学习9:MongoDB知识
MongoDB学习笔记
1 基本介绍
- 基本概念
MongoDB**是一种面向文档的数据库管理系统,由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。2007年10月,MongoDB由10gen团队所发展。2009年2月首度推出。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
- 优缺点
优点
- 文档结构的存储方式,能够更便捷的获取数据
- 内置GridFS,支持大容量的存储:GridFS是一个出色的分布式文件系统,可以支持海量的数据存储。 内置了GridFS了MongoDB,能够满足对大数据集的快速范围查询。
- 海量数据下,性能优越:在使用场合下,千万级别的文档对象,近10G的数据,对有索引的ID的查询不会比mysql慢,而对非索引字段的查询,则是全面胜出。 mysql实际无法胜任大数据量下任意字段的查询,而mongodb的查询性能实在让我惊讶。写入性能同样很令人满意。
- 动态查询
- 全索引支持,扩展到内部对象和内嵌数组:索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
- 查询记录分析
- 快速,就地更新
- 高效存储二进制大对象 (比如照片和视频)
- 复制(复制集)和支持自动故障恢复
- 内置 Auto- Sharding 自动分片支持云级扩展性,分片简单
- MapReduce 支持复杂聚合:主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
- 商业支持,培训和咨询
缺点
- 不支持事务操作:事务要求严格的系统(如果银行系统)肯定不能用它。
- MongoDB没有如MySQL那样成熟的维护工具
- 无法进行关联表查询,不适用于关系多的数据
- 复杂聚合操作通过mapreduce创建,速度慢
- 模式自由,自由灵活的文件存储格式带来的数据错
- MongoDB 在你删除记录后不会在文件系统回收空间。除非你删掉数据库。但是空间没有被浪费
- 关系型数据库遵循ACID

- 分布式计算优缺点

- NoSQL:not only SQL优缺点

- NoSQL数据库分类
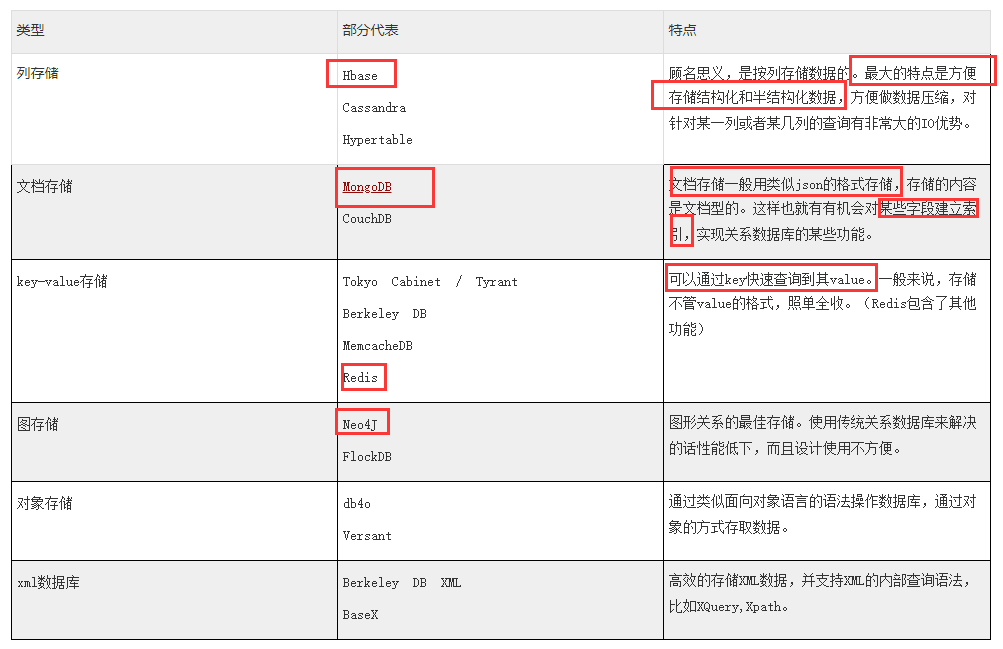
- MongoDB:C++语言编写,开源,高负载添加节点保证服务器性能。将数据存储为文档,于分布式文件存储的数据库。下载地址:http://www.mongodb.org/downloads
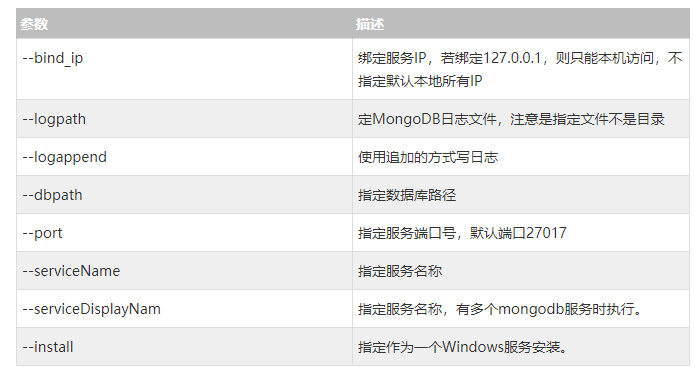
- MongoDB启动参数
- 配置MongoDB
解压下载https://www.mongodb.com/download-center/community的ZIP包,并更改文件名为mongodb,在其同目录下创建文件夹data和data\db,log和mongo.log。
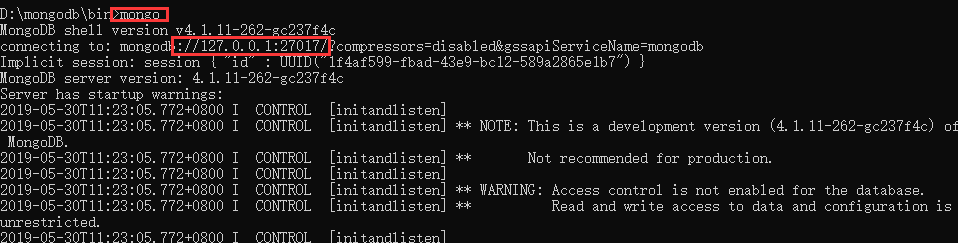
- 打开cmd 进入cd mongodb\bin,执行下面命令启动网络:
mongod --dbpath D:\mongodb\data\db --logpath=D:\mongodb\log\mongodb.log --logappend
最后,再次打开cmd 进入cd mongodb\bin,执行下面命令:mongo
在浏览器中打开地址:

