MySQL之6---存储引擎及事务
MySQL之6---存储引擎及事务
介绍
存储引擎MySQL中的“文件系统”
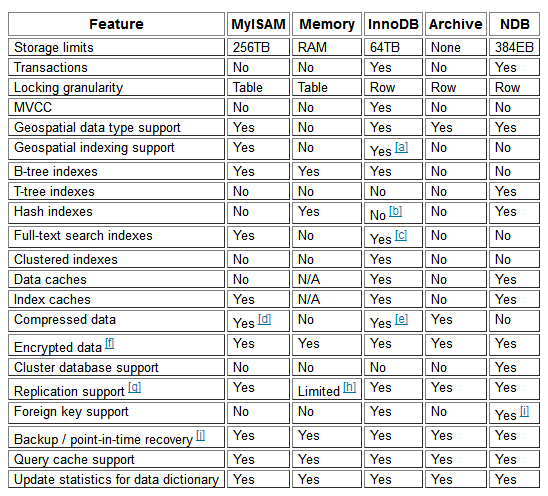
MySQL支持的存储引擎种类
FEDERATED
MEMORY
InnoDB
PERFORMANCE_SCHEMA
MyISAM
MRG_MYISAM
BLACKHOLE
CSV
ARCHIVE
彩蛋:请你列举MySQL中支持的存储引擎种类?
InnoDB、MyISAM、CSV、MEMORY
其它存储引擎
分支产品的引擎种类介绍
- PerconaDB:默认是XtraDB
- MariaDB:默认是InnoDB
- 其他引擎:TokuDB、MyRocks、Rocksdb
- 特点:压缩比15倍以上,插入数据性能快3-5倍
- 适应场景:Zabbix监控类的平台、归档库、历史数据存储业务
- Performance_Schema:Performance_Schema 数据库使用
- Memory:将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
- MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
- Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
- Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
- BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性
- Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
- CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
- BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
- example:“stub”引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
InnoDB存储引擎特性
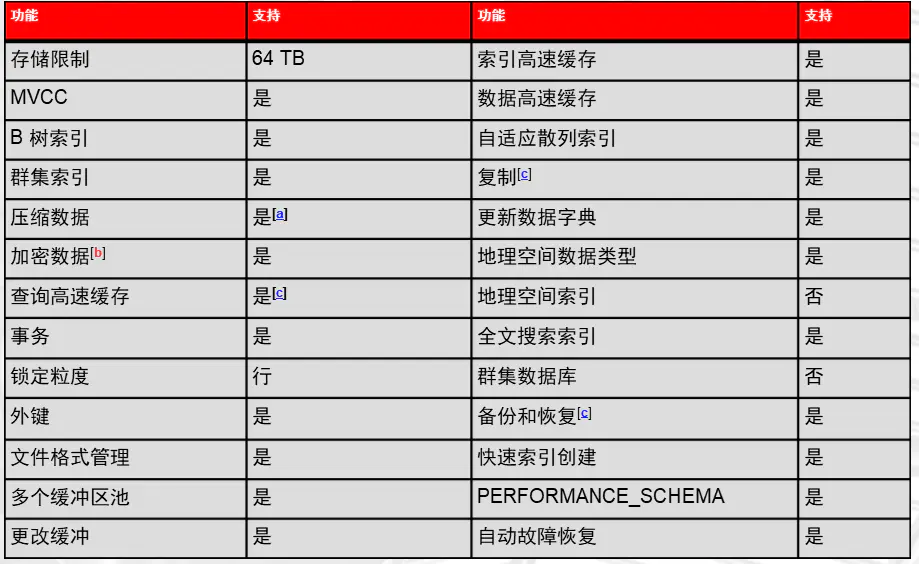
MVCC(Multi-Version Concurrency Control):多版本并发控制
聚簇索引: 用来组织存储数据和优化查询,IOT。
事务(Transaction): 数据安全保证
行级锁(Row-level Lock): 控制并发
外键
多缓冲区支持
AHI: 自适应Hash索引
复制(Replication):Group Commit,GTID(Global Transaction ID),多线程(Multi-Threads-SQL)
Hot Backup(热备份)
CR Crash Recovery: 自动故障恢复
DWB Double Write Buffer: 双写机制
My1SAM 和InnoDB
| MyISAM | InnoDB |
|---|---|
| 不支持事务 | 支持事务,适合处理大量短期事务 |
| 表级锁,当表锁定时,其他人都无法使用,影响并发性范围大 | 行级锁 |
| 读写相互阻塞,写入不能读,读时不能写 | 读写阻塞与事务隔离级别相关 |
| 只缓存索引 | 可缓存数据和索引 |
| 不支持外键约束 | 支持外键 |
| 不支持聚簇索引 | 支持聚簇索引 |
| 读取数据较快,占用资源较少 | MySQL5.5后支持全文索引 |
