


场景
Hadoop
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软
件框架,支持在商品硬件构建的大型集群上运行应用程序。Hadoop是根据Google公司发表的
MapReduce和GFS论文自行开发而成的。
Hadoop框架透明地为应用提供可靠性和数据移动,它实现了名为MapReduce的编程范式:
应用程序被切分成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。此
外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了
非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。
Hadoop2.0生态系统
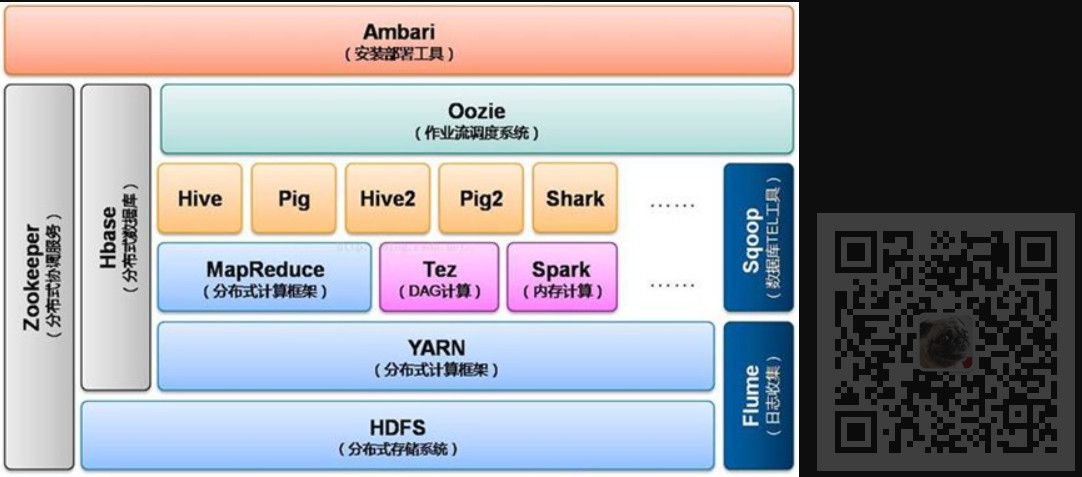
HDFS
对于分布式计算,每个服务器必须具备对数据的访问能力,这就是HDFS (Hadoop
Distributed File System)所起到的作用。在处理大数据的过程中,当Hadoop集群中的服务器
出现错误时,整个计算过程并不会终止,同时HDFS可以保障在整个集群中发生故障错误时
的数据冗余。当计算完成时将结果写入HDFS的一个节点之中,HDFS对存储的数据格式并无
苛刻的要求,数据可以是非结构化或其他类别的,而关系数据库在存储数据之前需要将数据
结构化并定义Schema。
MapReduce
MapReduce是一个计算模型,用于大规模数据集的并行运算。它极大地方便了编程人员
在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。MapReduce的重要创
新是当处理一个大数据集查询时会将其任务分解并在运行的多个节点中处理。当数据量很大
时就无法在一台服务器上解决问题,此时分布式计算的优势就体现出来了,将这种技术与
Linux服务器结合可以获得性价比极高的替代大规模计算阵列的方法。Hadoop MapReduce级
的编程利用Java APIs,并可以手动加载数据文件到HDFS中。
ZooKeeper
ZooKeeper是一个分布式应用程序协调服务,是Hadoop和HBase的重要组件。它是一个
为分布式应用提供一致性服务的软件,提供的功能包括配置维护、域名服务、分布式同步、
组服务等。
ZooKeeper集群提供了HA,可以保证在其中一些机器死机的情况下仍可以提供服务,而
且数据不会丢失;所有ZooKeeper服务的数据都存储在内存中,且数据都是副本。ZooKeeper
