在重复的,但是 (i, j) 重复的有很多。对于 (i, j) 重复的节点,我们只需要选择 dist 最小的节点,继续递归求解,其他节点就可以舍弃了。
找到重复子问题之后,有两种优化回溯算法的思路
- 第一种是直接用回溯加
备忘录的方法,来避免重复子问题。从执行效率上来讲,这跟动态规划的解决思路没有差别 - 第二种是使用动态规划的解决方法,
状态转移表法
现在我们尝试看下,是否可以用动态规划来解决呢?
画状态转移表法
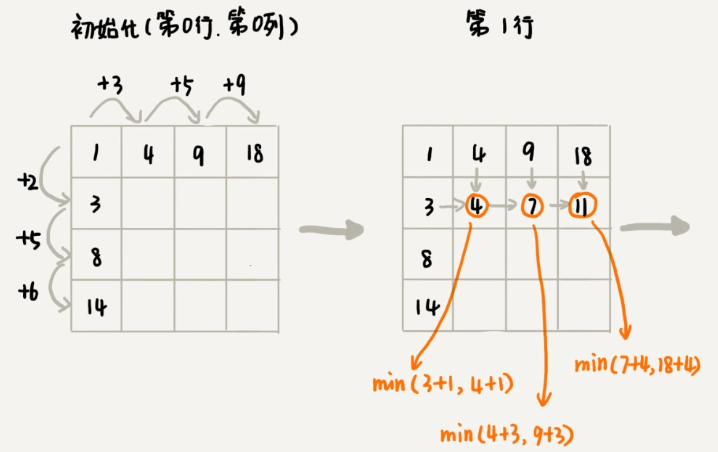
我们画出一个二维状态表,表中的行、列表示棋子所在的位置,表中的数值表示从起点到这个位置的最短路径。我们按照决策过程,通过不断状态递推演进,将状态表填好。为了方便代码实现,我们按行来进行依次填充。
尽管大部分状态表都是二维的,但是如果问题的状态比较复杂,需要很多变量来表示,那对应的状态表可能就是
高维的,这时就不适合用状态转移表法来解决了。
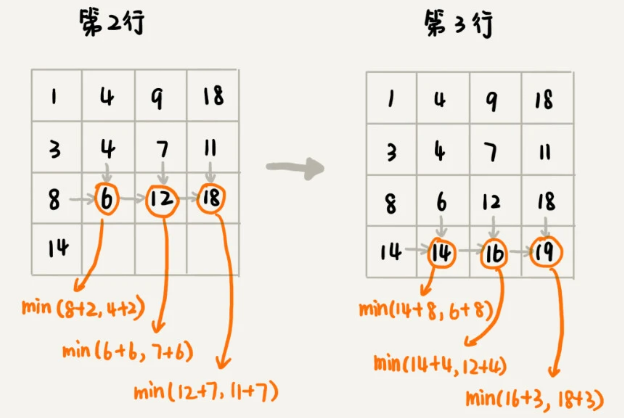
写动态规划代码
弄懂了填表的过程,代码实现就简单多了。我们将上面的过程,翻译成代码,就是下面这个样子。
public int minDistDP(int[][] matrix, int n) {
int[][] states = new int[n][n]; // 二维状态表
int sum = 0;
for (int j = 0; j < n; ++j) { // 初始化states的第一行数据
sum += matrix[0][j];
states[0][j] = sum;
}
sum = 0;
for (int i = 0; i < n; ++i) { // 初始化states的第一列数据
sum += matrix[i][0];
states[i][0] = sum;
}
for (int i = 1; i < n; ++i) {
for (int j = 1; j < n; ++j) {
states[i][j] = matrix[i][j] + Math.min(states[i][j-1], states[i-1][j]);
}
}
return states[n-1][n-1];
}
状态转移方程法
状态转移方程法有点类似递归的解题思路。我们需要分析,某个问题如何通过子问题来递归求解,也就是所谓的最优子结构。根据最优子结构,写出递归公式,也就是所谓的状态转移方程。
有了状态转移方程,代码实现就非常简单了。一般情况下,我们有两种代码实现方法
- 一种是
递归加备忘录 - 另一种是
迭代递推
状态转移方程前面已经分析过了:
min_dist(i, j) = w[i][j] + min(min_dist(i, j-1), min_dist(i-1, j))
状态转移方程是解决动态规划的关键,如果能写出状态转移方程,那动态规划问题基本上就解决一大半了,而翻译成代码非常简单。但是很多动态规划问题的状态本身就不好定义,状态转移方程也就更不好想到。
递归 + 备忘录
下面我用递归加备忘录的方式,将状态转移方程翻译成代码,你可以看看。对于另一种实现方式,跟状态转移表法的代码实现是一样的,只是思路不同。
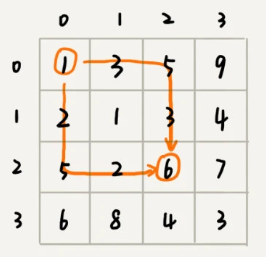
private int[][] matrix = {{1,3,5,9}, {2,1,3,4},{5,2,6,7},{6,8,4,3}};
private int n = 4;
private int[][] mem = new int[4][4]; //【备忘录】
// 调用 minDist(n-1, n-1)
public int minDist(int i, int j) {
if (i == 0 && j == 0) return matrix[0][0];
if (mem[i][j] > 0) return mem[i][j]; //从备忘录中直接取数
