drf 之序列化器-Serializer
# 1. 序列化: 序列化器会把模型对象转换成字典,将来提供给视图经过response以后变成json字符串 # 2. 反序列化,把客户端发送过来的数据,经过视图调用request以后变成字典,序列化器可以把字典转成模型 # 3. 反序列化,完成数据校验功能和操作数据库
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
接下来,为了方便演示序列化器的使用,我们先创建一个新的子应用sers
python manage.py startapp sers
目录
使用Django Rest_Framework(drf)介绍,以及安装和配置已有的数据库模型类students/Student,添加一个property属性
from django.db import models # Create your models here. class Student(models.Model): # 表字段声明 # 字段名 = models.数据类型(字段约束) name = models.CharField(null=False,verbose_name="姓名",max_length=32) age = models.IntegerField(verbose_name="年龄") sex = models.BooleanField(default=True, verbose_name="性别") class_num = models.CharField(max_length=5, verbose_name="班级编号") description = models.TextField(max_length=1000, verbose_name="个性签名") # 表信息声明 class Meta: # 设置数据库中表名 db_table="tb_students" verbose_name_plural= "学生" # 模型的操作方法 def __str__(self): return self.name @property def text(self): return 100
我们想为这个模型类提供一个序列化器,在sers目录下新建一个serializers.py文件如下:
from rest_framework import serializers # Serializer基础序列化器, # ModelSerializer 模型类序列化器,是基础序列化器的子类 class StudentSerializer(serializers.Serializer): """学生信息序列化器""" # 1. 字段声明 # 注意: # 1. 把需要提供给客户端的字段才写进来,或者需要客户端提供的字段才写进 # 2. =号左边的字段一定要和模型里面的字段名对应 # 3. 序列化器声明的字段并非一定要在数据库中的,也可以是模型声明的属性方法 id = serializers.IntegerField() name = serializers.CharField() age = serializers.IntegerField() sex = serializers.BooleanField() text = serializers.IntegerField() # description = serializers.CharField() # TextField是数据才有的,前端没有这种说法 # 2. 如果使用的模型类序列化器,则需要编写继承的模型信息 # 3. 验证数据的相关代码 # 4. 保存数据到数据库中的代码
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format='hex_verbose') format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_places: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
选项参数:
| 作用 | |
|---|---|
| max_length | 最大长度[适用于字符串,列表,文件] |
| min_lenght | 最小长度[适用于字符串,列表,文件] |
| allow_blank | 是否允许数据的值为空,如果使用这个选项,则前端传递过来的数据必须有这个属性。 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 【数值】最小值 |
| min_value |
通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
sers目录下的views.py视图(注意符合rest ful规范,在返回信息中包含状态码,错误信息的方法,使用字典)
# Create your views here. from django.views import View from django.http.response import JsonResponse from .serializers import StudentSerializer from students.models import Student class StudentsView(View): def get(self,request): # 序列化器的声明和使用 # 为符合rest ful规范在return信息中包含状态信息,命令执行信息 reponse_msg = {"status":100,"msg":"数据获取成功"} # 0. 从数据库中查询模型对象 student = Student.objects.filter(pk=1).first() # 1. 实例化序列化器对象 # 参数: # 1) instance 模型对象, 一般来自于ORM # 2) data 字典数据, 一般来自客户端 # 3) context 字典, 可以把视图中的信息传参给序列化器 # 4) many 布尔值,如果instance是多个对象,则必须声明many=True,否则序列化器会报错 if student: serializer = StudentSerializer(instance=student) reponse_msg["data"] = serializer.data # 序列化器对象.data就是序列化后的字典 # print(serializer.data) # 转换后的字典数据 else: reponse_msg["status"] = 101 reponse_msg["msg"] = "数据获取失败" return JsonResponse(reponse_msg, json_dumps_params={ensure_ascii:False})
drfdemo下的总路由urls.py
from django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('students/', include("students.urls")), path('sers/', include("sers.urls")), ]
sers目录下的路由urls.py
from django.urls import path,re_path from . import views urlpatterns = [ path('students/', views.StudentsView.as_view()), ]
1.2 创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3) many参数(布尔值),如果instance是多个对象,则必须声明many=True,否则序列化器会报错
4)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
# views.py中 class StudentsView(View): def get1(self,request): # 序列化器的声明和使用 # 0. 从数据库中查询模型对象 student = Student.objects.get(pk=1) # 1. 实例化序列化器对象 # 参数: # 1) instance 模型对象, 一般来自于ORM # 2) data 字典数据, 一般来自客户端 # 3) context 字典, 可以把视图中的信息传参给序列化器 # 4) many 布尔值,如果instance是多个对象,则必须声明many=True,否则序列化器会报错 num =1 serializer = StudentSerializer(instance=student,context={"num":num}) return JsonResponse(serializer.data)
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
-
使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
-
序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
-
序列化器的字段声明类似于我们前面使用过的表单系统。
-
开发restful api时,序列化器会帮我们把模型数据转换成字典.
-
drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
1.3 序列化器的使用
序列化器的使用分两个阶段:
-
在客户端请求时,使用序列化器可以完成对数据的反序列化。
-
在服务器响应时,使用序列化器可以完成对数据的序列化。
1.3.1.1 基本使用
1) 先查询出一个学生对象
from students.models import Student student = Student.objects.get(id=3)
2) 构造序列化器对象
from .serializers import StudentSerializer serializer = StudentSerializer(instance=student)
3)获取序列化数据
通过data属性可以获取序列化后的数据
serializer.data # {'id': 4, 'name': '小张', 'age': 18, 'sex': True, 'description': '猴赛雷'}
完整serializers,序列化器代码
from rest_framework import serializers # Serializer基础序列化器, # ModelSerializer 模型类序列化器,是基础序列化器的子类 class StudentSerializer(serializers.Serializer): """学生信息序列化器""" # 1. 字段声明
# 格式:
# 字段名 = serializers.字段类型(字段选项)
# 注意: # 1. 把需要提供给客户端的字段才写进来,或者需要客户端提供的字段才写进 # 2. =号左边的字段一定要和模型里面的字段名对应 # 3. 序列化器声明的字段并非一定要在数据库中的,也可以是模型声明的属性方法
# 4. 字段选项,主要用于在反序列化阶段验证数据
id = serializers.IntegerField() name = serializers.CharField() age = serializers.IntegerField() sex = serializers.BooleanField() text = serializers.IntegerField() # description = serializers.CharField() # TextField是数据才有的,前端没有这种说法 # 2. 如果使用的模型类序列化器,则需要继续的模型信息 # 3. 验证数据的相关代码 # 4. 保存数据到数据库中的代码
完整视图代码:
# Create your views here. from django.views import View from django.http.response import JsonResponse from .serializers import StudentSerializer from students.models import Student class StudentsView(View): def get1(self,request): # 序列化器的声明和使用 # 0. 从数据库中查询模型对象,获取单个值 pk = request.GET.get("pk") student = Student.objects.get(pk=pk) print(student) # 1. 实例化序列化器对象 # 参数: # 1) instance 模型对象, 一般来自于ORM # 2) data 字典数据, 一般来自客户端 # 3) context 字典, 可以把视图中的信息传参给序列化器 # 4) many 布尔值,如果instance是多个对象,则必须声明many=True,否则序列化器会报错 serializer = StudentSerializer(instance=student) print(serializer.data) # 转换后的字典数据 return JsonResponse(serializer.data)
# Create your views here. from django.views import View from django.http.response import JsonResponse from .serializers import StudentSerializer from students.models import Student class StudentsView(View): def get(self, request): """序列化多个数据""" # 1. 获取数据 student_list = Student.objects.all() # 2. 实例化序列化器对象 # many=True的作用,就是告诉序列化器内部,当前instance的值是一个列表,所以需要循环 serializer = StudentSerializer(instance=student_list, many=True) # 3. 返回结果 # 通过data属性获取序列化器转换数据后的结果 print(serializer.data) """打印效果 [ OrderedDict([('id', 1), ('name', '小明'), ('age', 17), ('sex', True), ('text', 100)]), OrderedDict([('id', 2), ('name', '小明'), ('age', 17), ('sex', True), ('text', 100)]), OrderedDict([('id', 3), ('name', '小明'), ('age', 17), ('sex', True), ('text', 100)]), OrderedDict([('id', 4), ('name', '小明'), ('age', 17), ('sex', True), ('text', 100)]), OrderedDict([('id', 5), ('name', '小明'), ('age', 17), ('sex', True), ('text', 100)]), .... ] OrderedDict 是python的高级数据类型,叫有序字典 from collections import OrderedDict 因为python内置的基础类型的字典是无序的,所以这种无序字典无法不保证存储时的键值对顺序和提取时候的顺序一致 有序字典和无序字典,除了声明不一样以外,对于成员的读取和操作是一样的。 for item in serializer.data: # 获取有序字典的键值对 print(item["name"]) """ # JsonResponse 只是支持返回普通的字符串和字典,对于复杂的列表数据,需要设置参数safe=False return JsonResponse(serializer.data, safe=False, json_dumps_params={"ensure_ascii":False})
1.3.2.1 数据验证
开发中,用户的数据都是不可信任的。
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的客户端数据前,必须在视图中调用序列化对象的is_valid()方法,序列化器内部是在is_valid方法内部调用验证选项和验证方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误提示。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
测试环境准备工作
目录
为了方便演示,我们这里采用另一个图书模型来完成反序列化的学习。当然也创建一个新的子应用unsers。
python manage.py startapp unsers
注册子应用,setting.py注册子应用,代码:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', # 把drf框架注册到django项目中 'students', # 注册子应用 'sers', # 演示序列化 'unsers', # 演示反序列化 ]
注意:
# 接下来的内容涉及到postman post提交数据,所以在此时我们没有学习到drf视图方法时,我i们把settings.py中的中间件的csrf关闭. MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', # 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ]
drfdemo/urls.py总路由
"""drfdemo URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.2/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('students/', include("students.urls")), path('sers/', include("sers.urls")), path('unsers/', include("unsers.urls")), ]
unsers中urls.py分路由
from django.urls import path, re_path from . import views urlpatterns = [ path("books/", views.BookInfoView.as_view()), ]
unsers中models.py模型代码:
from django.db import models # Create your models here. class BookInfo(models.Model): """图书信息""" title = models.CharField(max_length=20, verbose_name='标题') pub_date = models.DateField(verbose_name='发布日期') image = models.ImageField(upload_to="avatar",verbose_name='图书封面') price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name="价格") read = models.IntegerField(verbose_name='阅读量') comment = models.IntegerField(verbose_name='评论量') class Meta: # db_table = "表名" db_table = "tb_book_info" verbose_name = "图书" verbose_name_plural = verbose_name

pip install Pillow
数据迁移
python manage.py makemigrations
python manage.py migrate
经过上面的准备工作,我们接下来就可以给图书信息增加图书的功能,那么我们需要对来自客户端的数据进行处理,例如,验证和保存到数据库中,此时,我们就可以使用序列化器的反序列化器,接下来,我们就可以参考之前定义学生信息的序列化器那样,定义一个图书的序列化器,当然,不同的是,接下来的序列化器主要用于反序列化器阶段,在unsers子应用,创建serializers.py,代码如下:
反序列化时:数据验证方式一(在序列化器中字段声明时,填写字段类型括号内选项参数(和forms组件类似))
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
unsers/serializers.py
from rest_framework import serializers from .models import BookInfo class BookInfoSerializers(serializers.Serializer): """图书信息的序列化器""" """ 1. 同一个序列化器的代码,既可以用于序列化器,也可以用于反序列化器 序列化器的序列化代码和反序列化代码是可以共用并写在一起的 2. 序列化器的反序列化一共可以通过三种方式来编写 2.1 字段选项, 2.2 内部方法,validate和validate_字段 这些方法中,只能用于当前所在的序列化器 2.3 外部函数,字段选项的validators引入的外部函数,可以提供给多个不同的序列化器引入使用 """ """字段选项""" # 能不能设置id只会在返回数据给客户端的时候,序列化器才调用呢? # 可以,设置id为只读字段,read_only,当字段设置为read_only为True,则当前字段只会在序列化阶段使用 # read_only取值的时候显示,存值的时候可为空 id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=True, min_length=2, max_length=6,error_messages={ "required":"标题不能为空!", "min_length":"最小长度3个字符", "max_length":"标题不能超过6个字符", "blank":"数据的值不能为空" }) # write_only=True 表示当前字段只会在反序列化阶段使用,客户端提交数据的时候使用,不会提供给客户端, # 简而言之,write_only存值的时候必须存,取值的时候不显示 pub_date = serializers.DateField(write_only=True) # 可以设置默认值,default="2016-06-24" price = serializers.DecimalField(required=True, max_digits=8, decimal_places=2) read = serializers.IntegerField() comment = serializers.IntegerField()
unsers/views.py
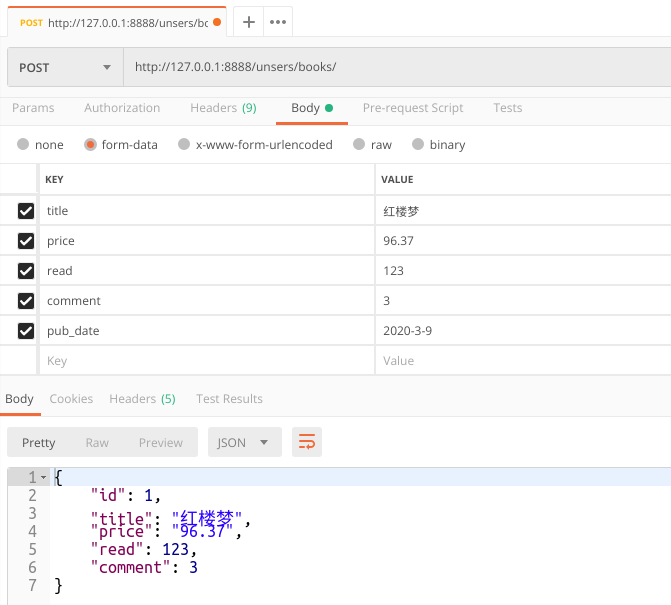
1 from django.views import View 2 from .models import BookInfo 3 from django.http import JsonResponse 4 from .serializers import BookInfoSerializers 5 6 # Create your views here. 7 class BookInfoView(View): 8 def post(self,request): 9 """反序列化,字段选项的校验""" 10 # 接收并实例化序列化器对象 11 serializer = BookInfoSerializers(data=request.POST) 12 # 启动验证 13 # is_valid 有个可选参数raise_exception,用于显示序列化器抛出的异常,直接终止视图代码的执行 14 # 如果设置了raise_exception=True,则下面的21~24行代码,就不要开发者自己编写,系统会自动根据请求的方式自动返回错误给客户端。 15 # 如果是ajax请求,则自动返回json格式的错误信息, 16 # 如果是表单请求,则自动返回html格式的错误信息 17 18 result = serializer.is_valid() 19 # result = serializer.is_valid(raise_exception=True) 20 print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 21 if not result: 22 # 当验证失败,则错误信息属性就有内容 23 print(serializer.errors) 24 return JsonResponse(serializer.errors) 25 else: 26 # 获取验证完成后的客户端数据 如果验证失败,则validated_data是空字典 27 print(serializer.validated_data) 28 29 # 把数据保存到数据库中 30 instance = BookInfo.objects.create(**serializer.validated_data) 31 32 # 返回结果,也是需要使用序列化进行转换的 33 serializer = BookInfoSerializers(instance=instance) 34 35 return JsonResponse(serializer.data)
postman测试:
反序列化时:数据验证方式二(在序列化器中提供的验证方法(validate_字段名、validate))进行验证数据
# 1 validate(data) 验证所有字段,data则表示客户端提交的数据,在实例化序列化器对象时的第二参数 # 2 validate_字段(data) 验证制定字段,data则表示来自客户端数据的指定字段值
unsers/serializers.py
