
前情提要:
数据分析:把一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究
对象的内在规律
数据分析的三剑客: numpy,pandas,matplotlb
numpy是python语言的一个扩展程序库,支持大量的维度数组与矩阵的运算
,此外,也针对数组的运算,提供了大量的数学函数库
一: 创建ndarray
导包
import numpy as np
1: 创建数组 np.array()
1=>1: 创建一个一维数组
np.array([1,2,3,4,5])
输出:
array([1, 2, 3, 4, 5])
1=>2:创建一个二维数组
in:
np.array([[1,2,3],[4,'a',6],[6,7,8]])
out:
array([['1', '2', '3'],
['4', 'a', '6'],
['6', '7', '8']], dtype='<U11')
注意: numpy的默认的ndarray的所有数据元素的类型是相同的.
如果传进ladies列表中包含不同的类型,则统一为统一类型
优先级:
str>float>int
2:使用np的routines函数创建
包含以下常见创建方法:
2=>1:
np.ones(shape,dtype=None,order='c') 创建纯一的数组
in:
np.ones(shape=(3,3))
out:
Out[9]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
2=>2:
np.zeros(shape,dtpye=None,order='c') 创建一个纯0的数组
in:
np.zeros(shape=(3,3))
out
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
2=>3:
np.full(shape,fill_value,dtype=None,order='c') 创建一个所有数字都一样的列表
in:
np.full(shape=(3,3),fill_value=100)
out:
array([[100, 100, 100],
[100, 100, 100],
[100, 100, 100]])
2=>4:
np.lispace(start,stop,num=50,endpoint=True. retstep=False, dtype=None)
等差数列
np.linspace(1,100,num=20)
2=>5:
np.arange(0,100,step=2)
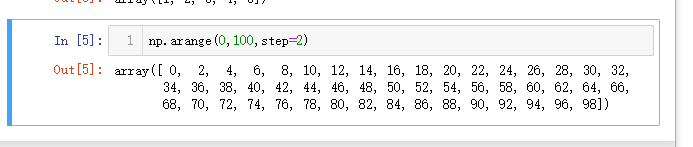
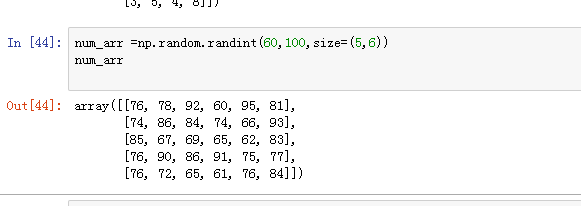
2=>6: 产生随机的整数
np.random.randint(low,high=None,size=None,dtype='l')

2=>7: 标准正太分布

二: ndarray的属性
4个必计参数:ndim ; 维度 shape :形状 (各维度的长度) size :总长度
dtype :元素类型
ndim 维度

size :总长度

dtype 数据类型

三: ndarray的基本操作
1 :索引
一维与列表完全一致 多维时同理

根据索引修改数据
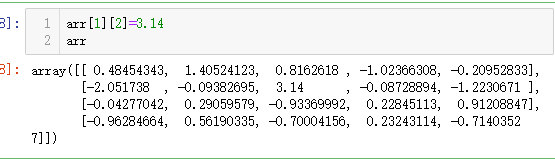
2 切片
一维与列表完全一致 多维时同理
样本数据
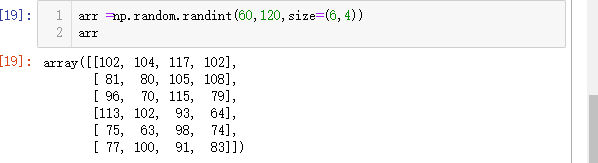
2=>1: 获取前两行

2=>2: 获取前两列
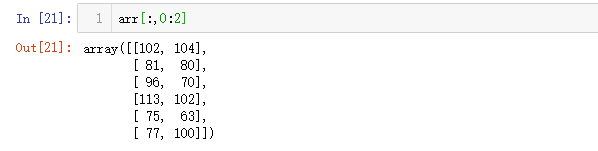
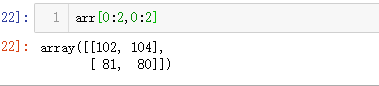
2=>3:获取前两列的前两行
2=>4: 行倒序
2:=>5: 列倒序

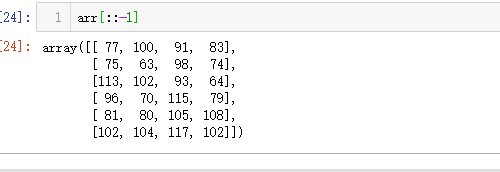
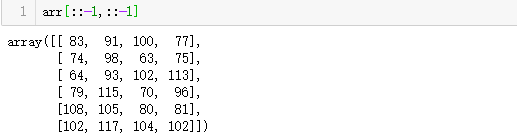
2=>6: 全部倒序
3 变形
使用arr.reshape(),注意参数是一个元组
基本使用
1.将一维数组变成多维数组,或多维数组变成以为数组
1=>1 :一变多

1=>2:多变一:

4: 级联
np.concatenate()
注意: axis=0 轴像
0 表示 竖直方向,
1 表示水平方向
相同轴像的数据维度要相同

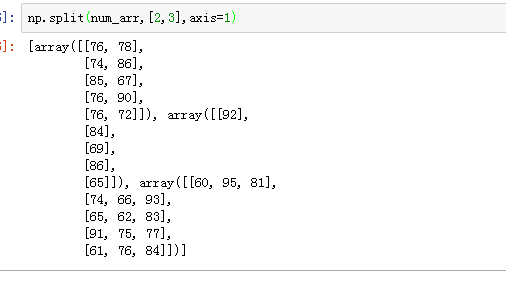
5 切分:
与级联类似,三个函数完成切分工作:
np.split(arr,行/列号,轴):参数2是一个列表类型
注意: axis=1 的时候为竖着切 ,0为横着切
四: ndarray的聚合操作


五 广播机制
ndarray广播机制的三条规则:缺失维度的数组将维度补充为进行运算的数组的维度。缺失的数组元素使用已有元素进行补充。
- 规则一:为缺失的维度补1(进行运算的两个数组之间的维度只能相差一个维度)
- 规则二:缺失元素用已有值填充
- 规则三:缺失维度的数组只能有一行或者一列
例子1 :

