学习Django框架前的预热知识
一、先写一个web框架,也就是后端服务器
1、服务端代码
import socket server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 如果为空默认为TCP server.bind(("127.0.0.1",9000)) server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) server.listen(5) while True: conn,addr = server.accept() data = conn.recv(1024) print(data) #先研究这个data conn.send(b"HTTP1.1 200 ok\r\n\r\n Hello world") #加http协议的回应头,和回应码,注意\r\n\r\n不能少 conn.close()
2、客户端浏览器访问这个web服务端
访问时加不同的后缀,之后查看服务端
3、查看服务端

""" b'GET /index HTTP/1.1\r\n Host: 127.0.0.1:9000\r\n Connection: keep-alive\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36\r\n Sec-Fetch-Dest: document\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n Sec-Fetch-Site: none\r\n Sec-Fetch-Mode: navigate\r\n Sec-Fetch-User: ?1\r\n Accept-Encoding: gzip, deflate, br\r\n Accept-Language: zh-CN,zh;q=0.9\r\n\r\n' """ """ b'GET /login HTTP/1.1\r\n Host: 127.0.0.1:9000\r\n Connection: keep-alive\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36\r\n Sec-Fetch-Dest: document\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n Sec-Fetch-Site: none\r\n Sec-Fetch-Mode: navigate\r\n Sec-Fetch-User: ?1\r\n Accept-Encoding: gzip, deflate, br\r\n Accept-Language: zh-CN,zh;q=0.9\r\n\r\n' """
注意:我们只看圈出来的,那两个/favicon.ico我们不关注
通过服务端接收我们发现,在访问时加的后缀时,后端查看就是圈出来的数据第二个字段
二、根据需求一步步接近Django
需求一:
根据客户端浏览器输入时添加的不同后缀,服务端返回不同的内容
例如:
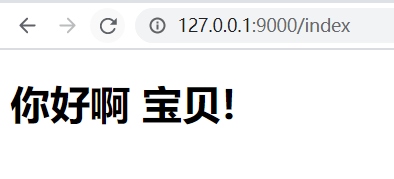
客户端浏览器输入http://127.0.0.1:9000/index;服务端返回index
实现:
根据一中我们已经直到,浏览器输入的后缀可以在服务端接收的data获取到,就是data的第二个字段;so,服务端接收到data后可以对data字符串进行decode("utf-8")解码,之后split切割,搞成列表,这样后缀就是获取到的列表索引为1的元素
代码:
import socket server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 如果为空默认为TCP server.bind(("127.0.0.1",9000)) server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) server.listen(5) while True: conn,addr = server.accept() data = conn.recv(1024) data=data.decode("utf-8") #字符串 current_path = data.split()[1] #取到后缀 # print(current_path) #发回应头和回应码 conn.send(b"HTTP1.1 200 ok\r\n\r\n") #和要发的内容分开,分两次发 #拿到路径后进行判断 if current_path == "/index": conn.send(b"This is index ") elif current_path == "/login": conn.send(b"This is login ") elif current_path == "/": conn.send(b"hello web ") else: conn.send(b"404") conn.close()
需求二:根据输入返回html页面
代码:
import socket server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 如果为空默认为TCP server.bind(("127.0.0.1",9000)) server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) server.listen(5) while True: conn,addr = server.accept() data = conn.recv(1024) data=data.decode("utf-8") #字符串 current_path = data.split()[1] #取到后缀 # print(current_path) #发回应头和回应码 conn.send(b"HTTP1.1 200 ok\r\n\r\n") #和要发的内容分开,分两次发 #拿到路径后进行判断 if current_path == "/index": with open("index.html","rb") as f: conn.send(f.read()) elif current_path == "/login": conn.send(b"This is login ") elif current_path == "/": conn.send(b"hello web ") else: conn.send(b"404") conn.close()
总结:纯手撸版本的不足之处
#不足之处 1.代码重复(服务端代码所有人都要重复写) 2.手动处理http格式的数据 并且只能拿到url后缀 其他数据获取繁琐(数据格式一样处理的代码其实也大致一样 重复写) 3.并发的问题
基于wsgiref模块实现上面的需求
""" urls.py 路由与视图函数对应关系 views.py 视图函数(后端业务逻辑) templates文件夹 专门用来存储html文件 """ # 按照功能的不同拆分之后 后续添加功能只需要在urls.py书写对应关系然后取views.py书写业务逻辑即可
目录:
基于wsgrief模块web框架.py代码:
from wsgiref.simple_server import make_server def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据,和socket一样传输要转成二进制格式 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 拿到路径后进行判断 if current_path == "/index": with open("index.html", "rb") as f: return [f.read()] # 写法固定,返回数据用列表包起来 elif current_path == "/login": return [b"login"] elif current_path == "/": return [b"hello web"] else: return [b"404 heihei"] if __name__ == '__main__': """ 会实时监听127.0.0.1:9000地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
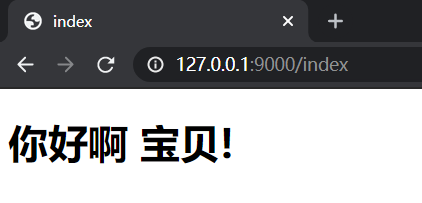
基于wsgiref模块实现需求后代码进行封装
# 开发人员: alias # 开发时间: 2020/5/22 18:58 # 文件名称: 基于wsgrief模块web框架.py # 开发工具: PyCharm from wsgiref.simple_server import make_server #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("index.html", "rb") as f: return f.read().decode("utf-8") # 先解码,下面return再统一编码 #访问路径为/login的处理函数 def login(env): return "This is login" #访问路径不存在的处理函数 def error(env): return "404" #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ] def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: #这个url就是一个个元组 if current_path == url[0]: #将url对应的函数名赋值给func func = url[1] #匹配到之后结束循环 break # 判断func是否为None if func: res=func(env) #将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res=error(env) #返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
进一步对wsgrief实现的功能代码进行拆分(因为代码多后会比较乱,所以将功能拆分成不同的文件)
文件说明:
# urls.py:存放url和处理函数的对应关系 # views.py:存放处理函数 # 基于wsgrief模块web框架.py: 入口文件
# index.html:处理函数返回给前端的html文件
urls.py
""" 存放url和处理函数的对应关系 """ #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ]
views.py
""" 存放处理函数 """ #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("index.html", "r" , encoding="utf-8") as f: return f.read() #访问路径为/login的处理函数 def login(env): return "This is login" #访问路径不存在的处理函数 def error(env): return "404"
基于wsgrief模块web框架.py
from wsgiref.simple_server import make_server from urls import urls from views import * def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: #这个url就是一个个元组 if current_path == url[0]: #将url对应的函数名赋值给func func = url[1] #匹配到之后结束循环 break # 判断func是否为None if func: res=func(env) #将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res=error(env) #返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
更进一步对wsgrief实现的功能代码进行拆分(考虑当文件比较多的时候,使用文件夹进行划分)
目录:

首先文件说明:
""" urls.py 路由与视图函数对应关系 views.py 视图函数(后端业务逻辑) templates文件夹 专门用来存储html文件 """ # 按照功能的不同拆分之后 后续添加功能只需要在urls.py书写对应关系然后取views.py书写业务逻辑即可
urls.py


""" 存放url和处理函数的对应关系 """ #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ]
views.py
""" 存放处理函数 """ #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("./templats/index.html", "r", encoding="utf-8") as f: return f.read() #访问路径为/login的处理函数 def login(env): with open("./templats/login.html", "r", encoding="utf-8") as f: return f.read() #访问路径不存在的处理函数 def error(env): return "404"
基于wsgrief模块web框架.py
from wsgiref.simple_server import make_server from urls import urls from views import * def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: #这个url就是一个个元组 if current_path == url[0]: #将url对应的函数名赋值给func func = url[1] #匹配到之后结束循环 break # 判断func是否为None if func: res=func(env) #将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res=error(env) #返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
动静态网页
""" 静态网页 页面上的数据是直接写死的 万年不变 动态网页 数据是实时获取的 eg: 1.后端获取当前时间展示到html页面上 2.数据是从数据库中获取的展示到html页面上 """
制作动态网页
1、后端获取当前时间展示到html页面上(使用比较low的方法)