from rest_framework import serializers from .models import BookInfo class BookInfoSerializers(serializers.Serializer): """图书信息的序列化器""" """ 1. 同一个序列化器的代码,既可以用于序列化器,也可以用于反序列化器 序列化器的序列化代码和反序列化代码是可以共用并写在一起的 2. 序列化器的反序列化一共可以通过三种方式来编写 2.1 字段选项, 2.2 内部方法,validate和validate_字段 这些方法中,只能用于当前所在的序列化器 2.3 外部函数,字段选项的validators引入的外部函数,可以提供给多个不同的序列化器引入使用 """ """字段选项""" # 能不能设置id只会在返回数据给客户端的时候,序列化器才调用呢? # 可以,设置id为只读字段,read_only,当字段设置为read_only为True,则当前字段只会在序列化阶段使用 # read_only取值的时候显示,存值的时候可为空 id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=True, min_length=2, max_length=6,error_messages={ "required":"标题不能为空!", "min_length":"最小长度3个字符", "max_length":"标题不能超过6个字符", "blank":"数据的值不能为空" }) # write_only=True 表示当前字段只会在反序列化阶段使用,客户端提交数据的时候使用,不会提供给客户端 # 简而言之,write_only存值的时候必须存,取值的时候不显示 pub_date = serializers.DateField(write_only=True) # 可以设置默认值,default="2016-06-24" price = serializers.DecimalField(required=True, max_digits=8, decimal_places=2) read = serializers.IntegerField() comment = serializers.IntegerField() """验证方法""" def validate_title(self, data): # 验证单个字段时,方法名必须固定为validate_字段, # data参数代表了指定字段的数据值,这里就是title字段值 if "老男孩" in data: """抛出异常""" raise serializers.ValidationError("对不起,当前标题不能出现关键字") # 验证方法必须要有返回值,这里的返回值将会被填写到 serailzier对象的validated_data里面 return data def validate(self, data): """验证多个字段时,方法名必须为validate, 参数data代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 开发中,类似 密码和确认密码,此时这2个字段,必须进行比较才能通过验证 """ print(data) # OrderedDict # 例如,我们要求图书的评论必须比阅读量要少 read = data.get("read") comment = data.get("comment") if read < comment: raise serializers.ValidationError("对不起,阅读量必须比评论量大") # 验证密码和确认密码 # 验证方法必须要有返回值 return data
unsers/views.py
from django.views import View from .models import BookInfo from django.http import JsonResponse from .serializers import BookInfoSerializers # Create your views here. class BookInfoView(View): def post(self,request): """反序列化,字段选项的校验""" # 接收并实例化序列化器对象 serializer = BookInfoSerializers(data=request.POST) # 启动验证 # is_valid 有个可选参数raise_exception,用于显示序列化器抛出的异常,直接终止视图代码的执行 # 如果设置了raise_exception=True,则下面的if not result错误判断代码,就不要开发者自己编写,系统会自动根据请求的方式自动返回错误给客户端。 # 如果是ajax请求,则自动返回json格式的错误信息, # 如果是表单请求,则自动返回html格式的错误信息 result = serializer.is_valid() # result = serializer.is_valid(raise_exception=True) print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 if not result: # 当验证失败,则错误信息属性就有内容 print(serializer.errors) return JsonResponse(serializer.errors) else: # 获取验证完成后的客户端数据 如果验证失败,则validated_data是空字典 print(serializer.validated_data) # 把数据保存到数据库中 instance = BookInfo.objects.create(**serializer.validated_data) # 返回结果,也是需要使用序列化进行转换的 serializer = BookInfoSerializers(instance=instance) return JsonResponse(serializer.data)
反序列化时:数据验证方式三(validators验证器)
验证器类似于验证方法,但是验证方法只属于当前序列化器,如果有多个序列化器共用同样的验证功能,则可以把验证代码分离到序列化器外部,作为一个普通函数,由validators加载到序列化器中使用。
在字段中添加validators选项参数,也可以补充验证行为,如
unsers/serializers.py
from rest_framework import serializers from .models import BookInfo # 在序列化器的外面声明一个验证函数 def check_price(data): # data代表要验证的数据 if data < 0: raise serializers.ValidationError("对不起,价格不能出现负数") # 验证函数也必须把数据返回 return data class BookInfoSerializers(serializers.Serializer): """图书信息的序列化器""" """ 1. 同一个序列化器的代码,既可以用于序列化器,也可以用于反序列化器 序列化器的序列化代码和反序列化代码是可以共用并写在一起的 2. 序列化器的反序列化一共可以通过三种方式来编写 2.1 字段选项, 2.2 内部方法,validate和validate_字段 这些方法中,只能用于当前所在的序列化器 2.3 外部函数,字段选项的validators引入的外部函数,可以提供给多个不同的序列化器引入使用 """ """字段选项""" # read_only取值的时候显示,存值的时候可为空 id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=True, min_length=2, max_length=6,error_messages={ "required":"标题不能为空!", "min_length":"最小长度3个字符", "max_length":"标题不能超过6个字符", "blank":"数据的值不能为空" }) # write_only=True 表示当前字段只会在反序列化阶段使用,客户端提交数据的时候使用,不会提供给客户端, # 简而言之,write_only存值的时候必须存,取值的时候不显示 pub_date = serializers.DateField(write_only=True) # 可以设置默认值,default="2016-06-24" # 调用验证器validators,这里的参数是一个列表,列表的成员是函数,函数名不能加引号 price = serializers.DecimalField(required=True, max_digits=8, decimal_places=2, validators=[check_price]) read = serializers.IntegerField() comment = serializers.IntegerField() """验证方法""" def validate_title(self, data): # 验证单个字段时,方法名必须固定为validate_字段, # data参数代表了指定字段的数据值,这里就指title的值 if "老男孩" in data: """抛出异常""" raise serializers.ValidationError("对不起,当前标题不能出现关键字") # 验证方法必须要有返回值,这里的返回值将会被填写到 serailzier对象的validated_data里面 return data def validate(self, data): """验证多个字段时,方法名必须为validate, 参数data代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 开发中,类似 密码和确认密码,此时这2个字段,必须进行比较才能通过验证 """ print(data) # OrderedDict # 例如,我们要求图书的评论必须比阅读量要少 read = data.get("read") comment = data.get("comment") if read < comment: raise serializers.ValidationError("对不起,阅读量必须比评论量大") # 验证密码和确认密码 # 验证方法必须要有返回值 return data
unsers/views.py
from django.views import View from .models import BookInfo from django.http import JsonResponse from .serializers import BookInfoSerializers # Create your views here. class BookInfoView(View): def post(self,request): """反序列化,字段选项的校验""" # 接收并实例化序列化器对象 serializer = BookInfoSerializers(data=request.POST) # 启动验证 # is_valid 有个可选参数raise_exception,用于显示序列化器抛出的异常,直接终止视图代码的执行 # 如果设置了raise_exception=True,则下面的if not result:错误判断代码,就不要开发者自己编写,系统会自动根据请求的方式自动返回错误给客户端。 # 如果是ajax请求,则自动返回json格式的错误信息, # 如果是表单请求,则自动返回html格式的错误信息 # result = serializer.is_valid() result = serializer.is_valid(raise_exception=True) print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 if not result: # 当验证失败,则错误信息属性就有内容 print(serializer.errors) return JsonResponse(serializer.errors) else: # 获取验证完成后的客户端数据 如果验证失败,则validated_data是空字典 print(serializer.validated_data) # 把数据保存到数据库中 instance = BookInfo.objects.create(**serializer.validated_data) # 返回结果,也是需要使用序列化进行转换的 serializer = BookInfoSerializers(instance=instance) return JsonResponse(serializer.data)
总结:
is_valid实际上内部执行了三种不同的验证方式: 1. 先执行了字段内置的验证选项 2. 在执行了validators自定义选项 3. 最后执行了validate自定义验证方法[包含了validate_<字段>, validate]
1.3.2.2 数据保存
通过序列化器来完成数据的更新或者添加,把视图中对于模型中的操作代码移出视图中,放入到序列化器。
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象.
