
人工智能初识,百度AI
一.人工智能初识
什么是智能
我们通常把人称为智慧生物,那么"智慧生物的能力"就是所谓的"人工智能"
我们有什么能力?
听,说,看,理解,思考,情感等等....
什么是人工智能
顾名思义就是由人创造的"智慧能力",同样具备,听说看理解等能力
听=语音识别
说=语音合成
看=图像视频文字识别
理解=语言(文字)图像视屏理解等逻辑处理
思考=理解后的逻辑处理
一个简单的问答
问题:你叫什么名字?
答案:我的名字叫栗子
回答者:"听, 看"到问题,通过大脑进行问题的"理解"
回答者获得答案后:"说,写"问题答案给提问者
这里的听就是语音识别,理解就是语言理解
目前的人工智能做了什么?
语音识别:小米的小爱同学,苹果的siri,微软的Cortana
语音合成:小米的小爱同学,苹果的siri,微软的Cortana
图像识别:交通摄像头拍违章,刷脸解锁手机等
视频识别:抖音内容审核,视频社交APP的审核机制
文字识别:从身份证照片提取身份证号码,扫一扫翻译
语义理解:智能问答机器人,也包含小米的小爱同学,苹果的siri,微软的Cortana
我们身边的人工智能
银行办卡刷脸就行
车辆违章有牌就跑不了
违法犯罪路过天眼等于自投罗网
“小爱同学”,”哎~”,”打开电视”,”好的!”
“欢迎使用10010智能语音系统”,”我还有多少话费”,”您的话费余额为0.01元”
扫一扫翻译看不懂的文字(支持26国语言)
二.百度AI
此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径
目前市面上主流的AI技术提供公司有很多,比如百度,阿里,腾讯,主做语音的科大讯飞,做只能问答的图灵机器人等等
这些公司投入了很大一部分财力物力人力将底层封装,提供应用接口给我们,尤其是百度,完全免费的接口
既然百度这么仗义,咱们就不要浪费掉怎么好的资源,从百度AI入手,开启人工智能之旅
开启人工智能技术的大门 : http://ai.baidu.com/

看看我大百度的AI大法,这些技术全部都是封装好的接口,看着就爽
接下来咱们就一步一步的操作一下
注册百度账号
首先进入控制台,注册一个百度的账号(百度账号通用)

开通一下我们百度AI开放平台的授权
然后找到已开通服务中的百度语音

走到这里,想必已经知道咱们要从语音入手了,语音识别和语音合成
创建语音引用
打开百度语音,进入语音应用管理界面,创建一个新的应用
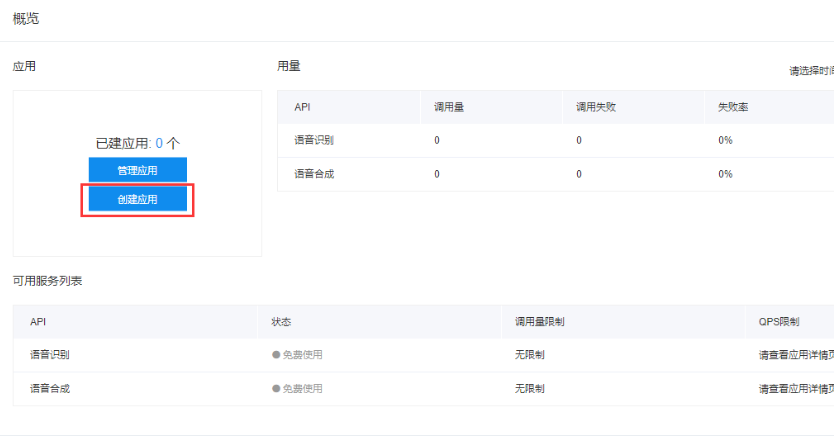
创建语音应用App
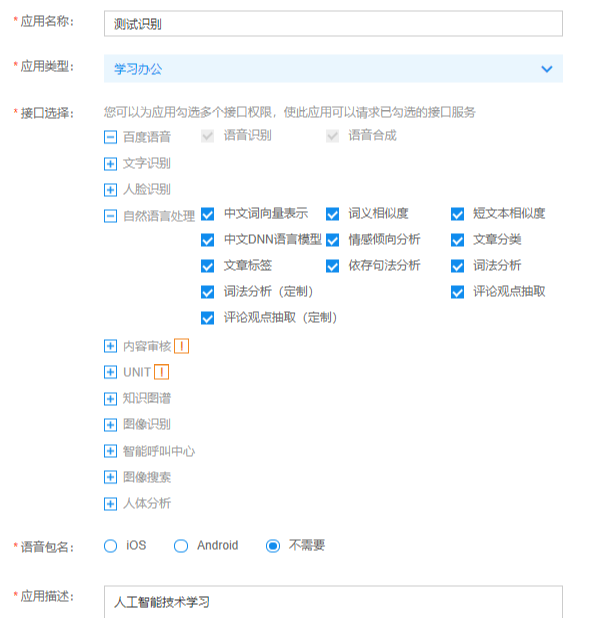
应用名称:可以随意写
应用类型:这里随便选择,暂时选择学习办公
接口选择:默认勾选了语音识别和语音合成。在自然语言处理中,全部选择。下面会用到!
语言包名:选择不需要,因为接下来是用纯python操作!
应用描述:写上一些描述,或者感人的话,都行!
回到应用列表我们可以看到已创建的应用了

