

场景
HDFS的访问方式之HDFS shell的常用命令:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119351218
在上面使用HDFS shell的方式去访问HDFS。
那么怎么使用Java API的方式去操作HDFS。
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
CentOS7上搭建Hadoop集群(入门级):
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119335883
在Windows上的搭建流程和上面的流程前面类似。
首先下载hadoop的tar包,这里选择版本和上面搭建的集群的版本一致。
在windows上依托于解压工具比如7-zip将tar.gz解压成tar再进行解压成目录如下
解压之后将其挪到没有中文路径和空格的目录下
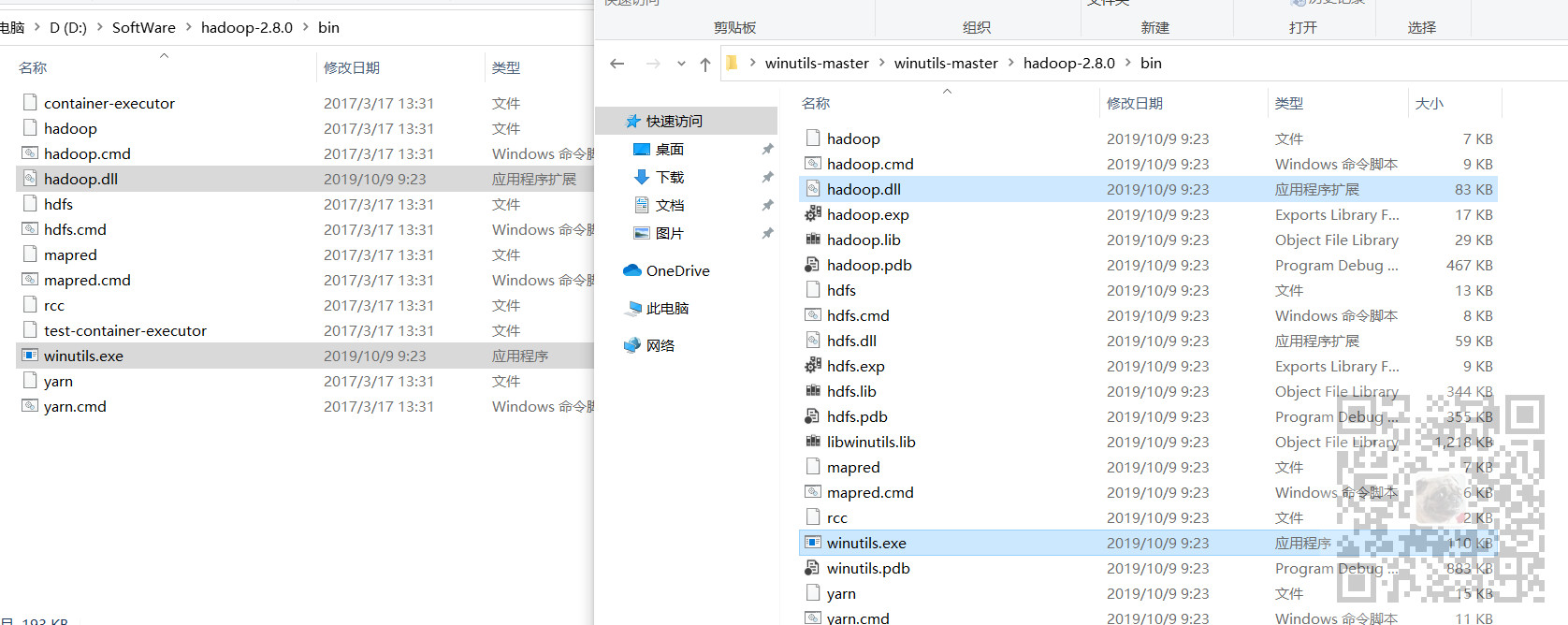
下载之后如果需要编程、还需要在hadoop的bin目录下添加对应版本的hadoop.dll和wintuils.exe
https://github.com/cdarlint/winutils
或者
https://download.csdn.net/download/BADAO_LIUMANG_QIZHI/20691010
下载之后将对应版本的hadoop.dll和winutils.exe复制到hadoop的bin目录下
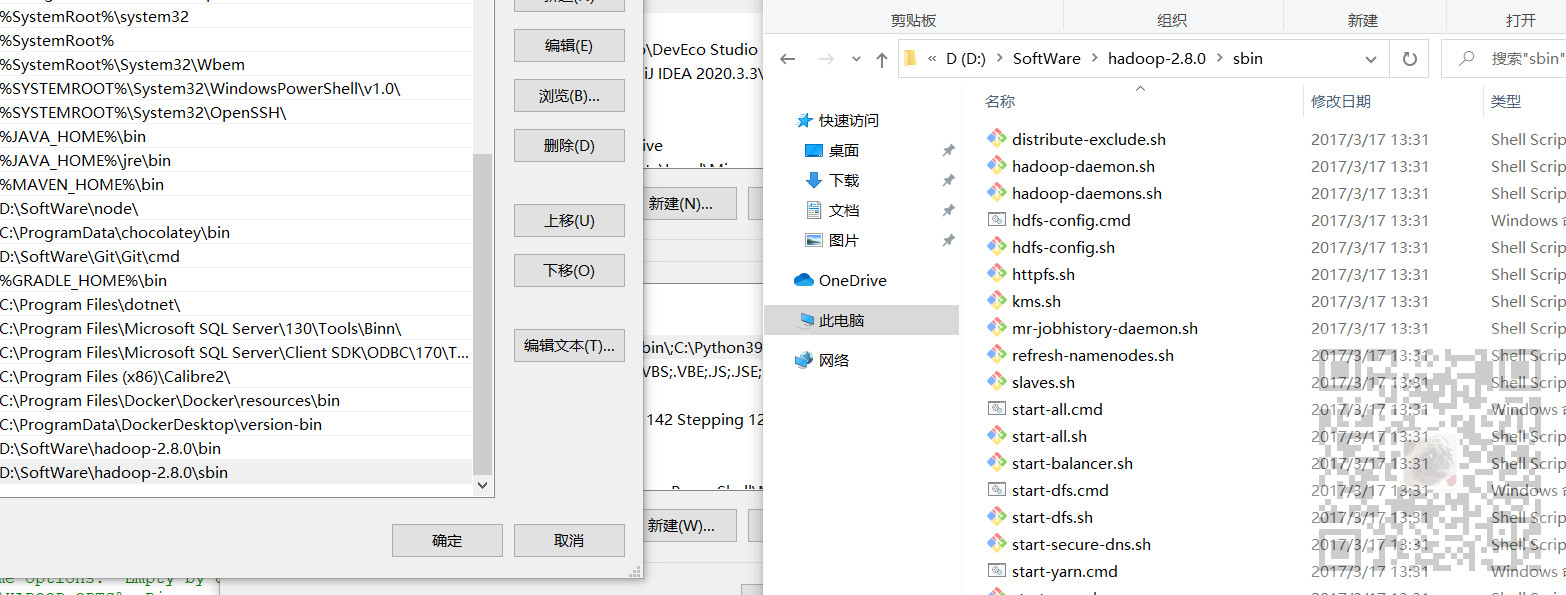
配置环境变量
将上面Hadoop的bin目录和sbin目录都添加到环境变量Path中
修改配置文件
按照上面Centos中搭建Hadoop流程中的配置文件,依次修改Windows下同目录的配置文件