注意:编写的create和update方法都是对于数据库的操作,所以不能保证百分百的操作成功,那么我们此时应该在数据库操作中进行容错处理,try...except...,当然也要抛出异常提供给视图,由视图转发给客户端,抛出异常则使用raise serializers.ValidationError。
可以通过实现create()和update()两个方法来实现。
unsers/serializers.py
from rest_framework import serializers from .models import BookInfo # 在序列化器的外面声明一个验证函数 def check_price(data): # data代表要验证的数据 if data < 0: raise serializers.ValidationError("对不起,价格不能出现负数") # 验证函数也必须把数据返回 return data class BookInfoSerializers(serializers.Serializer): """图书信息的序列化器""" """ 1. 同一个序列化器的代码,既可以用于序列化器,也可以用于反序列化器 序列化器的序列化代码和反序列化代码是可以共用并写在一起的 2. 序列化器的反序列化一共可以通过三种方式来编写 2.1 字段选项, 2.2 内部方法,validate和validate_字段 这些方法中,只能用于当前所在的序列化器 2.3 外部函数,字段选项的validators引入的外部函数,可以提供给多个不同的序列化器引入使用 """ """字段选项""" id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=True, min_length=2, max_length=6,allow_blank=True,error_messages={ "required":"标题不能为空!", "min_length":"最小长度3个字符", "max_length":"标题不能超过6个字符", "blank":"数据的值不能为空" }) pub_date = serializers.DateField(required=True, write_only=True) # 可以设置默认值,default="2016-06-24" # 调用验证器validators,这里的参数是一个列表,列表的成员是函数,函数名不能加引号 price = serializers.DecimalField(required=True, max_digits=8, decimal_places=2, validators=[check_price]) read = serializers.IntegerField() comment = serializers.IntegerField() """验证方法""" def validate_title(self, data): # 验证单个字段时,方法名必须固定为validate_字段, # data参数代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 if "老男孩" in data: """抛出异常""" raise serializers.ValidationError("对不起,当前标题不能出现关键字") # 验证方法必须要有返回值,这里的返回值将会被填写到 serailzier对象的validated_data里面 return data def validate(self, data): """验证多个字段时,方法名必须为validate, 参数data代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 开发中,类似 密码和确认密码,此时这2个字段,必须进行比较才能通过验证 """ # print(data) # OrderedDict # 例如,我们要求图书的评论必须比阅读量要少 read = data.get("read") comment = data.get("comment") if read < comment: raise serializers.ValidationError("对不起,阅读量必须比评论量大") # 验证密码和确认密码 # 验证方法必须要有返回值 return data # 数据保存代码 def create(self, validated_data): """数据添加操作的代码 validated_data,必须是验证通过的数据,也就是视图中serializer对象validated_data属性 原先视图中: # instance = BookInfo.objects.create(**serializer.validated_data) """ instance = BookInfo.objects.create(**validated_data) # 必须有返回值,就是本次创建的模型对象 return instance def update(self, instance, validated_data): """数据更新操作的代码 instance 本次修改数据的模型对象 validated_data,必须是验证通过的数据,也就是视图中serializer对象validated_data属性 """ # num = validated_data.get("num") # print(num) instance.title = validated_data.get("title") instance.pub_date = validated_data.get("pub_date") instance.read = validated_data.get("read") instance.price = validated_data.get("price") instance.comment = validated_data.get("comment") # ORM提供的数据保存方法 instance.save() # 必须有返回值,就是本次修改的模型对象 return instance
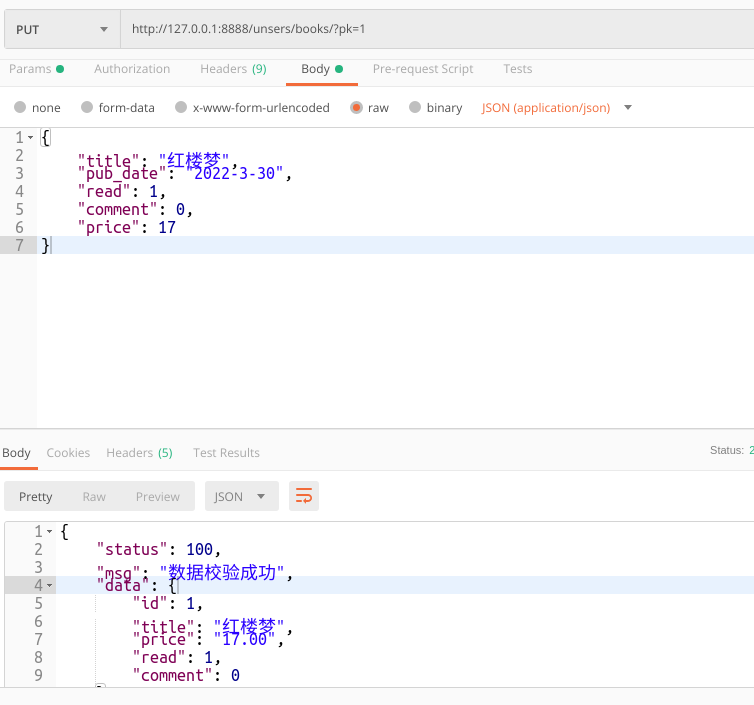
unsers/views.py(其中修改符合了restful 规范)
from django.views import View from .models import BookInfo from django.http import JsonResponse from .serializers import BookInfoSerializers # Create your views here. class BookInfoView(View): def post(self,request): """反序列化,字段选项的校验""" # 接收并实例化序列化器对象 serializer = BookInfoSerializers(data=request.POST) # 启动验证 # is_valid 有个可选参数raise_exception,用于显示序列化器抛出的异常,直接终止视图代码的执行 # 如果设置了raise_exception=True,则下面的19~22行代码,就不要开发者自己编写,系统会自动根据请求的方式自动返回错误给客户端。 # 如果是ajax请求,则自动返回json格式的错误信息, # 如果是表单请求,则自动返回html格式的错误信息 # result = serializer.is_valid() result = serializer.is_valid(raise_exception=True) # print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 if not result: # 当验证失败,则错误信息属性就有内容 print(serializer.errors) return JsonResponse(serializer.errors) else: # 获取验证完成后的客户端数据 如果验证失败,则validated_data是空字典 # print(serializer.validated_data) # 使用序列化器中的create保存数据方法 # instance = serializer.create(serializer.validated_data) # 序列化器实例化时,如果serializer有instance参数,则save会自动调用序列化器中update,否则就是调create # instance = serializer.save() # save会自动调用create/update方法 serializer.save() # 返回结果,如果显示还是原先的就在序列化一次 # serializer = BookInfoSerializers(instance=instance) return JsonResponse(serializer.data) def put(self, request): """修改操作""" reponse_msg = {"status":100,"msg":"数据校验成功"} # 查询要修改的模型对象 pk = request.GET.get("pk") try: instance = BookInfo.objects.get(pk=pk) except BookInfo.DoesNotExist: reponse_msg["status"] = 102 reponse_msg["msg"] = "对不起图书不存在" return JsonResponse(reponse_msg) # 接受客户端修改的数据 data = request.body # 针对django接受ajax的json数据,我们应该进行json序列化处理 import json data = json.loads(data) # 使用序列化器验证数据 serialzier = BookInfoSerializers(instance=instance,data=data) if serialzier.is_valid(): # 使用序列化器更新数据 # instance = serialzier.update(instance=instance, validated_data=serialzier.validated_data) # 序列化器提供的自动调用create和update方法 serialzier.save() # 因为上面serialzier有instance参数,所以就是save会自动识别为update reponse_msg['data'] = serialzier.data else: reponse_msg['status'] = 101 reponse_msg['msg'] = "数据校验未通过" reponse_msg['data'] = serialzier.errors return JsonResponse(reponse_msg)
postman测试put
总结:
在序列化器实现了create和update两个方法后,在反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了
instance = serialzier.save()
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
serailzier对象调用的save方法是什么?怎么做到自动调用update和create? 1. 这里的save不是数据库ORM模型对象的save,是BaseSerializer定义的。 2. save方法中根据实例化serializer时是否传入instance参数来判断执行update还是create的 当传入instance时,则instance.save调用的就是update方法 没有传入instance,则instance.save调用的就是create方法 3. serializer.save使用前提是必须在序列化器中声明create或者update方法,否则报错!!!
