【大数据-文摘笔记】京东HBase平台进化与演进
1.HBase京东集团级存储
HBase的软件,它的实现思想与Google Bigtable相似(也可以理解为是Bigtable的开源实现),是一个高可靠、分布式,面向列的开源数据库。直到今天HBase经历了十几个年头的发展,已经被应用在各种数据存储场景,成为大数据处理中不可缺少的一种解决方案。
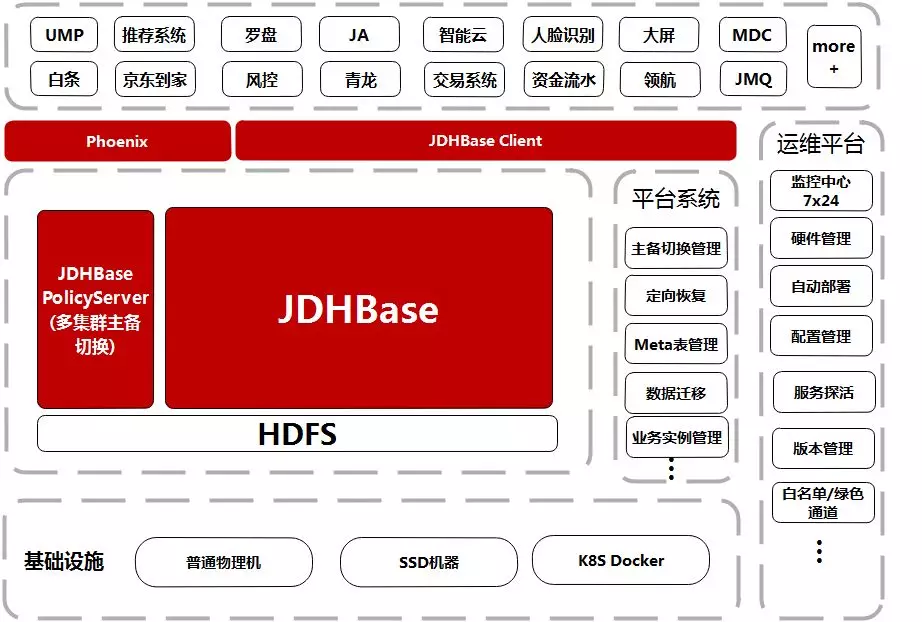
京东HBase平台作为集团级的存储服务,从商城前端到物流存储、从订单明细到金融分析等系统都有HBase的身影。它的稳定性和性能如果出现问题会直接影响到上层应用。可以说HBase是京东的核心服务之一。在长达几年的迭代过程中,HBase团队推动多次架构升级与优化,从最初的“裸奔”到后面拥有了丰富的降级与灾备手段,如:分组管理,限速&配额,跨机房智能灾备等功能。
2.应用场景
HBase在京东有着丰富的应用场景,在线部分我们提供每秒百万级的实时数据查询服务。如:商家营销、个性推荐、POP订单等业务应用。离线部分我们提供了每秒千万级的读写,支撑离线数据处理。
2.1 京东的典型业务有:
- 商城:商品评价、会员Plus、个性推荐、用户画像、POP订单、商家营销、即时通讯
- AI:智能客服、AI图片、图像识别、门禁刷脸
- 金融:风控、白条、支持、资管
- 物流:订单追踪、物流仓库、销量预测
- 监控:统一监控、服务器监控、容器监控、大数据监控、大屏监控
POP是卖家在京东销售商品,卖家每日将消费者订单打包送京东分拣中心,京东完成购物订单配送和收款,卖家开发票给消费者。
SOP是卖家在京东销售商品,卖家每日将消费者订单打包并自行或采用快递完成购物订单配送,卖家开发票给消费者(卖家可在众多快递中,选择京东快递做货到付款业务并享受专业的配送服务体验)
2.2 通过抽象与归纳HBase在京东的主要应用方向围绕在以下三个场景:
(1)超大规模毫秒级读场景
HBase需对上层最终用户提供批量查询和聚合的报表服务,,典型的如京东对千万商家提供的智能分析应用,在这种场景下业务用户的查询很容易就会穿透缓存到最底下的HBase存储层获取数据。
(2)离线数据T+1日批量存储
每天晚上将会有大量的数据被加工出来,然后这些加工好的数据会被推入HBase供上层系统使用。在每天凌晨1点到5点是HBase写入最高峰,各个系统都在这个阶段进行数据入库处理。
(3)实时数据毫秒级读和写
在这种生产者消费者的模式下,实时处理程序负责生产并存入HBase,再下游的应用直接使用新入库的数据。从而要求数据入库的时效与延迟必须达到毫秒级,同样的查询延迟也要求必须做到毫秒级。
2.3 HBase中京东数据规模如下:
京东积累了丰富的数据类型,如:结构化的订单信息、会员信息、即时通讯信息,非结构化的图片、训练模型,时序型的监控信息等。
在2018年京东HBase集群规模增长到了7000多台,存储容量达到了90PB。(硬盘有SSD和HDD两种规格)支撑了京东700多个业务系统。
3.平台架构
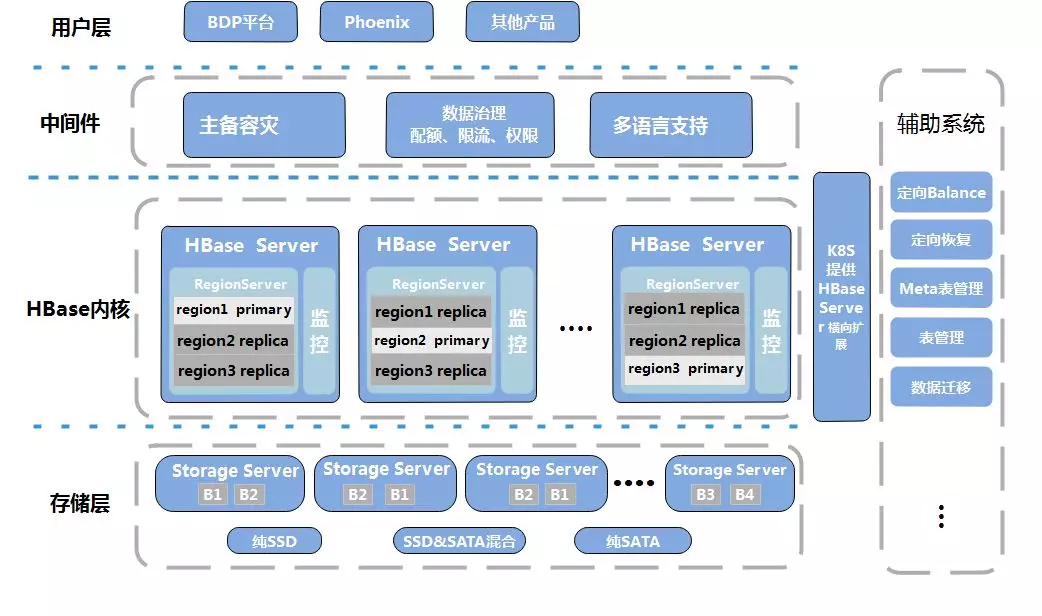
整个JD-HBase平台逻辑拆分成存储层、内核层、中间件层、用户层和一个辅助系统。
底层部署上我们支持将HDFS和HBase分开部署,同时可以利用容器技术K8S快速扩容和创建新的HBase集群。满足各种场景的读写需求。
在HBase内核部分我们通过修改源码让HBase RegionServer能够依据运行的硬件类型根据预设值自适应到最佳性能状态,支持多种硬件混合部署集群。
在中间件部分我们通过接口的方式提供了多个子系统和服务向外围系统提供支持,如主备容灾、数据治理服务、集群分组管理服务、权限管控服务、配额&限速管理服务,多语言支持组件等。
在用户层我们向最终用户提供多种可选的数据加载方式和查询引擎满足不同业务场景和需求。
4.多活灾备
