对梯度下降算法的理解和实现
对梯度下降算法的理解和实现
梯度下降算法是机器学习程序中非常常见的一种参数搜索算法。其他常用的参数搜索方法还有:牛顿法、坐标上升法等。
以线性回归为背景
当我们给定一组数据集合 \(D=\{(\mathbf{x^{(0)}},y^{(0)}),(\mathbf{x^{(1)}},y^{(1)}),...,(\mathbf{x^{(n)}},y^{(n)})\}\) ,其中上标为样本标记,每个 \(\mathbf{x^{(i)}}\) 为一个 \(d\) 维向量(向量默认加粗表示)。我们在有了一定数量的样本的情况下,希望能够从样本数据中提取信息或者某种模式,从而实现对新的数据也能具有一定的预测作用,这就需要我们找到一个能表示这组数据集合 \(D\) 的函数表达式。这样我们就从离散的点得到了连续的函数曲线,从而可以预测未曾见过的输入变量。
一种常见的假设是,将输入变量和输出变量之间的关系假设为线性关系:$$h_\theta(\mathbf x) = \theta_0 + \theta_1x_1 + ... + \theta_kx_d= \mathbf{\theta x^T}$$ 。其中 \(h\) 为 hypothesis,是我们假设的能够表示数据集合 \(D\) 的假设函数。而我们同时假设,存在一个 true function \(f\) ,使得样本集合 \(D\) 中的样本都是由该函数,加上一定的噪声产生的(因为我们无法考虑到与响应变量 \(y\) 相关的所有的情况,也无法搜集到所有的数据)。并且很常见的,我们假设噪声服从正态分布。机器学习的任务就是从假设函数空间 \(H=\{h_1,h_2,...,h_k\}\) 中找到一个对 true function 最好的近似。
这个寻找 \(h\) 的过程,就是机器去学习的过程。
从直观角度出发,我们可以设定这样一个目标函数:希望有一条直线能够距离每个样本点的距离都十分的近,整体来看,希望距离所有样本的距离和最近,这样的一条直线是最有可能接近 true function 的。形式化表达,可以表示为:
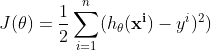
也可称之为损失函数。当该函数取得最小值时,说明当前的这个 \(h_\theta\) 是在当前数据集下对 true function 的最好的一个估计。
