数据库 MySQL 基本操作 语法
目录
数据库管理系统操作
查看版本号
-- 登录前
mysql -V
mysql --help | grep Ver
-- 登录后
select version();
status;
启动及关闭服务
-- 启动服务
net start mysql
mysqld --console
-- 关闭服务
net stop mysql
mysqladmin -uroot shudown
登录及退出
-- 登录
mysql [-D 所选择的数据库名] [-h 主机名] -u 用户名 -p
mysql -u root -p
-- 退出
exit;
quit;
\q;
其他
-- 登录前查看本地 MySQL 服务是否启动
netstat -an|find "3306"
-- 登录后查看MySQL端口号
show global variables like 'port';
数据库操作
创建数据库 create
create database db_name;
create database db_name character set gbk;
-- 创建一个使用字符集并带校对规则的数据库
create database db_name character set utf-8 collate utf8_bin;
查看数据库 show/select
show databases;
-- 查看创建数据库时的定义信息
show create database db_name;
-- 查看当前所选的数据库
select database();
其他操作 alter/drop/use
-- 修改数据库字符编码
alter database db_name character set utf8;
-- 删除数据库
drop database db_name;
-- 进入(切换)数据库,对于表的操作需要先进入库
use db_name;
数据库-表操作
MySQL有三大类数据类型,分别为数字、日期/时间、字符串,这三大类中又更细致的划分了许多子类型:
- 数字类型
- 整数: tinyint、smallint、mediumint、int、bigint
取值范围如果加了unsigned,代表无符号,则可存储的最大值翻倍
int(m) 里的 m 是表示 SELECT 查询结果集中的显示宽度,并不影响实际的取值范围 - 浮点数: float、double、real、decimal
- 整数: tinyint、smallint、mediumint、int、bigint
- 日期和时间: date、time、datetime、timestamp、year
- 字符串类型
- 字符串: char、varchar
- 文本: text、tinytext、mediumtext、longtext
- 二进制: blob、tinyblob、mediumblob、longblob
创建表 create
create table if not exists `user_accounts` (
`id` int(100) unsigned NOT NULL AUTO_INCREMENT primary key,
`password` varchar(32) NOT NULL DEFAULT '' COMMENT '用户密码',
`reset_password` tinyint(32) NOT NULL DEFAULT 0 COMMENT '用户类型:0-不需要重置密码;1-需要重置密码',
`mobile` varchar(20) NOT NULL DEFAULT '' COMMENT '手机',
`create_at` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`update_at` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
-- 创建唯一索引,不允许重复
UNIQUE INDEX idx_user_mobile(`mobile`)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8
COMMENT='用户表信息';
数据类型的属性解释
NULL:数据列可包含NULL值NOT NULL:数据列不允许包含NULL值DEFAULT:默认值PRIMARY KEY:主键AUTO_INCREMENT:自动递增,适用于整数类型UNSIGNED:是指数值类型只能为正数(即无符号的)CHARACTER SET name:指定一个字符集COMMENT:对表或者字段说明
查看表 show/desc
-- 查看当前数据库中所有表
show tables
-- 查看当前数据库表建表语句
show create table tableName
-- 查看表结构,也可用全称describe
desc tableName
删除表 delete/truncate/drop
-- 清空表中的数据,不删除表;可以回退,可以带 where 条件的删除
delete from tableName;
-- 删除表中的所有数据,不删除表;无法回退,默认所有的表内容都删除,删除速度比delete快
truncate table tableName;
-- 删除整张表
drop table tableName;
DROP TABLE IF EXISTS tableName;
其他操作 rename
-- 重命名表
alter table oldName rename newName;
rename table oldName to newName;
-- 修改表的字符集
alter table tableName character set gbk;
数据库-表-列操作 alter
添加列 add
-- 语法:alter table 表名 add [column] 列名 列数据类型 [after 插入位置];
alter table students add address char(60);
alter table students add column birthday date after age;
alter table students add `weeks` varchar(5) not null default "" after `number`;
修改列 change/modify
-- 语法:alter table 表名 change 列名称 列新名称 新数据类型;
alter table students change tel telphone char(13) default "-";
alter table students change name name char(16) not null;
-- 修改 COMMENT 前面必须得有类型属性
alter table students change name name char(16) COMMENT '这里是名字';
-- change用于修改列名字,需要重建表;仅修改列属性的时候建议使用modify,不需要重建表
alter table meeting modify `weeks` varchar(20) NOT NULL DEFAULT '' COMMENT '开放日期';
alter table meeting modify `id` INT NOT NULL;
-- FIRST 表示放在第一列的位置
alter table `user` modify COLUMN `id` varchar(50) NOT NULL FIRST;
删除列 drop
-- 语法:alter table 表名 drop 列名称;
alter table students drop birthday;
数据库-表-记录操作
插入记录 insert into
-- 语法:INSERT INTO 表名称 [(列1, 列2,...)] VALUES (值1, 值2,...)