基于wsgrief模块web框架.py,这个接口文件不变
from wsgiref.simple_server import make_server from urls import urls from views import * def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: #这个url就是一个个元组 if current_path == url[0]: #将url对应的函数名赋值给func func = url[1] #匹配到之后结束循环 break # 判断func是否为None if func: res=func(env) #将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res=error(env) #返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
urls.py里面添加路由
from views import * """ 存放url和处理函数的对应关系 """ #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ("/get_time",get_time), ]
views.py里面添加视图函数
import time """ 存放处理函数 """ #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("./templates/index.html", "r", encoding="utf-8") as f: return f.read() #访问路径为/login的处理函数 def login(env): with open("./templates/login.html", "r", encoding="utf-8") as f: return f.read() #访问路径不存在的处理函数 def error(env): return "404" #获取当前时间,展示到前端 def get_time(env): #先获取当前时间 current_time = time.strftime("%Y-%m-%d %X") #如何将后端获取到的数据传递给html文件 with open("./templates/mytime.html","r",encoding="utf-8") as f: data = f.read() data = data.replace("dadfafdadfa",current_time) return data
mytime.html:返回的前端页面
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>mytime</title> </head> <body> <!--随便写的字符串用于替换成当前时间--> dadfafdadfa </body> </html>
2、将一个字典传递给html文件 并且可以在文件上方便快捷的操作字典数据(使用模板语法:Jinja2模块)
jinja2模块安装方法:
#pip3 install jinja2
目录:

基于wsgrief模块web框架.py,这个接口文件不变
from wsgiref.simple_server import make_server from urls import urls from views import * def run(env, response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok", []) # 响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') # 取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: # 这个url就是一个个元组 if current_path == url[0]: # 将url对应的函数名赋值给func func = url[1] # 匹配到之后结束循环 break # 判断func是否为None if func: res = func(env) # 将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res = error(env) # 返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1", 9000, run) # 这个函数有个server返回值要接收一下 server.serve_forever() # 启动服务端
urls.py添加路由
from views import * """ 存放url和处理函数的对应关系 """ #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ("/get_time",get_time), ("/get_dict",get_dict), #添加get_dict路由关系 ]
views.py添加视图函数
import time from jinja2 import Template """ 存放处理函数 """ #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("./templates/index.html", "r", encoding="utf-8") as f: return f.read() #访问路径为/login的处理函数 def login(env): with open("./templates/login.html", "r", encoding="utf-8") as f: return f.read() #访问路径不存在的处理函数 def error(env): return "404" #获取当前时间,展示到前端 def get_time(env): #先获取当前时间 current_time = time.strftime("%Y-%m-%d %X") #如何将后端获取到的数据传递给html文件 with open("./templates/mytime.html","r",encoding="utf-8") as f: data = f.read() data = data.replace("dadfafdadfa",current_time) return data #获取字典 def get_dict(env): #定义一个字典用于发往html文件 user_dic = {"username":"egon","age":18} with open("./templates/get_dict.html","r",encoding="utf-8") as f: data = f.read() tmp = Template(data) # 将html文件读出来的data放入Template之后赋给变量tmp,之后就可以给这个html文件传值了 # 给get_dict.html传递了一个值,get_dict.html页面内部通过变量名user就能拿到user_dic,在get_dict.html页面内部怎么引用见get_dict,html res = tmp.render(user=user_dic) return res
get_dict.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>get_dict</title> </head> <body> <!--两个大括号,里面加上视图函数传递过来的变量名,这个变量名就对应那个字典user_dic--> {{ user }} <!--可以很方便的控制绑定过来的字典,例如字典取值,有三种方式--> {{ user.get("username") }} {{ user.age }} {{ user["username"] }} </body> </html>
浏览器访问

实践:后端获取数据库中的数据进行前端展示
准备一下数据库:

目录:

基于wsgrief模块web框架.py,这个接口文件不变
from wsgiref.simple_server import make_server from urls import urls from views import * def run(env,response): """ 两个模块加括号调用传过来的参数env,response以及return解释: :param env:请求相关的所有数据 :param response:响应相关的所有数据 :return:返回给浏览器的数据 """ # print(env) #根据env的大字典,可以发现,浏览器输入的后缀在大字典中的key为'PATH_INFO' """ env是一个大字典,字典包含了请求里面的所有数据,还封装了一些其他数据 (这个工作是wsgrief模块做的,帮我们处理好http格式的数据 封装成了字典,让你更加方便的去操作) """ response("200 ok",[]) #响应首行,加响应头[],列表内为空就行 current_path = env.get('PATH_INFO') #取到后缀路径 # 定义一个变量,存储匹配到的函数名 func = None for url in urls: #这个url就是一个个元组 if current_path == url[0]: #将url对应的函数名赋值给func func = url[1] #匹配到之后结束循环 break # 判断func是否为None if func: res=func(env) #将env一同传给函数接收的好处,功能更加强调,方便函数对字典进行各种操作 else: res=error(env) #返回数据 return [res.encode("utf-8")] # 写法固定,返回数据用列表包起来 if __name__ == '__main__': """ 会实时监听127.0.0.1:8080地址 只要有客户端来了都会交给run函数处理(模块会加括号触发run函数的运行) 注意:在加括号调用run函数的时候模块会自动传入两个参数(env,response) """ server = make_server("127.0.0.1",9000,run) #这个函数有个server返回值要接收一下 server.serve_forever() #启动服务端
urls.py添加路由
from views import * """ 存放url和处理函数的对应关系 """ #url与函数的对应关系 urls = [ ("/index",index), ("/login",login), ("/get_time",get_time), ("/get_dict",get_dict), ("/get_user",get_user), ]
views.py添加视图函数
import time from jinja2 import Template import pymysql """ 存放处理函数 """ #访问路径为/index的处理函数 def index(env): # 拿到路径后进行判断 with open("./templates/index.html", "r", encoding="utf-8") as f: return f.read() #访问路径为/login的处理函数 def login(env): with open("./templates/login.html", "r", encoding="utf-8") as f: return f.read() #访问路径不存在的处理函数 def error(env): return "404" #获取当前时间,展示到前端 def get_time(env): #先获取当前时间 current_time = time.strftime("%Y-%m-%d %X") #如何将后端获取到的数据传递给html文件 with open("./templates/mytime.html","r",encoding="utf-8") as f: data = f.read() data = data.replace("dadfafdadfa",current_time) return data #获取字典 def get_dict(env): #定义一个字典用于发往html文件 user_dic = {"username":"egon","age":18} with open("./templates/get_dict.html","r",encoding="utf-8") as f: data = f.read() tmp = Template(data) # 将html文件读出来的data放入Template之后赋给变量tmp,之后就可以给这个html文件传值了 # 给get_dict.html传递了一个值,get_dict.html页面内部通过变量名user就能拿到user_dic res = tmp.render(user=user_dic) return res def get_user(env): #去数据库中获取数据,传递给html页面,借助于模板语法 发送给浏览器 # 链接 conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='123456', database='atm_db', charset='utf8', # autocommit=True # 自动提交 ) # 游标 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #执行完毕返回的结果集以字典显示 # 执行sql语句 sql = 'select * from userinfo' rows = cursor.execute(sql) # 执行sql语句,返回sql查询成功的记录数目 # 获取数据: data_list = cursor.fetchall() # [{},{},,,,]列表套字典格式 cursor.close() conn.close() #将获取到的数据传递给html文件 with open("./templates/user_info.html", "r", encoding="utf-8") as f: data = f.read() tmp = Template(data) # 给user_info.html传递了一个值,user_info.html页面内部通过变量名user_data就能拿到data_list res = tmp.render(user_data=data_list) return res
user_info.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>userinfo</title> <!-- Bootstrap3 核心 CSS 文件 --> <link href="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/css/bootstrap.min.css" rel="stylesheet"> <!-- jQuery文件。务必在bootstrap.min.js 之前引入 --> <script src="https://cdn.staticfile.org/jquery/2.1.1/jquery.min.js"></script> <!-- Bootstrap3 核心 JavaScript 文件 --> <script src="https://cdn.staticfile.org/twitter-bootstrap/3.3.7/js/bootstrap.min.js"></script> <!-- <link rel="stylesheet" href="css/font-awesome.min.css"> --> <link href="https://cdn.bootcss.com/font-awesome/4.7.0/css/font-awesome.min.css" rel="stylesheet"> </head> <body> <div class="container"> <div class="row"> <div class="col-md-8 col-md-offset-2"> <h1 class="text-center">用户数据</h1> <br/> <table class="table table-striped table-hover"> <thead> <tr> <th class="text-center">ID</th> <th class="text-center">username</th> <th class="text-center">password</th> <th class="text-center">balance</th> <th class="text-center">flow</th> </tr> </thead> <tbody> {% for user_dict in user_data %} <tr> <td>{{ user_dict.id}}</td> <td>{{ user_dict.username}}</td> <td>{{ user_dict.password}}</td> <td>{{ user_dict.balance}}</td> <td>{{ user_dict.flow}}</td> </tr> {% endfor %} </tbody> </table> </div>> </div> </div> </body> </html>
浏览器访问效果:

总结:jinja2使用
# pip3 install jinja2 # 安装方法 """模版语法是在后端起作用的""" # 模版语法(非常贴近python语法) {{ user }} {{ user.get('username')}} #获取值 {{ user.age }} {{ user['hobby'] }} # 模板语法支持for循环 {% for user_dict in user_data %} <tr> <td>{{ user_dict.id}}</td> <td>{{ user_dict.username}}</td> <td>{{ user_dict.password}}</td> <td>{{ user_dict.balance}}</td> <td>{{ user_dict.flow}}</td> </tr> {% endfor %}
自定义简易版本web框架请求流程图
""" wsgiref模块做的两件事 1.请求来的时候解析http格式的数据 封装成大字典 2.响应走的时候给数据打包成符合http格式 再返回给浏览器 """
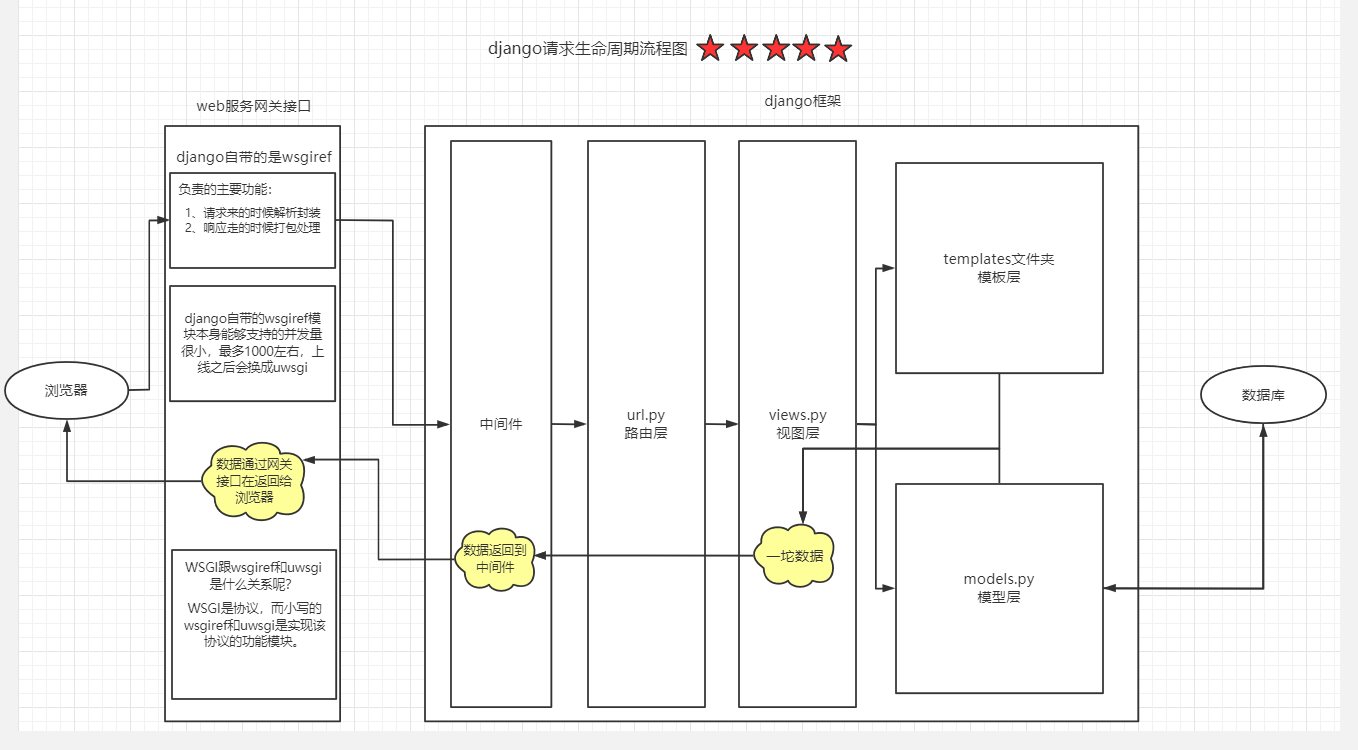
解释
CGI:定义了客户端浏览器与服务器之间如何传数据
FastCGI: CGI的升级版
WSGI:为Python定义的web服务器和web框架之间的接口标准
uWSGI:一个Web Server,即一个实现了WSGI的服务器,大体和Apache是一个类型的东西,处理发来的请求
uwsgi: uWSGI自有的一个协议