所以问题转化为一个最优化问题,在损失函数最小的情况下的 \(\mathbf{\theta}\) 是要求解的。这里我先举一个直观的例子。假设样本集合 \(D = {(1,2),(2,2)}\),\(h_\theta(\mathbf x) = \theta_0 + \theta_1x\) ;在此数据集下求解参数 \(\mathbf{\theta}\) ,将数据带入损失函数:
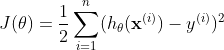
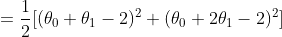
以上讨论,是希望能直观化的阐明一点,当带入所有的数据样本后,损失函数变成了一个只和参数 \(\theta\) 相关的函数。而对于这个二元函数求极值,我相信大家都不会陌生。可以令各个变量的偏导同时为 0 来求解可能的极值点,然后在这些极值点中,寻找最小的点,即为损失函数最小值点,此时对应的 \(\theta_0,\theta_1\) 就是我们要求解的参数。带回假设函数后,该函数就是我们对 true function 的一个近似。而预测过程就很简单了,只要将新的输入变量 \(x\) 带入 \(h_\theta\) 即可得到响应变量 \(y\)。
梯度下降算法
阐述完背景,接下来讨论梯度下降算法。你应该注意到了,之前对参数 \(\theta_0,\theta_1\) 的求解,我们是通过手动计算的方式计算出来的。事实上这个过程应当由计算机来完成,这很自然。那么一种显而易见的方法是对手算过程用计算机模拟,即求同时使得损失函数各个偏导都为 0 的点,然后去确定所有的极小值、极大值点,然后得到最小值点。但是呢,这个计算过程,对于人去手算可能并不困难,但是对于计算机求解却并不容易,因为这涉及到公式的推导,有时情况会很复杂,并且当损失函数形式变得复杂时,这也是不现实的。所以,一种非常简单而又直觉化的方法被提出——梯度下降算法。
梯度下降算法的直观解释是,在当前损失函数的某个点上,如果想要到达该函数的最低点,那么应该向下降速度最快的那个方向走一步,而这个方向,就是梯度的方向。步长采用对该方向分量的偏导值,也就是梯度的值。梯度下降算法的参数 \(\theta\) 更新公式为:
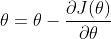
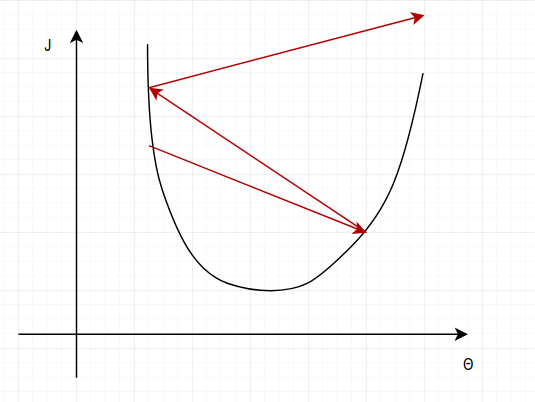
这里给出该公式的一个直观解释,以及它为什么可行。参考下图:
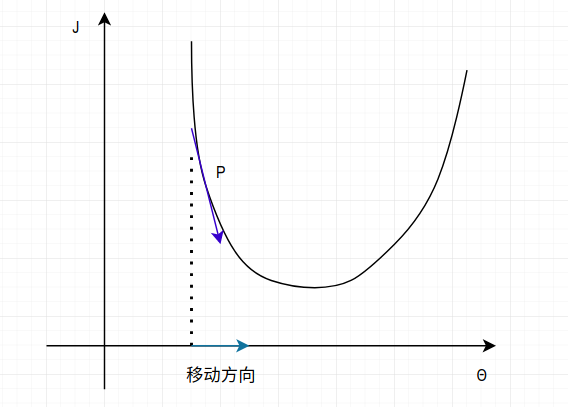