INSERT INTO Persons (LastName, Address) VALUES ('JSLite', 'shanghai');
INSERT INTO meeting SET a=1,b=2;
-- 如果要插入所有字段可以省写列列表,直接按表中字段顺序写值列表
insert into employee values (1,'ceo',800,'公司老大'), (2,'cto',300,'技术老大');
-- 插入一条数据,如果已存在就更新address和update_at字段,字符和日期型数据应包含在单引号中
INSERT INTO students (id,address,update_at) VALUES (3,'gz','2020-10-17') ON DUPLICATE KEY UPDATE id=VALUES(id), address=VALUES(address), update_at='2020-10-18';
-- 将一个表的数据插入到另外一个表:INSERT INTO 目标表 (列1,列2...) SELECT 字段1, 字段2, ... FROM 来源表;
INSERT INTO orders (num, title) SELECT m.user_id, m.title FROM meeting m where m.id=1;
更新记录 update set
-- 语法:UPDATE 表名称 SET 列名称 = 新值 [WHERE]
UPDATE orders set title='新标题' WHERE id=1;
-- WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行
update employee set salary = 3000 where name='张飞';
update employee set salary = 4000,job='ccc' where name='关羽';
update employee set salary = salary + 1000 where name='刘备';
update employee set salary = 5000;
-- 设置字段的值为另一个结果取出来的字段
update user set name = (select name from user1 where user1.id = 1 ) where id = (select id from user2 where user2 .name='小苏');
删除记录 delete from
-- 语法:DELETE FROM 表名称 [WHERE]
DELETE FROM Person WHERE LastName = 'JSLite'
DELETE from meeting where id in (2,3);
-- 如果不使用where子句,将删除表中所有数据(不删除表本身)
DELETE FROM table_name
DELETE * FROM table_name
-- 使用truncate删除表中记录和使用delete有所不同,参看mysql文档
truncate table employee;
查找记录 select from
-- 语法:SELECT 列名称 FROM 表名称 [WHERE]
select name,english from exam;
select * from exam;
-- 只拉一条数据(据说limit能优化性能)
SELECT * FROM users where id=3 limit 1
-- 过滤重复数据
select distinct english from exam;
-- 在所有学生数学分数上加10分显示
select name, math+10 from exam;
-- 使用别名表示学生总分(as可以省略),统计每个学生的总分
select name as 姓名 ,english+math+chinese 总成绩 from exam;
SELECT s.id from station s WHERE id in (13,14) and id not in (4);
-- 结果集显示 Persons表的 LastName、FirstName字段,Orders表的OrderNo字段
SELECT p.LastName, p.FirstName, o.OrderNo FROM Persons p, Orders o WHERE p.Id_P = o.Id_P
-- 中英文混合排序最简单的办法;ci是 case insensitive, 即 “大小写不敏感”
SELECT tag, COUNT(tag) from news GROUP BY tag order by convert(tag using gbk) collate gbk_chinese_ci;
SELECT tag, COUNT(tag) from news GROUP BY tag order by convert(tag using utf8) collate utf8_unicode_ci;
数据库-表-索引操作
索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
索引分单列索引和组合索引:
- 单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引
- 组合索引:即一个索引包含多个列
建立索引会占用磁盘空间的索引文件。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
索引也有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,因为更新表时,MySQL 不仅要保存数据,还要保存索引文件。
建立索引的时机
在WHERE和JOIN中出现的列需要建立索引,但也不完全如此:
- MySQL 只对
<<==>>=BETWEENIN使用索引 - 某些时候的
LIKE也会使用索引 - 在LIKE以通配符
