跟我学Elasticsearch(23) 分词器的内部组成以及内置分词器介绍
1、什么是分词器
分词器是在建立倒排索引前的一系列操作,目的是提升召回率,增加能够搜索到的结果的数量
(1) character filter:分词前的预处理,比如过滤html标签,特殊符号转换成英文单词
<span>hello<span> --> hello
I&you --> I and you
(2) tokenizer:分词,比如
hello you and me --> hello, you, and, me
(3) token filter:处理大小写,停用词,同义词,时态,单复数等
dogs --> dog
liked --> like
Tom --> tom
a/the/an --> 干掉
mother --> mom
一个分词器很重要,可以将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引
2、内置分词器介绍
Set the shape to semi-transparent by calling set_trans(5)
上面一句话在不同分词器下的分词结果如下
standard analyzer(es默认分词器):set, the, shape, to, semi, transparent, by, calling, set_trans, 5
simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
language analyzer(特定的语言的分词器,比如说,英语分词器):set, shape, semi, transpar, call, set_tran, 5
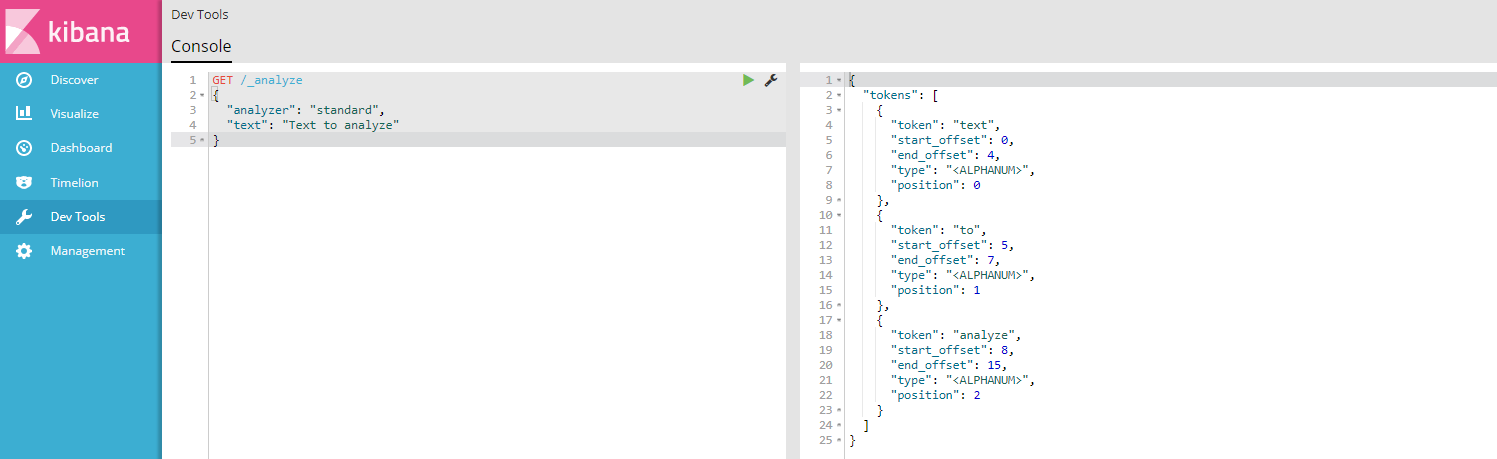
3、测试分词器
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}