int minLeft = Integer.MAX_VALUE;
if (j-1 >= 0) {
minLeft = minDist(i, j-1); //【递归】求解左侧位置的最小值
}
int minUp = Integer.MAX_VALUE;
if (i-1 >= 0) {
minUp = minDist(i-1, j); //【递归】求解上侧位置的最小值
}
int currMinDist = matrix[i][j] + Math.min(minLeft, minUp); //计算当前位置最小值
mem[i][j] = currMinDist; //存到备忘录中
return currMinDist;
}
案例:硬币找零问题
假设我们有几种不同币值的硬币 v1,v2,……,vn,如果我们要支付 w 元,求最少需要多少个硬币。
比如,我们有 3 种不同的硬币,1 元、3 元、5 元,我们要支付 14 元,最少需要 4 个硬币。
状态转移方程:f(w) = 1 + min(f(w-v1), f(w-v2), ... f(w-vn))
状态转移方程法
class Solution {
public int coinChange(int[] coins, int amount) {
if (amount == 0) return 0;
if (amount < 0) return Integer.MAX_VALUE;
int count = Integer.MAX_VALUE;
for (int i = 0; i < coins.length; i++) {
int temCount = coinChange(coins, amount - coins[i]);
if (temCount != -1 && temCount != Integer.MAX_VALUE) {
count = Math.min(count, 1 + temCount);
}
}
return count == Integer.MAX_VALUE ? -1 : count;
}
}
时间复杂度 O(n * 2^amount)
状态转移表法
class Solution {
public int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1]; //表示的凑成总金额为 n 所需的最少的硬币个数
Arrays.fill(dp, amount + 1); //初始化各个元素为 amount + 1,代表没法凑成的情况
dp[0] = 0; //自底向上,金额为 0 时最小硬币数为 0
for (int i = 1; i <= amount; i++) {
for (int j = 0; j < coins.length; j++) {
if (coins[j] <= i) {
//根据状态转移方程 dp[amount] = 1 + dp[amount-value]
//一定是可以根据 dp 数组中之前的值,推导当前 dp[i] 的值
dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1); //核心逻辑
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}
时间复杂度 O(n * amount)
42 | 动态规划实战
如何量化两个字符串的相似度
如何量化两个字符串之间的相似程度呢?有一个非常著名的量化方法,那就是编辑距离 Edit Distance。
编辑距离指的是,将一个字符串转化成另一个字符串,需要的最少编辑操作次数。编辑距离越大,说明两个字符串的相似程度越小。对于两个完全相同的字符串来说,编辑距离就是 0。
根据所包含的编辑操作种类的不同,编辑距离有多种不同的计算方式,比较著名的有:
- 莱文斯坦距离 Levenshtein distance