集群中包括领导者(leader)和跟随者( follower)两种角色,当客户端进行读取时,跟随者的
服务器负责给客户端响应;客户端的所有更新操作都必须通过领导者来处理。当更新被大多
数ZooKeeper服务成员持久化后,领导者会给客户端响应。
HBase
HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数
据库。与传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表
(key/value ),其中键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随
机、实时读写访问,使用Hadoop HDFS作为其文件存储系统,同时HBase中保存的数据可以
使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
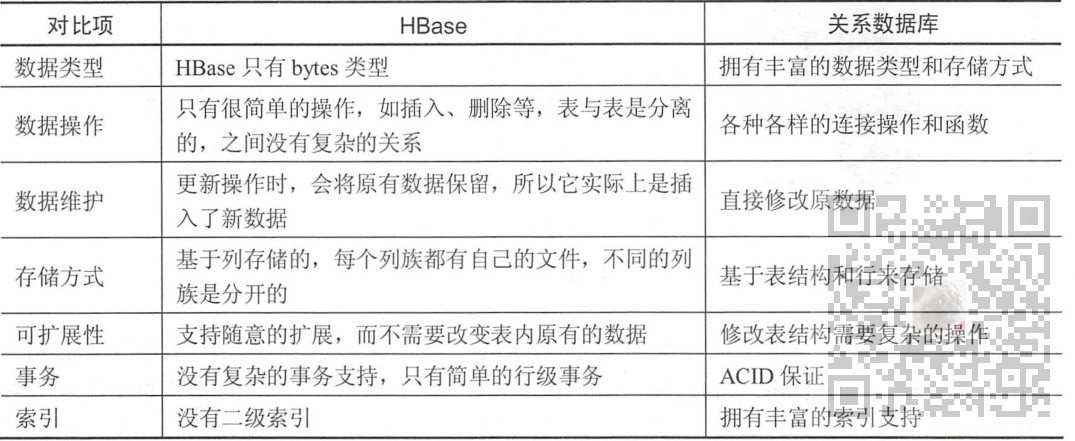
HBase与关系型数据的对比
Hive
Hive是基于Hadoop的一个数据仓库工具,由Facebook开源,最初用于海量结构化日志
数据统计,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可
以将SQL语句转换为MapReduce任务运行。通常用于进行离线数据处理(采用MapReduce),
可以认为是一个从HQL (Hive QL)到MapReduce的语言翻译器。
Hive的特点如下:
1、可扩展。Hive可以自由地扩展集群的规模,一般情况下不需要重启服务。
2、支持UDF。Hive支持用户自定义函数,用户可以根据自己的需要来实现。
3、容错。良好的容错性,节点失效时SQL依然可以正确执行到结束。
4、自由的定义输入格式。默认Hive支持txt, rc、sequence等,用户可以自由地定制自
己想要的输入格式。
5、可以根据字段创建分区表,如根据日志数据中的日期。
Pig
Pig是一个高级过程语言,它简化了Hadoop常见的工作任务,适合于使用Hadoop和
MapReduce平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似SQL的查询,
Pig可以简化Hadoop的使用。Pig可以加载数据、表达转换数据和存储最终结果。Pig内置的
操作使得半结构化数据变得有意义(如日志文件),同时Pig可以扩展使用Java中添加的自定