这里面有三个值 AppID , API Key , Secret Key 记住可以从这里面看到 , 在之后的学习中我们会用到
好了 百度语音的应用已经创建完成了 接下来 我会用Python 代码作为实例进行应用及讲解
语音合成
安装SDK
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了,这也是为什么我们选择百度人工智能的最大原因
点击左侧的技术文档
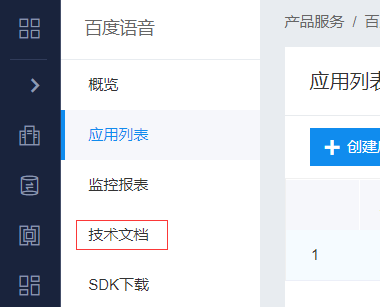
点击左边的语言合成->SDK文档->Python SDK

请严格按照文档里描述的参数进行开发。请注意以下几个问题:
-
合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。切忌文本长度超过限制。
-
语音合成 rest api不限制调用量,但是初始的QPS为100,如果默认配额不能满足您的业务需求,请从控制台中申请提高配额,我们会在两个工作日内完成审批
-
必填字段中,严格按照文档描述中内容填写。
语音合成 Python SDK目录结构
├── README.md ├── aip //SDK目录 │ ├── __init__.py //导出类 │ ├── base.py //aip基类 │ ├── http.py //http请求 │ └── speech.py //语音合成 └── setup.py //setuptools安装
支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。 - 如果已安装setuptools,执行
python setup.py install即可。
打开windows的cmd窗口,输入命令 pip3 install baidu-aip
我已经安装好了,效果如下:
新建AipSpeech
AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipSpeech:
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
打开Pycharm,新建一个目录ai
创建文件 baidu_ai.py
代码如下:
import time from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
将前面提到的AppID,API Key,Secret Key,复制到对应位置。
上面的id和KEY,后5位我改了,复制我的也没有用!呵呵!
请求说明
- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。文本长度不可超过限制
举例,要把一段文字合成为语音文件:
result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
修改 baidu_ai.py
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
执行代码,会看到当前目录出现了一个auido.mp3文件,打开播放器,听一下声音。
我用QQ影音,打开正常
技术上,代码上任何的疑惑,都可以从官方文档中得到答案
baidu-aip Python SDK 语音合成技术文档 : https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
刚才我们做了一个语音合成的例子,就用这个例子来展开说明
先来看第一段代码
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用
AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了
再来看第二段代码:
result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5, }) # 如果上面的三个参数APP_ID,API_KEY,SECRET_KEY填写正确的话,res就是咱们的音频文件流 # 如果返回失败的话,就会报错! print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
返回样例:
// 成功返回二进制文件流 // 失败返回 { "err_no":500, "err_msg":"notsupport.", "sn":"abcdefgh", "idx":1 }
用百度语音客户端中的synthesis方法,并提供相关参数
成功可以得到音频文件,失败则返回一段错误信息
重点看一下 synthesis 这个方法 , 从 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 来获得答案吧
从参数入手分析:
result = client.synthesis( '你好百度', # text: 合成的文本,使用UTF-8编码,请注意文本长度必须小于1024字节 'zh', # lang: 语言,中文:zh 英文:en 1, # ctp: 客户端信息这里就写1,写别的不好使,至于为什么咱们以后再解释 { 'vol': 5, # 合成音频文件的准音量 'spd':4, # 语速 取值0-9,默认为5 中语速 'pit':8, # 语调音调,取值0-9,默认为5 中语调 'per':4, # 发音人选择,0为女生,1为男生,3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女 } )
按照这些参数,从新发起一个语音合成
with open('auido.mp3', 'wb') as f: f.write(result)
语音识别
点击左边的百度语言->语音识别->Python SDK
建议使用pcm,因为它比较好实现。而另外2种语言格式,有非常高的要求,只有专业级别的设备才能录制。它才能达到百度的要求。
哎,每次到这里,我都默默无语泪两行,声音这个东西格式太多样化了,如果要想让百度的SDK识别咱们的音频文件,就要想办法转变成百度SDK可以识别的格式PCM
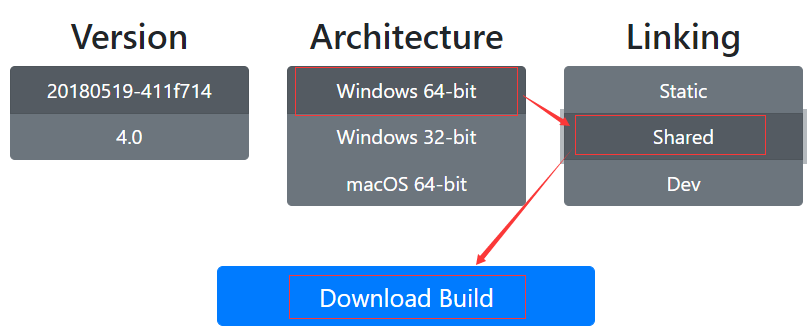
FFmpeg
目前已知可以实现自动化转换格式并且屡试不爽的工具 : FFmpeg 这个工具的下载地址是 : 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w6hk
或者官网下载
http://ffmpeg.org/download.html
点击windows图标,点击Builds

我的电脑是64位系统,选择64位,一定要选择Shared,最后点击下载。
FFmpeg 环境变量配置:
首先你要解压缩,然后找到bin目录,我的目录是 C:\ffmpeg\bin