| 不支持MVCC(多版本并发控制机制)高并发 | 支持MVCC高并发 |
| 崩溃恢复性差 | 崩溃恢复性好 |
| MySQL5.5.5前默认的数据库引擎 | MySQL5.5.5后默认的数据库引擎 |
| 适用只读(或者写较少)、表较小(可以接受长时间进行修复操作)的场景 | 系统表空间文件:ibddata1, ibddata2, ... |
| tb_name.frm 表结构,tb_name.MYD 数据行,tb_name.MYI 索引 | 每表两个数据库文件:tb_name.frm 每表表结构,tb_name.ibd 数据行和索引 |
彩蛋:InnoDB 核心特性有哪些? InnoDB和MyISAM区别有哪些?
InnoDB支持事务、MVCC、聚簇索引、外键、缓冲区、AHI、CR、DW,MyISAM不支持。
InnoDB支持行级锁,MyISAM支持表级锁。
InnoDB支持热备(业务正常运行,影响低),MyISAM支持温备份(锁表备份)。
InnoDB支持CR(自动故障恢复),宕机自动故障恢复,数据安全和一致性可以得到保证。MyISAM不支持,宕机可能丢失当前修改。
案例1
环境:
zabbix 3.2 + centos 7.3 + mariaDB 5.5 InnoDB,zabbix监控了2000多个节点服务
故障描述:
每隔一段时间zabbix卡的要死,每隔3-4个月,都要重新搭建一遍zabbix,存储空间经常爆满。zabbix数据库500G,存在一个文件ibdata1里,手工删除1个月之前的数据,空间不释放。
优化:
- 数据库版本升级到percona 5.7+ 或者 mariadb 10.x+,zabbix升级更高版本
- 存储引擎改为tokudb
- 监控数据按月份进行切割(二次开发:zabbix 数据保留机制功能重写,数据库分表)
- 关闭binlog和双1
- 参数调整....
为什么要这样优化?:
(1)MariaDB 10.0.9原生态支持TokuDB,经过测试,5.7要比5.5 版本性能高2-3倍
(2)TokuDB:insert数据比Innodb快的多,数据压缩比比Innodb高的多
(3)监控数据按月份进行切割,为了能够truncate每个分区表,立即释放空间
(4)关闭binlog:减少无关日志的记录.
(5)参数调整:关闭安全性参数,提高性能.
扩展部署:
zabbix新版+ 新版本 tokudb VS zabbix + 低版本mariadb
TokuDB独有的其他功能包括:
- 高达25倍的数据压缩
- 快速插入
- 通过无读复制消除从机延迟
- 热架构更改
- 热索引创建 - TokuDB表支持插入、删除和查询,而索引添加到该表时没有停机时间
- 热列添加、删除、扩展和重命名 — 当 alter table 添加、删除、扩展或重命名列时,TokuDB表支持不停机插入、删除和查询
- 在线备份
参考资料:
Zabbix 3.0 for percona-server TokuDB:https://www.jianshu.com/p/898d2e4bd3a7
MariaDB TokuDB:https://mariadb.com/kb/en/installing-tokudb/
Percona TokuDB:https://www.percona.com/doc/percona-server/5.7/tokudb/tokudb_installation.html
案例2
环境:
centos 5.8,MySQL 5.0 MyISAM,网站业务(LNMP),数据量50G左右
故障描述:
业务压力大的时候,非常卡;经历过宕机,会有部分数据丢失.