- 表示两个字符串
差异的大小 - 允许增加、删除、
替换字符这三个编辑操作
- 表示两个字符串
- 最长公共子串长度 Longest common substring length
- 表示两个字符串
相似程度的大小 - 只允许增加、删除字符这两个编辑操作
- 表示两个字符串
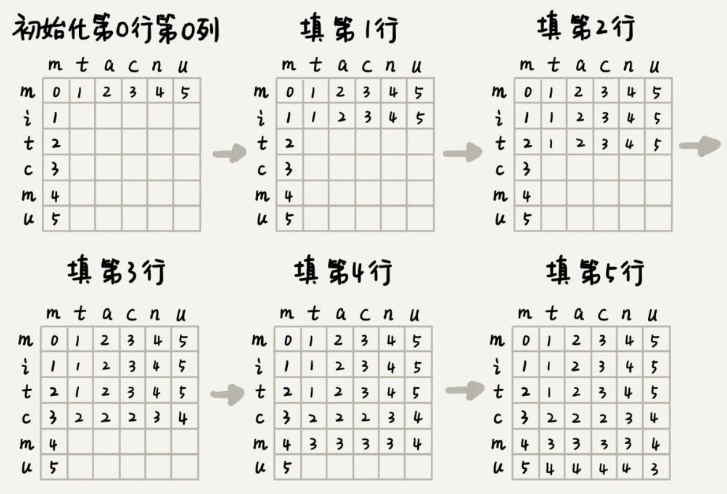
案例:字符串 mitcmu 和 mtacnu 的莱文斯坦距离是 3,最长公共子串长度是 4。
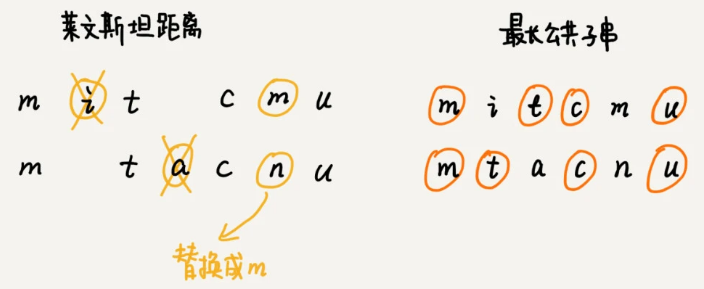
了解了编辑距离的概念之后,如何快速计算两个字符串之间的编辑距离?
如何计算莱文斯坦距离
这个问题是求把一个字符串变成另一个字符串,需要的最少编辑次数。整个求解过程,涉及多个决策阶段,我们需要依次考察一个字符串中的每个字符,跟另一个字符串中的字符是否匹配,匹配的话如何处理,不匹配的话又如何处理。所以,这个问题符合多阶段决策最优解模型。
回溯算法
我们前面讲了,贪心、回溯、动态规划可以解决的问题,都可以抽象成这样一个模型。要解决这个问题,我们可以先看一看,用最简单的回溯算法,该如何来解决。
回溯是一个递归处理的过程。如果 a[i] 与 b[j] 匹配,我们递归考察 a[i+1] 和 b[j+1]。如果 a[i] 与 b[j] 不匹配,那我们有多种处理方式可选:
- 可以删除 a[i],然后递归考察 a[i+1] 和 b[j]
- 可以删除 b[j],然后递归考察 a[i] 和 b[j+1]
- 可以在 a[i] 前面添加一个跟 b[j] 相同的字符,然后递归考察 a[i] 和 b[j+1]
- 可以在 b[j] 前面添加一个跟 a[i] 相同的字符,然后递归考察 a[i+1] 和 b[j]
- 可以将 a[i] 替换成 b[j],或者将 b[j] 替换成 a[i],然后递归考察 a[i+1] 和 b[j+1]
我们将上面的回溯算法的处理思路,翻译成代码,就是下面这个样子:
private char[] a = "mitcmu".toCharArray();
private char[] b = "mtacnu".toCharArray();
private int n = 6;
private int m = 6;
private int minDist = Integer.MAX_VALUE; // 存储结果
// 调用方式 lwstBT(0, 0, 0);
public lwstBT(int i, int j, int edist) {
if (i == n || j == m) {
if (i < n) edist += (n-i);
if (j < m) edist += (m - j);
if (edist < minDist) minDist = edist;
return;
}
if (a[i] == b[j]) { // 两个字符匹配
lwstBT(i+1, j+1, edist);
} else { // 两个字符不匹配
lwstBT(i + 1, j, edist + 1); // 删除a[i]或者b[j]前添加一个字符
lwstBT(i, j + 1, edist + 1); // 删除b[j]或者a[i]前添加一个字符
lwstBT(i + 1, j + 1, edist + 1); // 将a[i]和b[j]替换为相同字符
}
}
递归树
根据回溯算法的代码实现,我们可以画出递归树,看是否存在重复子问题。如果存在重复子问题,那我们就可以考虑能否用动态规划来解决;如果不存在重复子问题,那回溯就是最好的解决方法。
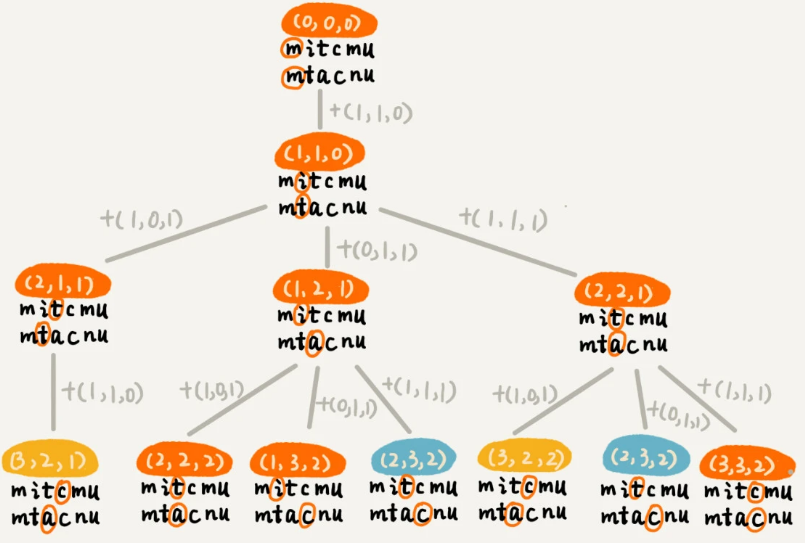
在递归树中,每个节点代表一个状态,状态包含三个变量 (i, j, edist),其中,edist 表示处理到 a[i] 和 b[j] 时,已经执行的编辑操作的次数。