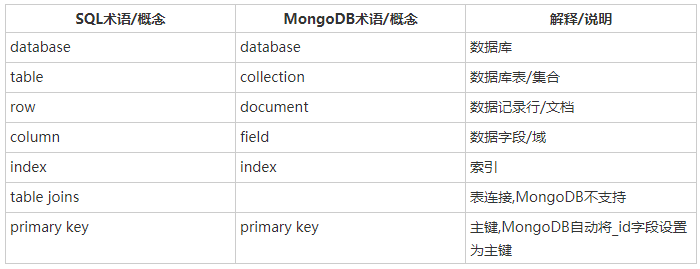
- MongoDB概念解析

- 数据库命令
- "show dbs" 命令显示所有数据的列表。
- "db" 命令显示当前数据库对象或集合
- "use"命令,可以连接到一个指定的数据库。
- 数据库命名规范

- 文档(行):文档是一个键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
- 集合(表):集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
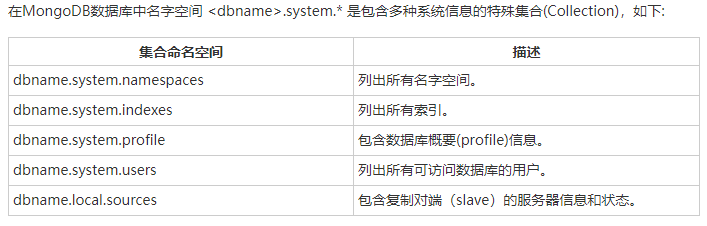
- 数据类型
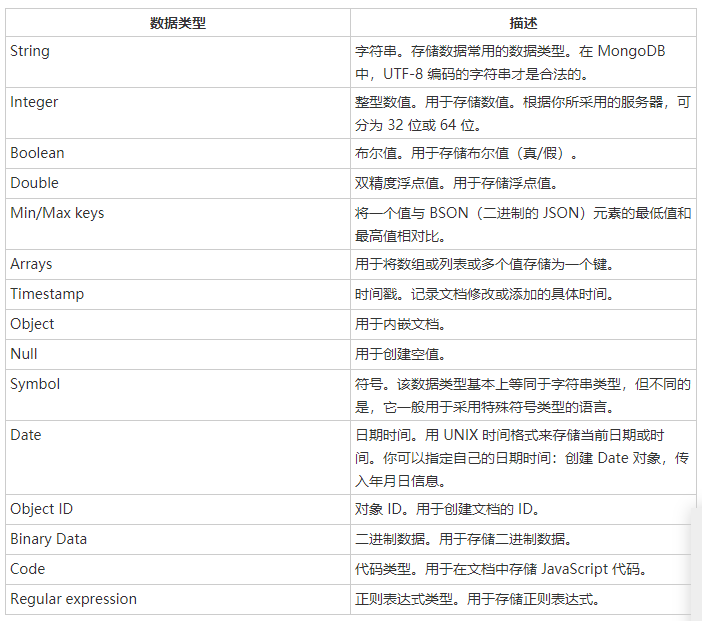
- mongodb连接
用户名和密码连接到MongoDB,'username:password@hostname/dbname'
2 MongoDB操作
- 创建数据库 use DATABASE_NAME
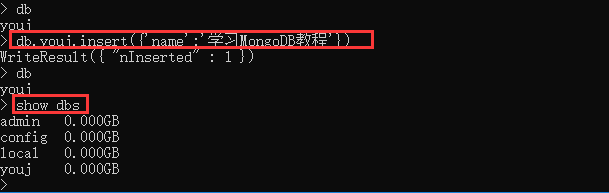
- 插入数据:
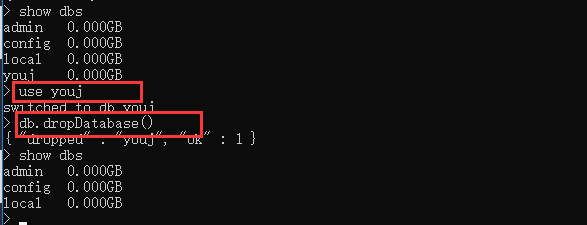
- 删除数据库: db.dropDatabase()
- 删除集合 db.collection.drop()
- 插入文档 : db.COLLECTION_NAME.insert(document)
- 更新文档: db.collection.update( criteria, objNew, upsert, multi )
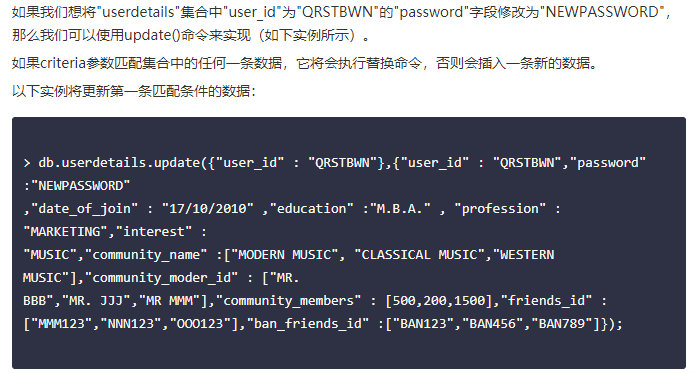
- 查找文档 db.userdetails.find(),find() 方法以非结构化的方式来显示所有文档。还有一个 findOne() 方法,它只返回一个文档。