1.3.2.3 附加参数说明
1) 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
例如:
views.py视图中,使用序列化器保存时
# 可以传递任意参数到数据保存方法中 # 例如:request.user 是django中记录当前登录用户的模型对象 instance = serializer.save(owner=request.user)
serializers.py序列化器中接收
owner = validated_data.get("owner")
案例:看put
views.py


from django.views import View from .models import BookInfo from django.http import JsonResponse from .serializers import BookInfoSerializers # Create your views here. class BookInfoView(View): def post(self,request): """反序列化,字段选项的校验""" # 接收并实例化序列化器对象 serializer = BookInfoSerializers(data=request.POST) # 启动验证 # is_valid 有个可选参数raise_exception,用于显示序列化器抛出的异常,直接终止视图代码的执行 # 如果设置了raise_exception=True,则下面的19~22行代码,就不要开发者自己编写,系统会自动根据请求的方式自动返回错误给客户端。 # 如果是ajax请求,则自动返回json格式的错误信息, # 如果是表单请求,则自动返回html格式的错误信息 # result = serializer.is_valid() result = serializer.is_valid(raise_exception=True) # print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 if not result: # 当验证失败,则错误信息属性就有内容 print(serializer.errors) return JsonResponse(serializer.errors) else: # 获取验证完成后的客户端数据 如果验证失败,则validated_data是空字典 # print(serializer.validated_data) # 把数据保存到数据库中 # instance = BookInfo.objects.create(**serializer.validated_data) # 使用序列化器中的create保存数据方法 # instance = serializer.create(serializer.validated_data) # 序列化器实例化时,如果有save参数,则save相当于update,否则就是create instance = serializer.save() # save会自动调用create/update方法 # 返回结果,也是需要使用序列化进行转换的 serializer = BookInfoSerializers(instance=instance) return JsonResponse(serializer.data) def put(self, request): """修改操作""" # 查询要修改的模型对象 pk = request.GET.get("pk") try: instance = BookInfo.objects.get(pk=pk) except BookInfo.DoesNotExist: return JsonResponse("对不起,当前图书不存在!") # 接受客户端修改的数据 data = request.body # 针对django接受ajax的json数据,我们应该进行json序列化处理 import json data = json.loads(data) # 使用序列化器验证数据 serialzier = BookInfoSerializers(instance=instance,data=data) serialzier.is_valid(raise_exception=True) # 使用序列化器更新数据 # instance = serialzier.update(instance=instance, validated_data=serialzier.validated_data) # 序列化器提供的自动调用create和update方法 instance = serialzier.save(num=200) # 因为上面serialzier有instance参数,所以就是save会自动识别为update # 返回结果 serialzier = BookInfoSerializers(instance=instance) return JsonResponse(serialzier.data)
serializers.py
from rest_framework import serializers from .models import BookInfo # 在序列化器的外面声明一个验证函数 def check_price(data): # data代表要验证的数据 if data < 0: raise serializers.ValidationError("对不起,价格不能出现负数") # 验证函数也必须把数据返回 return data class BookInfoSerializers(serializers.Serializer): """图书信息的序列化器""" """ 1. 同一个序列化器的代码,既可以用于序列化器,也可以用于反序列化器 序列化器的序列化代码和反序列化代码是可以共用并写在一起的 2. 序列化器的反序列化一共可以通过三种方式来编写 2.1 字段选项, 2.2 内部方法,validate和validate_字段 这些方法中,只能用于当前所在的序列化器 2.3 外部函数,字段选项的validators引入的外部函数,可以提供给多个不同的序列化器引入使用 """ """字段选项""" id = serializers.IntegerField(read_only=True) title = serializers.CharField(required=True, min_length=2, max_length=6,allow_blank=True,error_messages={ "required":"标题不能为空!", "min_length":"最小长度3个字符", "max_length":"标题不能超过6个字符", "blank":"数据的值不能为空" }) pub_date = serializers.DateField(required=True, write_only=True) # 可以设置默认值,default="2016-06-24" # 调用验证器validators,这里的参数是一个列表,列表的成员是函数,函数名不能加引号 price = serializers.DecimalField(required=True, max_digits=8, decimal_places=2, validators=[check_price]) read = serializers.IntegerField() comment = serializers.IntegerField() """验证方法""" def validate_title(self, data): # 验证单个字段时,方法名必须固定为validate_字段, # data参数代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 if "老男孩" in data: """抛出异常""" raise serializers.ValidationError("对不起,当前标题不能出现关键字") # 验证方法必须要有返回值,这里的返回值将会被填写到 serailzier对象的validated_data里面 return data def validate(self, data): """验证多个字段时,方法名必须为validate, 参数data代表了所有字段的数据值,其实就是视图代码中实例化序列化器对象时的data参数 开发中,类似 密码和确认密码,此时这2个字段,必须进行比较才能通过验证 """ # print(data) # OrderedDict # 例如,我们要求图书的评论必须比阅读量要少 read = data.get("read") comment = data.get("comment") if read < comment: raise serializers.ValidationError("对不起,阅读量必须比评论量大") # 验证密码和确认密码 # 验证方法必须要有返回值 return data # 数据保存代码 def create(self, validated_data): """数据添加操作的代码 validated_data,必须是验证通过的数据,也就是视图中serializer对象validated_data属性 原先视图中: # instance = BookInfo.objects.create(**serializer.validated_data) """ instance = BookInfo.objects.create(**validated_data) # 必须有返回值,就是本次创建的模型对象 return instance def update(self, instance, validated_data): """数据更新操作的代码 instance 本次修改数据的模型对象 validated_data,必须是验证通过的数据,也就是视图中serializer对象validated_data属性 """ num = validated_data.get("num") print(num) instance.title = validated_data.get("title") instance.pub_date = validated_data.get("pub_date") instance.read = validated_data.get("read") instance.price = validated_data.get("price") instance.comment = validated_data.get("comment") # ORM提供的数据保存方法 instance.save() # 必须有返回值,就是本次修改的模型对象 return instance
2)默认序列化器必须传递所有必填字段[required=True],否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新
# Update `BookInfo` with partial data # partial=True 设置序列化器只是针对客户端提交的字段进行验证,没有提交的字段,即便有验证选项或方法也不进行验证。 serializer = BookInfoSerializer(book, data=data, partial=True)
小总结:
那么data就用于保存提供给客户端的数据,而validated_data就是用于保存提供给数据库的数据了。
综合案例:符合restful 规范
urls.py
from django.contrib import admin from django.urls import path,re_path from app01 import views urlpatterns = [ path('admin/', admin.site.urls), re_path('api/books/(?P<book_id>\d+)/', views.BookView.as_view()), path('api/books/',views.BooksView.as_view()) ]
models.py
from django.db import models # Create your models here. class Book(models.Model): name = models.CharField(max_length=32,verbose_name="图书名") price = models.DecimalField(max_digits=8,decimal_places=2) author = models.CharField(max_length=32) publish = models.CharField(max_length=32)
serializers.py
from rest_framework import serializers from app01.models import Book class BookSerializer(serializers.Serializer): name = serializers.CharField(max_length=4,min_length=2) price = serializers.CharField() author = serializers.CharField() publish = serializers.CharField() # 数据保存代码 def create(self, validated_data): """数据添加操作的代码 validated_data,必须是验证通过的数据,也就是视图中serializer对象validated_data属性 原先视图中: # instance = BookInfo.objects.create(**serializer.validated_data) """ instance = Book.objects.create(**validated_data) # 必须有返回值,就是本次创建的模型对象 return instance def update(self, instance, validated_data): # num = validated_data.get("num") # print(num) instance.name = validated_data.get("name") instance.price = validated_data.get("price") instance.author = validated_data.get("author") instance.publish = validated_data.get("publish") # ORM提供的数据保存方法 instance.save() # 必须有返回值,就是本次修改的模型对象 return instance
views.py