义数据类型并支持数据转换。可以避免用户书写MapReduce程序,由Pig自动转成。任务编码的方式允许系统自动去
优化执行过程,从而使用户能够专注于业务逻辑,用户可以轻松地编写自己的函数来进行特殊用途的处理。
Mahout
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足
的发展,现在是Apache的顶级项目。Mahout的主要目标是创建一些可扩展的机器学习领域经
典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含
了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,
Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB或Cassandra)
集成等数据挖掘支持架构。
Sqoop
Sqoop是Hadoop与结构化数据存储互相转换的开源工具。可以使用Sqoop从外部的数据
存储将数据导入到Hadoop分布式文件系统或相关系统,如Hive和HBase。Sqoop也可以用于
从Hadoop中提取数据,并将其导出到外部的数据存储(如关系数据库和企业数据仓库),如
MySQL、Oracle、SQL Server,还可以通过脚本快速地实现数据的导入/导出。
Flume
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的
系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数
据进行简单处理,并写到各种数据接收方(可定制)的能力。它将数据从产生、传输、处理
并最终写入目标路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制
数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单
处理的能力,如过滤、格式转换等。总的来说,Flume是一个可扩展、适合复杂环境的海量日
志收集系统。
Chuwa
Chukwa是一个开源的用于监控大型分布式系统的数据收集系统,构建在Hadoop的HDFS
和MapReduce框架之上。Chukwa还包含了一个强大和灵活的工具集,可以用于展示、监控和
分析己收集的数据。
Oozie
Oozie是一个工作流引擎服务器,用于运行Hadoop MapReduce任务工作流(包括
MapReduce, Pig, Hive, Sqoop等)。Oozie Z作流通过HPDL (Hadoop
Process Defintion
