学习10:Python重要知识
Python易忽略知识
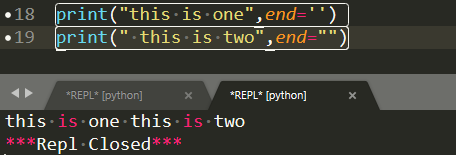
(1)print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
(2)isinstance 和 type 的区别在于:type()不会认为子类是一种父类类型。isinstance()会认为子类是一种父类类型。这么理解,父类:动物;子类:猫。isinstance()认为猫是动物,type()认为猫就是猫不是动物。
(3)数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。
(4)Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
(5)迭代器与生成器。
- 迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next() 。
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。使用 yield 实现斐波那契数列:
#!/usr/bin/python3
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
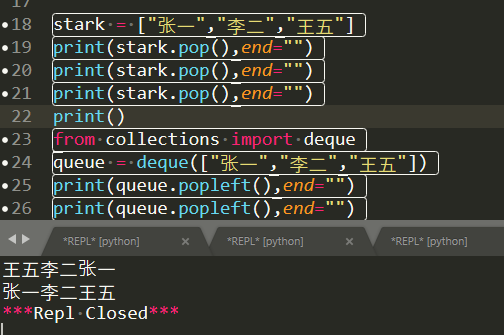
(6)列表的栈与队列
(7)将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
(8)类定义了 init() 方法,类的实例化操作会自动调用 init() 方法。类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定是用 self。
(9)__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。

(10)处理从 urls 接收数据的 urllib.request 以及用于发送电子邮件的 smtplib:
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... if 'EST' in line or 'EDT' in line.decode('utf-8'):
... print(line)
>>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
... """To: jcaesar@example.org
... From: soothsayer@example.org
...
... Beware the Ides of March.
... """)
>>> server.quit()
(11)doctest扫描模块并根据程序中内嵌的文档字符串执行测试。通过用户提供的例子,它强化了文档,允许 doctest 模块确认代码的结果是否与文档一致:
def average(values):
return sum(values) / len(values)
import doctest
print(doctest.testmod()) # 自动验证嵌入测试
(12)Python实例总结 https://www.runoob.com/python3/python3-examples.html
(13)Python实现查找与排序:https://www.runoob.com/python3/python3-examples.html
(14)re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。flags是否区分大小写。
re.match(pattern, string, flags=0)
(15)re.match与re.search的区别。re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
(16)Python连接MySQL
import MySQLdb
# 显示所有数据库
mydb = MySQLdb.Connect(
host='localhost',
user='root',
passwd='root',
database='all_news'
)
mycursor = mydb.cursor()
mycursor.execute("SHOW DATABASES")
for x in mycursor:
print(x)
print("*"*20)
# 创建数据表
# mycursor.execute("CREATE TABLE sites (name VARCHAR(255), url VARCHAR(255))")
mycursor.execute("SHOW TABLES")
for x in mycursor:
print(x)
# 修改表
# mycursor.execute("ALTER TABLE sites ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY")
# 插入数据
# sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
# val = ("RUNOOB", "https://www.runoob.com")
# mycursor.execute(sql, val)
# mydb.commit() # 数据表内容有更新,必须使用到该语句
# print(mycursor.rowcount, "记录插入成功。")
# 批量插入
# sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
# val = [
# ('Google', 'https://www.google.com'),
# ('Github', 'https://www.github.com'),
# ('Taobao', 'https://www.taobao.com'),
# ('stackoverflow', 'https://www.stackoverflow.com/')
# ]
# mycursor.executemany(sql, val)
# mydb.commit() # 数据表内容有更新,必须使用到该语句
# print(mycursor.rowcount, "记录插入成功。")
# 查询数据
print("="*20)
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchall() # fetchall() 获取所有记录
# myresult = mycursor.fetchone() # 读一条数据
for x in myresult:
print(x)
# 删除数据
# sql = "DELETE FROM sites WHERE name = 'stackoverflow'"
# mycursor.execute(sql)
# mydb.commit()
# print(mycursor.rowcount, " 条记录删除")
# 更新数据
sql = "UPDATE sites SET name = 'ZH' WHERE id = 4"
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录被修改")
# 执行事务
# SQL删除记录语句
sql = "DELETE FROM EMPLOYEE WHERE AGE > %s" % (20)
try:
# 执行SQL语句
cursor.execute(sql)
# 向数据库提交
db.commit()
except:
# 发生错误时回滚
db.rollback()
(17) 格式化日期:
#!/usr/bin/python3
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
(18)Python操作MongoDB
- 启动服务
D:\mongodb\bin>mongod --dbpath D:\mongodb\data\db --logpath=D:\mongodb\log\mongo.log --logappend
- MongoDB
# Python 操作MongoDB
print("*"*50)
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
dblist = myclient.list_database_names()
if "runoobdb" in dblist:
print("数据库已存在!")
# 创建集合
mycol = mydb["sites"]
collist = mydb.list_collection_names()
if "sites" in collist: # 判断 sites 集合是否存在
print("集合已存在!")
# 添加数据
mydict = [
{ "_id": 1, "name": "RUNOOB", "cn_name": "菜鸟教程"},
{ "_id": 2, "name": "Google", "address": "Google 搜索"},
{ "_id": 3, "name": "Facebook", "address": "脸书"},
{ "_id": 4, "name": "Taobao", "address": "淘宝"},
{ "_id": 5, "name": "Zhihu", "address": "知乎"}
]
# x = mycol.insert_one(mydict)
# x = mycol.insert_many(mydict)
# print(x.inserted_ids)
# 修改数据
myquery = { "alexa": "10000" }
newvalues = { "$set": { "alexa": "12345" } }
mycol.update_one(myquery, newvalues)
# 输出修改后的 "sites" 集合
# for x in mycol.find():
# print(x)
# 查询数据, find() 方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
# for x in mycol.find():
# print(x)
# for x in mycol.find({},{"_id":0}):
# print(x)
# myquery = { "name": "RUNOOB" }
# for x in mycol.find(myquery):
# print(x)
# myresult = mycol.find().limit(3)
# 输出结果
# for x in myresult:
# print(x)
# 删除数据
# myquery = { "name": "知乎" }
# myquery = { "name": {"$regex": "^F"} }
# mycol.delete_one(myquery)
# mycol.delete_many(myquery)
# 删除后输出
for x in mycol.find():
print(x)
# 排序,升序sort("alexa"),降序sort("alexa", -1)
# mydoc = mycol.find().sort("alexa")
# for x in mydoc:
# print(x)
(19)WSGI 应用和常见的 Web 框架
- 部署Django
[uwsgi]
socket = 127.0.0.1:3031
chdir = /home/foobar/myproject/
wsgi-file = myproject/wsgi.py
processes = 4
threads = 2
stats = 127.0.0.1:9191
uwsgi yourfile.ini
- 部署Flask
创建文件 myflaskapp.py ,代码如下:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "<span style='color:red'>I am app 1</span>"
执行以下命令:
uwsgi --socket 127.0.0.1:3031 --wsgi-file myflaskapp.py --callable app --processes 4 --threads 2 --stats 127.0.0.1:9191
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号