易懂的读取pretty(),
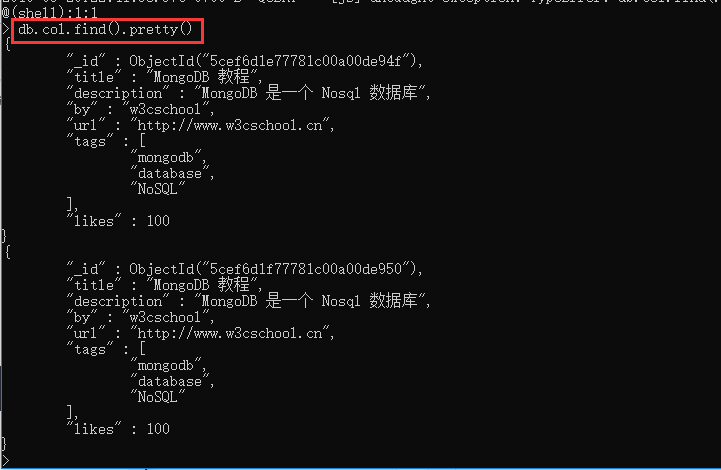
- 删除文档 remove() 方法,
db.collection.remove(
<query>,
<justOne>
)

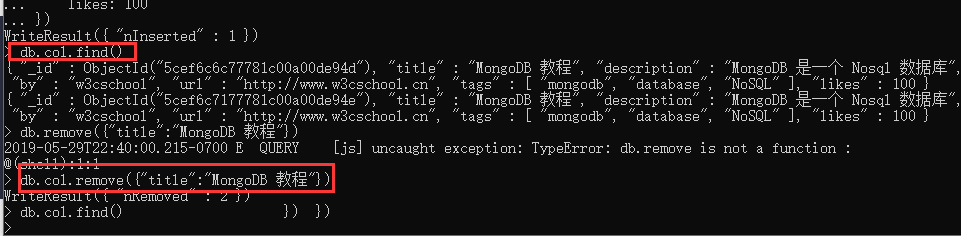

- MongoDB 与 RDBMS Where 语句比较
- MongoDB AND条件:MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
- OR查询条件:MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
- $type操作符:操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
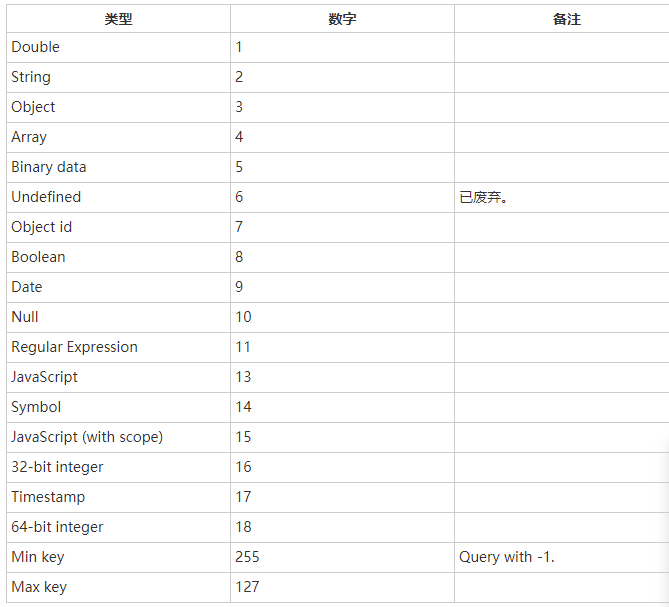

- limit与skip,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER)

skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
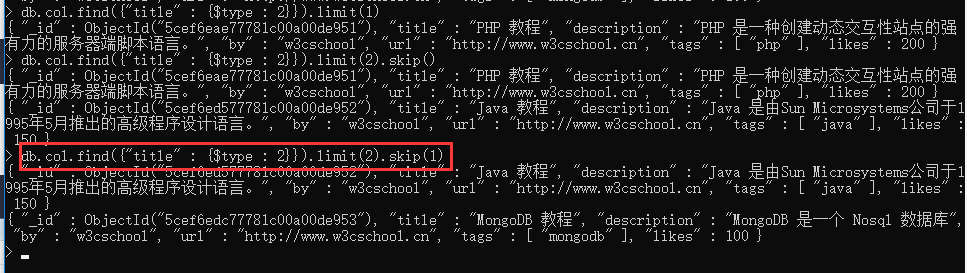
- 排序:sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.COLLECTION_NAME.find().sort({KEY:1})
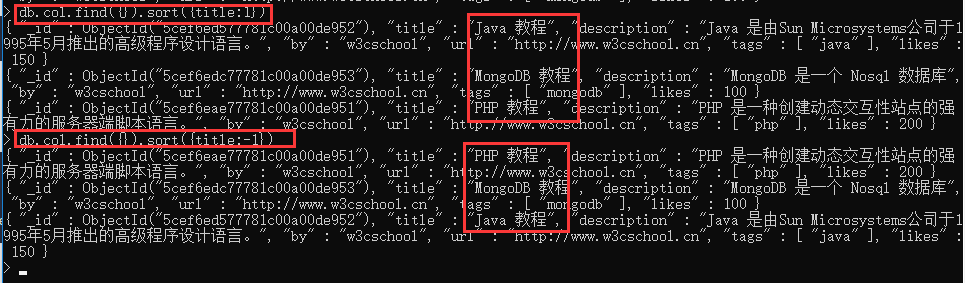
- 索引: ensureIndex() 方法来创建索引。语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
db.COLLECTION_NAME.ensureIndex({KEY:1})
- 聚合:处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。聚合的方法使用aggregate()。
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
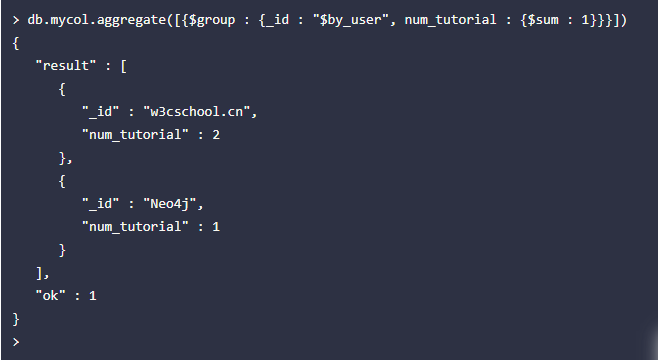
- 管道