现在只考虑某个分量\(\theta_i\) 与函数 \(J\) 的关系。当初始化一个 \(\theta_i\) 为某个值,它将位于损失函数的某个点 P 上,然后在该点计算一个偏导:\(\frac{\partial J(\theta))}{\partial \theta_i}\) ,对应上图中的深蓝色箭头,此时该偏导为负,所以按照 \(\theta\) 的更新公式:\(\theta_j = \theta_j - \frac{\partial J(\theta))}{\partial \theta_j}\) 可知 $\theta $ 将向坐标轴右方向移动,即更靠近函数的最低点。
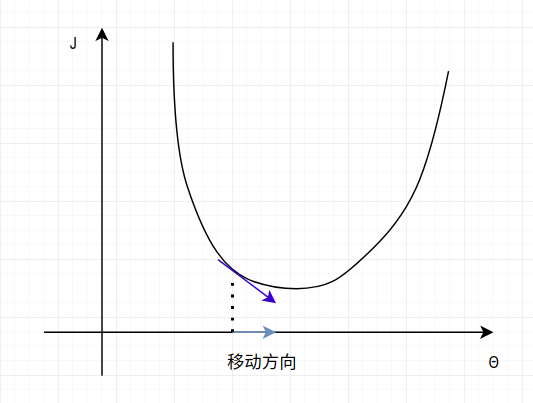
当进行了数次的迭代更新后,\(\theta\) 将不断向损失函数的最低点靠近,而该点,正是 \(\frac{\partial J(\theta))}{\partial \theta_j} = 0\) 的点。此时 \(\theta\) 将会收敛。你会发现,这与我们手算偏导为 0 的点是相同的!而这个过程会在每个 \(\theta\) 的分量 \(\theta_j\) 上进行(相当于我们手算对所有的变元求偏导为 0)。结果如下图:

此时便完成了对 \(\theta\) 的一个分量 \(\theta_j\) 的参数搜索。当偏导为正时,情况类似。
和我们去手算损失函数的最小值不同,梯度下降算法去搜索最小点很容易陷入到局部的极小值中,最后收敛在这一点反而不能找到全局的最小值。解决这一问题的方法有很多,最常见的就是通过初始化不同的起点,以避免陷入局部极小值。另一种方法是通过合理调整学习率,通过使算法每步的步长大一些,从而跳过一些局部的“凹陷”极小值处(但是过大的学习率也会带来问题,稍后我将展示这一点)。其实大多数,我们的目标函数都是单一凹凸性的,所以梯度下降算法一般可以工作的很好。
随机梯度下降和批梯度下降
为了得到梯度下降的具体公式,便于用计算机迭代求解,我们需要先做一些推导。我们已知损失函数:$$J(\theta) = \frac{1}{2} \sum_{i=1}^{n} (h_\theta(\mathbf x^{(i)}) - y{(i)})2$$ ,假设只有一个样本时(对于所有样本的情况,公式几乎相同,只差一个求和符号),对某个 \(\theta\) 分量 \(\theta_j\) 求偏导:
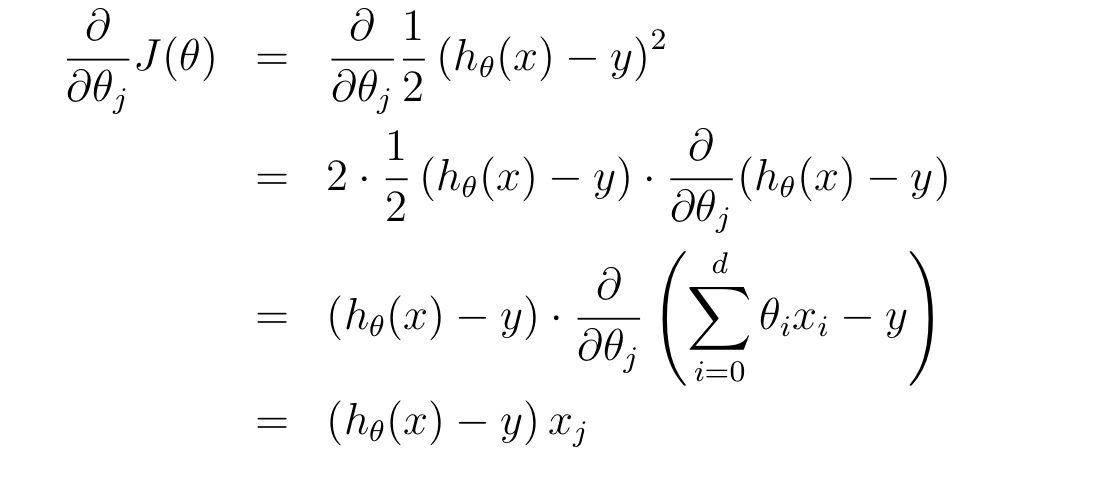