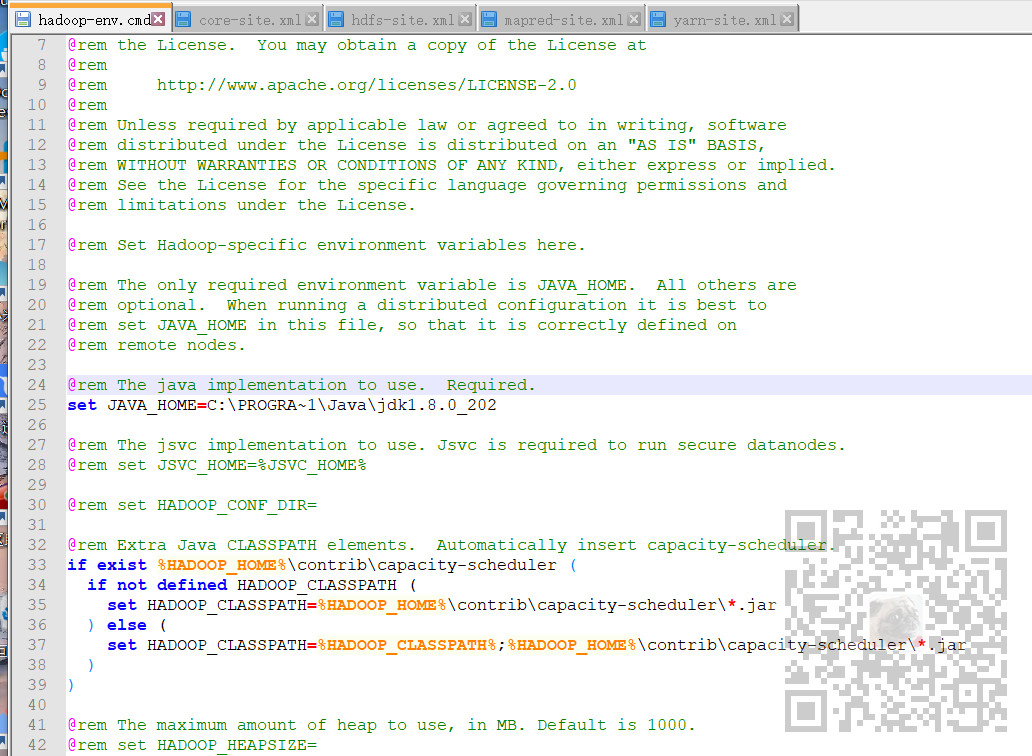
1、修改hadoop-env.cmd
修改这里的JAVA_HOME为对应目录
这里的jdk在默认路径下 ,Program Files有中文路径,可以使用
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_202
进行代替
2、修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.148.128:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>D:\SoftWare\hadoop-2.8.0\hdfs\tmp</value>
</property>
</configuration>
将这里的集群访问地址改为master的ip地址,将数据路径改为在Windows上的路径
3、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4、修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.148.128:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.148.128:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.148.128:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.148.128:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.148.128:18088</value>
</property>
</configuration>
全部改为master的ip地址
验证配置