%和_作为 开头 查询时,MySQL 不会使用索引
普通索引 index
普通索引的索引值可出现多次
-- 方式一,创建表的时候直接指定索引,语法:INDEX [indexName] (columnName[(length)])
CREATE TABLE tableName(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` CHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`id`),
INDEX indexName (title(8))
-- length:BLOB和TEXT类型必须指定 length;CHAR、VARCHAR类型时,length 可以小于字段实际长度
-- 【INDEX indexName (title)】:可忽略 length,但是不能忽略 columnName 外的小括号
-- 【INDEX (title)】:忽略 indexName 时,indexName 取 columnName 的值
);
-- 方式二,修改表结构方式添加索引,语法:ALTER table tableName ADD INDEX indexName(columnName[(length)])
ALTER table tableName ADD INDEX indexName(title(6))
-- 方式三,直接创建索引,语法:CREATE INDEX indexName ON tableName (columnName[(length)])
CREATE INDEX indexName ON tableName (title(6))
唯一索引 unique
唯一索引的值必须唯一,但允许有空值;如果是组合索引,则列值的组合必须唯一。
CREATE TABLE tableName(
...,
-- 方式一:UNIQUE INDEX [indexName] (columnName[(length)])
-- UNIQUE [indexName] (columnName[(length)])
);
-- 方式二:ALTER table tableName ADD INDEX indexName(columnName[(length)])
-- 方式三:CREATE UNIQUE INDEX indexName ON tableName (columnName[(length)])
主键索引 primary key
主键索引需要确保索引值必须是唯一的,且不能为NULL。
CREATE TABLE tableName (
-- AUTO_INCREMENT:自动增长;NOT NULL:非空约束
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
-- 方式一:创建表的时候指定,主键名indexName其实就是【PRIMARY】
PRIMARY KEY (`id`)
)
-- 方式二:ALTER table tableName ADD PRIMARY KEY(columnName[(length)])
ALTER TABLE tableName ADD PRIMARY key (id);
全文索引 fulltext
-- ALTER TABLE tableName ADD FULLTEXT indexName (columnName[(length)])
-- 给 user 表中的 description 字段添加全文索引
ALTER TABLE user ADD FULLTEXT (description);
删除索引 drop
-- 删除主键时只需指定 PRIMARY KEY,删除其他索引时,须指定索引名
DROP INDEX indexName ON tableName;
ALTER TABLE tableName DROP INDEX indexName;
ALTER TABLE tableName DROP PRIMARY KEY;
多列索引
-- ALTER TABLE tableName ADD INDEX indexName (column1, column2, column3)
ALTER TABLE user ADD INDEX name_city_age (name(10),city,age);
显示索引信息
-- 列出表中的相关的索引信息
SHOW INDEX FROM tableName;
几个关键字
补充知识点
where子句和having子句的区别:
- where子句在
分组之前进行过滤,having子句在分组之后进行过滤 - having子句中可以使用
聚合函数,where子句中不能使用聚合函数 - where子句不能在对数据进行某些
运算后使用,having子句可以 - 很多情况下使用where子句的地方可以使用having子句进行替代
sql语句书写顺序与执行顺序
- sql语句书写顺序:
select from where groupby having orderby - sql语句执行顺序:
from where select group by having order by
过滤 where
select * from exam where name='张飞';
select * from exam where name like '张%';
select * from exam where math > 90;
-- IN 操作符允许我们在 WHERE 子句中规定多个值
select * from exam where math in(75,76,77);
select * from exam where math between 80 and 100;
select * from exam where math > 70 and chinese > 80;
select name 姓名, math+english+chinese 总分 from exam where math+english+chinese > 230;
排序 order by
