第四次作业
作业①:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
输出信息:MYSQL的输出信息如下

1)爬取当当网图书实验
代码
创建数据库(id采用自增,其余和课本相同)
CREATE TABLE books(
bId INT PRIMARY KEY AUTO_INCREMENT,
bTitle VARCHAR(512),
bAuthor VARCHAR(256),
bPublisher VARCHAR(256),
bDate VARCHAR(32),
bPrice VARCHAR(16),
bDetail TEXT
)DEFAULT CHARACTER SET = utf8;
items.py
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
mySpiders.py
import scrapy
from book.items import BookItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = "虞初新志" # 盖其收录《口技》,作者林嗣环是泉州安溪人
source_url = "http://search.dangdang.com/"
def start_requests(self):
url = MySpider.source_url + "?key=" + MySpider.key
yield scrapy.Request(url,self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
# starts-with(@class,'line') class属性以line为开头
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = BookItem()
item['title'] = title.strip() if title else ""
item['author'] = author.strip() if author else ""
item['publisher'] = publisher.strip() if publisher else ""
item['date'] = date.strip() if date else ""
item['price'] = price.strip() if price else ""
item['detail'] = detail.strip() if detail else ""
yield item
link = selector.xpath("//div[@class='paging']/ul/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url,self.parse)
except Exception as e:
print(e)
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class BookPipeline:
# 打开spider爬虫就会执行该函数
def open_spider(self,spider):
print("opened")
try:
self.db = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
passwd="root",
db="crawler",
charset="utf8"
)
# 游标对象
self.cursor = self.db.cursor()
# 删除表
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as e:
print(e)
self.opened = False
# 关闭spider爬虫就会执行该函数
def close_spider(self,spider):
if self.opened:
self.db.commit()
self.db.close()
self.opened = False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
if self.opened:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (%s,%s,%s,%s,%s,%s)", (item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
self.count += 1
except Exception as e:
print(e)
return item
settings.py把下面内容取消注释(实验2,3也一样,不再赘述)
# ITEM_PIPELINES = {
# 'stock2.pipelines.Stock2Pipeline': 300,
# }
run.py(实验2,3也一样,不再赘述)
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
图片
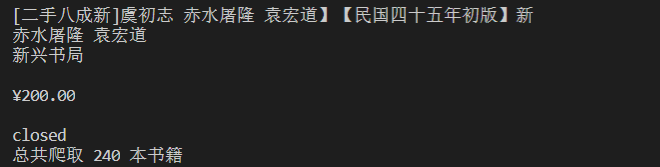
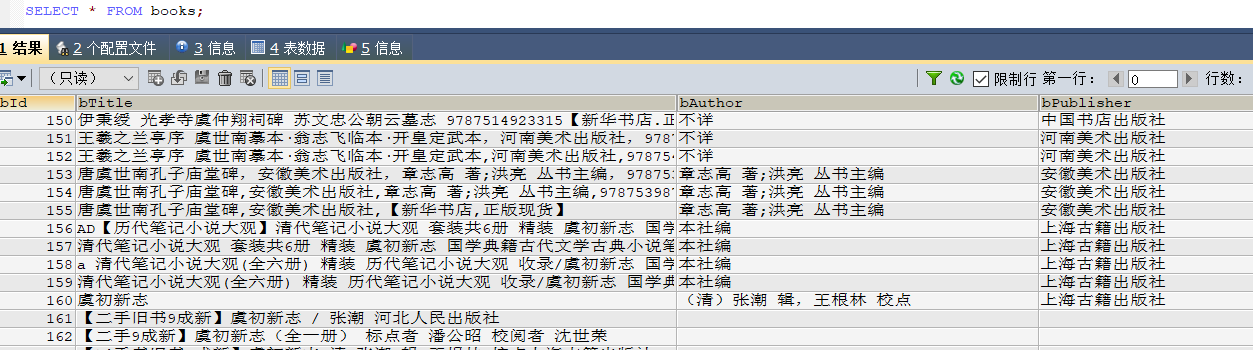
2)心得体会
本实验是Scrapy+Xpath+MySQL数据库存储技术路线的课本样例,使我对使用xpath定位元素、翻页机制、数据库操作有了更深的理解。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名,自行定义
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
1)爬取股票信息实验
代码
创建数据库(全部使用字符型,操作比较方便)
CREATE TABLE stock(
rank VARCHAR(5),
stockCode VARCHAR(10),
stockName VARCHAR(10),
latestPrice VARCHAR(10),
changeRange VARCHAR(10),
changeValue VARCHAR(10),
dealNumber VARCHAR(10),
dealTotal VARCHAR(10),
amplitude VARCHAR(10),
maxPrice VARCHAR(10),
minPrice VARCHAR(10),
today VARCHAR(10),
