django 对接elasticsearch实现全文检索
django 对接elasticsearch实现全文检索
第一步:安装elasticsearch环境(docker安装)
拉取镜像
# docker image pull delron/elasticsearch-ik:2.4.6-1.0
运行容器
# docker run -d -p 9200:9200 -p 9300:9300 --name search delron/elasticsearch-ik:2.4.6-1.0
elasticsearch建立索引库
# curl -XPUT http://localhost:9200/test

第二步:首先安装相关的依赖包
# pip3 install drf-haystack # pip3 install elasticsearch # pip3 install djangorestframework
第三步:在django项目配置文件settings.py中注册应用
INSTALLED_APPS = [ ... 'app01.apps.App01Config', 'haystack', 'rest_framework' ]
第四步:在django项目配置文件settings.py中指定搜索的后端
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://127.0.0.1:9200/', # 此处为elasticsearch运行的服务器ip地址,端口号固定为9200 'INDEX_NAME': 'test', # 指定elasticsearch建立的索引库的名称 }, } # 当添加、修改、删除数据时,自动生成索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor' # 指定搜索结果每页的条数 # HAYSTACK_SEARCH_RESULTS_PER_PAGE = 1
第五步:创建索引类
在此之前要先创建model类,并插入数据
from django.db import models class Book(models.Model): nid=models.AutoField(primary_key=True) name=models.CharField(max_length=32) publish=models.CharField(max_length=32) price=models.DecimalField(max_digits=5,decimal_places=2) #插入多条数据
在需要进行索引的应用的目录下创建文件search_indexes.py, 在该文件内创建该索引类
我在app01应用下创建:search_indexes.py
# 索引模型类的名称必须是 模型类名称 + Index from haystack import indexes from .models import Book class BookIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): """返回建立索引的模型类""" return Book def index_queryset(self, using=None): """返回要建立索引的数据查询集""" return self.get_model().objects.all() """ 说明: 1.在BookIndex建立的字段,都可以借助haystack由elasticsearch搜索引擎查询。 2.其中text字段声明为document=True,表名该字段是主要进行关键字查询的字段, 该字段的索引值可以由多个数据库模型类字段组成(是多个字段,不是多个数据库模型类,转者注),具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。 3.在 REST framework中,索引类的字段会作为查询结果返回数据的来源, """
第六步:在templates目录中创建text字段使用的模板文件