ORDER BY 语句用于根据指定的列对结果集进行排序
- DESC - 按照降序对记录进行排序
- ASC - 按照顺序(升序)对记录进行排序(默认)
-- Company在表Orders中为字母,则会以字母顺序(升序)显示公司名称;后面跟上 DESC 则为降序显示
SELECT Company, OrderNumber FROM Orders ORDER BY Company
SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC
-- 首先根据Company以降序显示,然后根据OrderNumber以顺序显示
SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC, OrderNumber ASC
-- 对姓张的学生根据总成绩按从高到低的顺序输出
select name 姓名,chinese+math+english 总成绩 from exam where name like '张%' order by 总成绩 desc;
分组查询 group by
-- 对订单表中商品归类后,显示每一类商品的总价
select product,sum(price) from orders group by product;
-- 查询购买了几类商品,并且每类总价大于100的商品
select product 商品名,sum(price)商品总价 from orders group by product having sum(price)>100;
-- 查询单价小于100而总价大于150的商品的名称
select product from orders where price<100 group by product having sum(price)>150;
逻辑运算 and or not
SELECT * FROM Persons WHERE FirstName='Thomas' AND LastName='Carter';
DELETE from meeting where id in (2,3) and user_id in (5,6);
SELECT * FROM Persons WHERE firstname='Thomas' OR lastname='Carter'
-- NOT 操作符总是与其他操作符一起使用,用在要过滤的前面。
SELECT vend_id, prod_name FROM Products WHERE NOT vend_id = 'DLL01' ORDER BY prod_name;
合并结果集 union
合并两个或多个 SELECT 语句的结果集
-- 列出所有在中国表和美国表的不同的雇员名
SELECT E_Name FROM Employees_China UNION SELECT E_Name FROM Employees_USA
-- 列出 meeting 表中的 pic_url,station 表中的 number_station 别名设置成 pic_url 避免字段不一样报错
-- 按更新时间排序
SELECT id,pic_url FROM meeting UNION ALL SELECT id,number_station AS pic_url FROM station ORDER BY update_at;
-- 通过 UNION 语法同时查询了 products 表 和 comments 表的总记录数,并且按照 count 排序
SELECT 'product' AS type, count(*) as count FROM `products` union select 'comment' as type, count(*) as count FROM `comments` order by count;
重命名 as
-- 重命名列名或者表名,语法:select columnName as 列昵称 from tableName as 表昵称
-- 把Employee表命名为 emp,命名一个表之后,你可以在下面用 emp 代替 Employee
SELECT * FROM Employee AS emp
-- 列出表 Orders 字段 OrderPrice 列最大值,结果集列不显示 OrderPrice 显示 LargestOrderPrice
SELECT MAX(OrderPrice) AS LargestOrderPrice FROM Orders
-- 显示表 users_profile 中的 name 列
SELECT t.name from (SELECT * from users_profile a) AS t;
聚合函数
统计个数 count
-- 语法:SELECT COUNT("字段名") FROM "表格名"
SELECT COUNT (Store_Name) FROM Store WHERE Store_Name IS NOT NULL;
-- 统计一个班级共有多少学生
select count(*) from exam;
select count(*) from exam where math > 70;
select count('什么有效的值都可以') as totals from exam;
最值 max/min
-- MAX 函数返回一列中的最大值,NULL 值不包括在计算中
SELECT MAX(OrderPrice) AS LargestOrderPrice FROM Orders
select max(ifnull(chinese,0) + ifnull(english,0) + ifnull(math,0)) from exam;
求和 sum
-- 将符合条件的记录的指定列进行求和操作
select sum(math) from exam;
select sum(math),sum(math)/count(*) 平均分 from exam;
-- sum仅对数值起作用,否则会报错;计算时,只要有null参与计算,整个计算结果都是null;可以用ifnull处理