yesterday VARCHAR(10)
)DEFAULT CHARACTER SET = utf8;
items.py
import scrapy
class Stock2Item(scrapy.Item):
rank = scrapy.Field()
stockCode = scrapy.Field()
stockName = scrapy.Field()
latestPrice = scrapy.Field()
changeRange = scrapy.Field()
changeValue = scrapy.Field()
dealNumber = scrapy.Field()
dealTotal = scrapy.Field()
amplitude = scrapy.Field()
maxPrice = scrapy.Field()
minPrice = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
mySpiders.py
import scrapy
from stock2.items import Stock2Item
from selenium import webdriver
import time
class MySpider(scrapy.Spider):
name = "mySpider"
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
page = 5
def start_requests(self):
yield scrapy.Request(self.url,self.parse)
def parse(self,response):
try:
driver = webdriver.Chrome()
driver.get(self.url)
for i in range(self.page):
# 本网页的翻页不会造成url跳转,所以不能通过url地址拼接,只能通过selenium模拟点击
# 第一次循环不点击"下一页"按钮
if i:
# 第一个sleep是为了等待"下一页"按钮加载出来
time.sleep(3)
# 定位"下一页"按钮并点击
driver.find_element_by_xpath('//*[@id="main-table_paginate"]/a[2]').click()
# 没这行代码可能会出现重复的内容
time.sleep(3)
selector = scrapy.Selector(text=driver.page_source)# page_source不能加括号,被卡🤮了
# 每支股票对应一个tr,利用xpath提取相应信息即可
trList = selector.xpath("//table[@id='table_wrapper-table']/tbody//tr")
item = Stock2Item()
for tr in trList:
item['rank'] = tr.xpath("./td[position()=1]/text()").extract_first()
item['stockCode'] = tr.xpath("./td[position()=2]/a/text()").extract_first()
item['stockName'] = tr.xpath("./td[position()=3]/a/text()").extract_first()
item['latestPrice'] = tr.xpath("./td[position()=5]/span/text()").extract_first()
item['changeRange'] = tr.xpath("./td[position()=6]/span/text()").extract_first()
item['changeValue'] = tr.xpath("./td[position()=7]/span/text()").extract_first()
item['dealNumber'] = tr.xpath("./td[position()=8]/text()").extract_first()
item['dealTotal'] = tr.xpath("./td[position()=9]/text()").extract_first()
item['amplitude'] = tr.xpath("./td[position()=10]/text()").extract_first()
item['maxPrice'] = tr.xpath("./td[position()=11]/span/text()").extract_first()
item['minPrice'] = tr.xpath("./td[position()=12]/span/text()").extract_first()
item['today'] = tr.xpath("./td[position()=13]/span/text()").extract_first()
item['yesterday'] = tr.xpath("./td[position()=14]/text()").extract_first()
yield item
except Exception as e:
print(e)
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class Stock2Pipeline:
# 打开spider爬虫就会执行该函数
def open_spider(self, spider):
print("opened")
try:
self.db = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
passwd="root",
db="crawler",
charset="utf8"
)
self.cursor = self.db.cursor()
self.opened = True
except Exception as e:
print(e)
self.opened = False
# 关闭spider爬虫就会执行该函数
def close_spider(self, spider):
if self.opened:
self.db.commit()