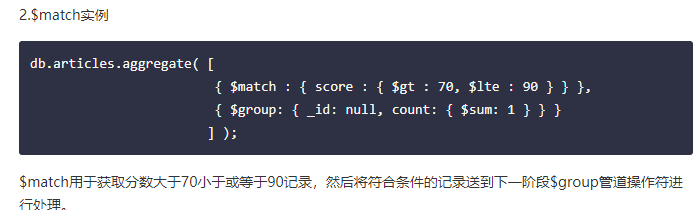
- 复制,复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许您从硬件故障和服务中断中恢复数据。

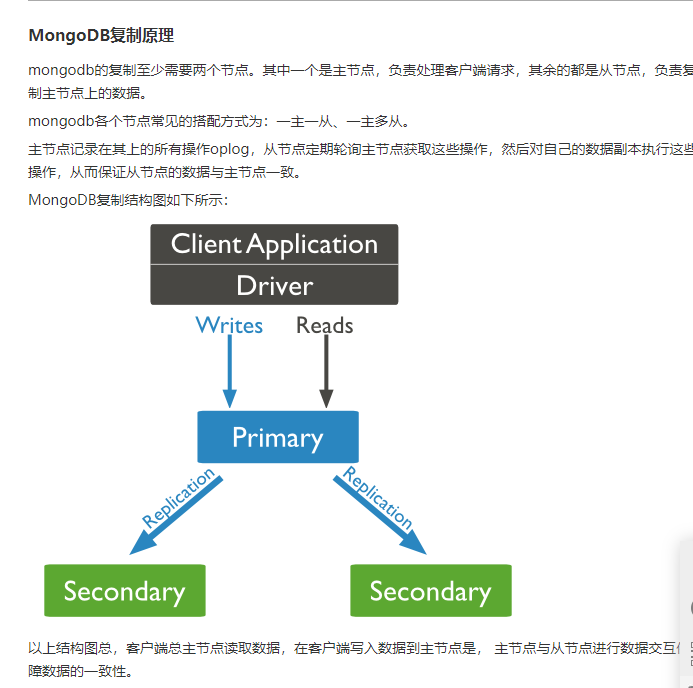

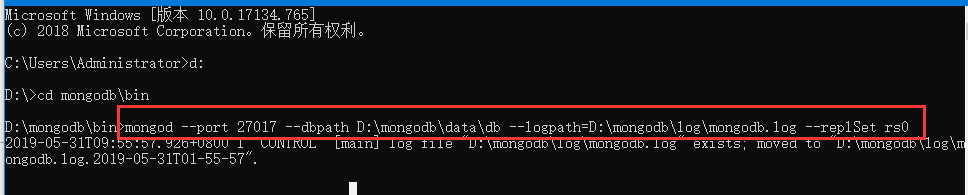
mongod --port 27017 --dbpath D:\mongodb\data\db --logpath=D:\mongodb\log\mongodb.log --replSet rs0
以上实例会启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置
查看副本集姿态使用 rs.status() 命令

D:\mongodb\bin>mongo
MongoDB shell version v4.1.11-262-gc237f4c
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("7109348e-cade-4128-af30-7cf8776302a9") }
MongoDB server version: 4.1.11-262-gc237f4c
# 添加副本集
> rs.add("mongod1.net:27017")
2019-05-30T18:57:26.058-0700 E QUERY [js] uncaught exception: Error: assert failed : no config object retrievable from local.system.replset :
doassert@src/mongo/shell/assert.js:20:14
assert@src/mongo/shell/assert.js:152:9
rs.add@src/mongo/shell/utils.js:1441:5
@(shell):1:1
# 查看当前运行是否是主节点
> db.isMaster()
{
"ismaster" : false,
"secondary" : false,
"info" : "Does not have a valid replica set config",
"isreplicaset" : true,
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 100000,
"localTime" : ISODate("2019-05-31T01:57:40.632Z"),
"logicalSessionTimeoutMinutes" : 30,
"connectionId" : 1,
"minWireVersion" : 0,
"maxWireVersion" : 8,
"readOnly" : false,
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(0, 0),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(0, 0)
}
# 启动一个新的副本集
> rs.initiate()
# 查看副本集的配置
rs0:SECONDARY> rs.conf()
# 查看副本集姿态
rs0:PRIMARY> rs.status()
- MongoDB分片,另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。当MongoDB存储海量的数据时,一台机器可能不足以存储数据也足以提供可接受的读写吞吐量。就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。

