
数据库
题号:51-56 题目:6
数据模型
概念数据模型
按照用户的观点对数据和信息建模,用E-R图表示
名词
-
实体:人/物/外部系统。
-
属性:
-
码:唯一标识实体的属性集。
-
域:取值范围。
-
联系:实体之间的关系称为联系
- 一对一
- 一对多
- 多对多
结构数据模型
结构性模式是直接面向数据库的逻辑结构。
分类
- 层次模式:有向数
- 网状模型:图结构
- 关系模型:用二维表格表示实体和实体之间的联系。
三级模式结构
外模式:视图,用户看,最外面可以看到的外观。
概念模式(模式):基本表,逻辑结构。
内模式:数据库内部的存储文件。
两级映像
模式内模式映像:模式和内模式的转换,物理独立性。
外模式模式映像:外模式和模式的转换,逻辑独立性。
关系模式术语
- 关系:一个关系就是一张二维表。
- 元组:一行就是一个元组。
- 属性:每一列就是一个属性。
- 域:取值范围。
- 关系模式:对关系的描述 关系名(属性1,属性2,属性3)
- 码:
- 候选码(键):属性/属性组合,值可以一个元组。
- 主码:在一个关系中可能有多个候选码,从中选择一个作为主码。
- 主属性:包含在任何候选码中的属性称为主属性,否则为非主属性。
- 外码:一个关系中的属性或者属性组不是当前关系的码,但他们是另外一个关系的码,则称为该关系的外码。
- 全码:关系模式的所有属性组是这个关系模式的候选码,称为全码。
- 超码:一个包含码的属性集称为超码。(主属性,非主属性)
完整性约束
实体完整性:关系中主码的值不能 为空或部分为空 。也就是说,主码中属性即主属性不能取空值。
参照完整性:外码的值必须在外码表中对应,或者为空。
用户定义的完整性:指用户对某一具体数据指定的约束条件进行检验。
关系代数
并查角笛卡尔
投影
像影子一样,垂直投影选择的列到新的关系中。
选择
选择满足运算结果的行,水平选择。
$\sigma_{1='5'}$ (第一列中值等于5的行)
$\sigma_{1=2}(第一列等于第二列的行)$
$\sigma_{1>2V1=3}(第一列大于第二列或者第一列等于第三列)$
连接
$\theta $连接‘’
S 和 D的笛卡尔积中取到符合条件的值
等值连接
S 和 D的笛卡尔积中取到相等的值
自然连接
挑选R和S的笛卡尔积中 R.A1 = S.A1 的元组 且去除重复列。
外连接
解决连接后数据丢失的问题
左外连接
自然连接后补全左表内容
右外连接
自然连接后补全右表内容
全外连接
自然连接后,补全左表和右表内容。
转sql语言
投影
选择
笛卡尔积
自然连接
SQL语言
SQL语言的分类
SQL语言按照用途可以分为如下4类:
DDL (Data Definition Language,数据定义语言) :在数据库系统中,每一个数据库、数据库中的表、视图和索引等都是数据库对象。要建立和删除一个数据库对象,都可以通过SQL语言来完成。DDL包括CREATE、ALTER和DROP等。
DML (Data Manipulation Language,数据操纵语i): DML是指用来添加、修改和删除数据库中数据的语句,包括INSERT(插入)、DELETE(删除)和UPDATE(更新)等。
DQL (Data Query Language,数据查询语言) :查询是数据库的基本功能,查询操作通过SQL数据查询语言来实现,例如,用SELECT查询表中的内容。
DCL (Data Control Language,数据控制语言): DCL 包括数据库对象的权限管理和事务管理等。
数据库定义语言
Data Dedinition Language
创建数据库
create database "数据库名"
创建表
create table "表明"{
}
修改表
删除表
drop table "表明"
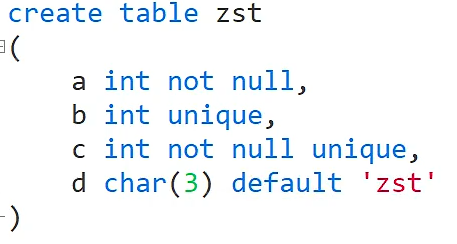
列的完整性约束
not null 是不能为空
unique 是不能重复(也就是唯一约束)
not null unique 是不能为空并且不能重复
default 是设置默认值
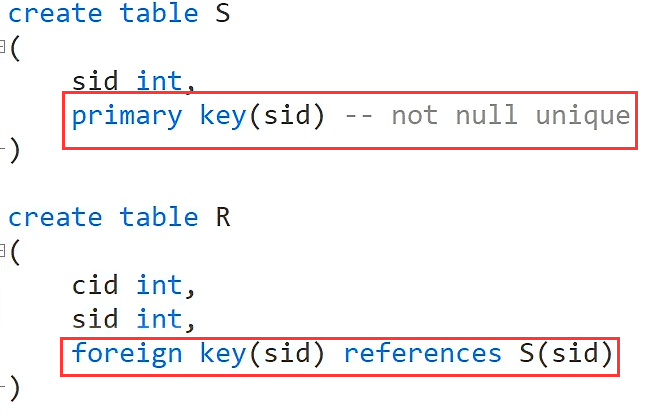
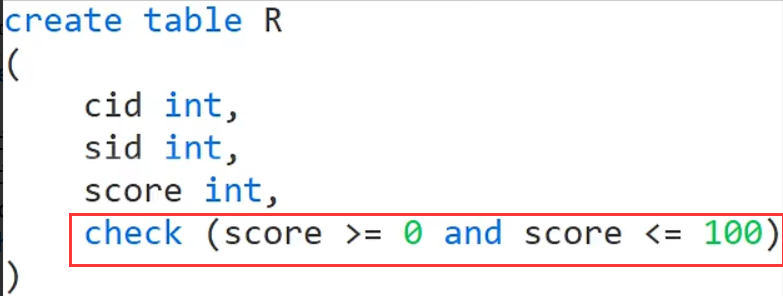
表完整性约束
primary key是主键约束(功能和not null unique 一样)
foreign key是外键约束(上面的外键约束语句意思是对sid设置外键约束并且参照S表中的sid)
check 是用户自定义完整性约束(上面语句意思是检查成绩是否在0-100范围内,也就是在表中插入数据的时候成绩这一列会有一个自动检查成绩范围的约束,不在这个范围就会报错)
数据库操纵语言
查询
select ...