self.db.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into stock(rank,stockCode,stockName,latestPrice,changeRange,changeValue,dealNumber,dealTotal,amplitude,maxPrice,minPrice,today,yesterday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (
item["rank"], item["stockCode"], item["stockName"], item["latestPrice"], item["changeRange"], item["changeValue"], item["dealNumber"], item["dealTotal"], item["amplitude"], item["maxPrice"], item["minPrice"], item["today"], item["yesterday"]))
except Exception as e:
print(e)
return item
图片
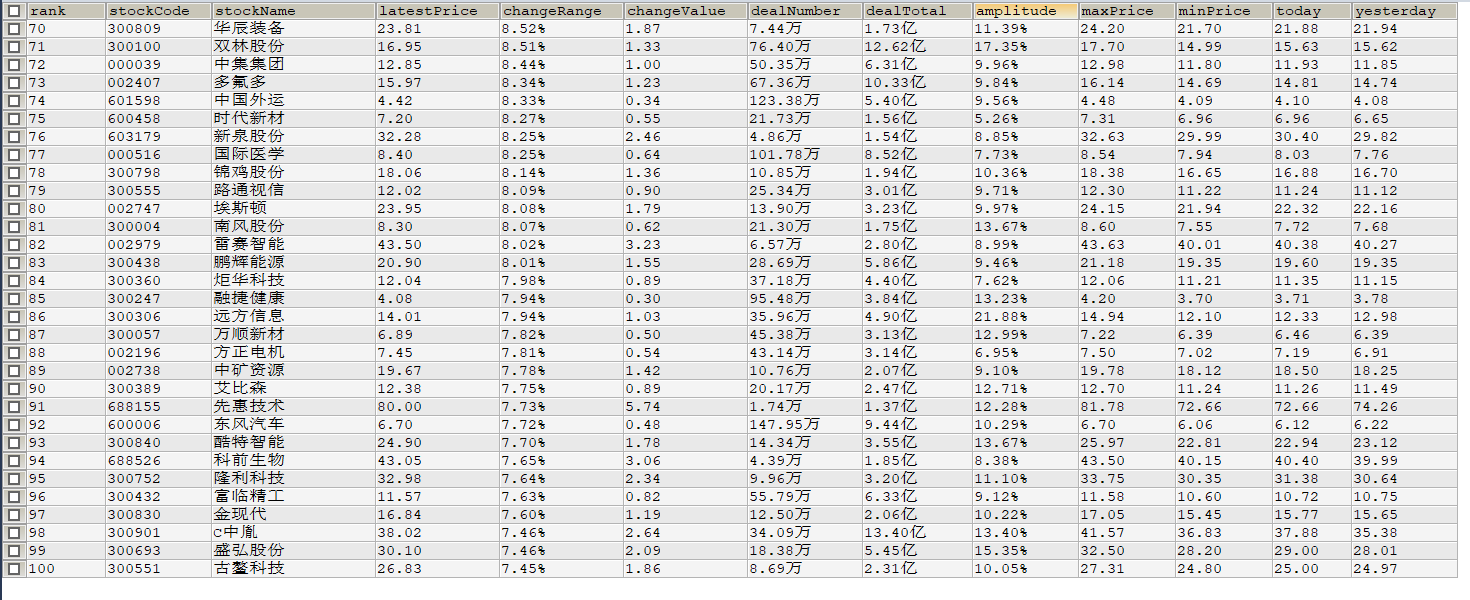
2)心得体会
本实验与实验一差不多,该网站源代码
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
输出信息:MYSQL数据库存储和输出格式
| Id | Currency | TSP | CSP | TBP | CBP | Time |
| 1 | 港币 | 86.60 | 86.60 | 86.26 | 85.65 | 15:36:30 |
| 2 | ... | ... | ... | ... | ... | ... |
1)爬取外汇实验
代码
创建数据库
CREATE TABLE exchange(
Id INT PRIMARY KEY AUTO_INCREMENT,
Currency VARCHAR(10),
TSP VARCHAR(10),
CSP VARCHAR(10),
TBP VARCHAR(10),
CBP VARCHAR(10),
cTime VARCHAR(10)
)DEFAULT CHARACTER SET = utf8;
items.py
import scrapy
class WaihuiItem(scrapy.Item):
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
mySpiders.py
import scrapy
from waihui.items import WaihuiItem
class MySpider(scrapy.Spider):
name = "mySpider"
url = "http://fx.cmbchina.com/hq/"
def start_requests(self):
yield scrapy.Request(self.url,self.parse)
def parse(self,response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
trList = selector.xpath("//div[@id='realRateInfo']//tr")
# 第一个tr是表头信息
for tr in trList[1:]:
item = WaihuiItem()
item['Currency'] = tr.xpath("./td[position()=1]/text()").extract_first().strip()
item['TSP'] = tr.xpath("./td[position()=4]/text()").extract_first().strip()
item['CSP'] = tr.xpath("./td[position()=5]/text()").extract_first().strip()
item['TBP'] = tr.xpath("./td[position()=6]/text()").extract_first().strip()
item['CBP'] = tr.xpath("./td[position()=7]/text()").extract_first().strip()
item['Time'] = tr.xpath("./td[position()=8]/text()").extract_first().strip()
yield item
except Exception as e:
print(e)
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class WaihuiPipeline:
# 打开spider爬虫就会执行该函数
def open_spider(self,spider):
print("opened")
try:
self.db = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
passwd="root",
db="crawler",
charset="utf8"
)
self.cursor = self.db.cursor()
self.opened = True
except Exception as e:
print(e)
self.opened = False
# 关闭spider爬虫就会执行该函数
def close_spider(self,spider):
if self.opened:
self.db.commit()
self.db.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
print(item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"])
self.cursor.execute("insert into exchange(Currency,TSP,CSP,TBP,CBP,cTime) values (%s,%s,%s,%s,%s,%s)", (
item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
except Exception as e:
print(e)
return item
图片
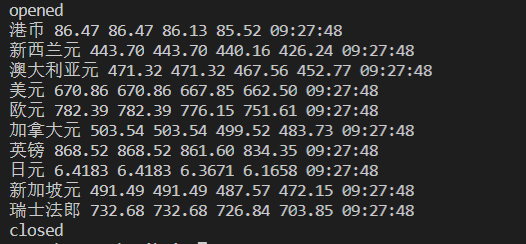

2)心得体会
本实验比前面两个实验简单一点,不涉及翻页,只需简单处理就能得到我们想要的数据。忽然抚尺一下,群响毕绝。撤屏视之,一人、一桌、一椅、一扇、一抚尺而已。
