scrapy-redis实现分布式爬虫
一 介绍
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)
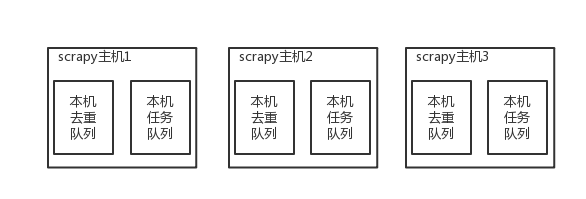
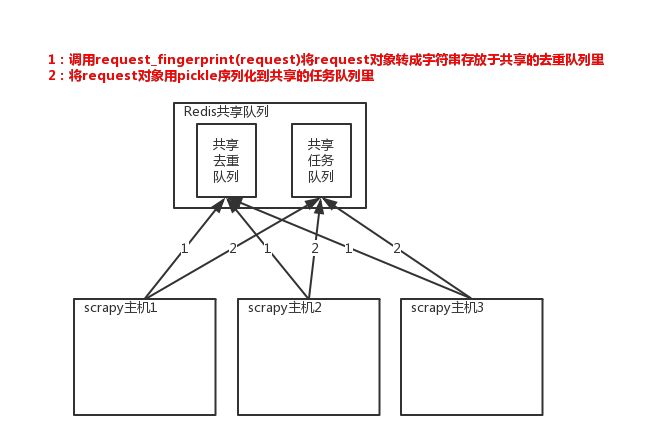
所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
#1、共享队列 #2、重写Scheduler,让其无论是去重还是任务都去访问共享队列 #3、为Scheduler定制去重规则(利用redis的集合类型)
以上三点便是scrapy-redis组件的核心功能
#安装: pip3 install scrapy-redis #源码: D:\python3.6\Lib\site-packages\scrapy_redis
二、scrapy-redis组件
使用分布式爬虫步骤
目录
1、安装
# pip3 install scrapy-redis
2、爬虫继承RedisSpider,(原来继承Spider)
cnblogs/spiders/cnblog_redis.py
# -*- coding: utf-8 -*- import scrapy from scrapy_redis.spiders import RedisSpider from cnblogs.items import CnblogsItem from scrapy import Request class CnblogSpider(RedisSpider): name = 'cnblog_redis' allowed_domains = ['www.cnblogs.com'] # start_urls = ['https:/www.cnblogs.com/'] redis_key = 'myspider:start_urls' def parse(self, response): # print(response.text) div_list = response.css('article.post-item') for div in div_list: item = CnblogsItem() title = div.css('.post-item-title::text').extract_first() item['title'] = title url = div.css('.post-item-title::attr(href)').extract_first() item['url'] = url desc = ''.join(div.css('.post-item-summary::text').extract()).strip() item['desc'] = desc # 要继续爬取详情 # callback如果不写,默认回调到parse方法 # 如果写了,响应回来的对象就会调到自己写的解析方法中 yield Request(url, callback=self.parser_detail, meta={'item': item}) # 解析出下一页的地址 next = 'https://www.cnblogs.com' + response.css('#paging_block>div a:last-child::attr(href)').extract_first() print(next) yield Request(next) def parser_detail(self, response): content = response.css('#cnblogs_post_body').extract_first() print(str(content)) # item哪里来 item = response.meta.get('item') item['content'] = content print(item) yield item
3、不能写start_urls,需要写redis_key,具体见2
4、setting中配置:
# 使用scrapy-redis的去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis的Scheduler # 分布式爬虫的配置 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 持久化的可以配置,也可以不配置 # 开启管道 ITEM_PIPELINES = { # 'cnblogs.pipelines.CnblogsFilePipeline': 300, 'cnblogs.pipelines.CnblogsMysqlPipeline': 305, 'scrapy_redis.pipelines.RedisPipeline': 299 } # 默认scrapy-redis链接redis是127.0.0.1:6379,如果想改见下面配置 REDIS_HOST = 'localhost' # 主机名 REDIS_PORT = 6379 # 端口 #REDIS_PASS = 'redisP@ssw0rd' # 密码 REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于上面三行配置) REDIS_PARAMS = {} # Redis连接参数 REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 REDIS_ENCODING = "utf-8" # redis编码类型
示例启动三个进程演示:
5、现在要让爬虫运行起来,需要去redis中以myspider:start_urls为key,插入一个起始地址
# lpush myspider:start_urls https://www.cnblogs.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号