机器学习笔记
四、机器学习
1 深度学习
1.1 线性回归与逻辑回归
1.1.1 线性回归
1.1.1.1 线性回归——二维线性回归方程
1)原理讲述
- 这个应该上过高中的小伙伴都听过,也都用过,那是在高中必修3中出现的知识点,考试也是会考的,可能你想不起那个公式了,但你肯定依稀的记得\(\hat{a},\hat{b}\)这两个东西,还有这个方程 \(\hat{y}=\hat{b}x+\hat{a}\),通过这个方程来预测y的值,\(\hat{a},\hat{b}\)都有它们的计算方式,但是公式有点复杂,老师可能也说过一般试卷上会给,让我们在脑海来重温一下那个知识,这里先给出计算公式:
公式够复杂,但是看着公式里面需要的参数来说其实也没有什么难度,其中公式中最重要的两个参数就是\(\bar{x},\bar{y}\)也就分别是x,和y的平均值,计算很简单.我们要学习一个东西既要知其然也要知其所以然,不妨我们从头来推导出这个公式:
- 首先我假设\(x,y\)为两个具有线性关系的变量,而且我们经有了回归方程模型 \(\hat{y}=\hat{b}x+\hat{a}\),而且现在还有一组原始值(就是训练数据):\((x_1,y_1),(x_2,y_2),\cdots,\cdots,(x_{n-1},y_{n-1}),(x_n,y_n)\),现在我们要通过我们得到的这个模型来计算出预测值,通过想模型中填入训练数据的所有\(x_i\)的值, 我们又可以得到一组预测数据:\((x_1,\hat{y}_1),(x_2,\hat{y}_2),(x_{n-1},\hat{y}_{n-1}),(x_n,\hat{y}_n)\),现在我们要来计算训练数据与真实数据之间的拟合度,如果我们利用下面这个公式来计算拟合度看看会发生什么:
很明显这样是错误的,因为我们预测值和真实值的波动是上下波动的,也就是说误差值可正可负,那么如果我们只有两组测试数据,\(y_1\)与\(\hat{y}_1\) 之差为 -5,\(y_2\)与\(\hat{y}_2\) 之差为 +5,那么通过这个公式一计算你会发现误差为0,也就是说预测值和真实值是完全拟合的,但是通过我们人去看显然波动非常大.所以我们得改进一下公式变为这样:
这样一来就算是负的误差通过平方后也会变成正的,所以在叠加时也不会出现正负抵消的情况了.
再推导线性回归方程前我们先来证明一上面求\(\hat{b}\)为什么可以这样变形,也就是下面两个等式为什么成立(因为这两个等式在推导线性回归方程时会用到):
- 等式一: \(\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}=\displaystyle \sum_{i=1}^n{x_iy_i-n\bar{x}\bar{y}}\)
证明:
将等式左边展开
\(=(x_1-\bar{x})(y_1-\bar{y})+(x_2-\bar{x})(y_2-\bar{y})+\cdots+(x_n-\bar{x})(y_n-\bar{y})\)
\(=(x_1y_1-x_1\bar{y}-\bar{x}y_1+\bar{x}\bar{y})+(x_2y_2-x_2\bar{y}-\bar{x}y_2+\bar{x}\bar{y})+\cdots+(x_ny_n-x_n\bar{y}-\bar{x}y_n+\bar{x}\bar{y})\)
合并同类项:
\(=(x_1y_1+x_2y_2+\cdots+x_ny_n)-(x_1\bar{y}+x_2\bar{y}+\cdots+x_n\bar{y})-(\bar{x}y_1+\bar{x}y_2+\cdots+\bar{x}y_n)+n\bar{x}\bar{y}\)
\(=\displaystyle \sum_{i=1}^n{x_iy_i}-n\bar{y}(\frac{x_1+x_2+\cdots+x_n}{n})-n\bar{x}(\frac{y_1+y_2+\cdots+y_n}{n})+n\bar{x}\bar{y}\)
∵ \(\bar{x},\bar{y}\)分别代表所有变量x和y的平均值
∴原式\(=\displaystyle \sum_{i=1}^n{x_iy_i}-n\bar{x}\bar{y}-n\bar{x}\bar{y}+n\bar{x}\bar{y}\)
\(=\displaystyle \sum_{i=1}^n{x_iy_i-n\bar{x}\bar{y}}=\)等式右端
证闭 - 等式二:\(\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}=\displaystyle \sum_{i=1}^n{x_i^2-n\bar{x}^2}\)
证明:
将等式左边展开
\(=(x_1-\bar{x})^2+(x_2-\bar{x})^2+\cdots+(x_n-\bar{x})^2\)
\(=(x_1^2-2x_1\bar{x}+\bar{x}^2)+(x_2^2-2x_2\bar{x}+\bar{x}^2)+\cdots+(x_n^2-2x_n\bar{x}+\bar{x}^2)\)
合并同类项
\(=(x_1^2+x_2^2+\cdots+x_n^2)-2\bar{x}(x_1+x_2+\cdots+x_n)+n\bar{x}^2\)
\(=\displaystyle \sum_{i=1}^n{x_i^2} - 2n\bar{x}(\frac{x_1+x_2+\cdots+x_n}{n})+n\bar{x}^2\)
\(=\displaystyle \sum_{i=1}^n{x_i^2} - 2n\bar{x}^2+n\bar{x}^2\)
\(=\displaystyle \sum_{i=1}^n{x_i^2} - n\bar{x}^2=\)等式右端
证闭 - 推导线性回归方程:
有了前面两个等式现在我们就可以来推导回归方程的来龙去脉了.
