
NUMA的结构+线与逻辑+write_once+xprop+process+this和local+pcie信号补偿
NUMA
https://houmin.cc/posts/b893097a/
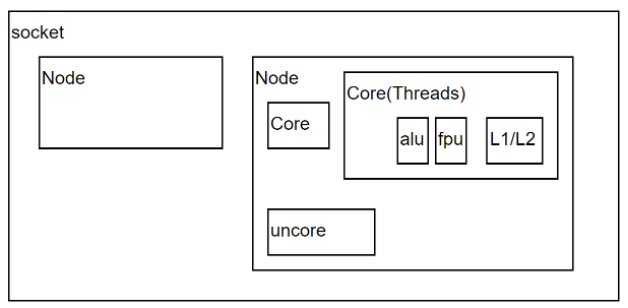
一个NUMA Node内部是由一个物理CPU和它所有的本地内存(Local Memory) 组成的。广义上还包含本地IO资源,对大多数Intel x86 NUMA平台来说,主要是PCIe总线资源。
物理 CPU:一个CPU Socket里可以由多个CPU Core和一个Uncore部分组成。每个CPU Core内部又可以由两个CPU Thread组成。 每个CPU thread都是一个操作系统可见的逻辑CPU。对大多数操作系统来说,一个八核HT打开的CPU会被识别为16个CPU。
以下是复制部分:
// ============================================
Socket
一个Socket对应一个物理CPU。 这个词大概是从CPU在主板上的物理连接方式上来的,可以理解为 Socket 就是主板上的 CPU 插槽。处理器通过主板的Socket来插到主板上。 尤其是有了多核(Multi-core)系统以后,Multi-socket系统被用来指明系统到底存在多少个物理CPU。
Node
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题。每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量。通常一个 Socket 有一个 Node,也有可能一个 Socket 有多个 Node。
Core
CPU的运算核心。 x86的核包含了CPU运算的基本部件,如逻辑运算单元(ALU), 浮点运算单元(FPU), L1和L2缓存。 一个Socket里可以有多个Core。如今的多核时代,即使是Single Socket的系统, 也是逻辑上的SMP系统。但是,一个物理CPU的系统不存在非本地内存,因此相当于UMA系统。
Uncore
Intel x86物理CPU里没有放在Core里的部件都被叫做Uncore。Uncore里集成了过去x86 UMA架构时代北桥芯片的基本功能。 在Nehalem时代,内存控制器被集成到CPU里,叫做iMC(Integrated Memory Controller)。 而PCIe Root Complex还做为独立部件在IO Hub芯片里。到了SandyBridge时代,PCIe Root Complex也被集成到了CPU里。 现今的Uncore部分,除了iMC,PCIe Root Complex,还有QPI(QuickPath Interconnect)控制器, L3缓存,CBox(负责缓存一致性),及其它外设控制器。