HBase提供了主备Replication的方案。此方案的原理也比较简单,就是写向主的数据会异步的流向备集群。如果主集群出现问题可以让业务切换到备集群。但需要让每个业务自行进行切换,人工成本很高而且不具备实时性,对于低延迟的业务稍微一个抖动都无法接受,更别说重启应用。
4.1 智能主备切换
自主研发了一套基于策略的多集群切换机制。在集群拓扑上每个集群都会有备份集群,来保证跨机房的数据备份。从安全维度上我们分别做到了,集群级、namespace、表级的支持,可以针对每个级别设置不同的容灾切换策略。如:手动、自动、强制等。通过这种方式我们可以随时调整策略将部分业务分批、分级切换,如:隔离、降级、防雪崩等场景。
工作组件由客户端、HBase PolicyServer、ServiceCenter三部分构成:
- 客户端:定期以心跳的方式访问HBasePolicyServer获取所操作对象的集群服务信息和切换策略信息,当发现主集群信息改变之后客户端会根据切换策略进入切换流程。
- HBasePolicyServer:对外提供查询和修改策略的服务,它所有策略数据会存储在MySQL中。可以通过加节点的方式动态扩展形成一个服务集群,避免单点问题。
- ServiceCenter:一个界面化的多集群管理服务供管理员使用。
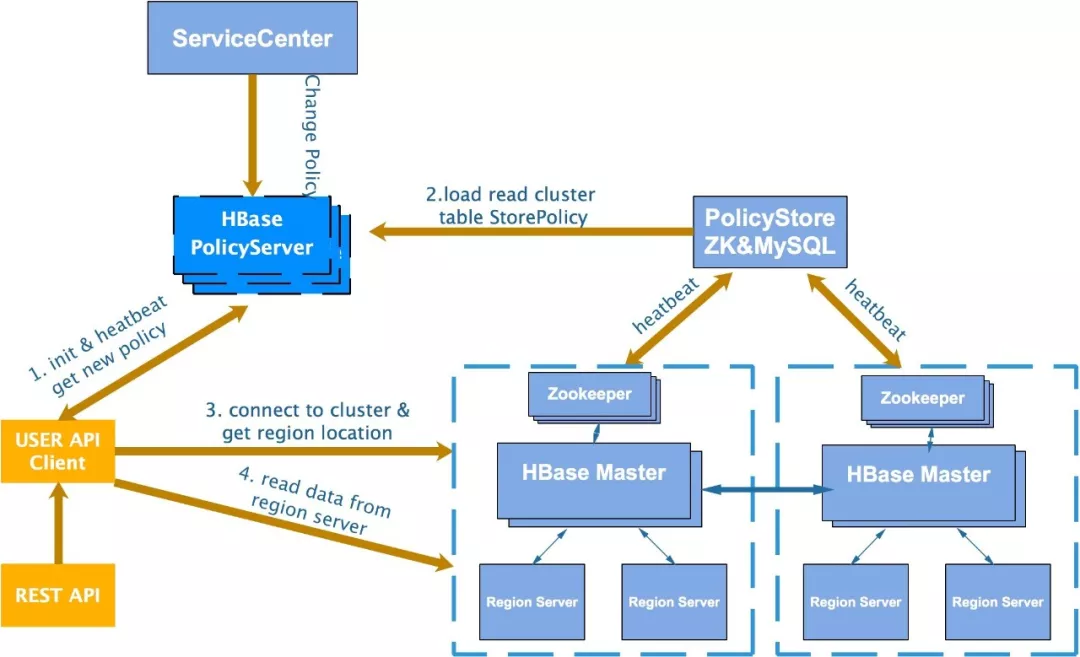
在极端情况下,如果主集群彻底瘫痪,我们可以通过强制切换的方式把所有业务快速切换到从集群。同时触发主备数据同步校验机制,后台会自动在主集群状态恢复后把数据对齐。保证数据一致性。
4.2主备一致性
因为主备集群间数据以异步的方式进行传输同步(虽然可以做成同步,但性能很差),假如跨机房或集群之间的网络有问题,那么数据将积压在主集群。很不幸如果我们在这个时间业务发生了切换那么最新的数据在备集群将读取不到。这也是不可接受的。现在阶段我们采用了比较简单的压缩并发传输WAL,然后备份集群解压回放的机制进行解决。