在递归树中,(i, j) 两个变量重复的节点很多,比如 (3, 2) 和 (2, 3)。对于 (i, j) 相同的节点,我们只需要保留 edist 最小的,继续递归处理就可以了,剩下的节点都可以舍弃。所以,状态就从 (i, j, edist) 变成了 (i, j, min_edist),其中 min_edist 表示处理到 a[i] 和 b[j],已经执行的最少编辑次数。
状态转移方程
看到这里,你有没有觉得,这个问题跟上两节讲的动态规划例子非常相似?不过,这个问题的状态转移方式,要比之前两节课中讲到的例子都要复杂很多。上一节我们讲的矩阵最短路径问题中,到达状态 (i, j) 只能通过 (i-1, j) 或 (i, j-1) 两个状态转移过来,而今天这个问题,状态 (i, j) 可能从 (i-1, j),(i, j-1),(i-1, j-1) 三个状态中的任意一个转移过来。
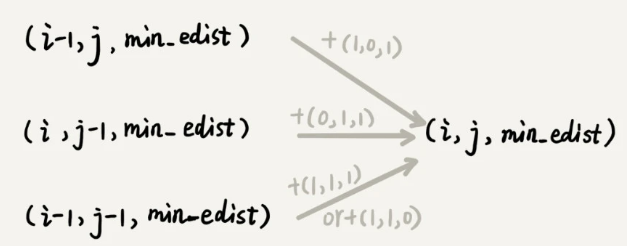
基于刚刚的分析,我们可以尝试着将把状态转移的过程,用公式写出来。这就是我们前面讲的状态转移方程。
如果:a[i]!=b[j],那么:min_edist(i, j) 就等于:
min(min_edist(i-1,j)+1, min_edist(i,j-1)+1, min_edist(i-1,j-1)+1)
如果:a[i]==b[j],那么:min_edist(i, j)就等于:
min(min_edist(i-1,j)+1, min_edist(i,j-1)+1,min_edist(i-1,j-1))
状态表
了解了状态与状态之间的递推关系,我们画出一个二维的状态表,按行依次来填充状态表中的每个值。
动态规划代码
我们现在既有状态转移方程,又理清了完整的填表过程,代码实现就非常简单了。我将代码贴在下面,你可以对比着文字解释,一起看下。
public int lwstDP(char[] a, int n, char[] b, int m) {
int[][] minDist = new int[n][m];
for (int j = 0; j < m; ++j) { // 初始化第0行:a[0..0]与b[0..j]的编辑距离
if (a[0] == b[j]) minDist[0][j] = j;
else if (j != 0) minDist[0][j] = minDist[0][j-1]+1;
else minDist[0][j] = 1;
}
for (int i = 0; i < n; ++i) { // 初始化第0列:a[0..i]与b[0..0]的编辑距离
if (a[i] == b[0]) minDist[i][0] = i;
else if (i != 0) minDist[i][0] = minDist[i-1][0]+1;
else minDist[i][0] = 1;
}
for (int i = 1; i < n; ++i) { // 按行填表
for (int j = 1; j < m; ++j) {
if (a[i] == b[j]) minDist[i][j] = min(
minDist[i-1][j]+1, minDist[i][j-1]+1, minDist[i-1][j-1]);
else minDist[i][j] = min(
minDist[i-1][j]+1, minDist[i][j-1]+1, minDist[i-1][j-1]+1);
}
}
return minDist[n-1][m-1];
}
private int min(int x, int y, int z) {
int minv = Integer.MAX_VALUE;
if (x < minv) minv = x;
if (y < minv) minv = y;
if (z < minv) minv = z;
return minv;
}
经验、技巧