问题分析:
-
监控锁的情况:有很多的表锁等待
-
存储引擎查看:所有表默认是MyISAM
MyISAM存储引擎特性:
-
表级锁,在高并发时,会有很高锁等待
-
不支持事务,在断电时,会有可能丢失数据
解决方案:
- 升级MySQL 5.6.1x版本
- 升级迁移所有表到新环境,调整存储引擎为InnoDB
- 开启双1安全参数
- 重构主从
存储引擎基本操作
查询支持的存储引擎
SHOW ENGINES;
查询默认存储引擎
select @@default_storage_engine;
设置默认存储引擎
-- 会话级别(仅影响当前会话)
set default_storage_engine=myisam;
-- 全局级别(仅影响新会话)重启失效
set global default_storage_engine=myisam;
-- 写入配置文件,重启永久生效
vim /etc/my.cnf
[mysqld]
default_storage_engine=InnoDB
存储引擎是作用在表上的,也就意味着,不同的表可以有不同的存储引擎类型。
查看库中所有表使用的存储引擎
SHOW TABLE STATUS from db_name;
查询指定表的存储引擎
SHOW create table 表名;
SHOW TABLE STATUS LIKE '%表名%';
查询系统中所有业务表的存储引擎信息
select table_schema, table_name, engine
from information_schema.tables
where table_schema not in ('sys','mysql','information_schema','performance_schema');
创建表时设定存储引擎
CREATE TABLE 表名 (id int) ENGINE=INNODB;
修改已有表的存储引擎
ALTER TABLE 库名.表名 ENGINE=MyISAM;
案例3
将所有的非InnoDB引擎的表查询出来,批量修改为InnoDB
- 查询:
SELECT table_schema, table_name, ENGINE
FROM information_schema.tables
WHERE table_schema NOT IN ('sys','mysql','information_schema','performance_schema')
AND ENGINE !='innodb';
- 开启导出文件功能
vim /etc/my.cnf
[mysqld]
secure-file-priv=/tmp
- 构建批量修改语句:
SELECT CONCAT("alter table ",table_schema,".",table_name," engine=innodb;")
FROM information_schema.tables
WHERE table_schema NOT IN ('sys','mysql','information_schema','performance_schema')
AND ENGINE !='innodb' INTO OUTFILE '/tmp/a.sql';
- 执行批量修改语句:
source /tmp/a.sql
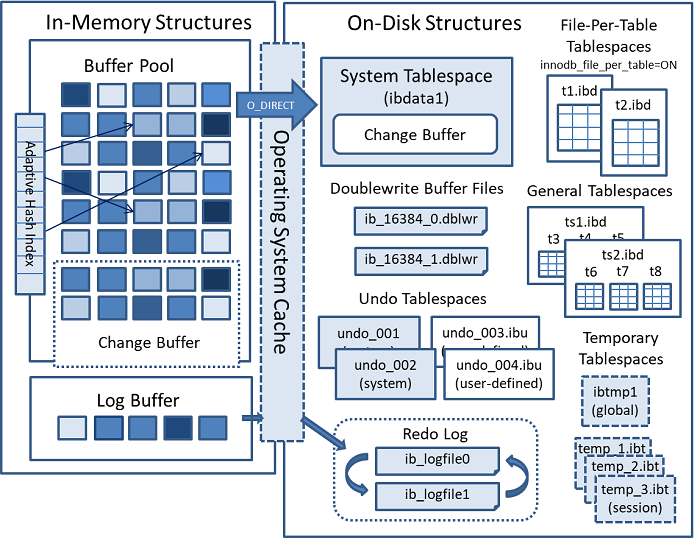
InnoDB磁盘结构(on-disk)
