Python中调用自然语言处理工具HanLP手记
手记实用系列文章:
3 自然语言处理手记
HanLP方法封装类:
# -*- coding:utf-8 -*-
# Filename: main.py
from jpype import *
startJVM(getDefaultJVMPath(), "-Djava.class.path=C:\hanlp\hanlp-1.3.2.jar;C:\hanlp", "-Xms1g", "-Xmx1g") # 启动JVM,Linux需替换分号;为冒号:
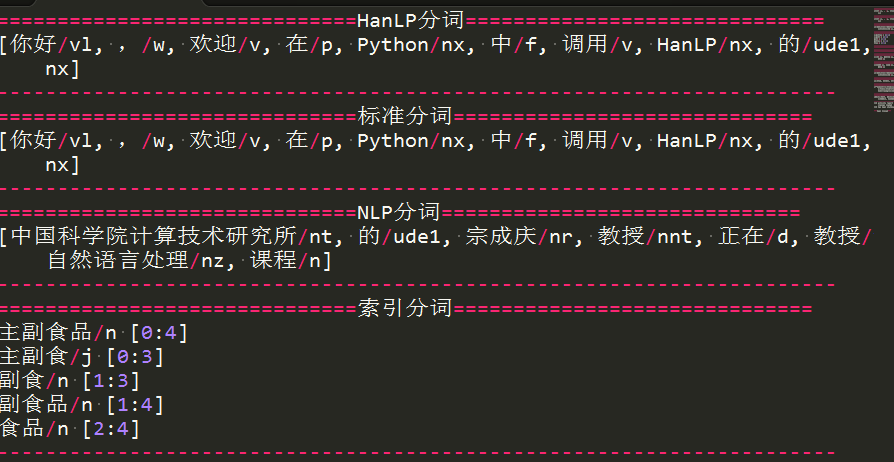
print("="*30+"HanLP分词"+"="*30)
HanLP = JClass('com.hankcs.hanlp.HanLP')
# 中文分词
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
print("-"*70)
print("="*30+"标准分词"+"="*30)
StandardTokenizer = JClass('com.hankcs.hanlp.tokenizer.StandardTokenizer')
print(StandardTokenizer.segment('你好,欢迎在Python中调用HanLP的API'))
print("-"*70)
# NLP分词NLPTokenizer会执行全部命名实体识别和词性标注
print("="*30+"NLP分词"+"="*30)
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))
print("-"*70)
print("="*30+"索引分词"+"="*30)
IndexTokenizer = JClass('com.hankcs.hanlp.tokenizer.IndexTokenizer')
termList= IndexTokenizer.segment("主副食品");
for term in termList :
print(str(term) + " [" + str(term.offset) + ":" + str(term.offset + len(term.word)) + "]")
print("-"*70)
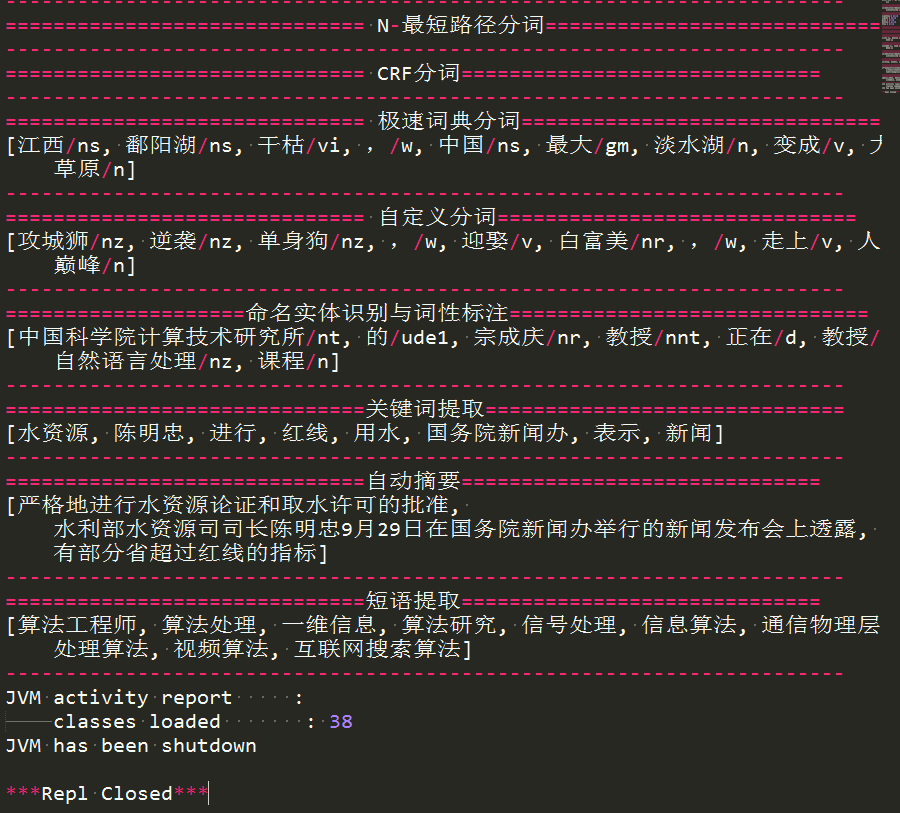
print("="*30+" N-最短路径分词"+"="*30)
# CRFSegment = JClass('com.hankcs.hanlp.seg.CRF.CRFSegment')
# segment=CRFSegment()
# testCase ="今天,刘志军案的关键人物,山西女商人丁书苗在市二中院出庭受审。"
# print(segment.seg("你看过穆赫兰道吗"))
print("-"*70)
print("="*30+" CRF分词"+"="*30)
print("-"*70)
print("="*30+" 极速词典分词"+"="*30)
SpeedTokenizer = JClass('com.hankcs.hanlp.tokenizer.SpeedTokenizer')
print(NLPTokenizer.segment('江西鄱阳湖干枯,中国最大淡水湖变成大草原'))
print("-"*70)
print("="*30+" 自定义分词"+"="*30)
CustomDictionary = JClass('com.hankcs.hanlp.dictionary.CustomDictionary')
CustomDictionary.add('攻城狮')
CustomDictionary.add('单身狗')
HanLP = JClass('com.hankcs.hanlp.HanLP')
print(HanLP.segment('攻城狮逆袭单身狗,迎娶白富美,走上人生巅峰'))
print("-"*70)
print("="*20+"命名实体识别与词性标注"+"="*30)
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))