关于复杂算法问题的解决思路,我还有一些经验、小技巧,可以分享给你。
当我们拿到一个问题的时候,我们可以先不思考计算机会如何实现这个问题,而是单纯考虑人脑会如何去解决这个问题。人脑比较倾向于思考具象化的、看得见摸得着的东西,不适合思考过于抽象的问题。所以,我们需要把抽象问题具象化。那如何具象化呢?我们可以实例化几个测试数据,通过人脑去分析具体实例的解,然后总结规律,再尝试套用学过的算法,看是否能够解决。
除此之外,我还有一个非常有效、但也算不上技巧的东西,那就是多练。实际上,等你做多了题目之后,自然就会有感觉,看到问题,立马就能想到能否用动态规划解决,然后直接就可以寻找最优子结构,写出动态规划方程,然后将状态转移方程翻译成代码。
如何计算最长公共子串长度
这个问题的解决思路,跟莱文斯坦距离的解决思路非常相似,也可以用动态规划解决。我刚刚已经详细讲解了莱文斯坦距离的动态规划解决思路,所以,针对这个问题,我直接定义状态,然后写状态转移方程。
每个状态还是包括三个变量 (i, j, max_lcs),max_lcs 表示 a[0...i] 和 b[0...j] 的最长公共子串长度。那 (i, j) 这个状态都是由哪些状态转移过来的呢?
我们先来看回溯的处理思路。我们从 a[0] 和 b[0] 开始,依次考察两个字符串中的字符是否匹配。
- 如果 a[i] 与 b[j] 互相匹配,我们将最大公共子串长度加一,并且继续考察 a[i+1] 和 b[j+1]
- 如果 a[i] 与 b[j] 不匹配,最长公共子串长度不变,这个时候,有两个不同的决策路线:
- 删除 a[i],或者在 b[j] 前面加上一个字符 a[i],然后继续考察 a[i+1] 和 b[j]
- 删除 b[j],或者在 a[i] 前面加上一个字符 b[j],然后继续考察 a[i] 和 b[j+1]
反过来也就是说,如果我们要求 a[0...i] 和 b[0...j] 的最长公共长度 max_lcs(i, j),我们只有可能通过下面三个状态转移过来:
- (i-1, j-1, max_lcs)
- (i-1, j, max_lcs)
- (i, j-1, max_lcs)
对于 (i, j, max_lcs),其中的 max_lcs 表示 a[0...i] 和 b[0...j] 的最长公共子串长度
如果我们把这个转移过程,用状态转移方程写出来,就是下面这个样子:
如果:a[i]==b[j],那么:max_lcs(i, j) 就等于:
max(max_lcs(i-1,j-1)+1, max_lcs(i-1, j), max_lcs(i, j-1));
如果:a[i]!=b[j],那么:max_lcs(i, j) 就等于:
max(max_lcs(i-1,j-1), max_lcs(i-1, j), max_lcs(i, j-1));
有了状态转移方程,代码实现就简单多了。我把代码贴到了下面,你可以对比着文字一块儿看。
public int lcs(char[] a, int n, char[] b, int m) {
int[][] maxlcs = new int[n][m];
for (int j = 0; j < m; ++j) {//初始化第0行:a[0..0]与b[0..j]的maxlcs
if (a[0] == b[j]) maxlcs[0][j] = 1;
else if (j != 0) maxlcs[0][j] = maxlcs[0][j-1];
else maxlcs[0][j] = 0;
}
for (int i = 0; i < n; ++i) {//初始化第0列:a[0..i]与b[0..0]的maxlcs
if (a[i] == b[0]) maxlcs[i][0] = 1;
else if (i != 0) maxlcs[i][0] = maxlcs[i-1][0];
else maxlcs[i][0] = 0;
}
for (int i = 1; i < n; ++i) { // 填表