Languge)来构建,工作流定义通过HTTP提交,可以根据目录中是否有数据来运行任务,任
务之间的依赖关系通过工作流来配置,任务可以定时调度。JobConf类要配置的内容,通过在
工作流(XML文件)中定义,实现了配置与代码的分离。
Ambari
Ambari是一种基于Web的工具,用于创建、管理、监视Hadoop的集群,支持Hadoop
HDFS,
Hadoop MapReduce, Hive, Hcatalog, HBase, ZooKeeper,
Oozie, Pig和Sqoop等的集中管理。
Yarn
Yarn是Hadoop 2.0版本中的一个新增特性,主要负责集群的资源管理和调度。Yarn不仅
可以支持MapReduce计算,还支持Hive, HBase, Pig, Spark等应用,这样就可以方便地使
用Yarn从系统层面对集群进行统一的管理。
Yarn仍然采用Master-Slave结构,在整个资源管理框架中,ResourceManager为Master,
NodeManager为Slave,
ResourceManager负责整个系统的资源管理和分配,NodeManage:负责
每个DataNode上的资源和任务管理。
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
集群环境搭建
1、首先搭建三台CentOS7的服务器(虚拟机)。
CentOS7下载与各版本区别(国内镜像网站下载):
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119025376
2、配置静态IP
这样可以避免IP冲突并获得网络相关信息
CentOS7中怎样设置静态IP:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119242495
3、配置主机名与hosts文件
配置一台服务器为主节点master,另外两台为从节点slave1和从节点slave2
CentOS7中怎样修改主机名和hosts文件(配置IP和主机名的对应管理):
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119245448
4、配置SSH免密钥登录。
Hadoop中的NameNode和DataNode数据通信采用了SSH协议,需要配置master对各slave
节点的免密钥登录。
CentOS7中多台服务器配置SSH免密钥登录:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119245853