磁盘文件(/data/mysql/data)
ibdata1:系统数据字典信息(统计信息),UNDO表空间等数据
ib_logfile0 ~ ib_logfile1: REDO日志文件,事务日志文件
ibtmp1: 临时表空间磁盘位置,存储临时表
frm:存储表的列信息
ibd:表的数据行和索引
| myisam | InnoDB 8.0之前 |
|---|---|
| .frm 数据字典 | .frm 单表数据字典 |
| .myd 数据行 | .ibd 数据行和索引 |
| .myi 索引 | ibdata 共享表空间 |
MySQL 8.0中删除.frm文件,其中数据存储在MySQL 8.0中引入的MySQL数据字典表中。
MySQL数据字典的元数据实际上位于MySQL数据库目录中的
InnoDB每表文件表空间文件中。对于InnoDB数据字典,元数据实际上位于InnoDB系统表空间中。从MySQL 8.0.3开始,
InnoDB除临时表空间和撤消表空间文件外,所有表空间文件中都存在SDI 。表空间文件中SDI的存在提供了元数据冗余。例如,如果数据字典不可用,则可以使用ibd2sdi从表空间文件中提取字典对象元数据。
表空间结构
表空间的概念源于Oracle数据库。最初的目的是为了能够很好的做存储的扩容。
到8.0.22版本为止,已经出现了很多表空间,具体介绍请查看官方文档:
- 系统表空间(The System Tablespace)
- 每表文件表空间(File-Per-Table Tablespaces)
- 通用表空间(General Tablespaces)
- 撤消表空间(Undo Tablespaces)
- 临时表空间(Temporary Tablespaces)
共享(系统)表空间
存储方式 ibdata1~ibdataN, 5.5版本默认。
共享表空间在各个版本存储内容的变化
5.5版本:出现共享表空间
系统相关:(全局)数据字典信息(表基本结构信息、状态、系统参数、属性..)、UNDO回滚日志(记录撤销操作)、Double Write Buffer信息、临时表信息、change buffer
用户数据: 表数据行、表的索引数据
5.6版本:共享表空间只存储于系统数据,把用户数据独立出去,由独立表空间管理。
系统相关:(全局)数据字典信息、UNDO回滚信息、Double Write Buffer信息、临时表信息、change buffer
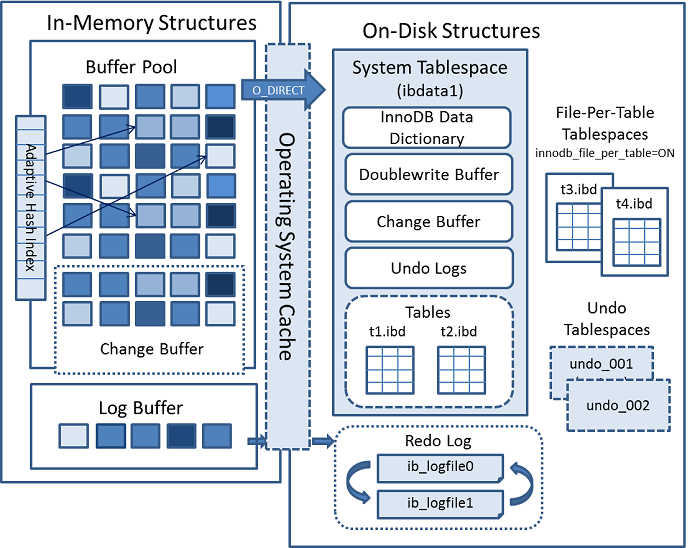
5.7版本:把临时表独立出去,UNDO回滚信息可以设定为独立出去
系统相关:(全局)数据字典信息、UNDO回滚信息、Double Write Buffer信息、change buffer
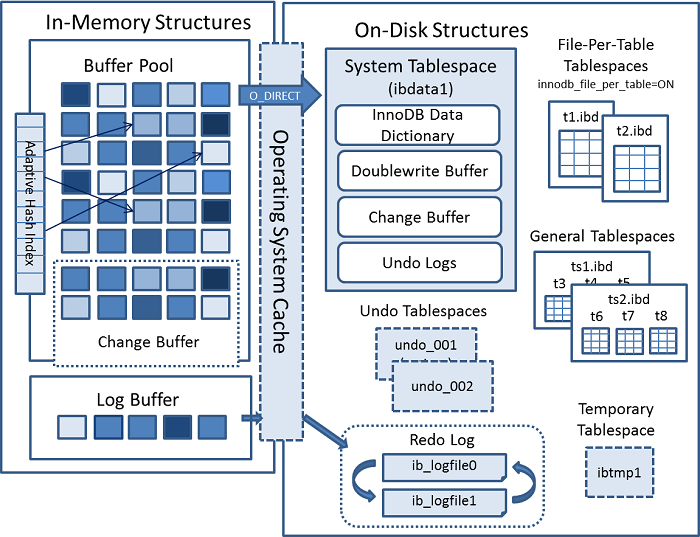
8.0.11~8.0.19版本:UNDO回滚信息默认独立出去,数据字典信息不再集中存储在一个文件。
系统相关:Double Write Buffer信息、change buffer
8.0.20版本: 把Double Write Buffer信息独立出去
系统相关:change buffer
共享表空间查看
mysql> select @@innodb_data_file_path;
+-------------------------+
| @@innodb_data_file_path |
