


缓存和数据库一致性分析之三种缓存策略
一、背景介绍
公司最近需要对DB使用进行优化,对于访问频繁的接口需要加上缓存。那么这自然会涉及到一个问题:缓存和数据库一致性问题。本文针对这个问题进行讨论,并介绍3种常用的缓存模式。
缓存由于其高并发和高性能的特性,已经在项目中被广泛使用,在缓存的使用中,通常会面临一个更新的问题,当数据源产生变化,如何去更新到数据库与缓存之中,并且尽量保证安全与性能。
二、Cache Aside模式
Cache-Aside可能是项目中最常见的一种模式,它是一种控制逻辑实现在应用程序中的模式。缓存不和数据库直接进行交互,而是由应用程序来同时和缓存以及数据库打交道。Cache-Aside的名字正体现了这个模式,Cache在应用的一旁(aside)。
读数据时:
- 程序需要判断缓存中是否已经存在数据。
- 当缓存中已经存在数据(也就是缓存命中,cache hit),则直接从缓存中返回数据
- 当缓存中不存在数据(也就是缓存未命中,cache miss),则先从数据库里读取数据,并且存入缓存,然后返回数据
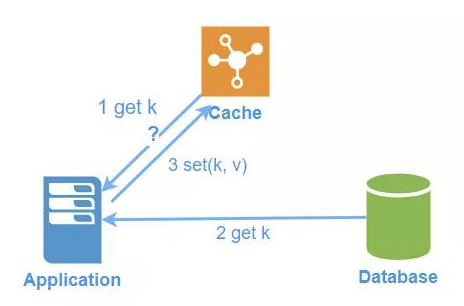
写数据时,有两种可选的方案,但推荐第二种方案:
第一种写数据方案:
- 先更新数据库/缓存
- 再更新缓存/数据库
但这种方案有线程安全的问题,可能出现缓存和数据库不一致。试想有两个写的线程,线程A和线程B
- A写数据库
- B后于A写数据库
- B写缓存
- A写缓存
- 缓存和数据库中的数据不一致,缓存中的是脏数据
要解决线程安全的问题,我们可以加锁,不过实现起来比较麻烦,因此我们不考虑这种写数据方案。
第二种写数据方案(推荐):
- 先更新数据库
- 再删除缓存中对应的数据
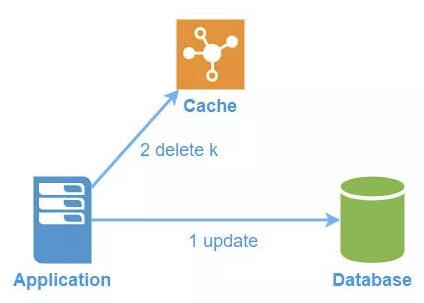
那么这种写方案会有线程安全的问题吗?有,试想一下有两个线程,线程A读,线程B写
- A读数据,由于未命中那么从数据库中取数据
- B写数据库
- B删除缓存
- A由于网络延迟比较慢,将脏数据写入缓存
但是这种情况可能性非常的小,需要同时满足很多条件,几乎不太可能发生,所以我们一般都采用这种写方案。另外可以对缓存中的数据设置合适的过期时间,即使发生的脏数据的情况,也不会发生很长时间。
缓存删除失败的解决方案:
如果更新完数据库之后,删缓存失败,那么就会导致读取的数据仍然是旧数据。此时解决方案就是利用消息队列进行删除的补偿,如图所示。具体的业务逻辑用语言描述如下:
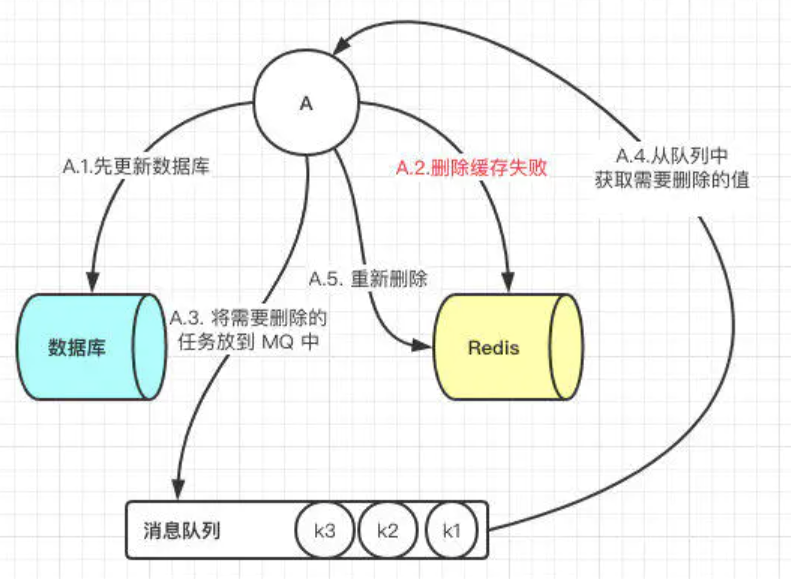
- 请求 A 先对数据库进行更新操作
- 在对 Redis 进行删除操作的时候发现报错,删除失败
- 此时将Redis 的 key 作为消息体发送到消息队列中
- 系统接收到消息队列发送的消息后再次对 Redis 进行删除操作
2.1、应用场景
适用于读多写少的场景。如果写操作较多,则会导致缓存中的数据频繁失效,降低缓存的作用。
2.2、优点
1. 缓存仅仅保存被请求的数据,属于懒加载模式(Lazy Loading),和下文的Write-Through模式相比,避免了任何数据都被写入缓存造成缓存频繁的更新。