然后 以 windows 10 为例,配置环境变量
添加环境变量
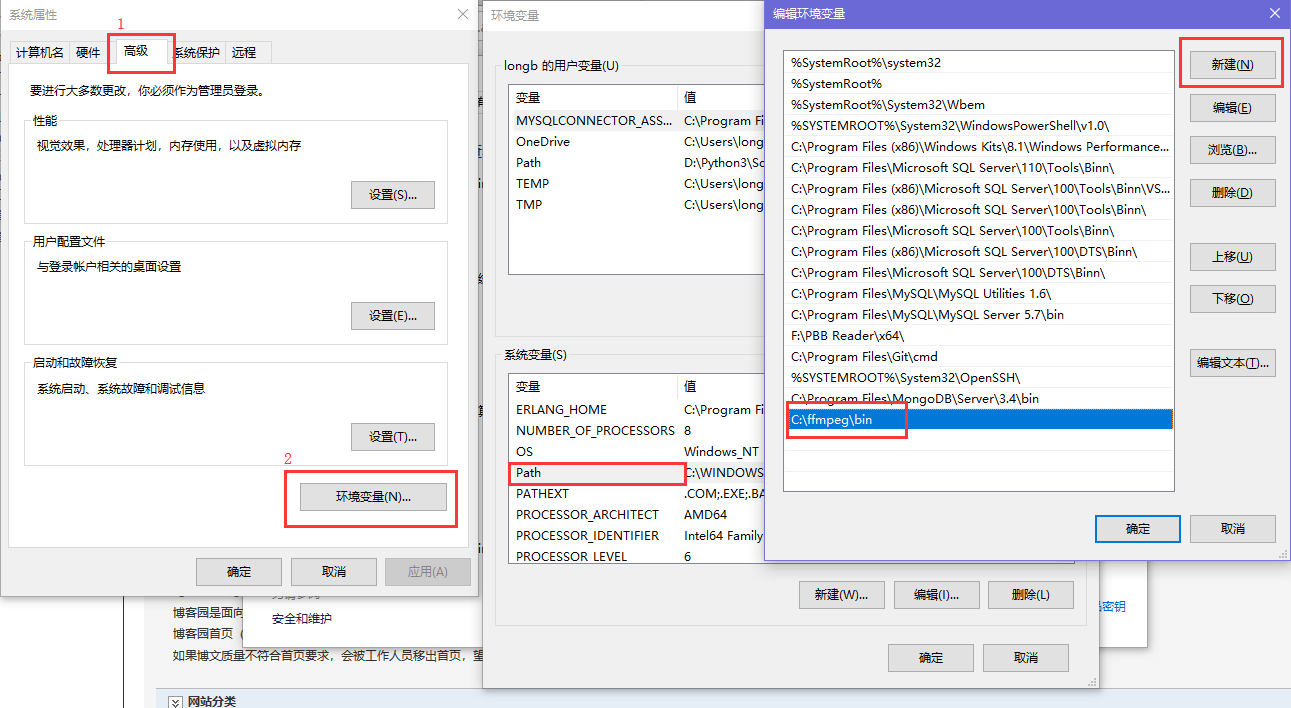
如果没搞明白的话,我也没有办法了,这么清晰这么明白
尝试一下,是否配置成功
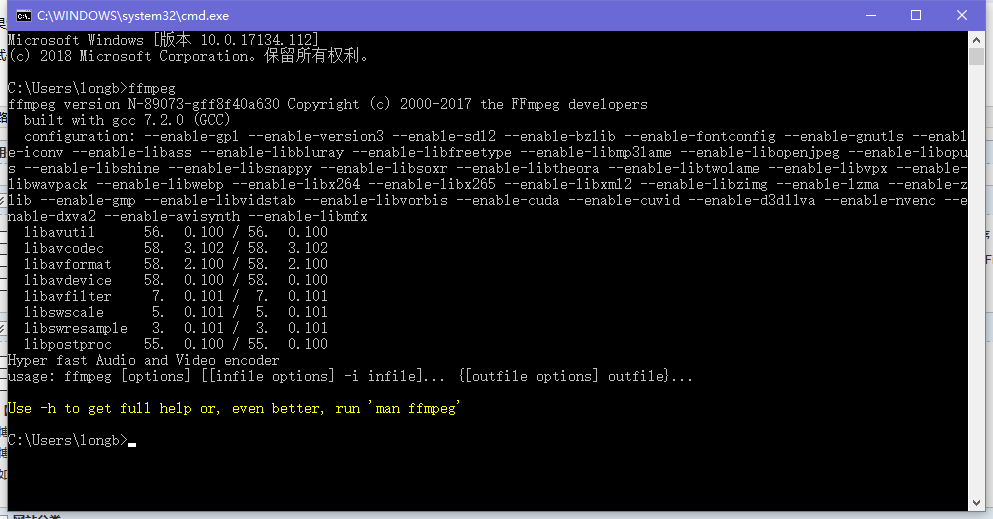
看到这个界面就算配置成功了,配置成功有什么用呢, 这个工具可以将wav wma mp3 等音频文件转换为 pcm 无压缩音频文件
这个时候,一定要关闭Pycharm,否则Pycharm识别不到。
再次开启Pycharm
做一个测试,首先要打开windows的录音机,录制一段音频(说普通话)
现在假设录制的音频文件的名字为 audio.wav 放置在 D:\DragonFireAudio\
然后我们用命令行对这个 audio.wav 进行pcm格式的转换然后得到 audio.pcm
命令是 :
ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
然后打开目录就可以看到pcm文件了
注意事项
如果需要使用实时识别、长语音、唤醒词、语义解析等其它语音功能,请使用Android或者iOS SDK 或 Linux C++ SDK 等。
-
请严格按照文档里描述的参数进行开发,特别请关注原始录音参数以及语音压缩格式的建议,否则会影响识别率,进而影响到产品的用户体验。
-
目前系统支持的语音时长上限为60s,请不要超过这个长度,否则会返回错误。
pcm文件已经得到了,赶紧进入正题吧
请求说明