Threads
这里特指CPU的多线程技术。在Intel x86架构下,CPU的多线程技术被称作超线程(Hyper-Threading)技术。 Intel的超线程技术在一个处理器Core内部引入了额外的硬件设计模拟了两个逻辑处理器(Logical Processor), 每个逻辑处理器都有独立的处理器状态,但共享Core内部的计算资源,如ALU,FPU,L1,L2缓存。 这样在最小的硬件投入下提高了CPU在多线程软件工作负载下的性能,提高了硬件使用效率。 x86的超线程技术出现早于NUMA架构。
MOS管
https://zhuanlan.zhihu.com/p/368263926
NMOS
https://zhuanlan.zhihu.com/p/368263926
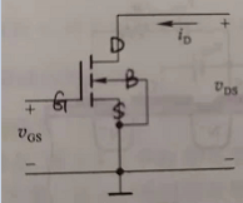
对于NMOS管,Vgs为高电平时,id电流能够形成,方向从D流向S到地;Vgs为低电平时,id电流形成不了,D、S之间断开。
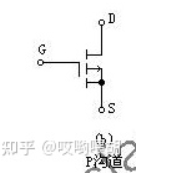
PMOS
G为0时候上下导通
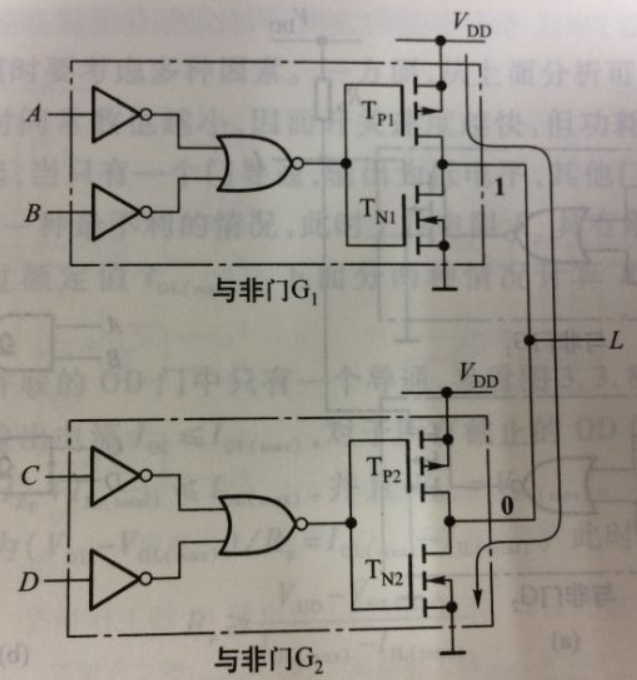
线与逻辑
https://www.cnblogs.com/MAQI/p/7426005.html
为什么需要线与逻辑,能做什么工作
- 可以增大驱动能力(如果同时为1的话)
- 可以实现逻辑变换(四个输入,一个输出,AB为0,且CD为0,输出才为1)
如何实现线与逻辑
输入端口都是0的情况下,输出G为1,下面的NMOS管导通,此时输出L为0。
上拉电阻的值越小,负载电容的充电时间常数也越小,因而开关速度越快。
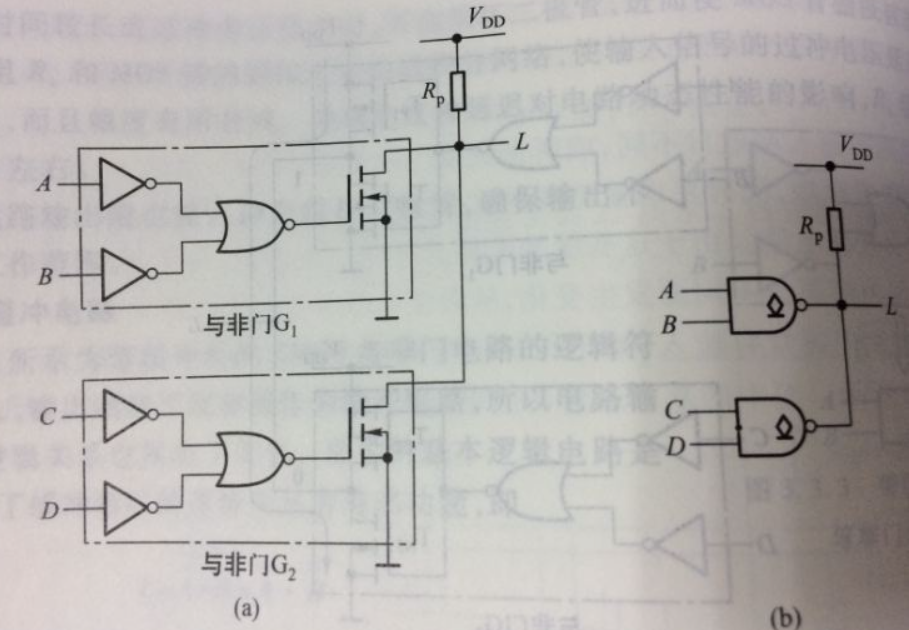
为什么不能有PMOS
都为0的时候,上下导通,形成短路。(其实如果加上电阻似乎也行,但是又更麻烦了吧)
Write-Once总线监听协议
https://www.cnblogs.com/gujiangtaoFuture/articles/11163400.html
Write-Once 是 Write-Back 和 Write-Through 的综合。当使用这种机制时,对一个 Cache Block 进行第一次回写时,采用 Write-Through 策略将数据同时回写到 Cache 和主存储器,之后的 写操作采用 Write-Back,只回写到 Cache 而不回写到主存储器。
Write-Back 机制 能够有效节约带宽,但是由于主存储器中并没有最新的数据副本,增加了维护 Cache Coherency 的开销。Write-Through 则相反。
vcs编译选项-xporp
https://blog.csdn.net/weixin_40357487/article/details/129996971