在设置之后如果使用虚拟机并且出现虚拟机内能访问外网,虚拟机能访问宿主机
但是宿主机访问不了虚拟机的情况。
VMWare中修改CentOS虚拟机静态IP后主机没法访问虚拟机:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119297108
5、安装JDK
CentOS7中怎样安装JDK与配置环境变量:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119248028
三台服务器上都配置一下
6、关闭所有虚拟机防火墙。
关闭防火墙
systemctl stop firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service
7、配置时钟同步
CentOS7中多台服务器配置时钟同步:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/119276930
Hadoop的安装
下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
这里下载的版本是2.8.0

下载成功之后
将其上传到master主服务器并解压到根目录下hadoop目录下
或者说可以直接用
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
将其下载到服务器上并解压

修改配置文件
进入解压之后的/etc/hadoop目录下可以看到这里很多配置文件
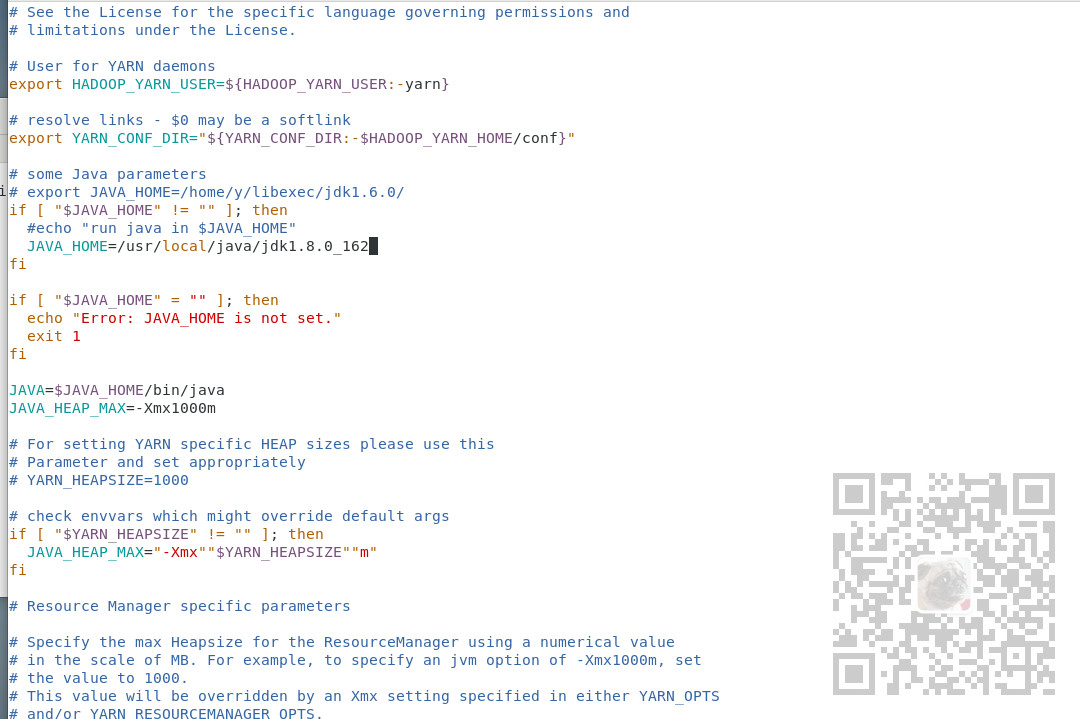
1、修改hadoop-env.sh 和 yarn-env.sh
以env.sh结尾的文件通常是配置所需的环境变量。
修改Java环境变量,修改为前面Java的安装路径
修改Hapdoop-env.sh

修改yarn-env.sh
2.修改core-site.xml
core-site.xml是Hadoop的全局配置文件,主要设置一些核心参数信息
如:
fs.defaultFS 设置集群的HDFS访问路径
hadoop.tmp.dir 指定NameNode、DataNode等存放数据的公共目录
首先创建如下目录
mkdir -p /hadoop/hdfs/tmp
然后修改配置文件在<configuration>中添加如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hdfs/tmp</value>
</property>