所以 $\theta_j $ 的更新公式为(全部样本集下):
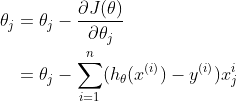
我们能发现,这个更新公式的形式很容易用计算机进行模拟。
对于梯度下降算法的实现有很多变种,最常见的两种策略就是随机梯度下降和批梯度下降。
批梯度下降的伪代码为:
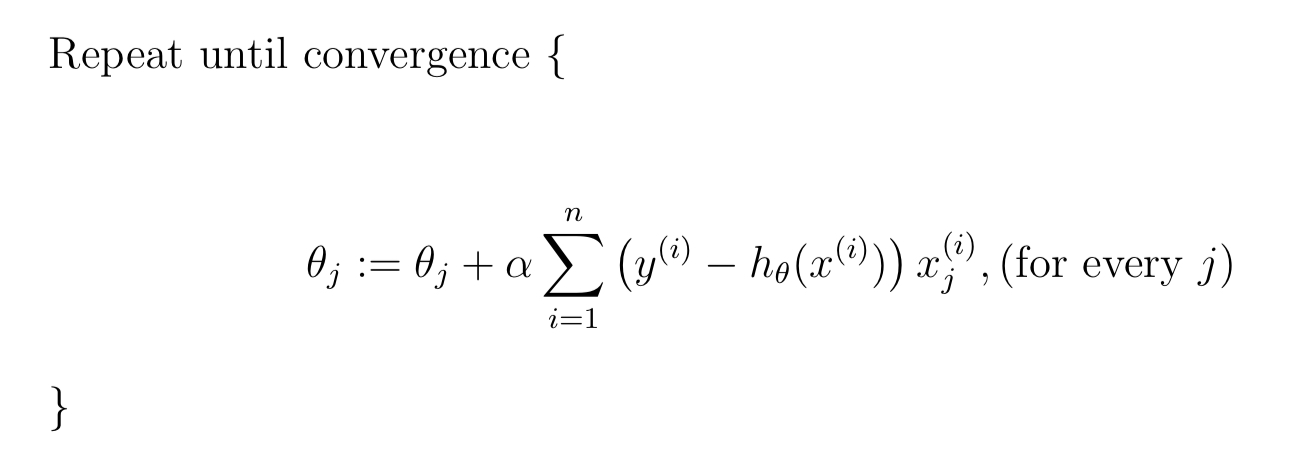
随机梯度下降的伪代码为:
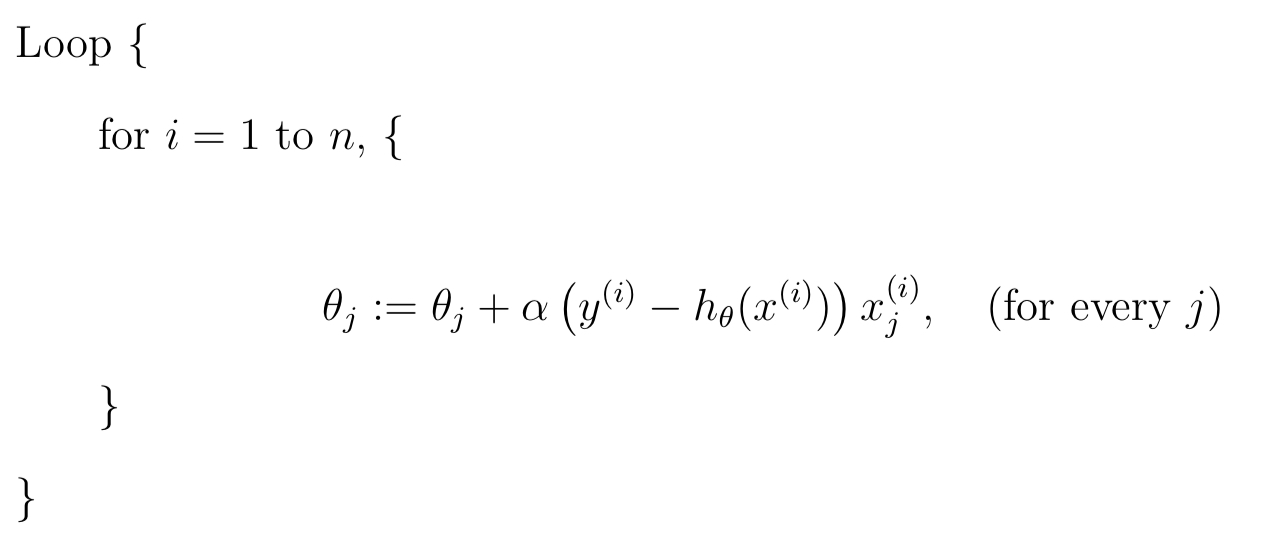
其中 \(\alpha\) 为学习率,控制每次移动的步长。
批梯度下降的优点是精确,损失函数的每个分量每次更新都会遍历所有的样本,计算偏导并进行一次更新,缺点是这样每次计算量很大。随机梯度下降每次使用一个样本进行参数的更新,优点是速度快且有随机性,缺点是每次只利用了一个样本。
对于二者之间折中的方法是随机小批量梯度下降算法。
随机小批量梯度下降算法的实现
问题背景
首先,假设问题的背景为预测橘子的售价。
我们假设橘子的售价和橘子的进价、质量和新鲜程度成线性关系,并且存在一个 true function \(f\) 在根据这些 attribute 生成橘子的售价,于是假设 true function为:
\(f = 1.25 * buyinprice + 0.42 * quality + 0.33 * fresh\) 。
但是现实是我们无法对一个现象进行精准的建模,所以为了更好的近似现实情况,我们给 true function 添加一个噪声项,来表示无法被模型捕获的因素,并用这个函数来生成我们的样本数据。所以该函数为:\(f = 1.25 * buyinprice + 0.42 * quality + 0.33 * fresh + noise\) 。
buyinprice = np.random.uniform(2,9,100)
quality = np.random.normal(6,1.5,100)
fresh = np.random.uniform(1,10,100)
noise = np.random.normal(0.85,0.15,100)
y = 1.25 * buyinprice + 0.42 * quality + 0.33 * fresh + noise
生成数据如图(共100组):
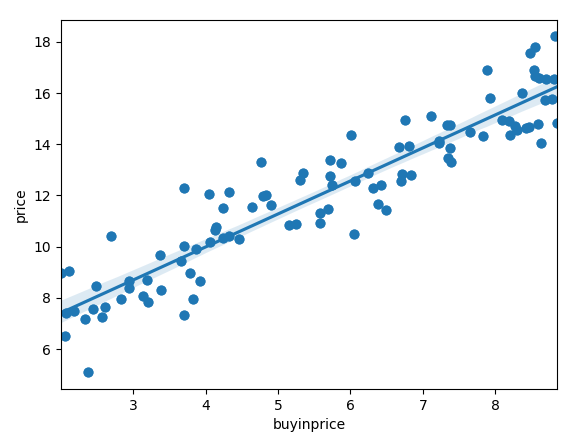