print("-"*70)
document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \
"有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \
"严格地进行水资源论证和取水许可的批准。"
print("="*30+"关键词提取"+"="*30)
print(HanLP.extractKeyword(document, 8))
print("-"*70)
print("="*30+"自动摘要"+"="*30)
print(HanLP.extractSummary(document, 3))
print("-"*70)
# print("="*30+"地名识别"+"="*30)
# HanLP = JClass('com.hankcs.hanlp.HanLP')
# segment = HanLP.newSegment().enablePlaceRecognize(true)
# testCase=["武胜县新学乡政府大楼门前锣鼓喧天",
# "蓝翔给宁夏固原市彭阳县红河镇黑牛沟村捐赠了挖掘机"]
# for sentence in testCase :
# print(HanLP.segment(sentence))
# print("-"*70)
# print("="*30+"依存句法分析"+"="*30)
# print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
# print("-"*70)
text =r"算法工程师\n 算法(Algorithm)是一系列解决问题的清晰指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。算法工程师就是利用算法处理事物的人。\n \n 1职位简介\n 算法工程师是一个非常高端的职位;\n 专业要求:计算机、电子、通信、数学等相关专业;\n 学历要求:本科及其以上的学历,大多数是硕士学历及其以上;\n 语言要求:英语要求是熟练,基本上能阅读国外专业书刊;\n 必须掌握计算机相关知识,熟练使用仿真工具MATLAB等,必须会一门编程语言。\n\n2研究方向\n 视频算法工程师、图像处理算法工程师、音频算法工程师 通信基带算法工程师\n \n 3目前国内外状况\n 目前国内从事算法研究的工程师不少,但是高级算法工程师却很少,是一个非常紧缺的专业工程师。算法工程师根据研究领域来分主要有音频/视频算法处理、图像技术方面的二维信息算法处理和通信物理层、雷达信号处理、生物医学信号处理等领域的一维信息算法处理。\n 在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法:机器视觉成为此类算法研究的核心;另外还有2D转3D算法(2D-to-3D conversion),去隔行算法(de-interlacing),运动估计运动补偿算法(Motion estimation/Motion Compensation),去噪算法(Noise Reduction),缩放算法(scaling),锐化处理算法(Sharpness),超分辨率算法(Super Resolution),手势识别(gesture recognition),人脸识别(face recognition)。\n 在通信物理层等一维信息领域目前常用的算法:无线领域的RRM、RTT,传送领域的调制解调、信道均衡、信号检测、网络优化、信号分解等。\n 另外数据挖掘、互联网搜索算法也成为当今的热门方向。\n"
print("="*30+"短语提取"+"="*30)
print(HanLP.extractPhrase(text, 10))
print("-"*70)
shutdownJVM()
HanLP运行结果:
python调用HanLP的jar包
链接: https://pan.baidu.com/s/1miDrWHq 密码: bmy6
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号