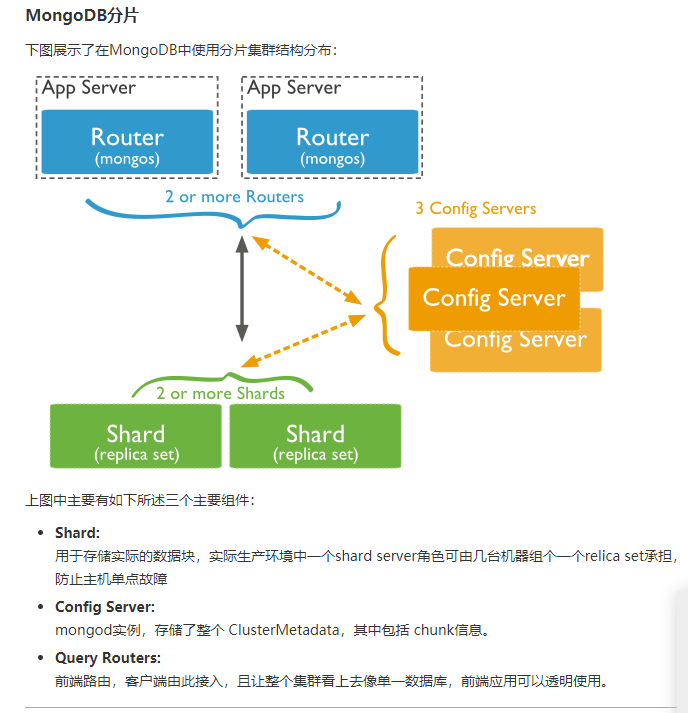
- 分片实例

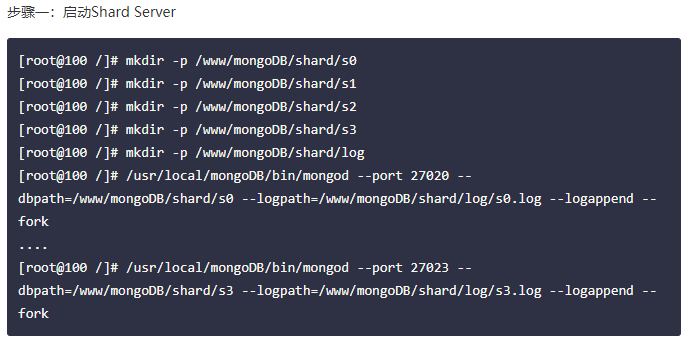
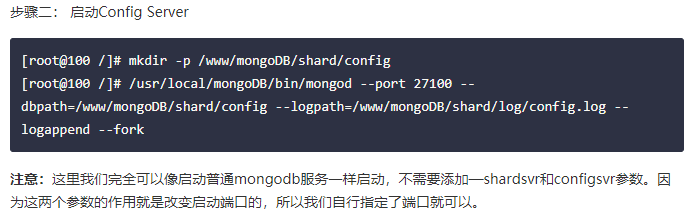
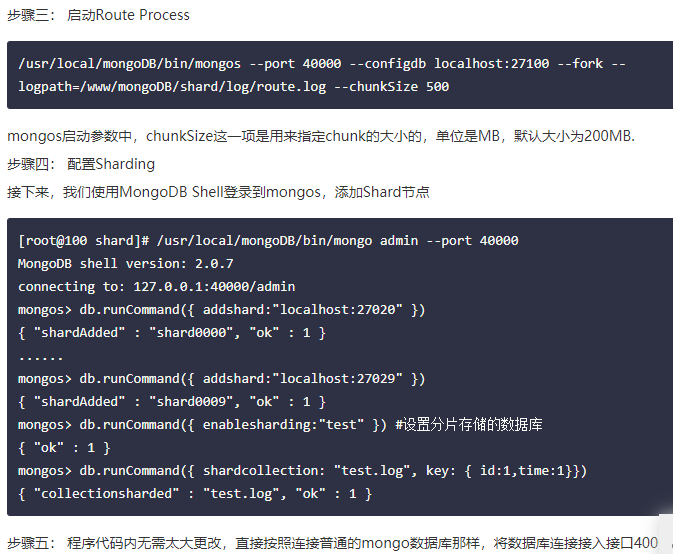
-
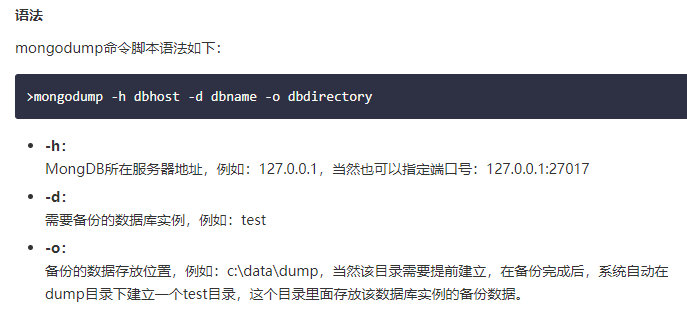
MongoDB数据备份:mongodbdump
使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。mongodump命令可以通过参数指定导出的数据量级转存的服务器。
 、
、

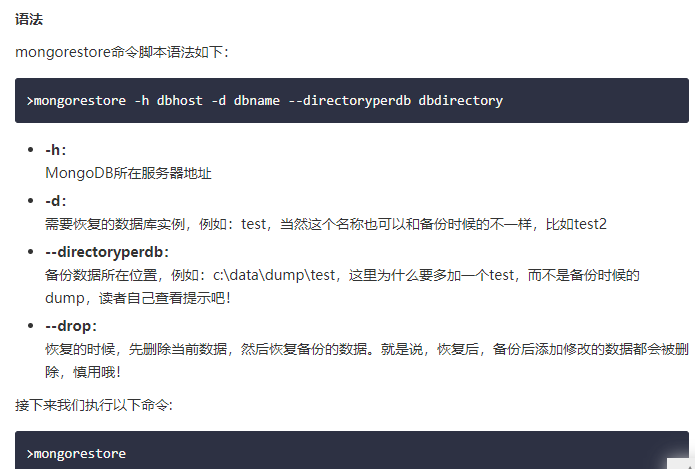
- MongoDB数据恢复,mongodbstore
- MongoDB监控
mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。