from django.shortcuts import render from django.views import View from rest_framework.views import APIView from app01.models import Book from app01.serializers import BookSerializer from rest_framework.response import Response from django.http import JsonResponse # Create your views here. class BookView(View): def get(self,request,book_id): reponse_msg = {"status": 100, "msg": "数据获取成功"} book = Book.objects.filter(pk=book_id).first() if book: serializer = BookSerializer(instance=book) reponse_msg["data"] = serializer.data print(serializer.data) # 转换后的字典数据 else: reponse_msg["status"] = 101 reponse_msg["msg"] = "数据获取失败" return JsonResponse(reponse_msg) def put(self,request,book_id): reponse_msg = {"status":100,"msg":"数据校验成功"} book = Book.objects.filter(pk=book_id).first() data = request.body import json data = json.loads(data) serializer = BookSerializer(instance=book, data=data) if serializer.is_valid(): serializer.save() reponse_msg['data'] = serializer.data else: reponse_msg['status'] = 101 reponse_msg['msg'] = "数据校验未通过" reponse_msg['data'] = serializer.errors return JsonResponse(reponse_msg) def delete(self,request,book_id): reponse_msg = {"status": 100, "msg": "数据删除成功"} book = Book.objects.filter(pk=book_id).delete() return JsonResponse(reponse_msg) class BooksView(View): def get(self,request): reponse_msg = {"status":100,"msg":"成功"} book = Book.objects.all() serializer = BookSerializer(instance=book,many=True) reponse_msg['data'] = serializer.data return JsonResponse(reponse_msg) # 新增 def post(self,request): reponse_msg = {"status":100,"msg":"成功"} serializer = BookSerializer(data=request.POST) if serializer.is_valid(): serializer.save() reponse_msg['data'] = serializer.data else: reponse_msg['status'] = 101 reponse_msg['msg'] = '数据校验失败' reponse_msg['data'] = serializer.errors return JsonResponse(reponse_msg)
1.3.3 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer基本相同,但提供了:
-
基于模型类自动生成一系列序列化器字段[基于模型自动生成序列化器的字段声明]
-
-
包含默认的create()和update()的实现
1.3.3.1 定义
比如我们创建一个BookInfoModelSerializer
"""模型序列化器""" """ ModelSerializer 是 Serializer的子类, 所以之前在Serializer里面使用过的功能和代码,都可以写在ModelSerializer """ from rest_framework import serializers from .models import BookInfo class BookInfoModelSerializer(serializers.ModelSerializer): # 字段声明[这里就是模型没有的字段],比如确认密码: commit_pwd = serializers.CharField() # 模型信息声明 class Meta: # 4个属性 model = BookInfo # 本次序列化器进行操作的模型类 # fields = "__all__" # 当前序列化器中调用所有模型中所有字段 fields = ["id","title","price","text","pub_date","read","comment"] # 当前序列化器中哪些字段参与数据转换 # 验证数据的补充属性,因为当前ModelSerializer的所有字段基本来自于模型 extra_kwargs = { "price":{"min_value": 0,"error_messages":{"min_value":"价格不能出现fush8u!"}}, # 字段选项,"validators":[],也在这里面加 } # 只读字段选项[声明那些字段只能用于序列化阶段] read_only_fields = ["id","text"] # 验证方法 validate_字段 或者 validate,和class Meta在同一级别 def validate_price(self, data): pass # 数据保存的方法 create或者 update,当然ModelSerializer默认提供了这2个方法
models.py
from django.db import models # Create your models here. class BookInfo(models.Model): """图书信息""" title = models.CharField(max_length=20, verbose_name='标题') pub_date = models.DateField(verbose_name='发布日期') image = models.ImageField(upload_to="avatar",verbose_name='图书封面') price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name="价格") read = models.IntegerField(verbose_name='阅读量') comment = models.IntegerField(verbose_name='评论量') @property def text(self): return 100 class Meta: # db_table = "表名" db_table = "tb_book_info" verbose_name = "图书" verbose_name_plural = verbose_name
1.3.3.2 指定字段
1) 使用fields来明确字段,__all__表名包含所有字段,也可以写明具体哪些字段,如
# fields = "__all__" # 当前序列化器中调用所有模型中所有字段 fields = ["id","title","price","text","pub_date","read","comment"] # 当前序列化器中那些字段参与数据转换
exclude = ('image',)
3) 指明只读字段
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
# 只读字段选项[声明那些字段只能用于序列化阶段] read_only_fields = ["id","text"]
1.3.3.3 添加额外参数
我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
# 验证数据的补充属性,因为当前ModelSerializer的所有字段基本来自于模型 extra_kwargs = { "price":{"min_value": 0,"error_messages":{"min_value":"价格不能出现fush8u!"}}, # 字段选项 }
补充:
extra_kwargs = { "price":{'write_only':True}, }
什么时候声明的序列化器需要继承序列化器基类Serializer,什么时候继承模型序列化器类ModelSerializer?
继承序列化器类Serializer 字段声明 验证 添加/保存数据功能 继承模型序列化器类ModelSerializer 字段声明[可选,看需要] Meta声明 验证 添加/保存数据功能[可选]
看表字段大小,看使用哪个更加节省代码了
完整案例:
总的路由:
drfdemo/urls.py
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('students/', include("students.urls")), path('sers/', include("sers.urls")), path('unsers/', include("unsers.urls")), # 模型类序列化器测试 ]
urls.py
from django.urls import path from . import views urlpatterns = [ path("books2/",views.BookInfo2View.as_view()) ]
serializers.py
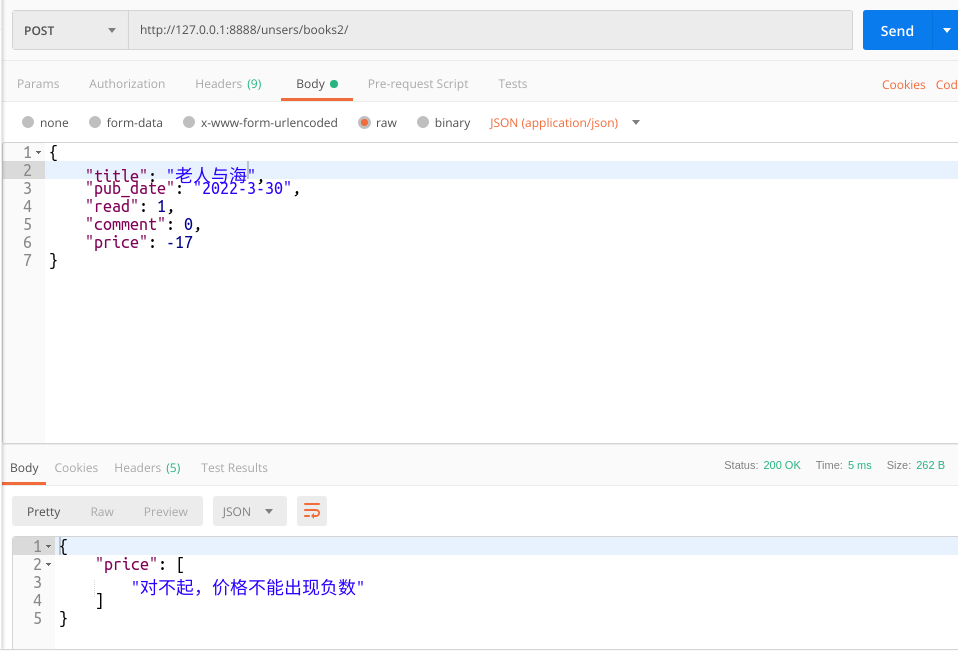
from rest_framework import serializers from .models import BookInfo class BookInfoModelSerializer(serializers.ModelSerializer): """模型序列化器""" """ ModelSerializer 是 Serializer的子类, 所以之前在Serializer里面使用过的功能和代码,都可以写在ModelSerializer """ # 字段声明[这里就是模型没有的字段] # 模型信息声明 class Meta: # 4个属性 model = BookInfo # 本次序列化器进行操作的模型类 # fields = "__all__" # 当前序列化器中调用所有模型中所有字段 fields = ["id", "title", "price", "text", "pub_date", "read", "comment"] # 当前序列化器中那些字段参与数据转换 # 验证数据的补充属性,因为当前ModelSerializer的所有字段基本来自于模型 extra_kwargs = { # "price": {"min_value": 0, "error_messages": {"min_value": "价格不能出现fush8u!"}}, # 字段选项 "price": {"validators": [check_price], "error_messages": {"min_value": "价格不能出现fush8u!"}}, # 字段选项"validators":[] } # 只读字段选项[声明那些字段只能用于序列化阶段] read_only_fields = ["id", "text"] # 验证方法 validate_字段 或者 validate # 数据保存的方法 create或者 update,当然ModelSerializer默认提供了这2个方法
views.py
from django.views import View from .models import BookInfo from django.http import JsonResponse from .serializers import BookInfoModelSerializer class BookInfo2View(View): def get(self, request): """获取所有的图书信息""" book_list = BookInfo.objects.all() serializer = BookInfoModelSerializer(instance=book_list, many=True) return JsonResponse(serializer.data, safe=False, json_dumps_params={"ensure_ascii": False}) def post(self, request): """添加图书信息""" # 接受来自于客户端的ajax数据 data = request.body import json data = json.loads(data) print(data) # 调用序列化器进行数据的验证 serializer = BookInfoModelSerializer(data=data) result = serializer.is_valid() # print(result) # 验证结果,True表示验证通过了,开发时一般不需要接收 if not result: # 当验证失败,则错误信息属性就有内容 print(serializer.errors) return JsonResponse(serializer.errors) else: instance = serializer.save() serializer = BookInfoModelSerializer(instance=instance) return JsonResponse(serializer.data)
models.py
from django.db import models # Create your models here. class BookInfo(models.Model): """图书信息""" title = models.CharField(max_length=20, verbose_name='标题') pub_date = models.DateField(verbose_name='发布日期') image = models.ImageField(upload_to="avatar",verbose_name='图书封面') price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name="价格") read = models.IntegerField(verbose_name='阅读量') comment = models.IntegerField(verbose_name='评论量') @property def text(self): return 100 class Meta: # db_table = "表名" db_table = "tb_book_info" verbose_name = "图书" verbose_name_plural = verbose_name