from ...
where ...
group by...
having ...
order by ...
执行顺序
①执行WHERE子句,从表中选取行。
②由GROUPBY对选取的行进行分组。
③执行聚合函数。
④执行HAVING子句选取满足条件的分组(对分组进行筛选)。
select号,号* 100 from student
select 1+1,1-1,1*1,1/1
--投影
select学号,性别from student
select DISTINCT A from teacher
--起别名
select学号as 'SNO',姓名as 'SNAME',性别as 'SEX',班号as 'CLASS"from student
--选择查询
select * from score where S between 60 and 80 --(S>=60 and S<=80)
--模糊匹配
select * from student where 姓名 like '王%' -- like %任意多个 -任意一个
--集合运算符
select * from score where S in (85, 86, 88) --在集合中
select * from score where S not in (85, 86, 88) --不在集合中
--逻辑组合运算符号
and or not
--排序
select * from score order by c asc/desc
select * from score order by 课程号 asc,分数 desc --组合排序
--聚合函数 只有一个结果
select AVG(分数)from score
select COUNT (*) from score
select MIN(分数)from score
select MAX(分数)from score
--分组
--分组+聚合 => 每个组都会得到一个聚合函数的值
select 课程号, SUM(分数), AVG(分数) from score group by 课程号
--连接查询
--内连接
select * from student inner join score on student.'号= score.'号
--自连接
select x.'课程号, x.学号,x.分数
from score x, score y
where
x.'课程号= '3-105' AND
y.'课程号= '3-105'AND
y.'学号= '109' AND
x.'分数>y.分数
order by x.分数 desc
--外连接
left join on
right join on
--子查询(查询的条件是另外一个查询)
属性>any(1,2,3) 只要属性中大于任何一个值都成立
属性>any(1,2,3) 属性中大于所有值才成立
UNION:并
INTERSECT交
EXCEPT:差。
SQL访问控制
视图
从其他表中导出,是一个虚拟表(给视图添加元组就是给原表添加元组)
--创建视图
create view 视图名
as select 查询子句
[with check option 表示以后对当前视图修改插入删除 都会附带这个条件子句 ]
--举例
--创建
create view stuView
as select * from stu where sex = '男'
with check option
--修改 元语句
update set name = '小白' where name = '小红'
--修改 实际执行的语句
update set name = '小白' where name = '小红' and sex = '男'
--删除视图
drop view 视图名
索引
关系描述
一个关系模式应该是一个三元组 R关系名<U属性,F函数依赖>
函数依赖
- 函数依赖:学号 -> 姓名 学号决定姓名 / 姓名被学号依赖
- 非平凡的函数依赖:X->Y $Y\nsubseteq X$ 学号 -> 姓名 姓名$\nsupseteq$学号 左侧属性不包含右侧的
- 平凡函数依赖: (学号,课程号)->课程号 课程号$\nsupseteq$ 课程号 左侧的属性中包含右侧的
- 完全函数依赖:(学号,课程号)-> 成绩 && 学号 $\nrightarrow$ 成绩 && 课程号 $\nrightarrow$ 成绩 左侧的某个属性不能单独决定右侧的
- 部分函数依赖:(学号,课程号)-> 姓名 && 学号$\rightarrow$姓名 => 部分函数依赖 左侧的某个属性可以单独决定右侧属性
- 传递依赖:$A\rightarrow B B\rightarrow C => A \rightarrow C $
- 码:
- 候选码(键):属性/属性组合,值可以一个元组。
- 主码:在一个关系中可能有多个候选码,从中选择一个作为主码。
- 主属性:包含在任何候选码中的属性称为主属性,否则为非主属性。
- 外码:一个关系中的属性或者属性组不是当前关系的码,但他们是另外一个关系的码,则称为该关系的外码。
- 全码:关系模式的所有属性组是这个关系模式的候选码,称为全码。
- 超码:一个包含码的属性集称为超码。(主属性,非主属性)
- 公理系统