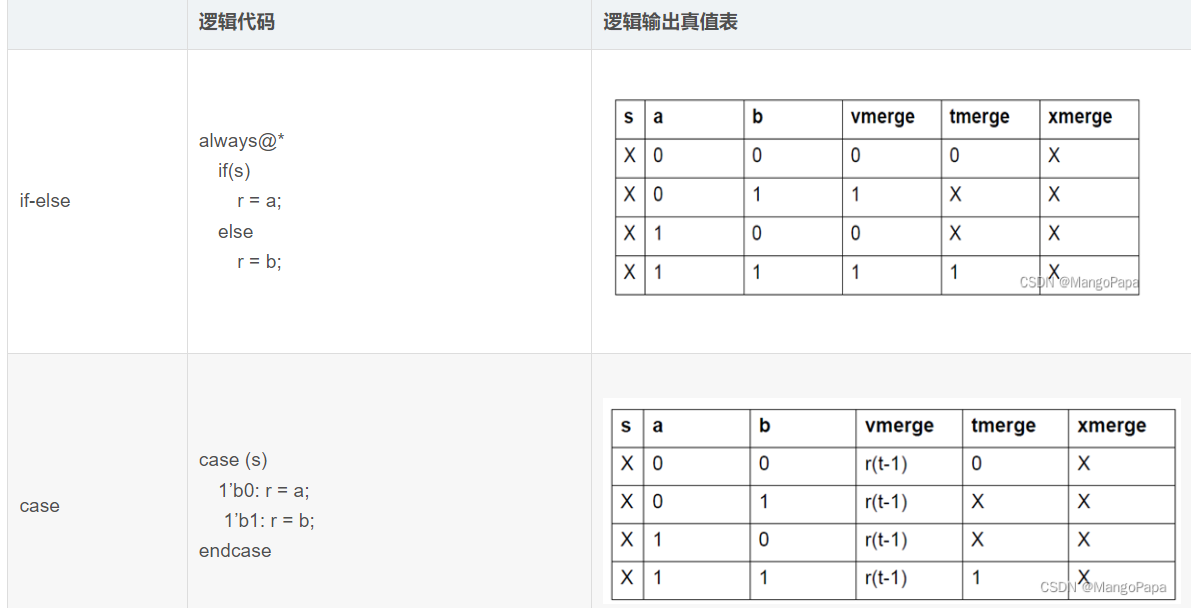
不同 Merge Mode 时的 X 态传播情况如下表所示:

sv的process线程使用
一个线程的创建往往是fork的方法,但是控制线程结束,要么直接disable fork,要么是disable label,要么是用process。前两个,如果出现多个fork,多个相同的label,都会杀掉,似乎在开发稍微大一点点的系统上,容易引出bug(并不需要杀掉多个,但是label无意写了相同)。
process似乎是更好的选择,但是process需要知道如何使用。
查阅手册的时候,往往需要使用关键字和实例,而一个class在使用的时候,往往尾端有分号,因此查找的关键词为:process;
以下是process类的声明:

以下是使用实例:
让多个线程同时创建,并在多个线程都启动后,等到线程1(第一个线程)完成,杀掉其它所有线程。

参阅
主要是sv的IEEE语言手册,然后是其他人的总结
http://www.lujun.org.cn/?p=1518
this和local的区别
这两个sv的关键词似乎有一点相似,但是其实不同的。
local是找到当前域里面的变量,this是找到当前类里面的变量,super是找到父类里的变量。
学习了语法(没有试过,但是逻辑说的通):https://zhuanlan.zhihu.com/p/493854166
this
class trans;
string name;
function display(output string name);
name = this.name;
endfunction
endclass
class trans_ex extends trans;
string name;
function display(output string name);
name = super.name;
endfunction
endclass
local
下述使用的约束data是形参data,如果是使用this.data,则约束data是class的data。
由这个例子可以看出,local::关键词可以索引到当前域(class, task, function)中的变量,而this则是索引一个类中子类新扩展的变量还是从父类继承来的变量。
class trans_rand;
int [31:0] data;
trans t,h;
virtual task write_reg(bit[7:0] addr, bit[31:0] data);
t = new();
void'(t.randomize() with {data == local::data;});
//local::data索引到的是形参data,
endtask
