跟我学Elasticsearch(8) 图解es集群的shard分配、扩容和容错机制
1、index、document和shard的关系
(1) 1个index的多个document会被均匀分配到多个shard;每个shard都是一个最小工作单元,承载1个index的部分document。
(2) 1个document只存在于某1个primary shard以及其对应的replica shard中,不可能存在于多个primary shard。
(3) replica shard是primary shard的副本,负责容错和分担读请求负载。
(4) primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改。
(5) primary shard默认数量是5,replica shard默认是1(倍),默认1个index有10个shard,其中5个primary shard和5个replica shard。
(6) primary shard和其对应的replica shard不会被分配在同一个es节点上(否则这个节点宕机了,primary shard和replica shard都会丢失,起不到容错的作用),但是可以和其它primary shard对应的replica shard放在同一个节点上。
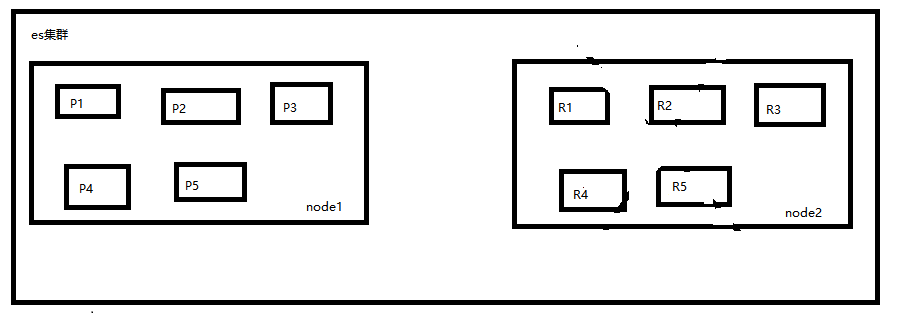
2、单个node下shard是如何分配的
单node下,创建1个index,有5个primary shard和5个replica shard,在分配shard的时候由于primary shard和其对应的replica shard是不能在一个node上的,又没有第二个node去放replica shard,因此只会把5个primary shard分配到这个node上,5个replica shard不会被分配。这个单节点集群是可以正常工作的,但是这个节点一旦宕机,数据会全部丢失,而且集群不可用,无法承载任何请求。
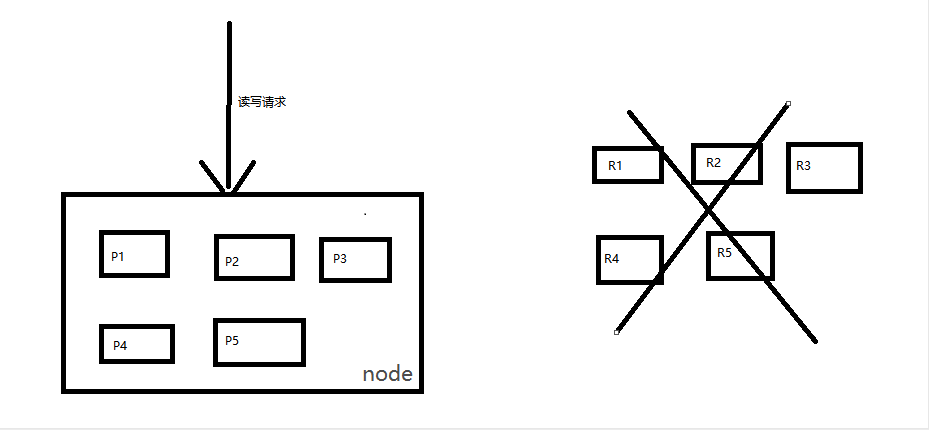