举例,要对段保存有一段语音的语音文件进行识别:
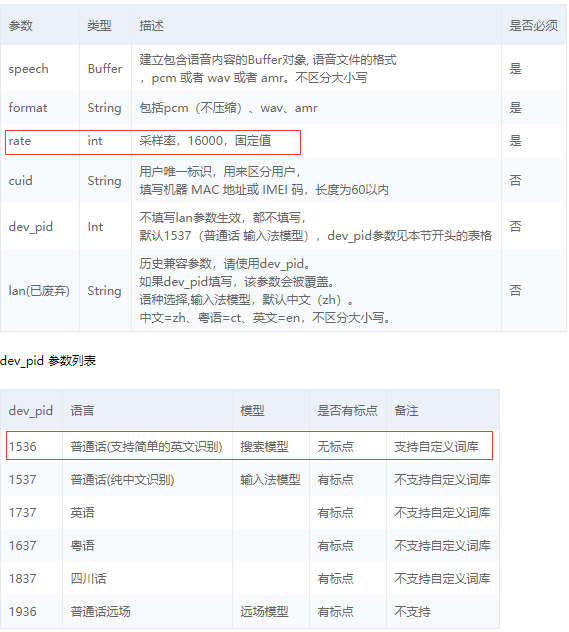
# 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 client.asr(get_file_content('audio.pcm'), 'pcm', 16000, { 'dev_pid': 1536, })
看参数,主要用到的是rate和1536
上图的16000表示采样率
1536表示能识别中文和英文,它的容错率比较高
1537必须是标准的普通话,带点地方口音是不行的。
所以建议使用1536
打开win10自带的录音机,录制一段声音,比如:你叫什么呀
一定要带一个呀字,下面的代码执行会输出10个结果,否则只有一个!
注意:笔记本的麦克风在摄像头的2边,所以录制的时候,一定要对着摄像头!
默认为m4a格式的,重命名为whatyouname.m4a,将文件放入ai目录
修改baidu_ai.py,内容如下:
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) print(a)
注意上面的id和key。文件名为whatyouname.wav
执行文件,输出:
{'sn': '7436726851526824321', 'err_no': 3301, 'err_msg': 'speech quality error.'}
返回错误'err_no': 3301
看文档
找下面对应的3301,表示声音不清晰!