5.HBase多租户资源隔离
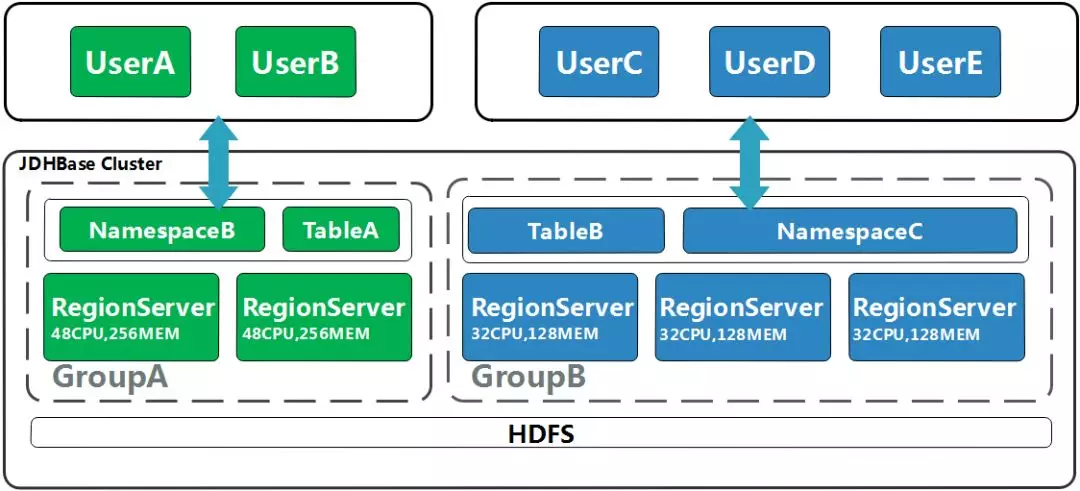
5.1物理资源隔离(分组管理)
(1)痛点
HBase早期的使用方式是一个业务一个集群,但是资源利用率低,维护成本高。虽然也可以多个业务共用一个集群,但是会有资源竞争和故障扩散等问题,一个业务出现异常可能会影响整个集群的可用性。
(2)方案
HBase2.0以后引入分组功能,实现了将HBase集群动态切分成多个分组,每个分组中有多台物理服务器。可以按不同的资源配置进行分组,然后把性能要求高业务放在高配的分组中增加读写吞吐。
这样既能将业务进行物理隔离防止资源竞争和故障扩散,还能在618和11.11大促时期动态调整集群资源,提升硬件资源利用率。
5.2 限速&配额
(1)痛点
有个别业务出于某些原因占用较多的集群资源,就会导致关键的业务无法得到及时反馈,产生更严重的影响。
另一方面,假如有些异常代码并发不停的读写一个表,并且这个表有局部region热点,这种操作对集群的性能是致命的,它极有可能将RegionServer的性能耗尽,造成这台RegionServer的请求大面积堆积。
(2)方案
为了让业务更合理的利用资源,我们增加了配额与限速功能(Backport from 2.0)。并在这些功能基础上增加了用户级、表级、namspace级的异常流量访问报警。帮助运维人员更加快速的定位问题。
6.Phoneix SQL& OLTP
原生的HBase只提供key-value查询和范围扫描。这种方式只能通过编码调用API的方式进行读写,很不友好。通过调研我们引入了开源的Phoenix组件,这个组件支持以SQL的方式查询HBase,让业务可以使用SQL的方式快速查询HBase获取数据。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号