3、2个node下shard是如何分配的
2个node下,会将primary shard和其对应的replica shard分散到两个node去。
写请求会打到primary shard,写入document之后document会被同步到其对应的replica shard中。
读请求会均匀打到primary shard和replica shard,分担读请求负载。
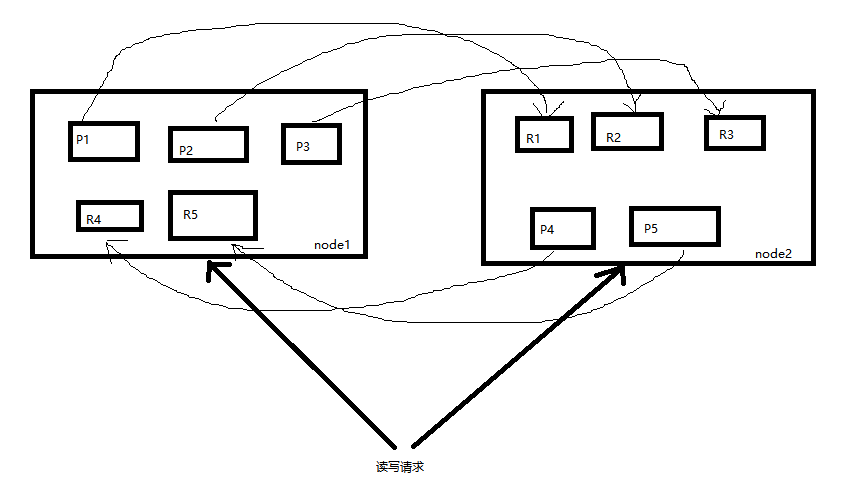
4、node扩容的意义
2个node的时候,每个node上有5个shard,假如有10个node,每个node就只有1个shard。
(1) 每个node有更少的shard,每个node上的IO/CPU/Memory资源就会给每个shard分配更多,每个shard的读写性能当然就更好。整个es集群的吞吐量也会更好。
(2) 2个node的时候如果1个node宕机,就会丢失一半的shard,容错性比较低。10个node的时候如果1个node宕机,只会丢失1个shard,容错性更高。
node多服务器的成本也会增加,所以需要综合考虑成本、吞吐量、容错性。
5、node容错机制(主备切换、数据恢复)
以2个node的es集群来举例,假如1个node宕机了,这个node上的所有shard都会丢失,这时候es会怎么处理呢
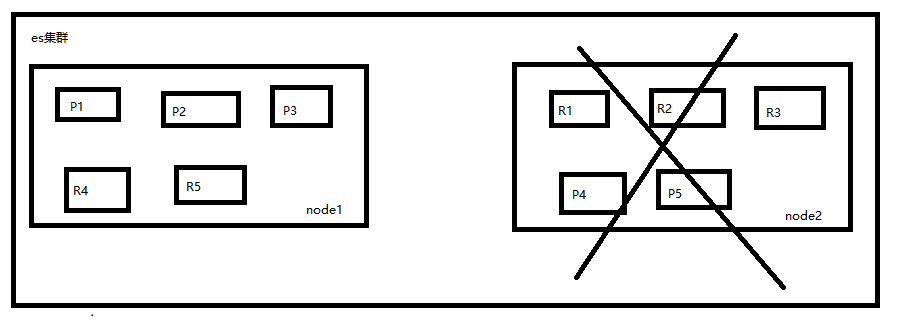
P4和P5丢失了,需要选出其对应的replica shard来作为新的primary shard,于是R4被提升为R4,R5被提升为P5
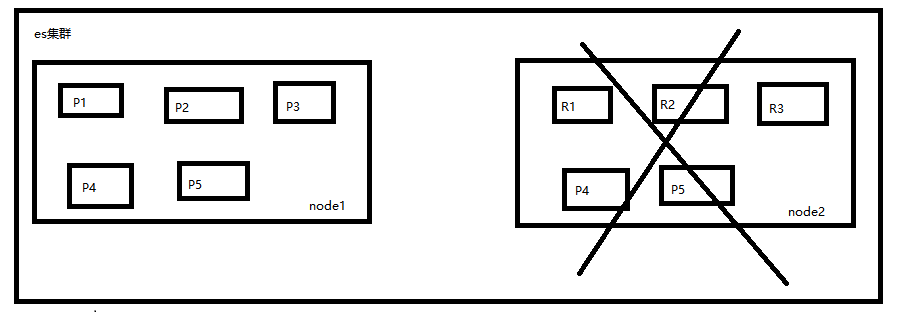
此时primary shard恢复完整,可以正常往这个index写入和读取数据,接着node2宕机后重启,node2检查到原来的P4和P5已经被替代了,于是P4降为R4,P5降为R5作为新的P4、P5的replica shard,同时重启后的node上的replica shard的数据会从其对应的primary shard上同步过来保证primary shard和其对应的replica shard的数据是一致的