证明:
∵ \(\displaystyle \lambda=\sum_{i=1}^n{(y_i-\hat{y}_i)^2},\hat{y}=\hat{b}x+\hat{a}\)
∴\(\displaystyle \lambda=\sum_{i=1}^n{(y_i-\hat{b}x_i-\hat{a})^2}\)
展开得:
\(\lambda=(y_1-\hat{b}x_1-\hat{a})^2+(y_2-\hat{b}x_2-\hat{a})^2+\cdots+(y_n-\hat{b}x_n-\hat{a})^2\)
\(=[y_1-(\hat{b}x_1+\hat{a})]^2+[y_2-(\hat{b}x_2+\hat{a})]^2+\cdots+[y_n-(\hat{b}x_n+\hat{a})]^2\)
\(=[y_1^2-2y_1(\hat{b}x_1+\hat{a}))+(\hat{b}x_1+\hat{a}))^2]+[y_2^2-2y_2(\hat{b}x_2+\hat{a}))+(\hat{b}x_2+\hat{a}))^2]+\cdots+[y_n^2-2y_n(\hat{b}x_n+\hat{a}))+(\hat{b}x_n+\hat{a}))^2]\)
\(=(y_1^2+y_2^2+\cdots+y_n^2)-\{[2y_1(\hat{b}x_1+\hat{a})-(\hat{b}x_1+\hat{a})^2]+\cdots+[2y_n(\hat{b}x_n+\hat{a})-(\hat{b}x_n+\hat{a})^2]\}\)
\(=\displaystyle \sum_{i=1}^n{y_i^2}-\{[2y_1(\hat{b}x_1+\hat{a})-(\hat{b}x_1+\hat{a})^2]+\cdots+[2y_n(\hat{b}x_n+\hat{a})-(\hat{b}x_n+\hat{a})^2]\}\)
\(=\displaystyle \sum_{i=1}^n{y_i^2}-[(2\hat{b}y_1x_1+2\hat{a}y_1-\hat{b}^2x_1^2-2\hat{a}\hat{b}x_1-\hat{a}^2)+\cdots+(2\hat{b}y_nx_n+2\hat{a}y_n-\hat{b}^2x_n^2-2\hat{a}\hat{b}x_n-\hat{a}^2)]\)
整理并合并同类项:
\(=\displaystyle \sum_{i=1}^n{y_i^2} -2\hat{b}\sum_{i=1}^n{x_iy_i}-2\hat{a}\sum_{i=1}^n{y_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}+2\hat{a}\hat{b}\sum_{i=1}^n{x_i}+n\hat{a}^2\)
整理得:
\(=\displaystyle \sum_{i=1}^n{y_i^2}-2n\hat{a}\left(\frac{\displaystyle \sum_{i=1}^n{y_i}}{n}-\frac{\displaystyle \hat{b}\sum_{i=1}^n{x_i}}{n}\right)-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}+n\hat{a}^2\)
\(=\displaystyle \sum_{i=1}^n{y_i^2}-2n\hat{a}\left(\bar{y}-\hat{b}\bar{x}\right)-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}+n\hat{a}^2\)
合并同类项:
\(=\displaystyle n\left[\hat{a}^2 -2\hat{a}\left(\bar{y}-\hat{b}\bar{x}\right)\right]+ \sum_{i=1}^n{y_i^2}-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}\)
通过完全平方公式,对方括号内的元素进行配方:
\(=\displaystyle n\left[\hat{a}^2 -2\hat{a}\left(\bar{y}-\hat{b}\bar{x}\right)+\left(\bar{y}-\hat{b}\bar{x}\right)^2-\left(\bar{y}-\hat{b}\bar{x}\right)^2\right]+ \sum_{i=1}^n{y_i^2}-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}\)
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2-n\left(\bar{y}-\hat{b}\bar{x}\right)^2+ \sum_{i=1}^n{y_i^2}-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}\)
展开第二项:
\(\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2-n\bar{y}^2+2n\hat{b}\bar{x}\bar{y}-n\hat{b}^2\bar{x}^2+ \sum_{i=1}^n{y_i^2}-2\hat{b}\sum_{i=1}^n{x_iy_i}+\hat{b}^2\sum_{i=1}^n{x_i^2}\)
整理一下:
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+ \left(\sum_{i=1}^n{y_i^2}-n\bar{y}^2\right)-\left(2\hat{b}\sum_{i=1}^n{x_iy_i}-2n\hat{b}\bar{x}\bar{y}\right)+\left(\hat{b}^2\sum_{i=1}^n{x_i^2}-n\hat{b}^2\bar{x}^2\right)\)
提取公因子:
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+ \left(\sum_{i=1}^n{y_i^2}-n\bar{y}^2\right)-2\hat{b}\left(\sum_{i=1}^n{x_iy_i}-n\bar{x}\bar{y}\right)+\hat{b}^2\left(\sum_{i=1}^n{x_i^2}-n\bar{x}^2\right)\)
代入等式一,等式二进行代换:
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+ \sum_{i=1}^n{\left({y_i}-\bar{y}\right)^2}-2\hat{b}\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}+\hat{b}^2\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}\)
合并变换:
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+ \sum_{i=1}^n{\left({y_i}-\bar{y}\right)^2}+\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}\left[\hat{b}^2-\frac{2\hat{b}\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}\right]\)
通过完全平方公式对最后一项配方:
\(=\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+ \sum_{i=1}^n{\left({y_i}-\bar{y}\right)^2}+\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}\left\{\hat{b}^2-\frac{2\hat{b}\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}+\left[\frac{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}\right]^2\right\}-\frac{\left[\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}\right]^2}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}\)
整理得:
\(\lambda =\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}\left[\hat{b}-\frac{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}\right]^2-\frac{\left[\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}\right]^2}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}+ \sum_{i=1}^n{\left({y_i}-\bar{y}\right)^2}\)
因为现在我们是要求\(\hat{a},\hat{b}\)所以不含有\(\hat{a},\hat{b}\)的项全部看做常数即可,那么等式可以变形为:
\(\lambda =\displaystyle n\left[\hat{a}-\left(\bar{y}-\hat{b}\bar{x}\right)\right]^2+\displaystyle t_1\left[\hat{b}-\frac{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})(y_i-\bar{y})}}{\displaystyle \sum_{i=1}^n{(x_i-\bar{x})^2}}\right]^2-t_2+ t_3\)
因为 \(\lambda\) 为误差系数,那么越趋近于0表明拟合程度越好,即我们需要求:
然后根据方程可以知道,前两项都有平方,所以为非负数,所以前两项如果为0,那么 \(\lambda\) 的值就能达到最小.所以解方程即可得到:
2)代码实现
- 有了公式再来使用代码实现就很简单了,这里我们先定义一个训练模型的函数,也就是求\(\hat{a},\hat{b}\)的值:
import matplotlib.pyplot as plt
import numpy as np
def train_model(x_data,y_data):
x_size = np.size(x_data)
y_size = np.size(y_data)
mean_x = np.mean(x_data)
mean_y = np.mean(y_data)
# 求b帽
b = np.sum((x_data-mean_x)*(y_data-mean_y))/np.sum(np.power(x_data - mean_x,2))
# 求a帽
a = mean_y - b*mean_x
return a,b
- 随机生成数据:
# 从1到30 均匀的分成10份
x = np.linspace(1,30,10)
# 定义原数据,也就是真实的y值,为了模拟真实情况,所以加上随机值进行波动
y = x*10 + 5 + np.random.randint(-100,100,10)
- 训练模型并生成训练数据:
a,b = train_model(x,y)
y_ = b*x+a
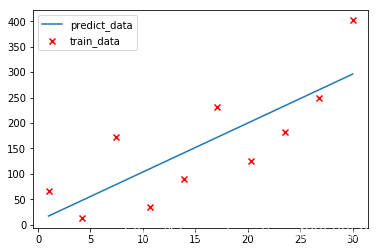
- 原数据和预测数据一起画在图中:
plt.scatter(x,y,c="r",marker="x",label="train_data")
plt.plot(x,y_,label="predict_data")
plt.legend()
1.1.1.2 线性回归——最小二乘法
1)公式推导
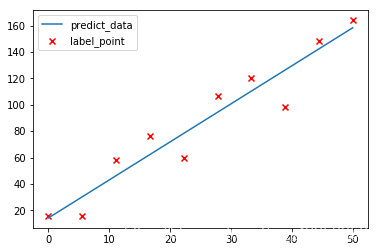
- 假如现在有一堆这样的数据\((x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\),然后我们已经通过某种方式得到了数据所对应的模型\(\hat{y}=\theta_0+\theta_1x\),但是因为 \(\hat{y}\) 毕竟是通过训练模型所得到的预测值,所以 \(\hat{y}\) 与 \(y\) 之间必定存在误差如图所示:
也就是说存在一个这样的等式 \(\omega=\hat{y}-y\) 其中 \(\omega\) 的值代表误差值.现在不妨我们再来将训练数据换一下变成\((x_{11},x_{12},\dots,x_{1m},y_1),(x_{21},x_{22},,\dots,x_{2m},y_1),\dots,(x_{n1},x_{n2},\dots,x_{nm},y_n)\)这里有n项数据,其中每项数据的前 m 个数据代表特征值,最后的一个数据代表标签值(也就是真实的 y 值),对这个数据我们通过线性模型也可以将数据对应的模型写出来:\(\hat{y}=\theta_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_mx_m\)不妨简化一下换成矩阵的形式表示:
其中\(\theta=\begin{bmatrix}\theta_0 \\ \theta_1 \\ \vdots \\ \theta_m \end{bmatrix},x_i=\begin{bmatrix}x_{i0}\\x_{i1}\\ \vdots\\x_{im}\end{bmatrix},x_{i0}=1\),我们再把 \(\hat{y}\) 换一个符号表示:
上面这个函数方程即表示我们的拟合曲线,再结合我们前面分析的误差结论可知(因为误差值可正可负,这里加减就无所谓了):
等式中的 右端项 \(y_i\) 代表真实的标签值,等式的左端项 \(\theta^Tx_i+\omega_i\) 就代表预测值加上误差值
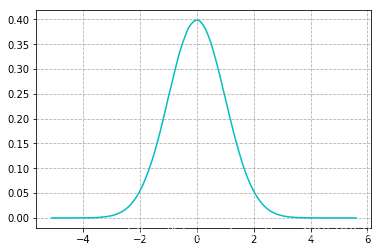
上图这个图应该很眼熟吧,没错就是表示正态分布(也称高斯分布)的统计图,其实现实生活中,误差的波动性也大多遵循这个规律.是什么意思呢?我们可以把图中的横坐标想作误差值,而纵坐标想成概率值,那么从图中我们可以发现一个很有意思的规律,误差值的绝对值越大那么它出现的概率反而会越小越趋近于0,误差值在0附近时可以看它们出现的概率是最大的,也就是说那种极大或者极小的误差值是占少数的.我们现在要引出一个函数也就是高斯分布的概率密度函数:
不懂概率密度函数的小伙伴也别急,你就把这个函数的自变量想成事件,然后函数的值想作此事件发生的概率即可;
- 既然误差遵循这个规律,那么我们就可以把前面我们得到的模型公式和概率密度函数联合起来就有:
将 \(\omega_i\) 代入概率密度函数就有:
我们通常习惯用 \(p(A|B)\) 来表示B事件发生后A事件发生的概率,前面的公式也就可以变成:
上式即表示我们通过训练模型得到准确值的概率,这个式子只是求单个数据得到真实值的概率,我们现在要来求全部数据都预测正确的概率,因为每个预测事件都是相互独立,的所以求全部正确概率只需要将所有单个的概率乘起来即可,那么就有:
这个函数有个官方的名称叫做似然函数,它表示参数 \(\theta\) 所对应的模型预测值全部与真实值相匹配的概率,也可以把它看做预测模型与数据的真实模型的相似度,显然看着上面的式子都很头大,很难计算,不妨将它转化一下.两边同时取对数:
它表示对数似然函数,这里图方便后面化简就取以 e 为底的对数,去了对数之后不妨来看有什么好处,我们来化简一下:
因为对数内部的乘法可以展开为外部的加法即 \(log{(ab)}=\log{a}+\log{b}\),所以:
把它在弄好看一点:
再次利用对数的乘法变加法性质展开得:
我们都知对数有这样一个性质: \(\log_a{a^n}=n\) 那么就有:
再把常数因子提到外边来就有:
为了便于观察,我们把常数项用 t 来代替掉:
因为 \(\ln{L(\theta)}\) 表示的是训练模型与真实模型相似值,越大表明训练模型越趋近于真实模型,根据方程我们可以知道,等式右端第一项 \(t_1(n\ln{\frac{1}{\sqrt{2\pi}\sigma}})\) 为一个非负常数,第二项中\(t_2({\displaystyle \frac{1}{2\sigma^2}})\)也为非负数,显然 \(t_2{\displaystyle \frac{1}{2}\sum_i^n{(y_i-\theta^Tx_i)^2}}\) 也为非负数,所以一个正的常数项减去一个非负变量,似然函数的值越大越好,也就是需要让后面这个非负变量越小那么似然函数的值也就越大,于是就有:
现在我们目标就是求 \(\max{J(\theta)}\),我们根据表达式可以看出这是一个开口向上的二次函数,那么它必定存在一个极值点,而且这个极值点就是函数的最小值,所以我们只需对 \(J(\theta)\) 进行求导,然后使其等于 0 即可,我们先将上面的式子换一种方式表达:
我们令:
那么就有:
#######################补充说明(如果上面等式你已经理解是如何来到可以跳过下面的内容)#####################
可能有小伙伴不知道是如何变换过来的,其实你只要懂矩阵的乘法就可以了,很明显:
\(X\theta= \begin{bmatrix} x_{11}&\cdots&x_{1m} \\ \vdots&\ddots&\vdots\\ x_{n1}&\cdots&x_{nm} \end{bmatrix} \begin{bmatrix}\theta_{1} \\ \vdots \\ \theta_{m}\end{bmatrix}= \begin{bmatrix} x_{11}\theta_1+&\cdots&+x_{1m}\theta_m \\ \vdots&\ddots&\vdots \\ x_{n1}\theta_1+&\cdots&+x_{nm}\theta_m \end{bmatrix}= \begin{bmatrix} \theta^Tx_1\\ \vdots \\ \theta^Tx_n \end{bmatrix}\)即它的结果是一个 n 行 1 列的矩阵,那么:
\((X\theta-Y)= \begin{bmatrix} \theta^Tx_1\\ \vdots \\ \theta^Tx_n \end{bmatrix}-\begin{bmatrix} y_1 \\ \vdots \\ y_n \end{bmatrix}=\begin{bmatrix} \theta^Tx_1-y_1\\ \vdots \\ \theta^Tx_n-y_n \end{bmatrix}\)
所以:
\((X\theta-Y)^T(X\theta-Y)= \begin{bmatrix} \theta^Tx_1-y_1,\cdots \theta^Tx_n-y_n \end{bmatrix} \begin{bmatrix} \theta^Tx_1-y_1\\ \vdots \\ \theta^Tx_n-y_n \end{bmatrix}\\= (\theta^Tx_1-y_1)^2+\cdots+(\theta^Tx_n-y_n)^2\\= \displaystyle \sum_i^n{(y_i-\theta^Tx_i)^2}\)
############################################ 结束 #################################################
- 现在我们对 \(J(\theta)\) 进行求偏导那么就有:
将转置放在里面来(注意在对含有乘法的项转置时要将矩阵变换顺序):
使用分配律将括号展开:
在最终求导前要先介绍三个矩阵求导的性质:
性质一:
如果有 \(f(A)=A^TBA\) 那么 \(\displaystyle \frac{\delta(f(A))}{\delta A}=BA+B^TA\)
性质二:
如果有 \(f(A)=B^TA\) 那么 \(\displaystyle \frac{\delta(f(A))}{\delta A}=B\)