</configuration>
3、修改hdfs-site.xml
该文件是HDFS的配置文件,在<configuration>中添加如下
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
dfs.replication用来设置副本存放个数,在实际生产中还会设置
dfs.namenode.name.dir NameNode的存放路径
dfs.datanode.data.dir DataNode的存放路径
同时将core-site.xml中的hadoop.tmp.dir去掉避免冲突。
这里有几个注意点:
这里设置这两个目录和上面core-site中设置的目录为了避免冲突,要二选一,
最好不要都设置,甚至两个设置不一样的路径。
然后这个路径一定要提前创建好,否则put文件到hdfs系统时就会报错。
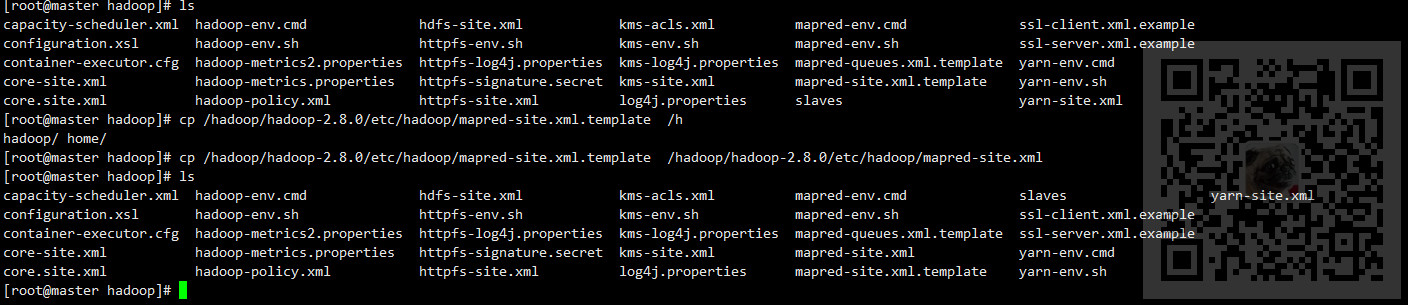
4、修改mapred-site.xml
该文件是MapReduce的配置文件,由于Hadoop中不存在该文件,因此首先复制一个
cp /hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
然后将其修改为指定由Yarn作为MapReduce的程序运行框架
如果没有配置这项,那么提交的程序只会运行在local模式,而不是分布式模式。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、修改yarn-site.xml
yarn-site.xml用来配置Yarn的一些信息。
yarn.nodemanager.aux-services
配置用户自定义服务,例如MapReduce的shuffle
yarn.resourcemanager.address
设置客户端访问的地址,客户端通过该地址向RM提交应用程序杀死应用程序等。
yarn.resourcemanager.scheduler.address
设置ApplicationMaster的访问地址,通过该地址向ResouceManager申请资源、释放资源等
yarn.resourcemanager.resource-track.address
设置NodeManager的访问地址,通过该地址向ResourceManager汇报心跳、领取任务等。
yarn.resourcemanager.admin.address
设置管理员的访问地址,通过该地址向ResouceManager发送管理命令等
yarn.resourcemanager.webapp.address