再仔细用播放器,播放一下刚才的声音,挺清晰的呀!
这里报3301不是因为声音不清晰,而是格式不支持。
使用os模块调用ffmpeg实现转码
代码如下:
import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath) os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可 with open(filePath + ".pcm", 'rb') as fp: return fp.read() # 识别本地文件 a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) print(a)
执行输出,效果如下:
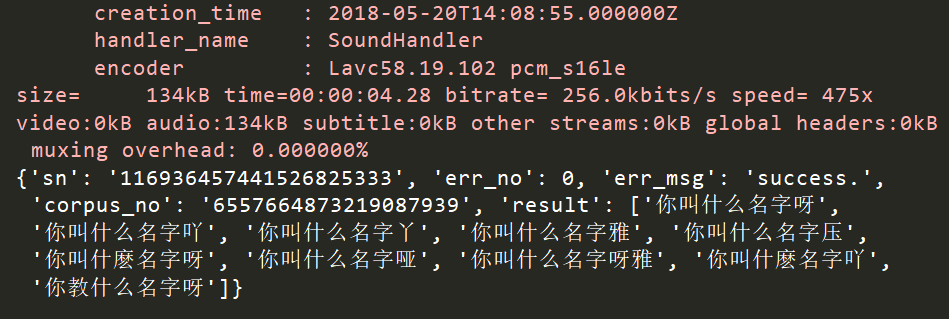
上面红色文件,不是报错,而是转码过程
主要看err_msg是什么,这里显示success,表示成功。
在ai目录下,会多出一个文件whatyouname.m4a.pcm。这个文件才是刚才真正发给百度的语言文件
返回的结果是一个字典,第一个结果,一般是最正确的。取第一个,就可以了!
接下来,就需要从字典取值。字典取值,不要用以下这种方法:
print(a['result'])
为什么呢?如果key不存在,会直接报错!毕竟报错,是要崩溃的...
所以建议使用get方法,将最后一行的print(a),修改为以下内容:
import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath) os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可 with open(filePath + ".pcm", 'rb') as fp: return fp.read() # 识别本地文件 a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) if a.get('result'): print(a.get('result')[0])
执行输出:

从结果上来看就只有一个了。
low版问答系统
whatyouname.m4a,是已经录制好的音频


import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取音频文件函数 def get_file_content(filePath): cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath) os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可 with open(filePath + ".pcm", 'rb') as fp: return fp.read() # 识别本地文件 a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) # if a.get('result'): # print(a.get('result')[0]) q = a.get('result')[0] # 识别音频文件的内容 a = "我不知道你在说什么" if q == "你叫什么名字": a = "我叫小青龙" # 配置音频流,a就是指定的文本 result = client.synthesis(a, 'zh', 1, { 'spd': 4, 'vol': 5, 'pit': 8, 'per': 4 }) # 写入文件 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) os.system("audio.mp3")
os.system("audio.mp3") ,它会自动调用windows的默认音频软件,并打开文件audio.mp3
执行程序,会自动弹出音乐播放器,内容是: 我叫小青龙
如果需要定义别的问题,需要重新录制,并在py文件中定制问题。很low是吧,后续会讲web版的问答系统!
短文本相似度
短文本相似度接口用来判断两个文本的相似度得分。
文档链接:
https://ai.baidu.com/docs#/NLP-Python-SDK/6dfe1b04
text1 = "浙富股份" text2 = "万事通自考网" """ 调用短文本相似度 """ client.simnet(text1, text2); """ 如果有可选参数 """ options = {} options["model"] = "CNN" """ 带参数调用短文本相似度 """ client.simnet(text1, text2, options)
查看参数

短文本相似度返回示例
{ "log_id": 12345, "texts":{ "text_1":"浙富股份", "text_2":"万事通自考网" }, "score":0.3300237655639648 //相似度结果 },
举例:
新建一个文件baidu_nlp.py
from aip import AipNlp APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' nlp_client = AipNlp(APP_ID,API_KEY,SECRET_KEY) """ 调用短文本相似度 """ res = nlp_client.simnet("你叫什么名字","你的名字叫什么") print(res) # 如果相似度达到70% if res.get("score") > 0.7: print("我叫青龙")
执行输出:
{'log_id': 4522060321660798564, 'texts': {'text_2': '你的名字叫什么', 'text_1': '你叫什么名字'}, 'score': 0.864488}
我叫青龙
这里的score是相似度,这里表示86.4%。如果是1,表示100%
那么就可以使用短文本相似度,来回答问题了
修改baidu_ai.py,导入AipNlp,修改问题部分,代码如下:
import os from aip import AipSpeech from aip import AipNlp """ 你的 APPID AK SK """ APP_ID = '11212345' API_KEY = 'pVxdhsXS1BIaiwYYNT712345' SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY) # 读取音频文件函数 def get_file_content(filePath): cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath) os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可 with open(filePath + ".pcm", 'rb') as fp: return fp.read() # 识别本地文件 a = client.asr(get_file_content('whatyouname.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) # if a.get('result'): # print(a.get('result')[0]) q = a.get('result')[0] # 识别音频文件的内容 a = "我不知道你在说什么" # 当相似度达到70%时 if nlp_client.simnet(q, "你的名字叫什么").get("score") >= 0.7: a = "我叫小青龙" # 配置音频流,a就是指定的文本 result = client.synthesis(a, 'zh', 1, { 'spd': 4, 'vol': 5, 'pit': 8, 'per': 4 }) # 写入文件 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) os.system("audio.mp3")
执行程序,会自动打开音频文件,说出: 我叫小青龙
参考文档:https://www.cnblogs.com/DragonFire/p/9208195.html