性质三:
如果有 \(f(A)=A^TBC\) 那么 \(\displaystyle \frac{\delta(f(A))}{\delta A}=BC\)
有了上面三个性质,现在就可以计算上面式子的导数了(先做一下变换,方便使用上面的性质)
利用性质一,二,三可得:
将转置放在扩号中去:
合并同类项:
因为我们要求极值点,所以令导数等于0即可:
移项得:
两边同时乘以一个\((X^TX)^{-1}\):
这样我们便得到了\(\theta\)的计算方法
2)代码实现
- 有了计算方式,那么使用代码来实现就简单了
- 先定义计算 \(\theta\) 的函数
import matplotlib.pyplot as plt
import numpy as np
def train_model(x_data,y_data):
# 逻辑很简单就是把求theta的公式实现了一遍
matrix_x = np.matrix(x_data)
matrix_y = np.matrix(y_data)
matrix_x_T = matrix_x.T
t1 = np.dot(matrix_x_T,matrix_x)
t1_I = t1.I
t2 = np.dot(t1_I,matrix_x_T)
theta = np.dot(t2,matrix_y)
return theta
- 定义使用模型进行预测的函数:
def predict(model,x_data):
# 这里因为我们传入的x_data是 n×m,model是 m×1,所以反过来乘代码逻辑就会简单许多
return np.dot(np.matrix(x_data),model)
- 加载数据
# 导入自带的波士顿房价数据
from sklearn.datasets import load_boston
boston_data = load_boston().data
train_x = boston_data[:,:-1]
# 这里需要注意的波士顿原本数据内只有12个特征值,前面也说过我们的模型有一个单出来的 theta0
# 那么我们只需要在数据中认为的假如一列特征列,全部置一即可
# 也就是 t_0x_0+t_1x_1+...+t_12x_12
# 我们把方程中的t_0全部变为1即可
ones_x = np.ones(train_x.shape[0])
train_x = np.column_stack((ones_x,train_x))
train_y = boston_data[:,-1:]
- 训练模型
model = train_model(train_x,train_y)
model.shape
# (13,1)
- 预测数据
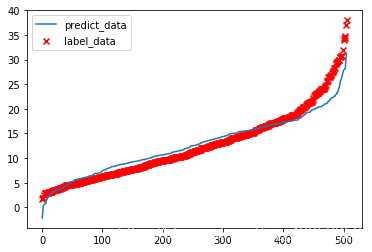
p_y = predict(model,train_x)
p_y = np.sort(np.array(p_y)[:,0])
- 在图上绘制数据
plt.scatter(np.arange(0,506),np.sort(boston_data[:,-1]),marker="x",c="r",label="label_data")
plt.plot(np.arange(0,506),p_y,label="predict_data")
plt.legend()
*
1.1.1.3 线性回归——梯度下降法
1)什么是梯度下降?
- 很多初学者一听到这个词就望而生畏,觉得这是一个很高大上的词,觉得很高大上.其实它也只是名字被蒙上了一层面纱,远没有大家想得那么高大上,打个很通俗的比方就是楼梯跟滑滑梯的区别是什么,不就是楼梯是一步一步的移动吗,而滑滑梯则是光滑的持续的运动轨迹,在上面是一瞬即逝的.在打个比方你在一座山上,现在你需要找到一条路下到山底,你现在是不知道下山的路的,山上有很多的岔路口,该怎么办呢?其实解决办法很简单,既然是下山那么你在高度H是必定要减少的,不妨你走一步然后测量一下当前这一步是让你的高度下降了还是上升了.如果是下降了就跟着这个方向走,如果不是则换个方向再测量反复如此,你就到达山下了.这是一个典型的贪心问题,用局部解求出全解的过程.
- 我们再从现实回到书面函数图像上来.

这是一个开口向上的二次函数 \(f(x)=x^2\) 的函数图像,我们把它比作成一座山,它的最低点就是山底,图中还有一个红点,他表示我们人现在所处的位置,如果用梯度下降的方法,让人下山,那么它的轨迹可以表示成下图:

图浅显易懂,一眼便能看出’下山’轨迹,但是问题来了在算法上我们是如何实现的呢?
导数大家都应该清楚吧,导数反应的就是函数中某点的变化率,而且这个变化率是正增长的变化率,换句话说就是某个点它最对应的\(f(x)\)的增长那个’增脏速度速度’,给他加个负号反转过来便是我们的’下山’方向.在’山路’(函数)中我们么一步就可以用下面的方式来进行表示:
其中你发现多另一个 \(\alpha\) 参数,这个参数的作用是代表我们每一步的跨度,专业术语也叫学习率,之所以要有这个参数是因为,我们要让下上的时间尽量短(也就是一步走大一点),但是也不能太大,如果太大会发生什么呢?请看下图你就明白了:

可以看到在这种函数图像下面,我们如果一步迈大了,那么直接就跳过了最小值的地方,来到了另一个极小值的区域,显然不是我们想要的,所以 \(\alpha\) 不能太小也不能太大,恰到好处最好
搞懂了原理我们再来根据公式来计算一遍:
我们这里让起点为 \(x_0=-4\),\(\alpha=0.4\)
\(f(x)=x^2\)
\(f'(x)=2x\)
(1):
\(x_1=x_0-\alpha f'(x_0)\\ =-4-0.4 \times(2\times-4)\\ =-0.8\)
(2):
\(x_2=x_1 -\alpha f'(x_1)\\ =-0.8-0.4\times(2\times-0.8)\\ =-0.16\)
(3)
\(x_3=x_2 -\alpha f'(x_2)\\ =-0.16-0.4\times(2\times-0.16)\\ =-0.032\)
可以看到只经过了三步迭代就已经接近最低点的位置了,可见效率还是挺高.
有了上面的知识你就算入门梯度下降了,你会发现上面只提到了一个自变量的情况,但在实际开发当中数据往往是多维的,具有多个特征值,那么多维的数据该怎么处理呢,上面我们只是提到了导数,其实导数还有一个亲兄弟叫做偏导数,多维度的数据我们往往采用偏导数的方式来解决,如果我们有一个函数是这样的:
通过作图工具我们将图像画出来是这样的:

很明显函数的最低点在(0,0,0)处,但我们要怎么来求?先别急计算的原理都是大同小异,在计算之前先了解这样一个概念
在只有一个自变量的函数中我们对其求导,因为只有一个自变量所以它的方向就要么向前,要么向后我们就用一个标量\(\Delta\)
来表示它的变化,\(\Delta\)为负表示向后,\(\Delta\)为正表示向前.