创建文件templates/search/indexes/app01/book_text.txt文件中定义
{{ object.name }}
{{ object.publish }}
第七步:手动更新索引
# python manage.py rebuild_index #数据库有多少条数据,全部会被同步到es中
第八步:创建haystack序列化器
from drf_haystack.serializers import HaystackSerializer from rest_framework.serializers import ModelSerializer from app01 import models from app01.search_indexes import BookIndex class BookSerializer(ModelSerializer): class Meta: model=models.Book fields='__all__' class BookIndexSerializer(HaystackSerializer): object = BookSerializer(read_only=True) # 只读,不可以进行反序列化 class Meta: index_classes = [BookIndex]# 索引类的名称 fields = ('text', 'object')# text 由索引类进行返回, object 由序列化类进行返回,第一个参数必须是text
第九步:创建视图类
from drf_haystack.viewsets import HaystackViewSet from app01.models import Book from app01.serializers import BookIndexSerializer class BookSearchView(HaystackViewSet): index_models = [Book] serializer_class = BookIndexSerializer #该视图会返回搜索结果的列表数据,所以如果可以为视图增加REST framework的分页功能。 #我们在配置文件已经定义了分页配置,所以此搜索视图会进行分页
第十步:添加路由
from django.conf.urls import url from django.contrib import admin from rest_framework import routers from app01.views import BookSearchView router = routers.DefaultRouter() router.register("book/search", BookSearchView, base_name="book-search") # 全文搜索 urlpatterns = [ url(r'^admin/', admin.site.urls), ] urlpatterns += router.urls
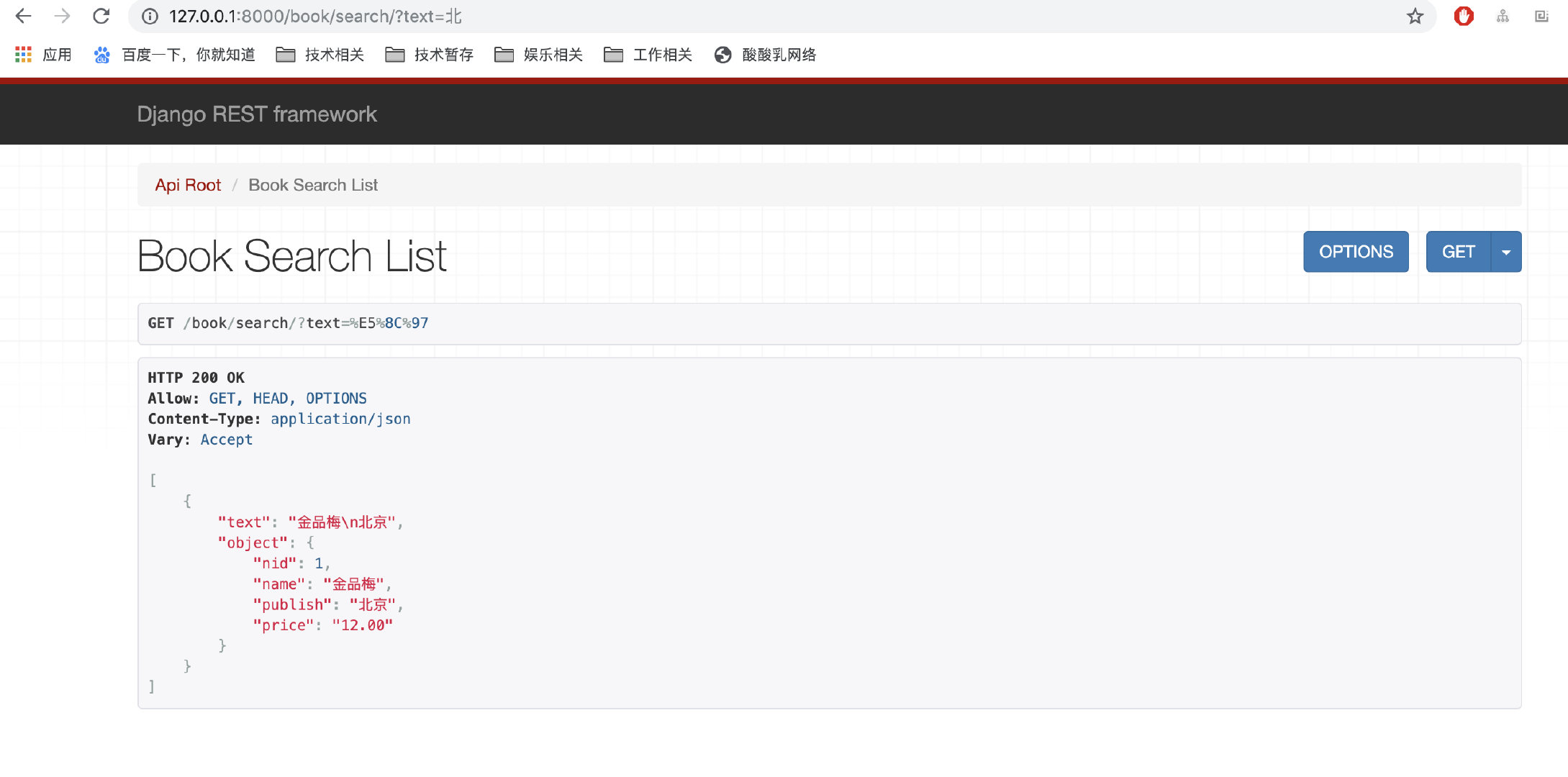
第十一步:测试
http://127.0.0.1:8000/?text=北 #查询出名字中和出版社中有北的数据