设置对外ResourceManager Web访问地址,用户可通过该地址在浏览器中查看集群的各类信息
修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
6、创建文件slaves
touch /hadoop/hadoop-2.8.0/etc/hadoop/slaves
将其内容修改为各slave节点的主机名
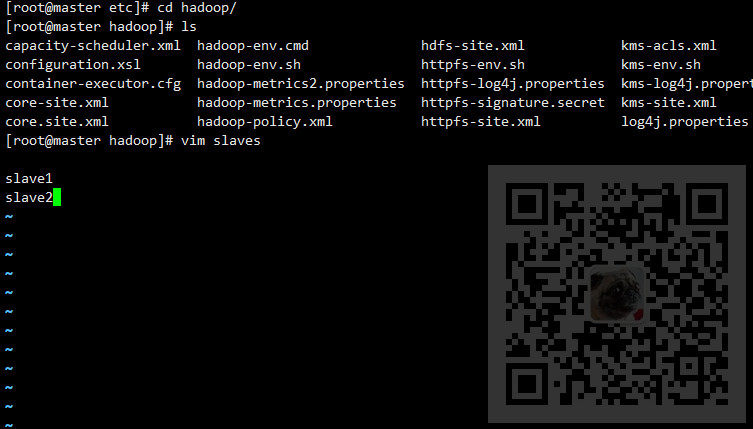
通过该master节点知道集群中有几个子节点,然后通过主机名和/etc/hosts的信息就知道各子节点对应的IP并和其通信
该文件只需在master节点配置即可,子节点不需要。
7、将修改后的hadoop分发到子节点。
scp -r /hadoop slave1:/
scp -r /hadoop slave2:/
这个过程可以会比较慢,需要等待
8、修改所有节点的环境变量
在/etc/profile的文件末尾添加Hadoop的环境变量
vim /etc/profile
添加如下配置
export HADOOP_HOME=/hadoop/hadoop-2.8.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后使环境变量生效
source/etc/profile
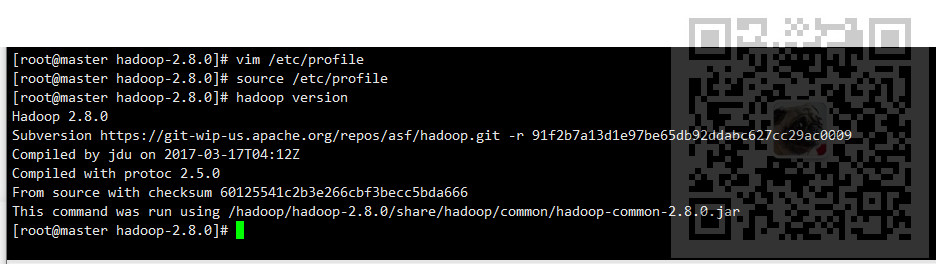
验证下是否配置成功
hadoop version
9、在master节点格式化NameNode
hdfs namenode -format
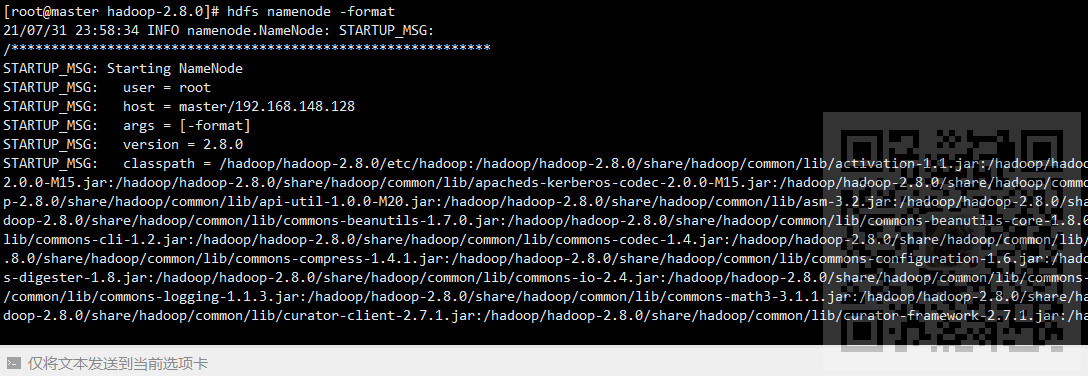
等待格式化完成
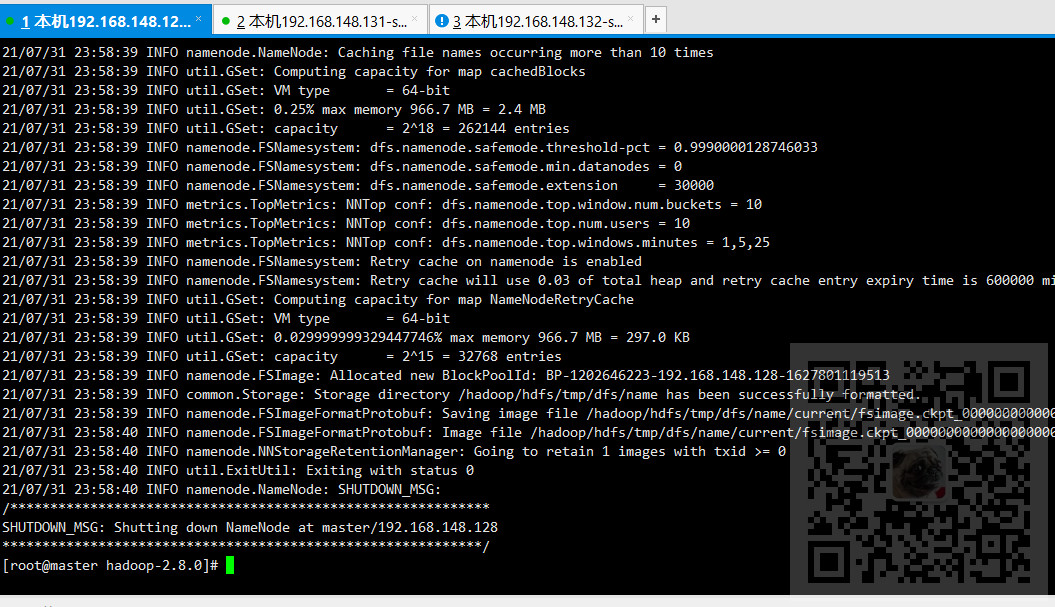
10、在master节点启动start-all.sh
start-all.sh就等同于start-dfs.sh和start-yarn.sh
此启动命令在sbin目录下,包括停止的脚本stop-all.sh
启动后会提示输入yes
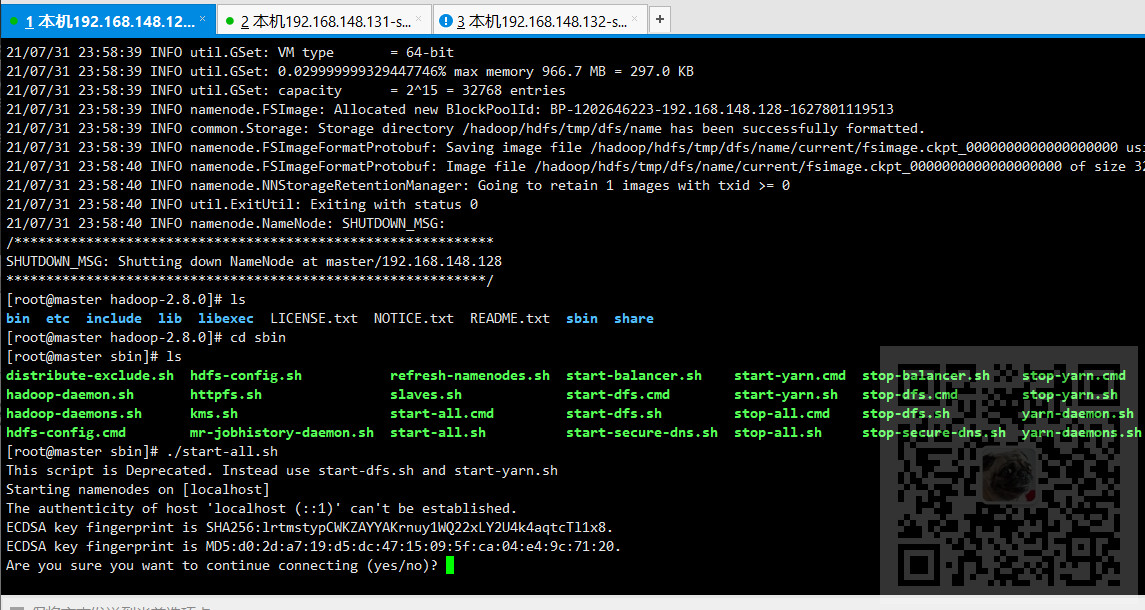
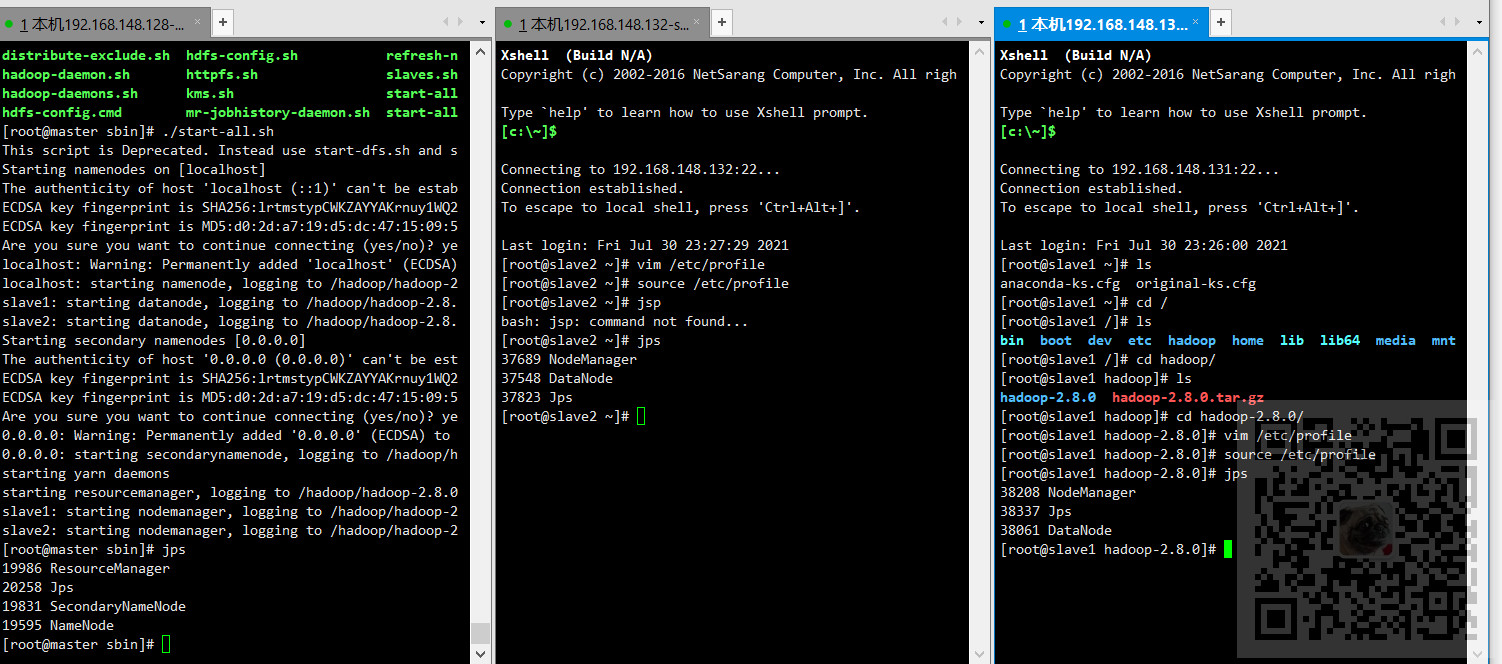
启动成功之后,在master以及各slave节点输入
jps
如果出现如下则是集群正常搭建
这块需要特别注意的是:
1、在配置Hadoop集群的时候,可能会不小心多次执行启动和格式化,这样会造成NameNode
和DataNode中的cIusterlD值不一致,遇到这种情况修改DataNode中的clusterlD即可,位置