现在到了有多个自变量的函数中,我们就需要对所有的自变量求一次偏导,然后让这些求得的偏导组成一个列表,我们通常称这个列表为一个向量,向量是具有方向的而标量则没有.求出来的向量是这样的
我们不妨来对\(f(\theta)=\theta_1^2+\theta_2^2\),这个曲面方程来计算一下它的梯度下降过程:
还以一样先确定取初始位置,起点就设为\(<\theta_{01},\theta_{02}>=<4,4>\),\(\alpha=0.4\)
再分别把偏导函数求出来:
\(\displaystyle \frac{\delta(f(\theta))}{\delta\theta_1}=2\theta_1,\displaystyle \frac{\delta(f(\theta))}{\delta\theta_2}=2\theta_2\)
然后开始迭代:
(1)
\(<\displaystyle \theta_{11},\theta_{12}>=\left<\theta_{01}-\alpha\displaystyle \frac{\delta(f(\theta_{01}))}{\delta\theta_1},\theta_{02}-\alpha\displaystyle \frac{\delta(f(\theta_{02}))}{\delta\theta_2}\right> \\=<4-0.4\times(2\times4),4-0.4\times(2\times4)> \\=<0.8,0.8>\)
(2)
\(<\displaystyle \theta_{21},\theta_{22}>=\left<\theta_{11}-\alpha\displaystyle \frac{\delta(f(\theta_{11}))}{\delta\theta_1},\theta_{12}-\alpha\displaystyle \frac{\delta(f(\theta_{12}))}{\delta\theta_2}\right> \\=<0.8-0.4\times(2\times0.8),0.8-0.4\times(2\times0.8)> \\=<0.16,0.16>\)
(3)
\(<\displaystyle \theta_{31},\theta_{32}>=\left<\theta_{21}-\alpha\displaystyle \frac{\delta(f(\theta_{21}))}{\delta\theta_1},\theta_{22}-\alpha\displaystyle \frac{\delta(f(\theta_{22}))}{\delta\theta_2}\right> \\=<0.16-0.4\times(2\times0.16),0.16-0.4\times(2\times0.16)> \\=<0.032,0.032>\)
……,……
(j)
\(<\displaystyle \theta_{j1},\theta_{j2}>=\left<\theta_{(j-1)1}-\alpha\displaystyle \frac{\delta(f(\theta_{(j-1)1}))}{\delta\theta_1},\theta_{(j-1)2}-\alpha\displaystyle \frac{\delta(f(\theta_{(j-1)2}))}{\delta\theta_2}\right>\)
由于篇幅原因这里就列出了三次迭代过程,我们来看看将整个过程在途中绘制出来是怎样的

根据图像还是很直观可以看到梯度下降法的下降轨迹.
2)线性回归梯度下降法公式推导
- 最小二乘法公式:
公式的证明与推导在上一篇博文中已经讲解,这里就不阐述公式的由来了,如有疑问可以翻看博文查看由来.为什么要在这里提及最小二乘法的公式呢?这是因为我们这里要引入一个新的式子,均方误差或者也可以叫它代价函数(\(J(\theta)\)):
可以看到这个公式和上面的最小二乘法的公式区别就在与前面对整个计算结果除以了一下样本个数,就相当于是求了一下误差的平均值,从而消除了样本个数对参数求解的影响.
让我们来对这个函数求偏导数就有:
#################################### 明白求导过程的小伙伴可以跳过 ####################################
到这里的小伙伴肯定会问求导之后为什么会是这样,不妨听博主推导一遍:
在推导之前你要先明白下面三个个性质:
性质一:(复合函数求导公式)
\(u=x^2,f'(u)=f'(u)u'\)
性质二:(求偏导时忽略其他自变量)
\(\displaystyle f(\theta)=\theta_1^2+2\theta_2+\theta_3^2\\ \frac{\delta(f(\theta))}{\theta_1}=2\theta_1,\frac{\delta(f(\theta))}{\theta_2}=2,\frac{\delta(f(\theta))}{\theta_1}=2\theta_3\)
性质三:(导数的加法分配率)
\(f(x)=f_1(x)+f_2(x),f'(x)=f_1'(x)+f_2'(x)\)
明白了这三个性质,我们现在将\(J(\theta)\)展开:
开始对\(J(\theta)\)求\(\theta_0\)的偏导数
把所有的 2 与分母约掉:
现在我们来计算\(\displaystyle \frac{\delta(h_\theta(x_n))}{\delta\theta_0}\),先展开再根据性质二可得:
我们再来回到原来的式子中将\(\frac{\delta(h_\theta(x_n))}{\delta\theta_0}\)替换掉就有:
最后将式子合起来表示:
############################################# END ################################################
我们求得了偏导函数,现在就可以利用前面所介绍的梯度下降法则了,那么就有公式:
这个公式中的 n 代表样本数,\(\alpha\)代表学习率也就是步长,如果我们每次都取全部样本来计算显然算出来的参数是最准确的,但是时间上肯定也是最大的 n 如果取 1 ,我们随机取一个样本来计算参数,这样是最快,但是准确就不能保证,所以通常n可以取一个常数表示抽取样本中的一部分数据来测试,这样准确率不会太低,时间开销也不会太大.