在Windows中打开cmd
hadoop version
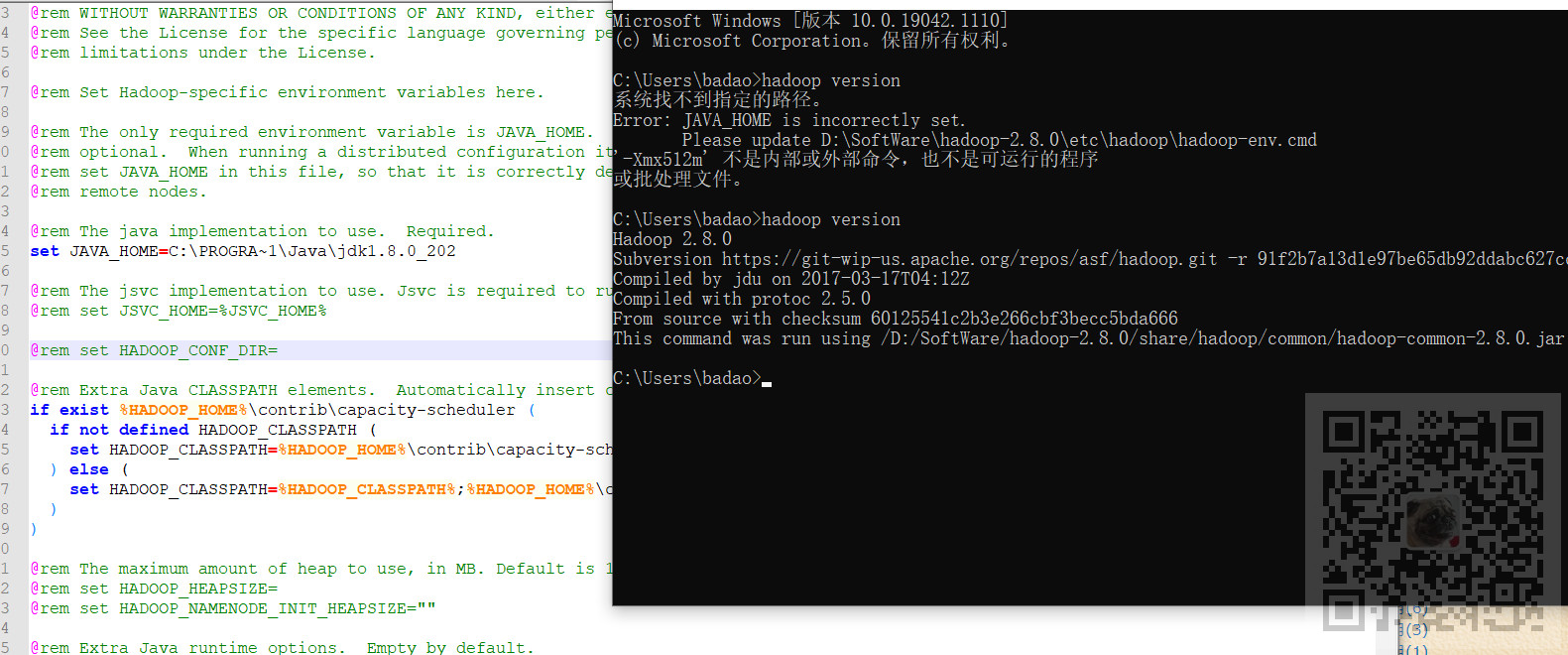
然后输入
hdfs dfs -ls /
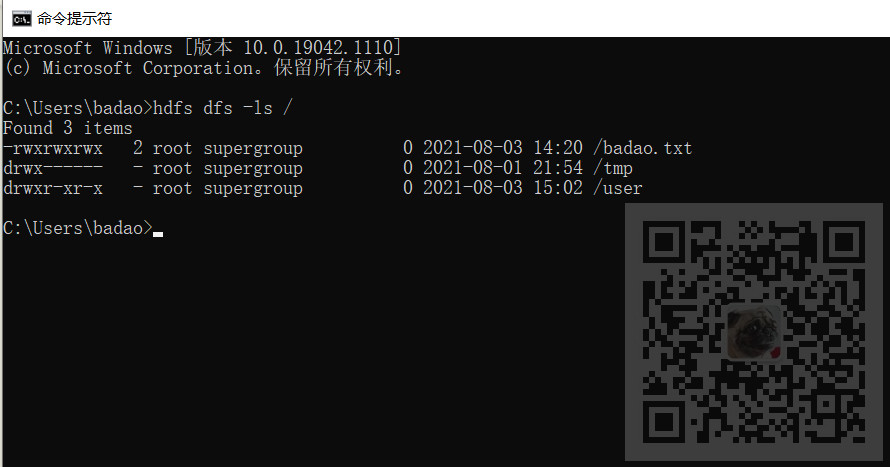
查看hdfs中根目录下所有文件
用Java API 操作HDFS
打开IDEA-新建一个Maven项目,pom.xml中引入依赖,这里与集群中
hadoop的版本一致。
在Maven仓库中搜索hadoop
需要如下依赖
hadoop-client
hadoop-common
hadoop-hdfs
hadoop-hdfs-client
hadoop-mapreduce-client-core
junit
pom.xml依赖如下:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
然后新建包,包下新建类,类中新建main方法
package com.badao.hdfsdemo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.IOException; public class hellohdfs { public static void main(String[] args) throws IOException { FileSystem fileSystem = getFileSystem(); //获取文件详情 RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(new Path("/"), true); while (listFiles.hasNext()){ LocatedFileStatus status = listFiles.next(); //输出详情 