//而不带前缀的data按就近原则索引到t中的data
virtual task send_trans();
h = new();
assert(h.randomize with {local::data >= 0 -> data == local::data;})
//local::data索引到的是trans_rand类中的data,
endtask
//而不带前缀的data按就近原则索引到h中的data
endclass
class trans;
rand int [31:0] data;
constraint cstr {
soft data[31:6]==0;
};
endclass
PCIe信号补偿技术
总所周知,信号可以拆解为一系列不同的正弦波,信号如果失真的时候,可以通过各种方法补偿,添加一些输入,恢复信号。
重点看别人写的
https://mangopapa.blog.csdn.net/article/details/124538348
PCIe 高速串行信号经信道从发送端传输到接收端后,其高频分量比低频分量衰减要大,而高频分量主要集中在信号的上升沿及下降沿。
为了补偿这种高频衰减,在信号发送的时候,有意增强信号跳变沿的信号幅度,增高高频分量,即信号预加重;
相比于预加重的方案,去加重则是降低跳变沿之外的信号幅度,削弱低频分量,同样能够达到目的。
接收端均衡器相当于高通滤波器,来补偿失真的波形。

PCIe 均衡系数协商
传输速率上升至 8 GT/s 及以上后,收发端均衡更加复杂,收发端之间需要协商均衡系数,以获得最佳传输性能。
收发端在链路训练的 Recovery.Equalization 状态进行均衡系数协商。
整个 EQ 过程包括 4 个过程,称作4个Phase。
当速率为 8 GT/s 及以上时,EQ Phase 信息存放在了 TS1 的 EC 字段(Symbol 6,bit 0~1)。
四个 Phase 中,Phase0/1 采用 Preset 粗调,Phase2/3 精调。如果粗调阶段就达到了信号质量需求,也可以不进行精调。除非有特别配置,8 GT/s 以上速率时必须进行 EQ,至少在最高速率上要进行 EQ,中间速率可以跳过 EQ。
比如最高支持 32 GT/s,那么在 8 GT/s,16 GT/s 的时候可以跳过 EQ。从 32GT/s 降速时,需要重新进行链路训练并做 EQ。
在某一传输速率下,通过单独调整每一条 Lane 的收发端均衡器系数,使得链路上所有有效 Lane 上的传输误码率 BER≤10-12 即认为该速率均衡完成。如果在一定时间内无法达到 BER≤10-12 的通信性能,则认为当前速率均衡失败。
Le vent se lève! . . . il faut tenter de vivre!
Le vent se lève! . . . il faut tenter de vivre!