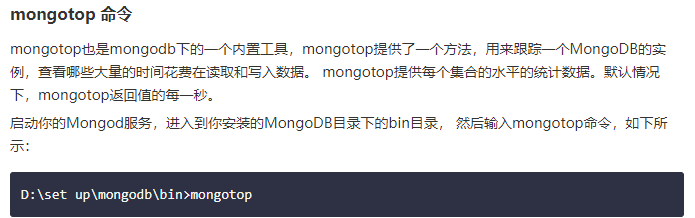
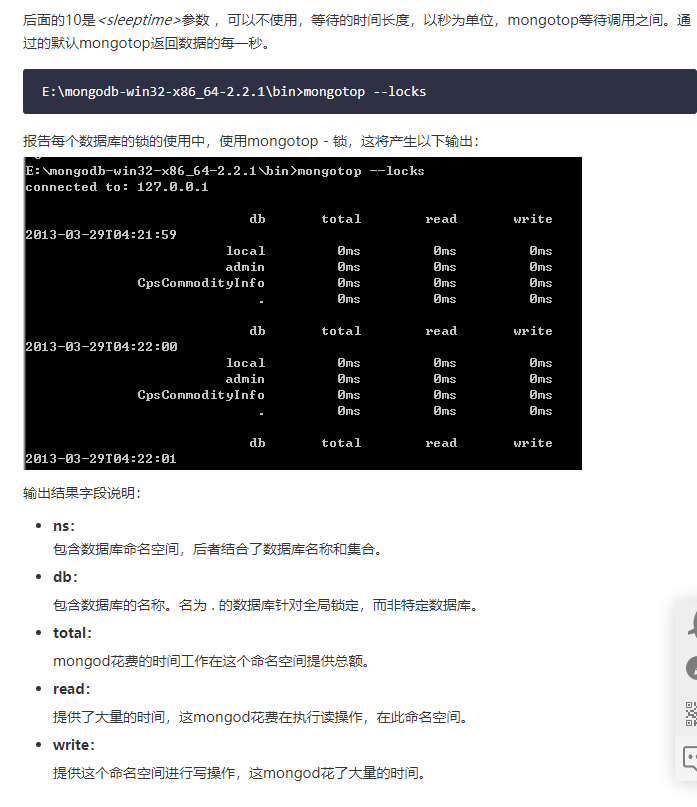
3连接MongoDB数据库
3.1 Java代码连接MongoDB数据库
环境配置,在Java程序中如果要使用MongoDB,你需要确保已经安装了Java环境及MongoDB JDBC 驱动。
- 首先你必须下载mongo jar包,下载地址:https://github.com/mongodb/mongo-java-driver/downloads, 请确保下载最新版本。
- 你需要将mongo.jar包含在你的 classpath 中。。
- 连接数据库,你需要指定数据库名称,如果指定的数据库不存在,mongo会自动创建数据库。
import com.mongodb.MongoClient;
import com.mongodb.MongoException;
import com.mongodb.WriteConcern;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.BasicDBObject;
import com.mongodb.DBObject;
import com.mongodb.DBCursor;
import com.mongodb.ServerAddress;
import java.util.Arrays;
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用com.mongodb.DB类中的createCollection()来创建集合
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.createCollection("mycol");
System.out.println("Collection created successfully");
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用com.mongodb.DBCollection类的 getCollection() 方法来获取一个集合
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.createCollection("mycol");
System.out.println("Collection created successfully");
DBCollection coll = db.getCollection("mycol");
System.out.println("Collection mycol selected successfully");
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用com.mongodb.DBCollection类的 insert() 方法来插入一个文档
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.getCollection("mycol");
System.out.println("Collection mycol selected successfully");
BasicDBObject doc = new BasicDBObject("title", "MongoDB").
append("description", "database").
append("likes", 100).
append("url", "//www.w3cschool.cn/mongodb/").
append("by", "w3cschool.cn");
coll.insert(doc);
System.out.println("Document inserted successfully");
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用com.mongodb.DBCollection类中的 find() 方法来获取集合中的所有文档。
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到 mongodb 服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.getCollection("mycol");
System.out.println("Collection mycol selected successfully");
DBCursor cursor = coll.find();
int i=1;
while (cursor.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(cursor.next());
i++;
}
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用 com.mongodb.DBCollection 类中的 update() 方法来更新集合中的文档
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到Mongodb服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到你的数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.getCollection("mycol");
System.out.println("Collection mycol selected successfully");
DBCursor cursor = coll.find();
while (cursor.hasNext()) {
DBObject updateDocument = cursor.next();
updateDocument.put("likes","200")
coll.update(updateDocument);
}
System.out.println("Document updated successfully");
cursor = coll.find();
int i=1;
while (cursor.hasNext()) {
System.out.println("Updated Document: "+i);
System.out.println(cursor.next());
i++;
}
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
- 使用com.mongodb.DBCollection类中的 findOne()方法来获取第一个文档,然后使用remove 方法删除