select sum(ifnull(chinese,0)+ifnull(english,0)+ifnull(math,0)) from exam;
平均值 avg
-- 计算符合条件的记录的指定列的值的平均值
select avg(math) from exam;
select avg(ifnull(chinese,0) + ifnull(english,0) + ifnull(math,0)) from exam;
多表设计与多表查询
外键约束 foreign key
表是用来保存现实生活中的数据的,而现实生活中数据和数据之间往往具有一定的关系,我们在使用表来存储数据时,可以明确的声明表和表之前的依赖关系,命令数据库来帮我们维护这种关系,像这种约束就叫做外键约束。
create table dept(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
dept_id int,
-- 定义外键约束:foreign key(本表的列名) references 引用的表名(引用的表中的列名)
foreign key(dept_id) references dept(id)
);
多表设计
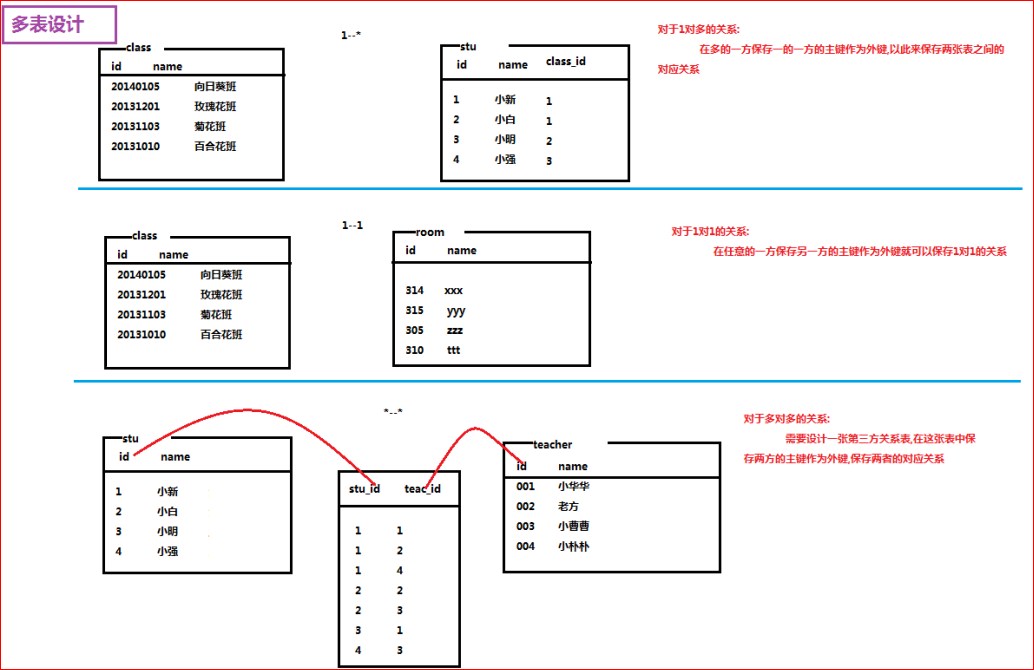
不同场景下的多表设计思路:
- 一对一:在任意一方保存另一方的主键作为外键
- 一对多:在
多的一方保存一的一方的主键做为外键 - 多对多:创建
第三方关系表保存两张表的主键作为外键,保存他们对应关系
多表查询 join
笛卡尔积查询
将两张表的记录进行一个相乘的操作查询出来的结果就是笛卡尔积查询
如果左表有 n 条记录,右表有 m 条记录,笛卡尔积查询出有n*m条记录,其中往往包含了很多错误的数据,所以这种查询方式并不常用。
select * from dept,emp;
内连接查询 inner
-- 查询的是左边表和右边表都能找到对应记录的记录
select * from dept,emp where dept.id = emp.dept_id;
select * from dept inner join emp on dept.id=emp.dept_id;
左/右外连接查询 left/right
-- 左外连接查询:在内连接的基础上,增加左边表有而右边表没有的记录
select * from dept left join emp on dept.id=emp.dept_id;
-- 右外连接查询:在内连接的基础上,增加右边表有而左边表没有的记录
select * from dept right join emp on dept.id=emp.dept_id;
全外连接 union
-- 全外连接查询:在内连接的基础上,增加左边表有而右边表没有的记录,和右边表有而左表表没有的记录
select * from dept full join emp on dept.id=emp.dept_id;
-- mysql 不支持全外连接,我们可以使用 union 关键字模拟全外连接
select * from dept left join emp on dept.id = emp.dept_id
union
select * from dept right join emp on dept.id = emp.dept_id;
多表查询实例
创建表a
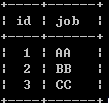
create table a(id int primary key,job varchar(20));
insert into a values(1,'AA'), (2,'BB'), (3,'CC');
select * from a;
创建表b
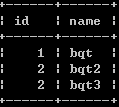
create table b(id int ,name varchar(20) ,foreign key(id) references a(id));
insert into b values(1,'bqt'), (2,'bqt2'), (2,'bqt3');
select * from b;
PS:
被参照的a(id)必须定义为unique才可以被参照,否则报错(逻辑错误)。
插入数据的id必须在被参照的表中已经存在,否则报错(逻辑错误)。
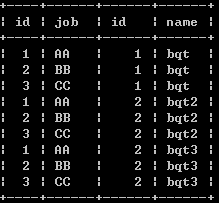
笛卡尔积查询
select * from a,b;
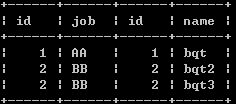
内连接查询
select * from a,b where a.id = b.id;
select * from a inner join b on a.id=b.id;
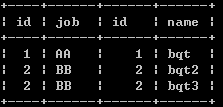
左外连接查询
select * from a left join b on a.id=b.id;
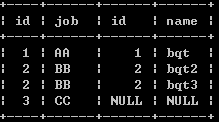
右外连接查询
select * from a right join b on a.id=b.id;
PS:由于右边表参照左边表,所以不存在右边表有而左边表没有的记录。
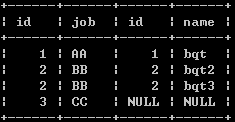
全外连接查询
select * from a left join b on a.id = b.id
union
select * from a right join b on a.id = b.id;
2020-04-07
本文来自博客园,作者:白乾涛,转载请注明原文链接:https://www.cnblogs.com/baiqiantao/p/12650787.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现
2016-04-07 反编译 APKTool jadx