第一次个人编程作业
| PSP2.1 | Personal Software Process Stages |
预估耗时 (分钟) |
实际耗时 (分钟) |
| Planning | 计划 | 40 | 50 |
| · Estimate | · 估计这个任务需要多少 时间 |
40 | 60 |
| Development | 开发 | 420 | 450 |
| · Analysis | · 需求分析 (包括学习新 技术) |
280 | 300 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 | 60 | 80 |
| · Coding Standard | · 代码规范 (为目前的开 发制定合适的规范) |
60 | 60 |
| · Design | · 具体设计 | 100 | 120 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改 代码,提交修改) |
40 | 60 |
| Reporting | 报告 | 70 | 80 |
| · Test Repor | · 测试报告 | 40 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程 改进计划 |
40 | 60 |
| · 合计 | 1470 | 1670 |
在查阅一些资料后,我就决定使用余弦相似度来做。
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
第二步,列出所有的词。
我,喜欢,看,电视,电影,不,也。
第三步,计算词频。
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
第四步,写出词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
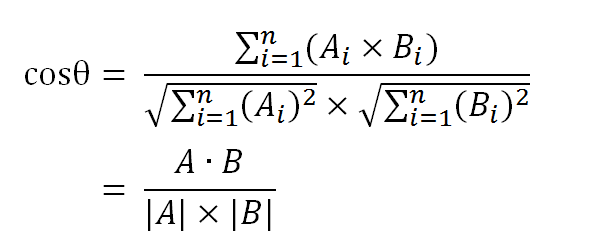
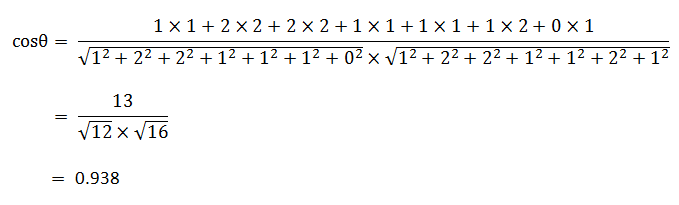
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
首先我是用jieba.lcut将两篇文章分词,并计算对应的词频向量,然而相似度算出来都是0.99+,于是我查看了分词的结果

原来是"我","了","的","在"这种词语频率太高了,我第一反应是降低这些词语的权重,后面查阅了一些资料,发现在NLP中,这些词被称为停用词,于是我从网上下载了一个停用词库,对于在停用词库里的词乘一个较小的比例系数,相似度结果有所好转。
然而,我看到了作业的一条提醒:凡提交的可执行文件、出现下列情况之一者,作业以0分计:
...
尝试读写其他文件
...
,所以这个想法只能放弃。
然后我又通过查资料找到一个jieba.analyse.textrank()函数,格式是keywords = jieba.analyse.textrank(content, topK=5, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v')),
即关键词仅提取地名、名词、动名词、动词。结果挺符合我的期望,但当我import time库去计算程序运行时间的时候,结果时间都是5s以上,放弃+1.
最后我选择使用jieba.analyse.extract_tags()函数,它的allows参数默认为[""],不会过滤词性。而textrank()需要构造图,复杂度高,时间自然就长。虽然extract_tags()的效果会差亿点,不过时间却少了很多,总的来说差强人意。