3)代码实现
- 为了方便计算我们把上面的公式换成矩阵来表式
至于为什么可以变成这样,也可以参考博主前面一篇文章中的推理方法,自行推理这里也不多讲了。
- 定义必要的函数:
def error_func(theta,train_x,train_y):
# 均方误差
data_len = train_x.size
temp = np.dot(train_x,theta) - train_y
result = np.dot(temp.T,temp)/2*data_len
return result
def gradient_func(theta,train_x,train_y):
# 梯度
data_len = train_x.size
temp = np.dot(train_x,theta) - train_y
result = np.dot(train_x.T,temp)/data_len
return result
def gradient_descent(x,y,a,valve):
# 根据梯度进行下降
features_len = x.shape[1]
theta = np.ones(features_len).reshape(features_len,1)
data_len = x.shape[0]
while True:
gradient = gradient_func(theta,x,y)
theta = theta - gradient*a
if np.all(np.absolute(gradient) < valve):
return theta
def predict(model,x_data):
# 预测
return np.dot(np.matrix(x_data),model)
- 加载数据训练模型并绘图
from sklearn.datasets import load_boston
boston_data = load_boston().data
X = boston_data[:,:-1]
ones_x = np.ones(X.shape[0])
X = np.column_stack((ones_x,X))
Y = boston_data[:,-1:]
t = gradient_descent(X,Y,0.00004,0.1)
p_y = predict(t,X)
p_y = np.sort(np.array(p_y)[:,0])
plt.scatter(np.arange(0,506),np.sort(boston_data[:,-1]),marker="x",c="r",label="label_data")
plt.plot(np.arange(0,506),p_y,label="predict_data")
plt.legend()

1.1.1.4 逻辑回归——梯度下降法
1)逻辑回归是回归算法?
- 当然不是啦,你别被它的名字所迷惑了,虽然它的名字当中带有回归二字,但是它却是一个彻彻底底的分类算法,而且还是一个经典的二分类回归算法.所以这里还需留意,为什么它被归到分类算法的类别当中呢,不妨来看一下它的实现过程与原理
2)算法原理及推导
- 其实吧逻辑回归算法既然名字当中带有回归二字,那必然是有原因的,那是因为它就是通过线性回归的算法模型然后衍生出来的.
- 我们先来看一个函数:
它名字叫做Sigmoid函数,通常它就是用来将连续的数据变为离散的数据的,我们来看看它的函数图像吧:

博主故意将函数的纵轴从y=0.5为分界线划分成了红,蓝两个区域,可以看到这个函数的取值就是在0~1之间的,
- 那么如何利用Sigmoid函数来进行分类呢?
打个比方现在我有一些数据\([x_1,x_2,\cdots,x_n]\)
我们将\(x_i\)传入 Sigmoid 函数当中来计算,那么必然就可以得到一些 0~1 之间的数值.
我们从 0.5 为界分割线开始划分,
如果\(g(x_i) \gt 0.5\)我们就把 \(x_i\) 归到类别一当中;
如果\(g(x_i) \lt 0.5\)我们就把 \(x_i\) 归到类别二当中:
这不我们就将数据分为两类了吗. - 如何从线性回归转到逻辑回归
还记得线性回归的模型吗:
我们根据上面的模型,传入对应的特征数据那么模型就会给我们计算出一个预测结果 \((\hat{y})\) 来,我们都知道这个预测值还是一个连续的变量,所以我们不妨将\(\hat{y}\)带入Sigmoid函数中来看,就有了一个新的预测模型:
很明显 \(0 \lt h_\theta(X) \lt 1\),我们再根据 $ h_\theta(X)$ 是否大于 0.5 来判断该样本属于哪一类.
这就是逻辑回归的核心原理
- 求解方法推导
既然原理已经清楚了,现在我们该来谈谈如来进行计算:
我们在回到刚才的公式上来,既然\(g(\theta^TX)\)的取值是0到1之间,不妨我们把它的值看成是概率,那么就有下面的表示:
我们可以将两个式子合并一下,用一个式子来表示:
可以看到当y=1时:
\(p(y|x;\theta)= h_\theta(X)\)
当y=0时:
\(p(y|x;\theta)= 1-h_\theta(X)\)
有了合并后的公式,我们再来通过训练样本来计算公式的准确度,我们知道上面我们得到的那个式子就是用来计算传入的特征为这个类别y的概率值的.就是下面的这个意思:
我有一行样本数据:\(x_0=[x_{01},x_{02},\cdots,x_{0n}], y_0=1\)
我们将样本数据传入上面的公式当中就会得到一个概率 p :
这个p值有两层含义,第一层很容易就可以想到就表示此行样本为类别1的概率,
第二层含义就要转一个弯了,p 可以表示为本次预测的与真实值的匹配度,为什么呢?你想,假如 p = 1,你想是不是这个概率表示此次模型预测的结果与样本的真实结果完全匹配;如果 p=0 ,那么就表示此次预测与样本真实值毫不相关.当然举的是两个极端的例子,那么中间的概率自然可以用作预测值和真实值的匹配度嘛.概率越接近 1 表示预测结果与真实值越匹配,概率越接近0就表示预测值与真实值相差越远.
有了第二层含义的基础我们就可以将整个样本计算出来的预测集连乘起来,那么就可以写出下面这个式子:
上面这个式子就叫做似然函数,用它的值来表示 \(\theta\)(也就是我们通过训练得出的所有x前面的系数),通过这个\(\theta\)所构建的这个模型与数据真实模型的相似程度.
因为乘法并不便于后期我们的计算,所以我们要想个法子将它变成加法,没错就是两边同时取对数:
由 \(\log_a{bc}=\log_ab+\log_ac\) 性质可得:
再由 \(\log{a^x}=x\log{a}\)性质可得:
上面这个式子就叫对数似然函数.