for (int j = 1; j < m; ++j) {
if (a[i] == b[j]) maxlcs[i][j] = max(
maxlcs[i-1][j], maxlcs[i][j-1], maxlcs[i-1][j-1]+1);
else maxlcs[i][j] = max(
maxlcs[i-1][j], maxlcs[i][j-1], maxlcs[i-1][j-1]);
}
}
return maxlcs[n-1][m-1];
}
private int max(int x, int y, int z) {
int maxv = Integer.MIN_VALUE;
if (x > maxv) maxv = x;
if (y > maxv) maxv = y;
if (z > maxv) maxv = z;
return maxv;
}
如何实现搜索引擎的拼写纠错功能
利用 Trie 树,可以实现搜索引擎的关键词提示功能,这样可以节省用户输入搜索关键词的时间。实际上,搜索引擎在用户体验方面的优化还有很多,比如你可能经常会用的拼写纠错功能。
当你在搜索框中一不小心输错单词时,搜索引擎会非常智能地检测出你的拼写错误,并且用对应的正确单词来进行搜索。这个功能是怎么实现的呢?
当用户在搜索框内,输入一个拼写错误的单词时,我们就拿这个单词跟词库中的单词一一进行比较,计算编辑距离,将编辑距离最小的单词,作为纠正之后的单词,提示给用户。
这就是拼写纠错最基本的原理。不过,真正用于商用的搜索引擎,拼写纠错功能显然不会就这么简单
- 一方面,单纯利用编辑距离来纠错,
效果并不一定好 - 另一方面,词库中的数据量可能很大,搜索引擎每天要支持海量的搜索,所以对纠错的
性能要求很高
针对纠错效果不好的问题,我们有很多种优化思路,比如:
-
我们并不仅仅取出编辑距离最小的那个单词,而是取出编辑距离最小的 TOP 10,然后根据其他参数,决策选择哪个单词作为拼写纠错单词。比如使用搜索热门程度来决定哪个单词作为拼写纠错单词。
-
我们还可以用多种编辑距离计算方法,比如今天讲到的两种,首先分别计算编辑距离最小的 TOP 10,然后求交集,用交集的结果,再继续优化处理。
-
我们还可以通过统计用户的搜索日志,得到最常被拼错的单词列表,以及对应的拼写正确的单词。搜索引擎在拼写纠错的时候,首先在这个最常被拼错单词列表中查找。如果一旦找到,直接返回对应的正确的单词。这样纠错的效果非常好。
-
我们还有更加高级一点的做法,引入个性化因素。针对每个用户,维护这个用户特有的搜索喜好,也就是常用的搜索关键词。当用户输入错误的单词的时候,我们首先在这个用户常用的搜索关键词中,计算编辑距离,查找编辑距离最小的单词。
针对纠错性能方面,我们也有相应的优化方式,下面是两种分治的优化思路:
-
如果纠错功能的 TPS (Transactions Per Second,每秒传输的事务个数) 不高,我们可以部署多台机器,每台机器运行一个独立的纠错功能。当有一个纠错请求的时候,我们通过负载均衡,分配到其中一台机器,来计算编辑距离,得到纠错单词。
-
如果纠错系统的响应时间太长,也就是,每个纠错请求处理时间过长,我们可以将纠错的词库,分割到很多台机器。当有一个纠错请求的时候,我们就将这个拼写错误的单词,同时发送到这多台机器,让多台机器并行处理,分别得到编辑距离最小的单词,然后再比对合并,最终决定出一个最优的纠错单词。
真正的搜索引擎的拼写纠错优化,肯定不止我讲的这么简单,但是万变不离其宗。掌握了核心原理,就是掌握了解决问题的方法,剩下就靠你自己的灵活运用和实战操练了。
2021-10-9
本文来自博客园,作者:白乾涛,转载请注明原文链接:https://www.cnblogs.com/baiqiantao/p/15387346.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现