流程图
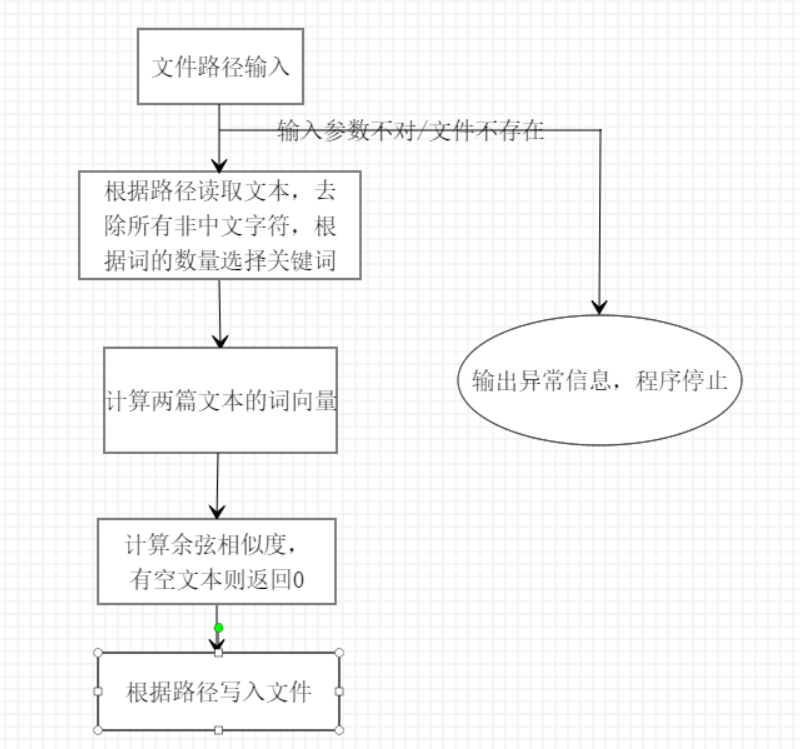
函数介绍(没进行异常处理)
# 余弦相似度算法适合短文本,所以短文本的关键词数/总词数可以尽量大些
def wordsNum(num):
if num<10:
return num
elif num<200:
return ceil(num/2)
else:
return ceil(num/3)
def extractKeywords(path):
s = open(path, 'r', encoding='utf-8')
line = s.read()
# punctuation是从zhon.hanzi导入的包含很多符号的字符串,punctuation += '\n '(有个空格),再用正则表达式替换就能得到一个纯中文字符串
line = re.sub(r"[%s]+" % punctuation, "", line)
# 根据词语数量来确定提取关键词数量,用set去除重复元素
wordSum = jieba.lcut(line)
length = len(set(wordSum))
# 利用jieba.analyse.extract_tags()函数,返回关键词及其权重(需要设置withWeight=True)
keyWords = jieba.analyse.extract_tags(line, wordsNum(length), True)
s.close()
# 原来的keyWords是一个列表,里面的元素都是元组,转成字典有利用后续操作
return dict(keyWords)
# 求两个关键词并集,先用集合去重,返回list是为了方便遍历
def mergeWords(d1, d2):
wordSet = set(d1.keys()).union(d2.keys())
return list(wordSet)
# 求关键词向量
def calVector(d, wordlist):
length = len(wordlist)
vector = [0] * length
keys = d.keys()
for i in range(length):
if wordlist[i] in keys:
vector[i] = d[wordlist[i]]
return vector
# 求余弦相似度
def calCos(v1, v2):
vectorLength = len(v1)
B = sum(v1[i]*v2[i] for i in range(vectorLength))
A1 = sum(i**2 for i in v1)
A2 = sum(i**2 for i in v2)
A = sqrt(A1*A2)
return B/A
# 将结果写入指定文件
def saveData(path,data):
with open(path, 'w') as file_object:
file_object.write(format(data, ".2f"))
file_object.close()
print("写入"+path+"文件完成")
# 主函数
if __name__ == "__main__":
# sys.argv[0] : main.py
filePath1,filePath2,savePath = sys.argv[1],sys.argv[2],sys.argv[3]
# 加上换行和空格,结合正则表达式可去除所有非中文的字符
punctuation += '\n '
# 分别提取两篇文本的关键词及其权重
t1 = extractKeywords(filePath1)
t2 = extractKeywords(filePath2)
# 求出关键词并集
words = mergeWords(t1, t2)
# 分计算词向量
v1 = calVector(t1, words)
v2 = calVector(t2, words)
# 计算余弦相似度
cos = calCos(v1, v2)