public class MongoDBJDBC{
public static void main( String args[] ){
try{
// 连接到Mongodb服务
MongoClient mongoClient = new MongoClient( "localhost" , 27017 );
// 连接到你的数据库
DB db = mongoClient.getDB( "test" );
System.out.println("Connect to database successfully");
boolean auth = db.authenticate(myUserName, myPassword);
System.out.println("Authentication: "+auth);
DBCollection coll = db.getCollection("mycol");
System.out.println("Collection mycol selected successfully");
DBObject myDoc = coll.findOne();
coll.remove(myDoc);
DBCursor cursor = coll.find();
int i=1;
while (cursor.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(cursor.next());
i++;
}
System.out.println("Document deleted successfully");
}catch(Exception e){
System.err.println( e.getClass().getName() + ": " + e.getMessage() );
}
}
}
4 MongoDB高级教程
4.1 关系
MongoDB 的关系表示多个文档之间在逻辑上的相互联系。文档间可以通过嵌入和引用来建立联系。MongoDB 中的关系可以是:
- 1:1 (1对1)
- 1: N (1对多)
- N: 1 (多对1)
- N: N (多对多)
一个用户可以有多个地址,所以是一对多的关系。
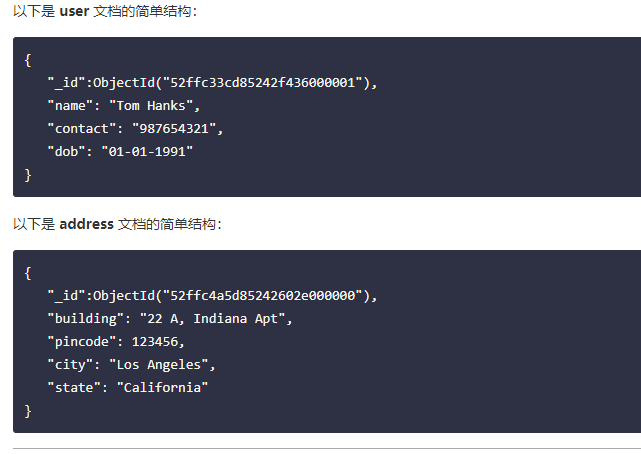
- 使用嵌入式方法,我们可以把用户地址嵌入到用户的文档中
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}]
}
数据保存在单一文档中,比较容易的获取很维护数据。 你可以这样查询用户的地址:
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})
这种数据结构的缺点是,如果用户和用户地址在不断增加,数据量不断变大,会影响读写性能。
- 引用式关系,把用户数据文档和用户地址数据文档分开,通过引用文档的 id 字段来建立关系。
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
需要两次查询,第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息。
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
4.2 MapReduce
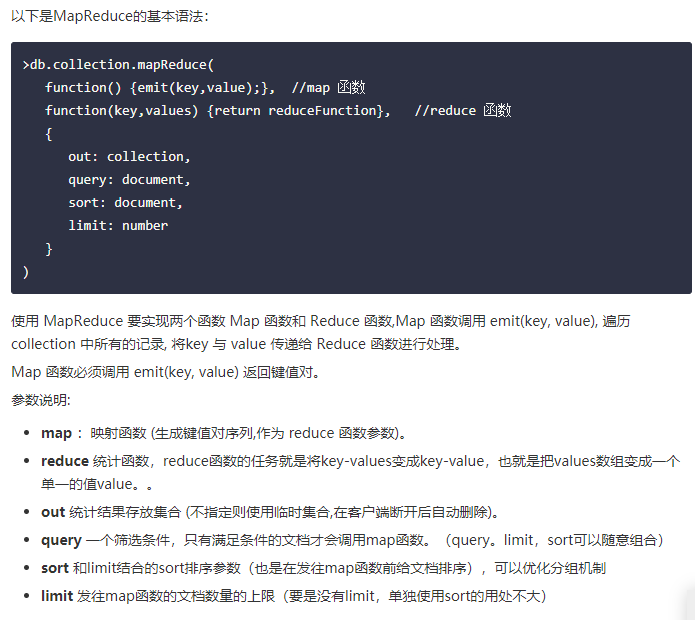
- 使用MapReduce
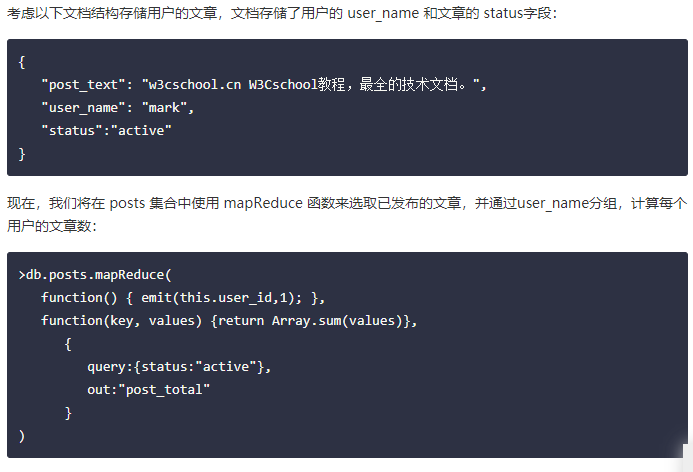
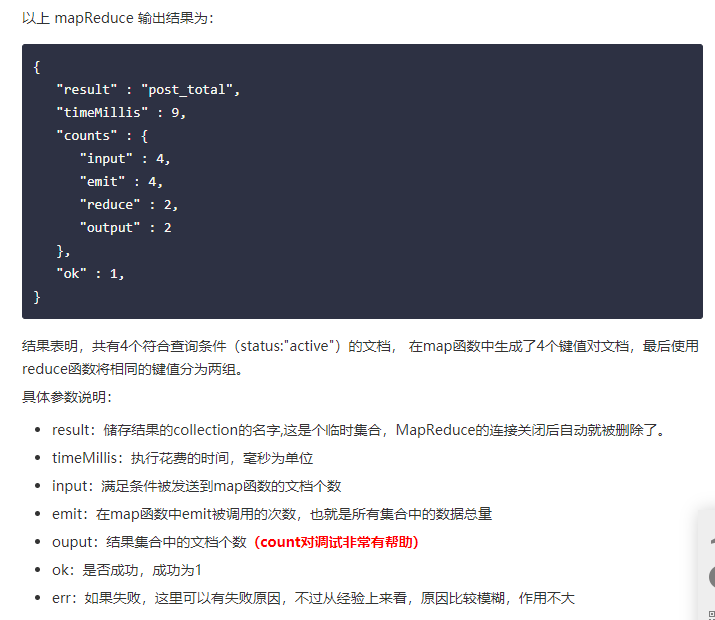
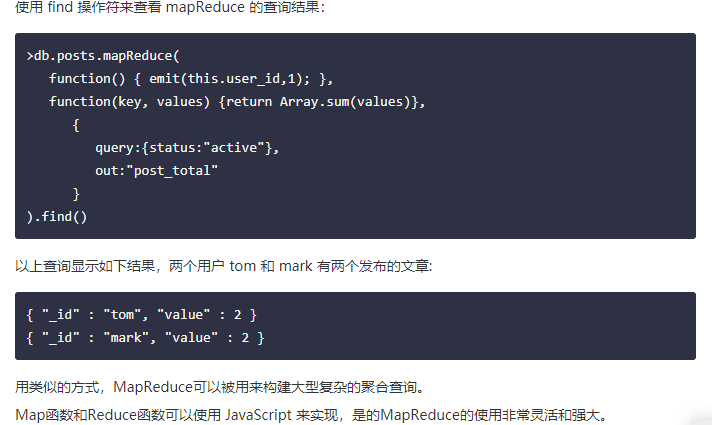
- 全文检索,MongoDB 在 2.6 版本以后是默认开启全文检索的
- 创建全文索引
考虑以下 posts 集合的文档数据,包含了文章内容(post_text)及标签(tags):
{
"post_text": "enjoy the mongodb articles on w3cschool.cn",
"tags": [
"mongodb",
"w3cschool"
]
}
我们可以对 post_text 字段建立全文索引,这样我们可以搜索文章内的内容:
>db.posts.ensureIndex({post_text:"text"})
- 使用全文索引
现在我们已经对 post_text 建立了全文索引,我们可以搜索文章中的关键词w3cschool.cn:
>db.posts.find({$text:{$search:"w3cschool.cn"}})
以下命令返回了如下包含NoSQL关键词的文档数据:
D:\mongodb\bin>mongo
MongoDB shell version v4.1.11-262-gc237f4c
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
myinfo 0.000GB
w3cschooldb 0.000GB
youj 0.000GB
> use youj
switched to db youj
> db.col.find()
{ "_id" : ObjectId("5cef550377781c00a00de949"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "w3cschool", "url" : "http://www.w3cschool.cn", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
{ "_id" : ObjectId("5cef690677781c00a00de94a"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "w3cschool", "url" : "http://www.w3cschool.cn", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
> db.col.ensureIndex({description:"text"})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.col.find({$text:{$search:"NoSQL"}})
{ "_id" : ObjectId("5cef690677781c00a00de94a"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "w3cschool", "url" : "http://www.w3cschool.cn", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