postman测试
get:
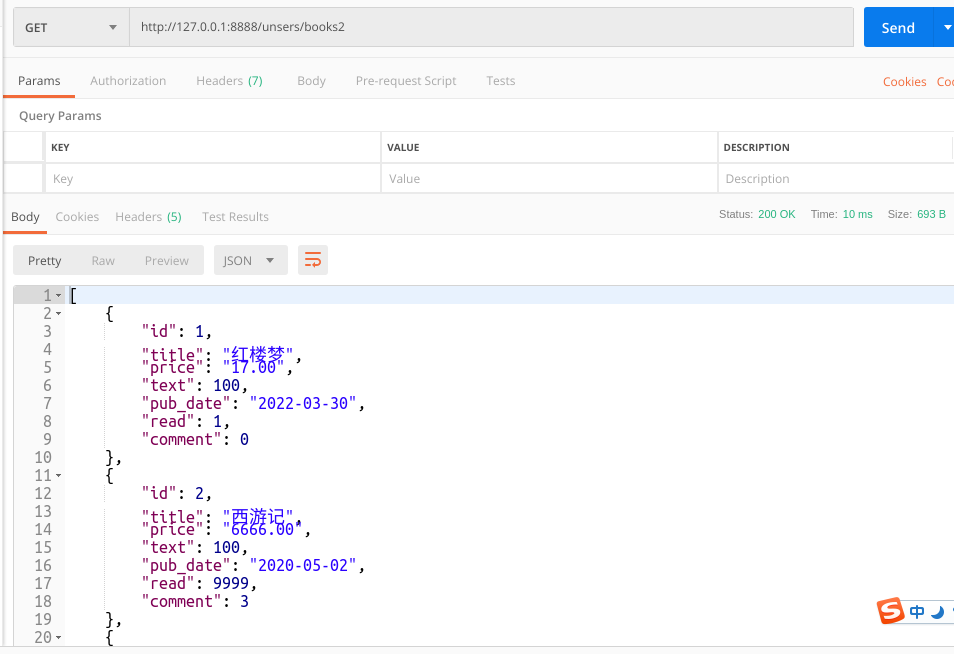
post:
1.4、序列化器高级用法
# source的使用 1 可以改字段名字 xxx=serializers.CharField(source='title') 2 可以.跨表publish=serializers.CharField(source='publish.email') 3 可以执行方法pub_date=serializers.CharField(source='test') test是Book表模型中的方法 # SerializerMethodField()的使用,可以用来重写某个字段 1 它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 authors=serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 def get_authors(self,instance): # book对象 authors=instance.authors.all() # 取出所有作者 ll=[] for author in authors: ll.append({'name':author.name,'age':author.age}) return ll
source的使用
models.py
from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=32) price = models.IntegerField() pub_date = models.DateField(default="2020-10-10") publish = models.ForeignKey("Publish", on_delete=models.CASCADE, null=True) authors = models.ManyToManyField("Author") def __str__(self): return self.title class Publish(models.Model): name = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() def __str__(self): return self.name
views.py
from rest_framework.views import APIView from app02.models import Book from app02.serializers import BookSerializer from rest_framework.response import Response # Create your views here. class App02BookView(APIView): def get(self,request,book_id): reponse_msg = {"status": 100, "msg": "数据获取成功"} book = Book.objects.filter(pk=book_id).first() if book: serializer = BookSerializer(instance=book) reponse_msg["data"] = serializer.data print(serializer.data) # 转换后的字典数据 else: reponse_msg["status"] = 101 reponse_msg["msg"] = "数据获取失败" return Response(reponse_msg)
改字段名
serializer.py
from rest_framework import serializers class BookSerializer(serializers.Serializer): book_title = serializers.CharField(max_length=4,min_length=2,source="title") price = serializers.CharField() pub_date = serializers.DateField() publish = serializers.CharField() # publish相当于book.publish,publish值是models.py模型类的__str__方法返回值,如果没有__str__则是模型类对象 authors = serializers.CharField()
跨表
from rest_framework import serializers class BookSerializer(serializers.Serializer): book_title = serializers.CharField(max_length=4,min_length=2,source="title") price = serializers.CharField() pub_date = serializers.DateField() publish = serializers.CharField(source="publish.email") authors = serializers.CharField()
可执行方法:
models.py
from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=32) price = models.IntegerField() pub_date = models.DateField(default="2020-10-10") publish = models.ForeignKey("Publish", on_delete=models.CASCADE, null=True) authors = models.ManyToManyField("Author") @property def test(self): return "2020-3-7" def __str__(self): return self.title class Publish(models.Model): name = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() def __str__(self): return self.name
serializers.py
from rest_framework import serializers class BookSerializer(serializers.Serializer): book_title = serializers.CharField(max_length=4,min_length=2,source="title") price = serializers.CharField() pub_date = serializers.DateField(source="test") # test是models.py中book类的一个属性方法 publish = serializers.CharField(source="publish.email") authors = serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 def get_authors(self, instance): # instance就是book对象 authors = instance.authors.all() # 取出所有作者 ll = [] for author in authors: ll.append({'name': author.name, 'age': author.age}) return ll
SerializerMethodField()的使用
from rest_framework import serializers class BookSerializer(serializers.Serializer): book_title = serializers.CharField(max_length=4,min_length=2,source="title") price = serializers.CharField() pub_date = serializers.DateField() publish = serializers.CharField(source="publish.email") authors = serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 def get_authors(self, instance): # instance就是book对象 authors = instance.authors.all() # 取出所有作者 ll = [] for author in authors: ll.append({'name': author.name, 'age': author.age}) return ll
1.5、补充序列化模型表中没有的字段方法
models.py
from django.db import models # Create your models here. class BaseModel(models.Model): is_delete = models.BooleanField(default=False) # auto_now_add=True 只要记录创建,不需要手动插入时间,自动把当前时间插入 create_time = models.DateTimeField(auto_now_add=True) # auto_now=True,只要更新,就会把当前时间插入 last_update_time = models.DateTimeField(auto_now=True) # import datetime # create_time=models.DateTimeField(default=datetime.datetime.now()) # 这是个坑,因为加括号以后所有时间都是项目运行的时间 # create_time=models.DateTimeField(default=datetime.datetime.now) # 如果要用这样用 class Meta: # 单个字段,有索引,有唯一 # 多个字段,有联合索引,联合唯一 abstract = True # 抽象表,不在数据库建立出表 class Book(BaseModel): # verbose_name admin中显示中文 name = models.CharField(max_length=32, verbose_name='书名', help_text='这里填书名') price = models.DecimalField(max_digits=8, decimal_places=2) # 一对多的关系一旦确立,关联字段写在多的一方, # to 指名关联的表 # to_field 默认不写,关联到Publish主键 # db_constraint=False 逻辑上的关联,实质上没有外键练习,增删不会受外键影响,但是orm查询不影响 publish = models.ForeignKey(to='Publish', on_delete=models.DO_NOTHING, db_constraint=False) # 多对多,跟作者,关联字段写在 查询次数多的一方 # 什么时候用自动,什么时候用手动?第三张表只有关联字段,用自动 第三张表有扩展字段,需要手动写 # 不能写on_delete authors = models.ManyToManyField(to='Author', db_constraint=False) class Meta: verbose_name_plural = '书表' # admin中表名的显示 def __str__(self): return self.name @property def publish_name(self): return self.publish.name # def author_list(self): def author_list(self): author_list = self.authors.all() # ll=[] # for author in author_list: # ll.append({'name':author.name,'sex':author.get_sex_display()}) # return ll return [{'name': author.name, 'sex': author.get_sex_display()} for author in author_list] class Publish(BaseModel): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) def __str__(self): return self.name class Author(BaseModel): name = models.CharField(max_length=32) sex = models.IntegerField(choices=((1, '男'), (2, '女'))) # 一对一关系,写在查询频率高的一方 # OneToOneField本质就是ForeignKey+unique,自己手写也可以 authordetail = models.OneToOneField(to='AuthorDetail', db_constraint=False, on_delete=models.CASCADE) class AuthorDetail(BaseModel): mobile = models.CharField(max_length=11)
ser.py
from rest_framework import serializers from api import models class BookModelSerializer(serializers.ModelSerializer): # publish,显示出版社名称 # 一种方案(只序列化可以,反序列化有问题) # publish=serializers.CharField(source='publish.name') # 第二种方案,models中写方法(看models.py) class Meta: list_serializer_class = BookListSerializer model = models.Book # fields='__all__' # 用的少 # depth=0 fields = ('id', 'name', 'price', 'authors', 'publish', 'publish_name', 'author_list') extra_kwargs = { 'publish': {'write_only': True}, 'publish_name': {'read_only': True}, 'authors': {'write_only': True}, 'author_list': {'read_only': True} }
第三种方法:反序列化
models.py