2.3、缺点
1. 当发生缓存未命中的情况时,则会比较慢,因为要经过三个步骤:查询缓存,从数据库读取,写入缓存
2. 如果写操作较多,则会导致缓存中的数据频繁失效,降低缓存的作用。
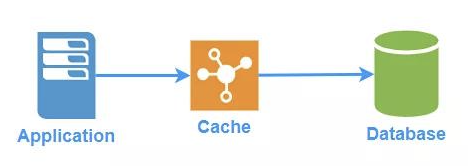
三、Read-Through/Write-Through 模式
这种模式中,应用程序将缓存作为主要的数据源,而数据库对于应用程序是透明的,更新数据库和从数据库的读取的任务都交给缓存来代理了,所以对于应用程序来说,简单很多。
3.1、Read-Through
由缓存配置一个读模块,它知道如何将数据库中的数据写入缓存。在数据被请求的时候,如果未命中,则将数据从数据库载入缓存。
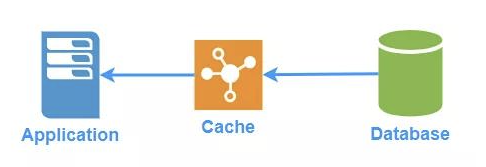
3.2、Write-Through
缓存配置一个写模块,它知道如何将数据写入数据库。当应用要写入数据时,缓存会先存储数据,并调用写模块将数据写入数据库。
3.3、应用场景
本模式适用于读多写少、对数据一致性要求较高的场景。
3.4、优点
1. 缓存不存在脏数据
2. 相比较Cache-Aside懒加载模式,读取速度更高,因为较少因为缓存未命中而从数据库中查找
3. 应用程序的逻辑相对简单
3.5、缺点
1. 缓存的容量使用较高
2. 对于总是写入却很少被读取的应用,那么Write-Through会非常浪费性能,因为数据可能更改了很多次,却没有被读取,白白的每次都写入缓存造成写入延迟。
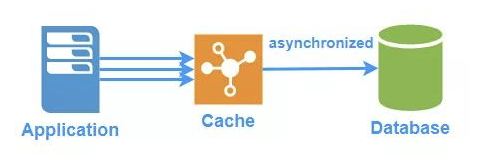
四、Write-Back 模式
本模式又叫做Write-Behind。和Write-Through写入的时机不同,Write-Back将缓存作为可靠的数据源,每次都只写入缓存,而写入数据库则采用异步的方式,比如当数据要被移除出缓存的时候再存储到数据库或者一段时间之后批量更新数据库。
4.1、应用场景
读写效率都非常好,写的时候因为异步存储到数据库,提升了写的效率,适用于读写密集的应用。
4.2、优点
1. 写入和读取数据都非常的快,因为都是从缓存中直接读取和写入。
2. 对于数据库不可用的情况有一定的容忍度,即使数据库暂时不可用,系统也整体可用,当数据库之后恢复的时候,再将数据写入数据库。
3. 降低了DB的压力,可以在流量高峰期以缓存为主,等流量过去之后,再慢慢的把数据同步到DB。
4.3、缺点
1. 有数据丢失的风险,如果缓存挂掉而数据没有及时写到数据库中,那么缓存中的有些数据将永久的丢失了。
五、总结
分布式系统里要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,缓存系统适用的场景就是非强一致性的场景,所以它属于CAP中的AP,BASE理论。
异构数据库本来就没办法强一致,我们只是减少时间窗口,达到最终一致性。每种方案各有利弊,其实每一次的选择都需要我们对于我们的业务进行评估来选择,没有一种技术是对于所有业务都通用的。没有最好的,只有最适合我们的。