# 在指定路径存储数据
saveData(savePath,cos)
print('相似度为 = ' + format(cos, ".2f"))
# 评测结束返回0
sys.exit(0)
使用pycharm的性能分析
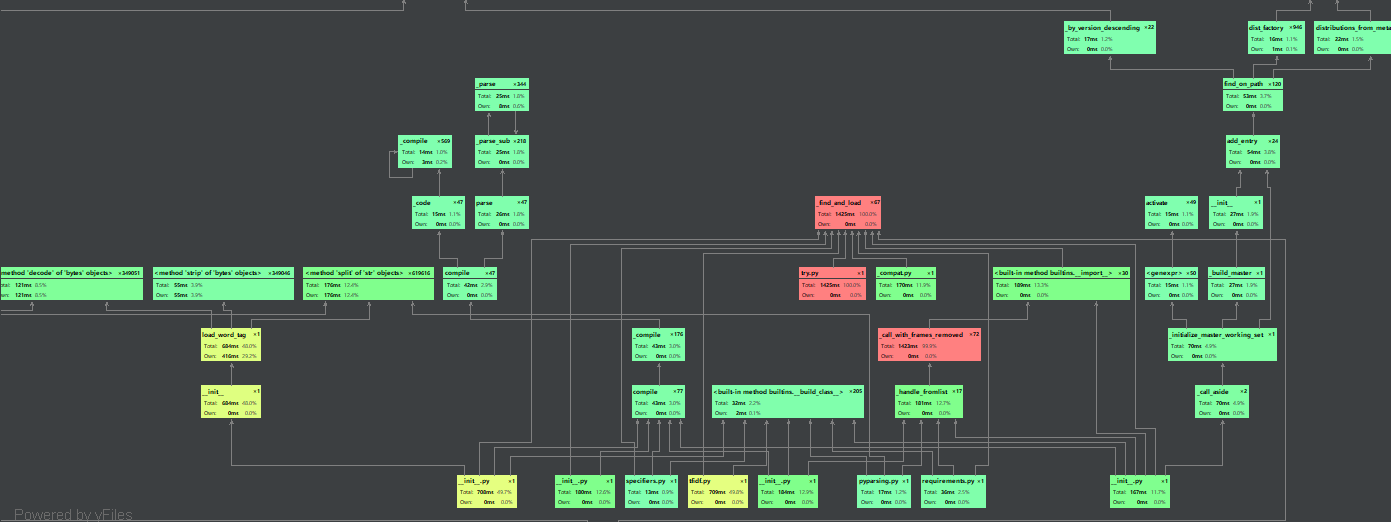
时间花费最多的是提取关键词函数
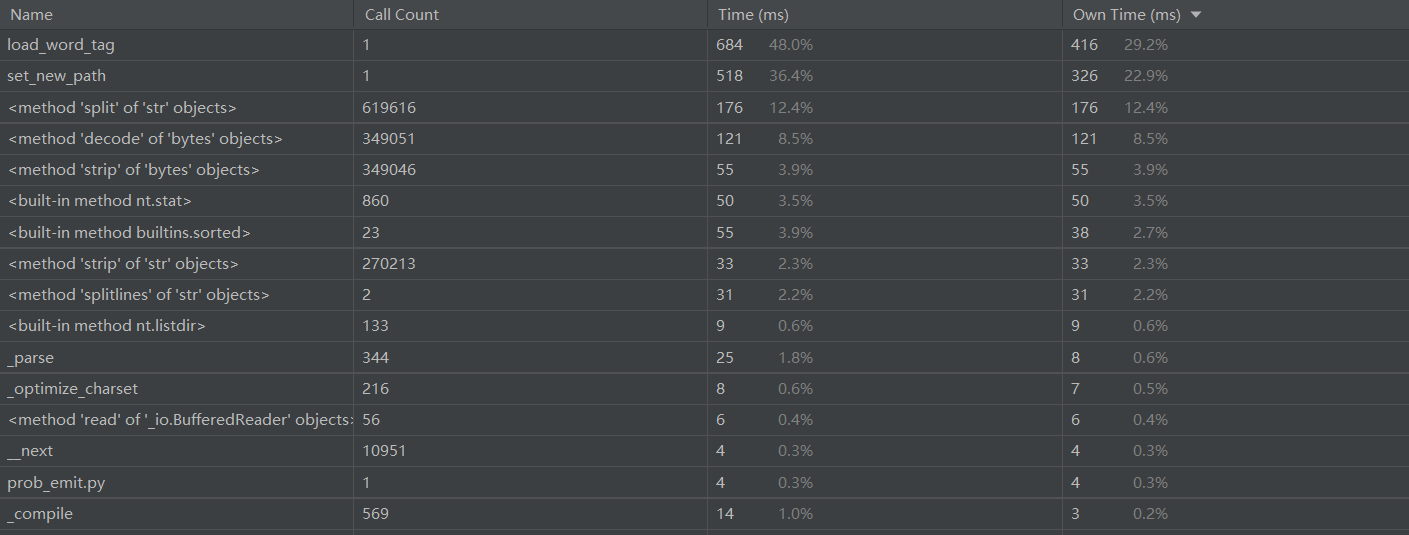
总时间
import unittest
from mainfunc import maintest
# 部分
class MyTest(unittest.TestCase):
orig = 'C:\image\sim_0.8\orig.txt'
folderpath = 'C:\image\sim_0.8\\'
def test_add(self):
fileName = "orig_0.8_add.txt"
cosValue = maintest.calCos(self.orig, self.folderpath+fileName)
print(fileName+"的相似度为:"+format(cosValue, ".3f"))
def test_dis_1(self):
fileName = "orig_0.8_dis_1.txt"
cosValue = maintest.calCos(self.orig, self.folderpath+fileName)
print(fileName+"的相似度为:"+format(cosValue, ".3f"))
def test_dis_3(self):
fileName = "orig_0.8_dis_3.txt"
cosValue = maintest.calCos(self.orig, self.folderpath+fileName)
print(fileName+"的相似度为:"+format(cosValue, ".3f"))
def test_rep(self):
fileName = "orig_0.8_rep.txt"
cosValue = maintest.calCos(self.orig, self.folderpath+fileName)
print(fileName+"的相似度为:"+format(cosValue, ".3f"))
if __name__ == "__main__":
unittest.main()
测试结果

1.命令行输入参数不正确
2.要读取的文件不存在
3.读取的文件是空文本
# 前两个我在主函数用try-exception处理,如果发生异常,就打印错误原因
try:
...
except Exception as e:
print(e)
print("请输入正确的参数")
finally:
# 程序结束,返回0
sys.exit(0)
# 读取的文件是空文本,会出现除0的错误,就返回余弦相似度为0
try:
def calCos(v1, v2):
try:
vectorLength = len(v1)
B = sum(v1[i]*v2[i] for i in range(vectorLength))
A1 = sum(i**2 for i in v1)
A2 = sum(i**2 for i in v2)
A = sqrt(A1*A2)
return B/A
except ZeroDivisionError as e:
print(e)
return 0
1.命令行参数不正确

2.要读取的文件不存在

3.读取的文件是空文本

最终代码重用率为

一开始看到这个题目,就感觉到快,有催人跑的意思,所以我们现在正合适做这样的题。通过此次面向百度编程,我新认识了许多东西,github,性能分析,单元测试等等。很惭愧,too young too simple,sometimes naive!就做了一点微小的工作。最后用鹅城张牧之的一句话勉励一下自己:雄关漫道真如铁,而今迈步从头越。