我们可以先看一下数据 buyinprice 的分布和与 price 的直观上的关系:
sns.regplot(x='buyinprice',y='price',data=data)
quality:
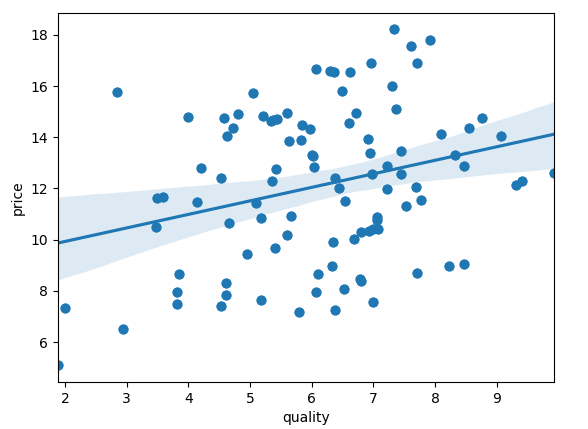
因为 quality 对 price 的影响远没有 buyinprice 大,所以数据显得比较分散。也就是 quality 与 price 的关系受到另一个维度 buyinprice 的扰动非常大。fresh 与此相似。
接下来考虑进行我们的机器学习程序的设计。
假设线性回归模型:\(h_\theta(\mathbf{x}) = \theta_1x_1 + \theta_2x_2 + \theta_3x_3\) 。
那么现在我们要从数据集中去学习参数,从而得到我们假设的模型的表达式。
现在使用随机小批量梯度下降算法来进行参数搜索。
theta = [0.1,0.1,0.1] # initialize theta
last_theta = [-100000,-100000,-100000]
alpha = 0.001 # learning rate
while measure_close(theta,last_theta):
random_pick = np.random.uniform(1,100,30) # a small batch sample
last_theta = theta[:] # reserve and copy
for j in range(3): # update every Θj
theta[j] = theta[j] - alpha * par_der(random_pick,last_theta,j)
print(theta)
可以看到 theta 的搜索过程:
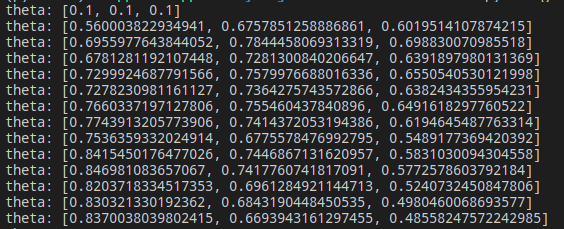
经过数轮迭代后:

最后参数收敛在 \(\theta_1 = 1.277,\theta_2 = 0.499,\theta_3 = 0.35\),而这与我们的 true function 的参数是较为接近的,可以认为随机小批量梯度下降算法取得了效果。
然后我们观察 buyinprice 和price 的 true function 图像与我们通过梯度下降算法拟合出的图像:

其中蓝色直线为 true function ,而红色直线为我们通过梯度下降算法拟合出的直线,可以看到二者十分的接近。