{ "_id" : ObjectId("5cef550377781c00a00de949"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "w3cschool", "url" : "http://www.w3cschool.cn", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
>
4.3 删除全文索引
删除已存在的全文索引,可以使用 find 命令查找索引名:
>db.col.getIndexes()
通过以上命令获取索引名,本例的索引名为post_text_text,执行以下命令来删除索引:
> db.col.dropIndex('description_text')
4.4 正则
使用 $regex 操作符来设置匹配字符串的正则表达式。
- 使用正则表达式,使用正则查找包含 w3cschool.cn 字符串的文章:
>db.posts.find({post_text:{$regex:"w3cschool.cn"}})
以上查询也可以写为:
>db.posts.find({post_text:/w3cschool.cn/})
- 不区分大小写的正则表达式
如果检索需要不区分大小写,我们可以设置 $options 为 $i。以下命令将查找不区分大小写的字符串 w3cschool.cn:
>db.posts.find({post_text:{$regex:"w3cschool.cn",$options:"$i"}})
集合中会返回所有包含字符串 w3cschool.cn 的数据,且不区分大小写:
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on W3Cschool.cc",
"tags" : [ "tutorialspoint" ]
}
- 数组元素使用正则表达式
这在标签的实现上非常有用,如果你需要查找包含以 tutorial 开头的标签数据(tutorial 或 tutorials 或 tutorialpoint 或 tutorialphp), 你可以使用以下代码:
>db.posts.find({tags:{$regex:"tutorial"}})
- 优化正则表达式查询
如果你的文档中字段设置了索引,那么使用索引相比于正则表达式匹配查找所有的数据查询速度更快。
如果正则表达式是前缀表达式,所有匹配的数据将以指定的前缀字符串为开始。例如: 如果正则表达式为^tut ,查询语句将查找以 tut 为开头的字符串。
4.5 GridFS
GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。也是文件存储的一种方式,但是它是存储在MonoDB的集合中。GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
以下是简单的 fs.files 集合文档:
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}
以下是简单的 fs.chunks 集合文档:
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}
- GridFS 添加文件
现在我们使用 GridFS 的 put 命令来存储 mp3 文件。 调用 MongoDB 安装目录下bin的 mongofiles.exe工具。
打开命令提示符,进入到MongoDB的安装目录的bin目录中,找到mongofiles.exe,并输入下面的代码:
>mongofiles.exe -d gridfs put song.mp3
GridFS 是存储文件的数据名称。如果不存在该数据库,MongoDB会自动创建。Song.mp3 是音频文件名。使用以下命令来查看数据库中文件的文档:
>db.fs.files.find()
以上命令执行后返回以下文档数据:
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}
我们可以看到 fs.chunks 集合中所有的区块,以下我们得到了文件的 _id 值,我们可以根据这个 _id 获取区块(chunk)的数据:
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})
以上实例中,查询返回了 40 个文档的数据,意味着mp3文件被存储在40个区块中。
4.6 自动增长
MongoDB 没有像 SQL 一样有自动增长的功能, MongoDB 的id是系统自动生成的12字节唯一标识。但在某些情况下,我们可能需要实现 ObjectId 自动增长功能。由于 MongoDB 没有实现这个功能,我们可以通过编程的方式来实现,以下我们将在 counters 集合中实现id字段自动增长。
- 使用集合
以下 products 文档。id 字段实现 从 1,2,3,4 到 n 的自动增长功能。
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}
为此,创建 counters 集合,序列字段值可以实现自动长:
>db.createCollection("counters")
向 counters 集合中插入以下文档,使用 productid 作为 key:
{
"_id":"productid",
"sequence_value": 0
}
sequence_value 字段是序列通过自动增长后的一个值。使用以下命令插入 counters 集合的序列文档中:
>db.counters.insert({_id:"productid",sequence_value:0})
- 创建 Javascript 函数
创建函数 getNextSequenceValue 来作为序列名的输入, 指定的序列会自动增长 1 并返回最新序列值。在本文的实例中序列名为 productid 。
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify(
{
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}
- 使用 Javascript 函数
使用 getNextSequenceValue 函数创建一个新的文档, 并设置文档 _id 自动为返回的序列值:
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"})
使用 getNextSequenceValue 函数来设置 _id 字段。为了验证函数是否有效,我们可以使用以下命令读取文档:
>db.prodcuts.find()
以上命令将返回以下结果,我们发现 _id 字段是自增长的:
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号