System.out.println(status.getPath().getName());//文件名称 System.out.println(status.getLen());//长度 System.out.println(status.getPermission());//权限 System.out.println(status.getOwner());//所属用户 System.out.println(status.getGroup());//分组 System.out.println(status.getModificationTime());//修改时间 //获取存储的块信息 BlockLocation[] blockLocations = status.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { //获取块存储的主机节点 String[] hosts = blockLocation.getHosts(); for (String host : hosts) { System.out.println(host); } } } fileSystem.close(); } /** * 获取HDFS文件系统 * @return * @throws IOException */ public static FileSystem getFileSystem() throws IOException { Configuration configuration = new Configuration(); configuration.set("fs.defaultFS","hdfs://192.168.148.128:9000"); configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); System.setProperty("HADOOP_USER_NAME","root"); FileSystem fileSystem = FileSystem.get(configuration); return fileSystem; } }
注意:
其中main方法中调用了获取HDFS文件系统的方法getFileSystem
1、configuration.set("fs.defaultFS","hdfs://192.168.148.128:9000");
这里的集群的访问地址与core-site.xml中fs.defaultFS配置的一致。
2、configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
这里的目的是:
如果不加这个就会提示:
Exception in thread "main" java.io.IOException: No FileSystem for scheme: hdfs
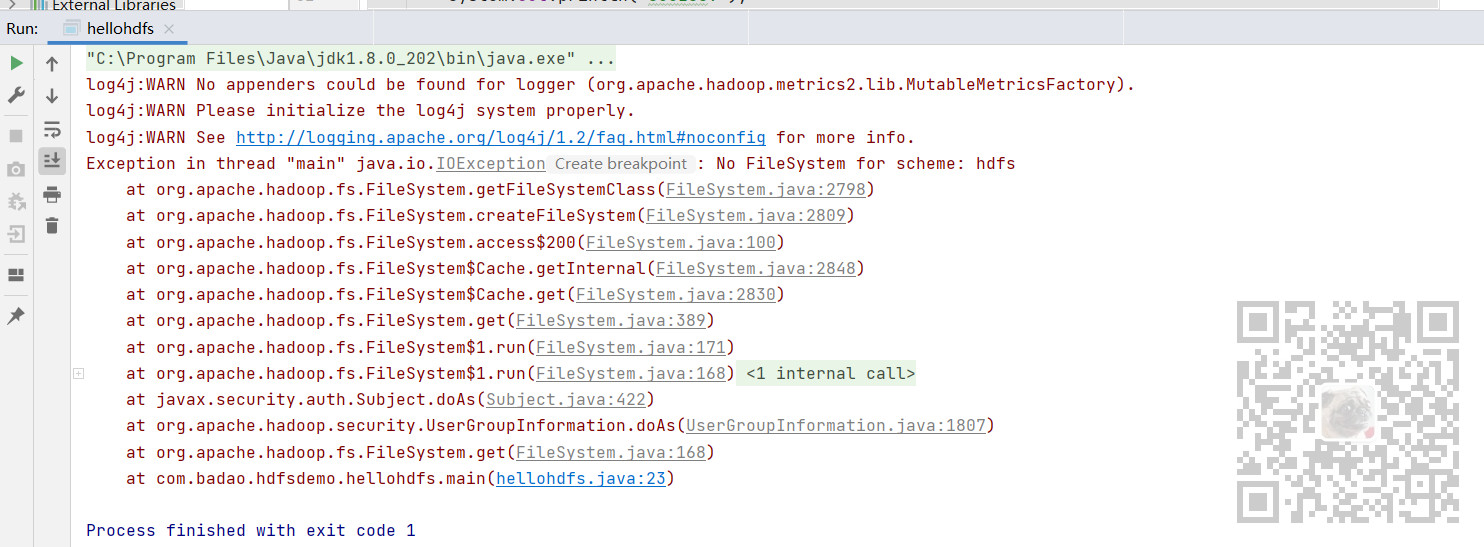
hadoop filesystem相关的包有以下两个:hadoop-hdfs-xxx.jar和hadoop-common-xxx.jar(xxx是版本),而他们当中都有org.apache.hadoop.fs.FileSystem这个文件
调用的接口是hadoop-hdfs-xxx.jar中的,所以很明显No FileSystem for scheme: hdfs这个问题是因为,相同文件被覆盖了
3、System.setProperty("HADOOP_USER_NAME","root");
如果不加这个就会提示:
org.apache.hadoop.serurity.AccessControlException:Permission denied: user =

效果
然后运行main方法,获取HDFS根目录下所有的文件的详情