from django.db import models from luffyapi.utils.models import BaseModel # 实际luffy中的表,免费课的 class CourseCategory(BaseModel): """ 课程分类 python,linux,go, 网络安全 跟课程是一对多的关系 """ name = models.CharField(max_length=64, unique=True, verbose_name="分类名称") class Meta: db_table = "luffy_course_category" verbose_name = "分类" verbose_name_plural = verbose_name def __str__(self): return "%s" % self.name class Course(BaseModel): """课程""" course_type = ( (0, '付费'), (1, 'VIP专享'), (2, '学位课程') ) level_choices = ( (0, '初级'), (1, '中级'), (2, '高级'), ) status_choices = ( (0, '上线'), (1, '下线'), (2, '预上线'), ) # 原始字段 name = models.CharField(max_length=128, verbose_name="课程名称") course_img = models.ImageField(upload_to="courses", max_length=255, verbose_name="封面图片", blank=True, null=True) course_type = models.SmallIntegerField(choices=course_type, default=0, verbose_name="付费类型") # 使用这个字段的原因 brief = models.TextField(max_length=2048, verbose_name="详情介绍", null=True, blank=True) level = models.SmallIntegerField(choices=level_choices, default=0, verbose_name="难度等级") pub_date = models.DateField(verbose_name="发布日期", auto_now_add=True) period = models.IntegerField(verbose_name="建议学习周期(day)", default=7) attachment_path = models.FileField(upload_to="attachment", max_length=128, verbose_name="课件路径", blank=True, null=True) status = models.SmallIntegerField(choices=status_choices, default=0, verbose_name="课程状态") price = models.DecimalField(max_digits=6, decimal_places=2, verbose_name="课程原价", default=0) # 优化字段 students = models.IntegerField(verbose_name="学习人数", default=0) sections = models.IntegerField(verbose_name="总课时数量", default=0) pub_sections = models.IntegerField(verbose_name="课时更新数量", default=0) # 关联字段 teacher = models.ForeignKey("Teacher", on_delete=models.DO_NOTHING, null=True, blank=True, verbose_name="授课老师", db_constraint=False) course_category = models.ForeignKey("CourseCategory", on_delete=models.SET_NULL, db_constraint=False, null=True, blank=True, verbose_name="课程分类") class Meta: db_table = "luffy_course" verbose_name = "课程" verbose_name_plural = "课程" def __str__(self): return "%s" % self.name # @property # def course_category_name(self): # return self.course_category.name @property def course_type_name(self): return self.get_course_type_display() @property def level_name(self): return self.get_level_display() @property def status_name(self): return self.get_status_display() @property def section_list(self): ll = [] # 根据课程取出所有章节(反向查询,related_name.all()) course_chapter_list = self.coursechapters.all() for course_chapter in course_chapter_list: # 通过章节对象,取到章节下所有的课时(反向查询) # course_chapter.表名小写_set.all() 现在变成了course_chapter.coursesections.all() course_sections_list = course_chapter.coursesections.all() for course_section in course_sections_list: ll.append({ 'name': course_section.name, 'section_link': course_section.section_link, 'duration': course_section.duration, 'free_trail': course_section.free_trail, }) if len(ll) >= 4: return ll return ll class Teacher(BaseModel): """ 导师 跟课程一对多,关联字段写在课程表中 """ role_choices = ( (0, '讲师'), (1, '导师'), (2, '班主任'), ) name = models.CharField(max_length=32, verbose_name="导师名") role = models.SmallIntegerField(choices=role_choices, default=0, verbose_name="导师身份") title = models.CharField(max_length=64, verbose_name="职位、职称") signature = models.CharField(max_length=255, verbose_name="导师签名", help_text="导师签名", blank=True, null=True) image = models.ImageField(upload_to="teacher", null=True, verbose_name="导师封面") brief = models.TextField(max_length=1024, verbose_name="导师描述") class Meta: db_table = "luffy_teacher" verbose_name = "导师" verbose_name_plural = verbose_name def __str__(self): return "%s" % self.name def role_name(self): # 返回角色的中文 return self.get_role_display() class CourseChapter(BaseModel): """ 章节 章节跟课程是一(课程)对多(章节多) """ course = models.ForeignKey("Course", related_name='coursechapters', on_delete=models.CASCADE, verbose_name="课程名称", db_constraint=False) chapter = models.SmallIntegerField(verbose_name="第几章", default=1) name = models.CharField(max_length=128, verbose_name="章节标题") summary = models.TextField(verbose_name="章节介绍", blank=True, null=True) pub_date = models.DateField(verbose_name="发布日期", auto_now_add=True) class Meta: db_table = "luffy_course_chapter" verbose_name = "章节" verbose_name_plural = verbose_name def __str__(self): return "%s:(第%s章)%s" % (self.course, self.chapter, self.name) class CourseSection(BaseModel): """ 课时 章节和课时是一对多的关系,关联字段写在多的一方,课时 """ section_type_choices = ( (0, '文档'), (1, '练习'), (2, '视频') ) chapter = models.ForeignKey("CourseChapter", related_name='coursesections', on_delete=models.CASCADE, verbose_name="课程章节", db_constraint=False) name = models.CharField(max_length=128, verbose_name="课时标题") orders = models.PositiveSmallIntegerField(verbose_name="课时排序") section_type = models.SmallIntegerField(default=2, choices=section_type_choices, verbose_name="课时种类") section_link = models.CharField(max_length=255, blank=True, null=True, verbose_name="课时链接", help_text="若是video,填vid,若是文档,填link") duration = models.CharField(verbose_name="视频时长", blank=True, null=True, max_length=32) # 仅在前端展示使用 pub_date = models.DateTimeField(verbose_name="发布时间", auto_now_add=True) free_trail = models.BooleanField(verbose_name="是否可试看", default=False) class Meta: db_table = "luffy_course_Section" verbose_name = "课时" verbose_name_plural = verbose_name def __str__(self): return "%s-%s" % (self.chapter, self.name) @property def section_type_name(self): return self.get_section_type_display()
serializers.py
from rest_framework import serializers from . import models class CourseCategorySerializer(serializers.ModelSerializer): class Meta: model = models.CourseCategory fields = ['id', 'name'] class TeacherSerializer(serializers.ModelSerializer): class Meta: model = models.Teacher fields = ('name', 'role_name', 'title', 'signature', 'image', 'brief') class CourseModelSerializer(serializers.ModelSerializer): # 子序列化的方式 teacher = TeacherSerializer() class Meta: model = models.Course fields = [ 'id', 'name', 'course_img', 'brief', 'attachment_path', 'pub_sections', 'price', 'students', 'period', 'sections', 'course_type_name', 'level_name', 'status_name', 'teacher', 'section_list', # 'course_category_name' ] # fields = ['id', 'name', # 'course_img', # 'brief', # 'teacher', # 'course_type_name', # 'status_name', # 'level_name', # 'course_sections' # ] class CourseSectionSerializer(serializers.ModelSerializer): class Meta: model = models.CourseSection fields = ['name', 'orders', 'duration', 'free_trail', 'section_link', 'section_type_name'] class CourseChapterSerializer(serializers.ModelSerializer): # 子序列化方式 coursesections = CourseSectionSerializer(many=True) class Meta: model = models.CourseChapter fields = ['name', 'summary', 'chapter', 'coursesections']