在/hadoop/hdfs/tmp/dfs/data/current/VERSION
2、在初学的时候由于配置步骤不熟悉或者集群非正常关闭,会出现进程都己启动,但是
DataNode为0的情况,可以通过Web访问查看集群情况,或者运行Hadoop自带的MapReduce
实例验证集群节点情况,如果出现异常,可以根据各个节点下的log日志查看异常原因.通常
可以通过以下方法解决:
执行stop-all.sh命令,通过jps查看是否还有僵尸进程存在,有的话
将其杀死
然后删除/hadoop/dfs/tmp目录下的所有文件,重新对其格式化。
3、如果确定是master的各个配置文件配置的不正确,需要将各子节点的hadoop目录全部删掉
然后从master节点中将配置正确后的整个hadoop目录全部分发到各子节点,然后重新执行后面的
流程。
11、检查NameNode和DataNode是否启动正常
在浏览器中输入
检查NameNode是否启动正常
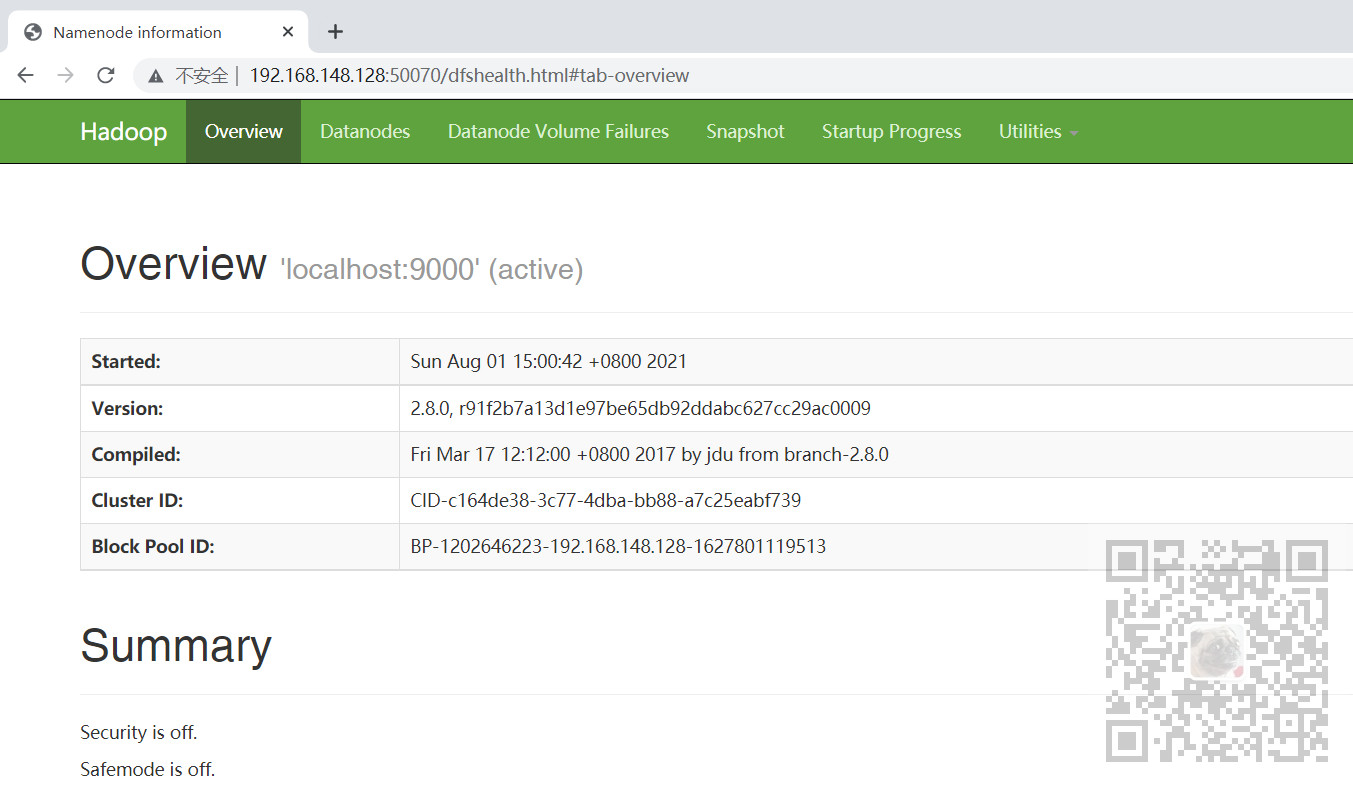
然后点击Datanodes检查是否启动正常
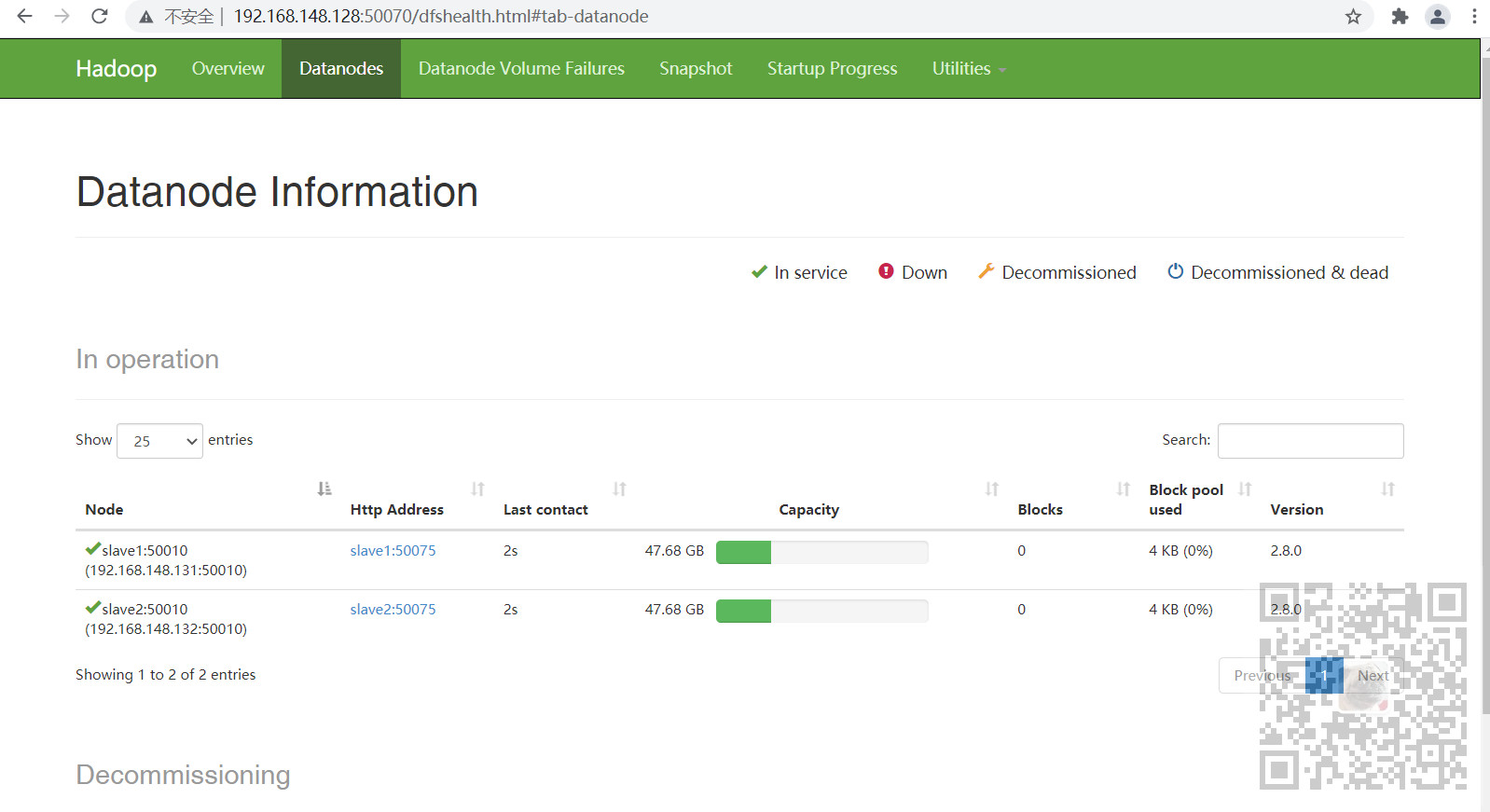
12、检查Yarn是否启动正常
在浏览器中输入
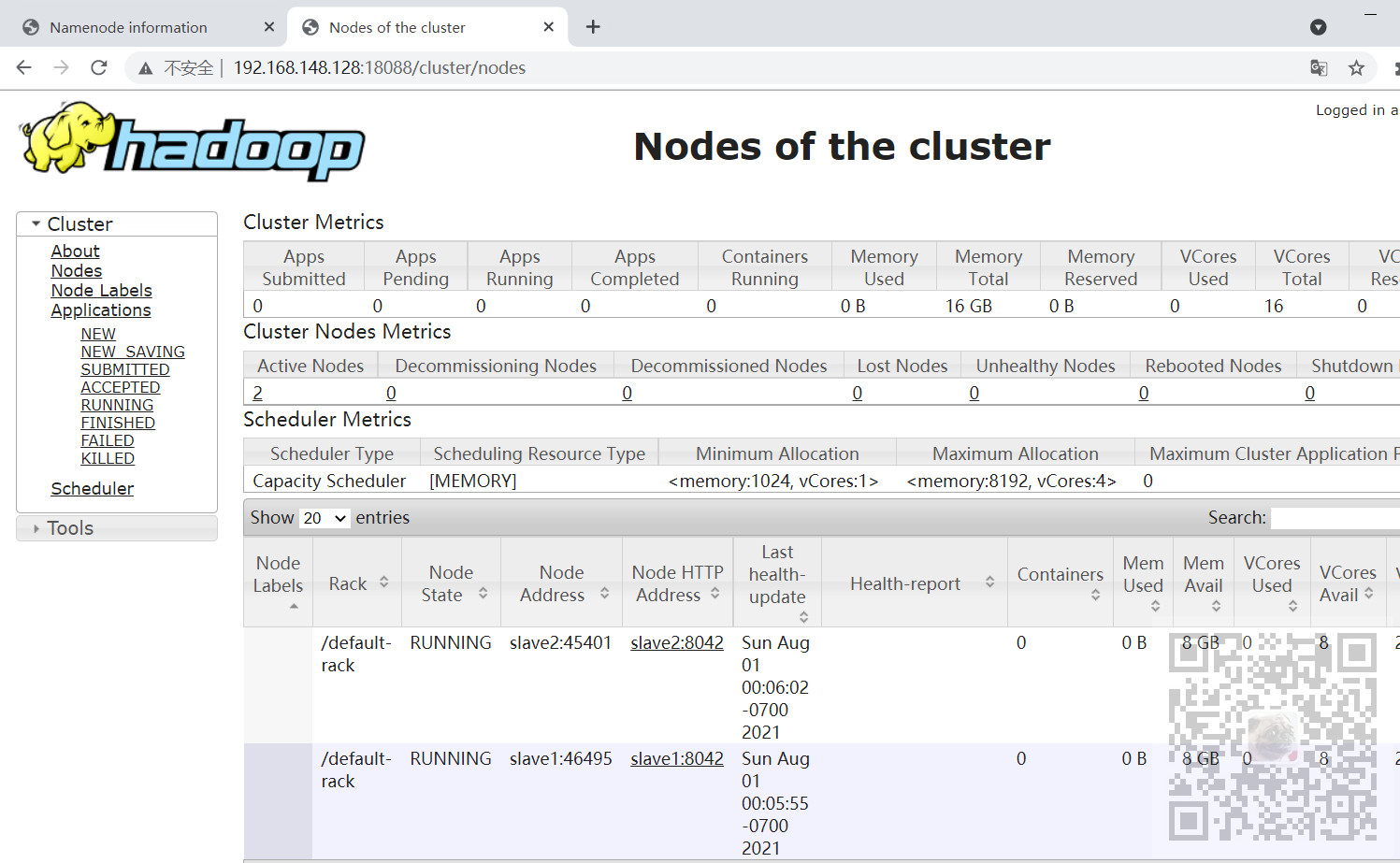
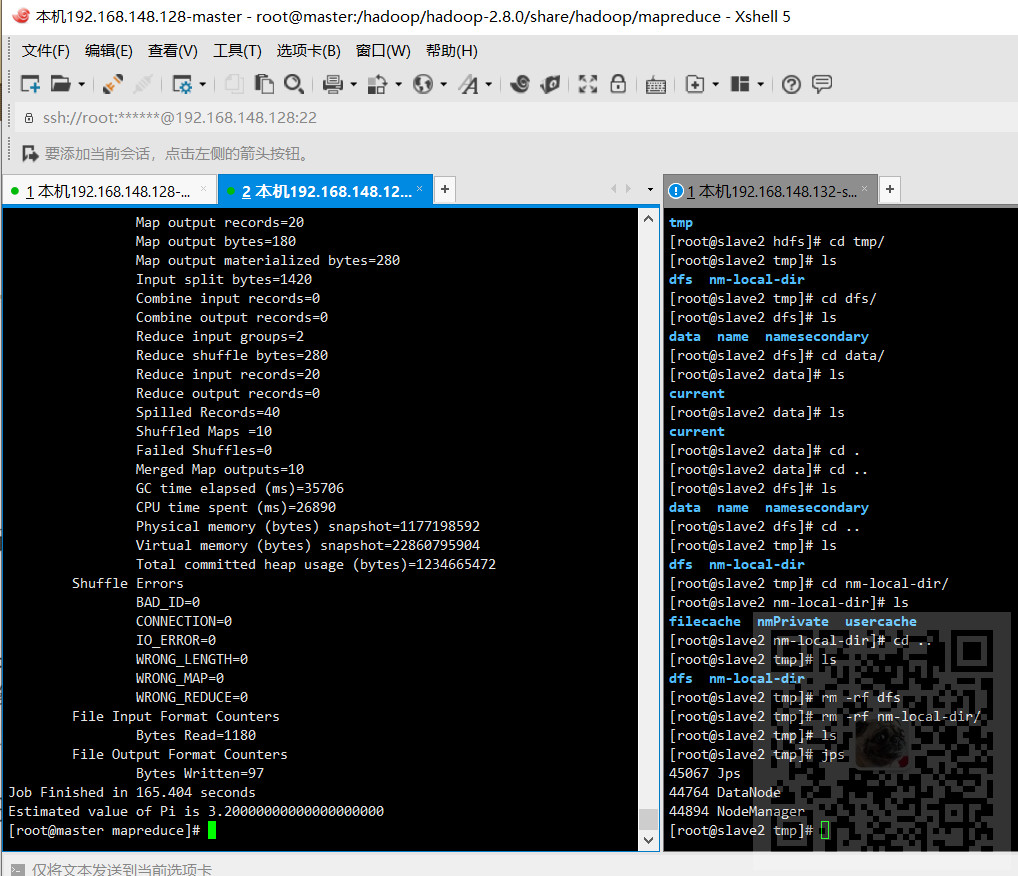
13、验证整个集群是否正常
在master节点上运行Hadoop自带的MapReduce例子,以验证整个集群是否正常。
进入目录/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/
运行命令
hadoop jar hadoop-mapreduce-examples-2.8.0.jar pi 10 10
这个代码是通过启动10个map和10个reduce任务求pi值,如果出现如下则是整个集群正常。
如果运行后提示:
There are 0 datanode(s) running and no node(s) are excluded in this operation
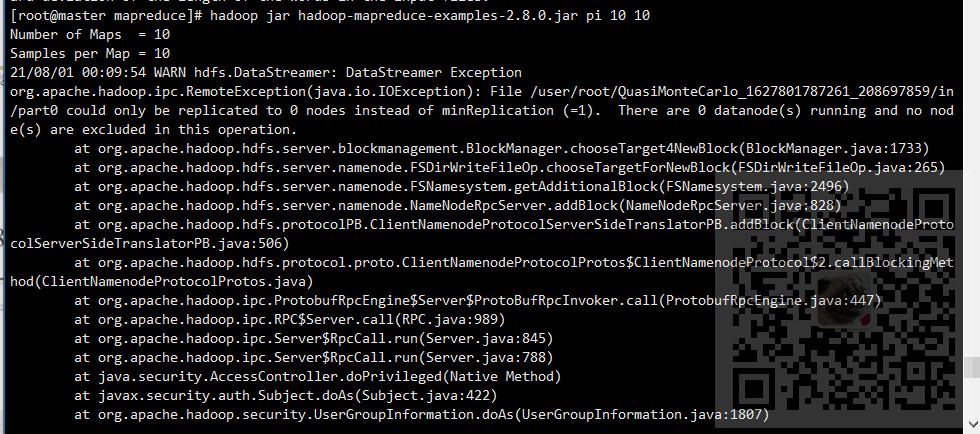
则可能是如下原因
1、上面讲的多次格式化之后clusterID不一致。
2、两个地方配置的NameNode和DataNode的路径不一致或者有问题。
3、服务器的防火墙没有关。
4、其他原因导致datanode没有正常启动。