- 传递率:$A\rightarrow B B\rightarrow C => A \rightarrow C $
- 合并规则:$A\rightarrow B : A\rightarrow C => A \rightarrow BC $
- 分解规则:$A\rightarrow B : C \subseteq B => A \rightarrow C $
求闭包->主键
选取某个属性求闭包
关系模式的范式
1NF(解决属性项不能再分)
属性为元子 不可分割
不能排除数据冗余和更新异常,可能存在部分函数依赖
数据冗余
修改异常
修改张三的姓名可能导致修改不同步
插入异常
主吗为课程号和学号,不能为空,但我只想插入课程信息。
删除异常
删除课程可能会删除学生信息。
2FN 第二范式(解决部分函数依赖)
每个非主属性都要完全依赖于候选码
解决第一范式的数据冗余和更新异常问题
问题:
解决:
传递函数依赖导致数据冗余,更新异常
3FN(解决传递函数依赖)
解决传递函数依赖
但同时会出现 主属性对候选码的传递函数依赖或部分函数依赖,导致的数据冗余和更新异常
![image-20220826163526432]()
问题
解决
BC范式(消除主属性对非主属性的传递函数依赖 但存在主属性对候选码的传递函数依赖)
消除主属性对候选码的部分函数依赖或传递函数依赖
满足了BC范式的关系必定解决了冗余,更新异常。
总结范式
*技巧
无损连接
无损连接性指的是对关系模式分解时,原关系模式下任一合法的关系实例在分解之后应能通过自然连接运算恢复起来。
数据库的分析与设计
数据库设计步骤(奥尔良法)
需求分析设计
输出需求说明文档,数据字典,数据流程图
概念设计(概念模型设计)
对需求分析的信息进行定义,最好使用ER图。
弱实体
职工$\rightarrow$ 家庭 家庭这个实体必须依赖职工这个实体才能存在。
冲突
对于一个大的ER图可以分解出来多个分ER图,但是分ER图之间可能存在冲突。
-
属性冲突:学生的分数属性 ,正常考试的分数为100 软考证书需要150分
-
命名冲突:相同意义的属性在不同的分E-R图上有着不同的命名,或是名称相同的属性在不同的分E-R图中代表着不同的意义,这些也要进行统一
-
结构冲突:同一实体在不同的分E-R图中有不同的属性,同一对象在某一分E-R图中被抽象为实体,而在另一分E-R图中又被抽象为属性,需要统一。
逻辑设计
ER图 转换 关系模式——> 规范化。
一对一关系转换:
- 添加一个独立的关系模式,任选厂长实体或者仓库实体的主键作为新关系模式的主键。
- 两种转换方式
一对多关系转换
- 添加一个独立的关系模式。主码为多方关系模式的主码
- 给多方添加单方的主码以及关系的属性。
多对多
新添加一个关系模式,主码为两张表的主码组合。
物理设计
逻辑在计算机中的具体实现。
事务
(1)原子性。事务是原子的,要么都做,要么都不做。
(2)一致性。事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。因此,当数据库只包含成功事务提交的结果时,称数据库处于一致性状态。
(3)隔离性。事务相互隔离。当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其他事务都是不可见的。
(4)持久性。一旦事务成功提交,即使数据库崩溃,其对数据库的更新操作也将永久有效。
数据库的备份与恢复
备份方法
- 静态转储和动态转储:静态转储是指在转储期间不允许对数据库进行任何存取、修改操作; 动态转储是在转储期间允许对数据库进行存取、修改操作。因此,转储和用户事务可并发执行。
- 海量转储和增量转储:海量转储是指每次转储全部数据;增量转储是指每次只转储上次转储后更新过的数据。
- 日志文件:在日志执行的过程中
- DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。
- 一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。因此,DBMS利用日志文件来进行事务故障恢复和系统故障恢复,并可协助后备副本进行介质故障恢复。
恢复
- 扫描日志。
- 对事务的更新逆操纵。
- 继续反向扫描日志文件,查找该事务的其他更新,并做同样的处理。
并发(封锁)
排他锁:
事务对象T对A加了排他锁,则A只允许被T读取和修改,且不能加其他锁。
共享锁:
加了共享锁的数据对象,只能对数据对象读取不能修改,其他事务只能继续加共享锁/读取数据。
分布式数据库
分片透明:指用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的
复制透明:指采用复制技术的分布方法,用户不需要知道数据是复制到哪些节点,如何复制的。
位置透明:指用户无须知道数据存放的物理位置
逻辑透明:指用户或应用程序无需知道局部场地使用的是哪种数据模型
共享性:指数据存储在不同的结点数据共享
自治性:指每结点对本地数据都能独立管理
可用性:指当某一场地故障时,系统可以使用其他场地上的副本而不至于使整个系统瘫疾
分布性:指数据在不同场地上的存储

 浙公网安备 33010602011771号
浙公网安备 33010602011771号