现在为了让我们训练出来的 \(\theta\) 值对应的模型与真实模型拟合度最高,所以就需要不断改变\(\theta\),然后让 \(l(\theta)\) 的值取得最大,当\(l(\theta)\)的值去得最大时,此时的 \(\theta\) 也就是我们训练出的最好的参数组合,根据上面的式子我们发现此时的\(l(\theta)\)还与样本数量n具有有相关型,为了使它脱离与样本数量的关系,我们就对它取一下平均数就好,也就是除以样本数量n.还有我们要使用梯度下降法,但是这里我们是求的最大值,所以我们要将它转换一下,变成求最小值,所以给它前面加上一个负号即可.综上所处我们就可以把公式表示成这样:
好了现在我们就可以根据梯度下降的流程走了:
(1).第一步就是求各个\(\theta\)分量的偏导作为下降的方向:
根据\(\displaystyle \frac{\delta(\log{x})}{\delta(x)}=\frac{1}{x}\)和求导分配率,复合函数求导法则可以得:
因为 \(\displaystyle h_\theta(X)=g(\theta^TX)\),那么化简可得:
现在来求\(\displaystyle \frac{\delta(h_\theta(x_i))}{\delta(\theta_j)}\),因为\(\displaystyle h_\theta(x_i)=\frac{1}{1+e^{-\theta^Tx_i}}\)所以求导可得:
化简,在配方可得:
约分.合并后可得:
现在再把这个结果带入到刚才的表达式当中就有:
约分并化简:
计算\(\displaystyle \frac{\delta(\theta^Tx_i)}{\delta(\theta_j)}\)后得(如不懂为什么变成这样,博主上一期博文中有讲解):
将括号内的项展开,化简可得:
把最前面的负号提到括号中来:
现在求导算已经完成了,下面将它带入梯度下降的公式可得:
到这里原理推导就完成了,下面看如何使用代码实现
3)算法实现
- 定义一个用于训练模型的类(具体做法都写在注释中了)
class LogisticRegression:
class Model:
"""
desc:训练出的模型
"""
def __init__(self,theta):
"""
desc:根据传入的 θ 构建模型
"""
self.theta = theta
def predict(self,x_test):
"""
desc:根据传入的特征,利用模型预测数据
"""
t = np.dot(x_test, self.theta)
# 得出类别为 1 的概率
result = LogisticRegression.sigmoid(t)
# 将所有数据取整 p > 0.5 return: 1 , p <= 0.5 return: 0
return np.round(result)
def __init__(self,alpha,theta,valve,batch_n=-1,max_iter=10**3):
"""
:param: alpha: 学习率,也称梯度下降中每一步的步长
:param: theta: 初始化的 θ 向量
:param: valve: 阀值,训练过程中,如梯度值的绝对值小于阀值就会跳出训练
:param: batch_n: 取一个整数表示微梯度下降中采用的样本数量,-1表示每次迭代采用全部数据
:param: max_iter: 最大的迭代次数,超过时自动跳出训练
"""
self.alpha = alpha
self.theta = theta
self.valve = valve
self.batch_n = batch_n
self.max_iter = max_iter
def fit(self,x_data,y_data):
"""
:param x_data: 特征值
:param y_data: 标签值
"""
iter_cnt = 0
data_len = x_data.shape[0]
# 验证样参数是否满足要求,并使其满足要求
self.batch_n = data_len if self.batch_n <= 0 or self.batch_n > data_len else self.batch_n
# 开始迭代
while self.__gradient_func(x_data,y_data) and iter_cnt < self.max_iter:
iter_cnt += 1
return self.Model(self.theta)
def __gradient_func(self,x_data,y_data):
"""
:param x_data: 特征值
:param y_data: 标签值
"""
gradient_vector = np.zeros(self.theta.size)
data_len = x_data.shape[0]
fetature_len = self.theta.shape[0]
# 遍历特征维度
for t in range(fetature_len):
j_ = 0
# 遍历样本数据
for i in range(0,data_len,round(data_len/self.batch_n)):
# 计算θx_1 + θx_2 + ... + θx_n 也就是公式中的(θ^TX)
t1 = np.dot(x_data[i], self.theta)
# 计算预测值 h_θ(x_i)
h_theta = LogisticRegression.sigmoid(t1)
# 结果累加起来 (h_θ(x_i) - y_i)x_ij
j_ += (h_theta-y_data[i])*x_data[i][t]
# 除以处理的样本数量,也就是取均值
j_ /= self.batch_n
# 修改梯度下降方向向量中对应的值
gradient_vector[t] = j_
# 更新全局 θ 的值,也就是朝着下山的方向走一步
self.theta = self.theta - self.alpha*gradient_vector
# 输出是否梯度是否达到阀值
return np.abs(gradient_vector.sum()) >= self.valve
@staticmethod
def sigmoid(x):
t = 1 + np.exp(-x)
result = np.divide(1,t)
return result
- 准备数据 (这里使用sklearn中自带的鸢尾花数据集)
from sklearn.datasets import load_iris
iris_data = np.column_stack(load_iris(return_X_y=True))
# 这里我们实现的只是二分类算法,左右只需要类别0和类别1两种即可
iris_data = iris_data[iris_data[:,-1]<2]
# 将数据打乱
np.random.shuffle(iris_data)
# 将数据分成两份
train_data,test_data= np.split(iris_data,2,axis=0)
# 训练数据
train_x = train_data[:,:-1]
train_y = train_data[:,-1]
# 测试数据
test_x = test_data[:,:-1]
test_y = test_data[:,-1]
- 训练模型
l = LogisticRegression(0.04,np.array([1]*train_x.shape[1]),0.0003,batch_n=20,max_iter=1000)
m = l.fit(train_x,train_y)
- 利用测试数据预测结果
m.predict(test_x)
后言:
如果文章对你有帮助不妨动动小手点个赞再走呗 !(__)!
文章中有什么问题也欢迎指出哟,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号