而在整个数据集上,考虑到 quality 和 fresh 因素,得到的模型对 price 的预测 predict_price 和实际的价格 price 之间关系:
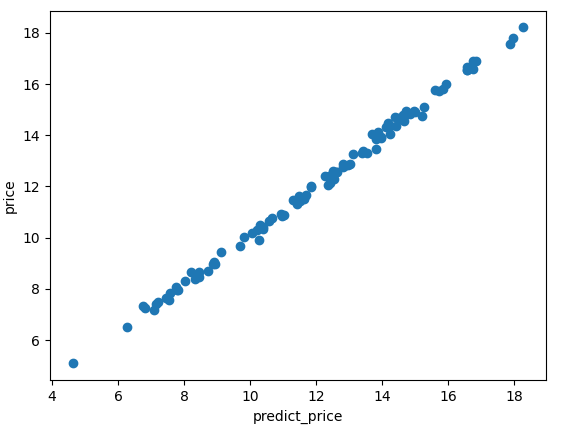
能看到,二者几乎相等。所以可以认为在训练数据集上,我们的模型表现的非常好。
超参数调整
在编写梯度下降算法进行参数搜索时,出现了一个很有意思的 bug。刚开始很多次,我的参数搜索结果都是这样的:
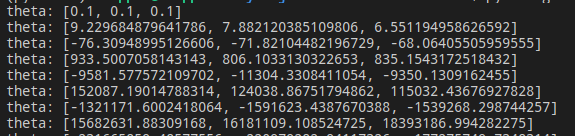
\(\theta\) 变得越来越大,而且速度非常快,很快,我得到了这个结果:

它的值已经超出了数据范围。为什么会出现这个问题?我困扰了很久。直到到想起了超参数(hyper-parameters)。
我这里有两个超参数:learning rate = 0.05,measure close = 0.1。第一个控制步长,第二个控制收敛条件。measure_close 函数的代码如下:
def measure_close(theta,last_theta):
res = 0
for i in range(3):
res += abs(theta[i] - last_theta[i])
if(res >= 0.1): # hyper parameters:0.1
return True
else: return False
我想一幅图可以很好的说明我遇到的问题:
过大的步长使得梯度下降算法跳过了最低点,并且 \(\theta\) 朝着 x 轴的两侧不断扩张,最后趋向于无穷。
而此时,通过不断的调节 learning rate,和 measure close 的值,我们也能搜索到不同的 \(\theta\) 结果,直到找到一个我们觉得满意的参数为止,这就是机器学习中的超参数调整(调参)。
下图是我将 learning rate 设置为 0.0012 时的到的参数:

合适的超参数将会得到拟合程度更好的模型。(不考虑泛化能力)
注
- 参考资料 CS229 note1
- markdown 在博客园始终这么丑 :<
作者:Skipper
出处: https://www.cnblogs.com/backwords/p/13701122.html
本博客中未标明转载的文章归作者 Skipper 和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号