+-------------------------+
| ibdata1:12M:autoextend |
+-------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_autoextend_increment;
+-------------------------------+
| @@innodb_autoextend_increment |
+-------------------------------+
| 64 |
+-------------------------------+
1 row in set (0.00 sec)
含义:ibdata1文件,默认初始大小12M,不够用会自动扩展,默认每次扩展64M
共享表空间扩容
① 初始化后设置共享表空间,重启生效。
vim /etc/my.cnf
[mysqld]
innodb_data_file_path=ibdata1:12M;ibdata2:64M;ibdata3:64M:autoextend
注意:ibdata1必须和当前文件时间大小一致
错误处理:
ibdata1设置值和当前文件实际大小不一致,重启数据库报错,查看日志文件
tail -10 /data/3306/data/db01.err | grep ERROR
... ...
[ERROR] InnoDB: The innodb_system data file './ibdata1' is of a different size 4864 pages (rounded down to MB) than the 768 pages specified in the .cnf file!
... ...
实际大小:4864*16K/1024=76M
my.cnf文件设置大小:768*16K/1024=12M
查看ibdata1实际大小
[root@db01 ~]# ls -lh /data/3306/data/ibdata1
-rw-r----- 1 mysql mysql 76M May 6 17:11 ibdata1
② 初始化前设置共享表空间(生产建议)
5.7 中建议:设置共享表空间2-3个,大小建议1G或者4G,最后一个定制为自动扩展。
8.0 中建议:设置1-2个就ok,大小建议1G或者4G,最后一个定制为自动扩展。
独立(每表文件)表空间
从5.6开始,出现了独立表空间,包含单个InnoDB表的数据和索引 ,并存储在文件系统中自己的数据文件中,一个表一个ibd文件单独管理,8.0版本删除了frm文件。
独立表空间控制
-- 查看控制参数
select @@innodb_file_per_table;
-- 独立表空间存储用户数据,创建表生成ibd文件
set global innodb_file_per_table=1;
-- 共享表空间存储用户数据,创建表不生成ibd文件
set global innodb_file_per_table=0;
独立表空间同版本快速迁移数据
源端:/data/3306/data/t100w -----> 目标端:/data/3307/data/t100w
-- 获取写锁
mysql> lock tables test.t100w write;
-- 或者刷新并获取表的读锁
mysql> flush tables test.t100w with read lock;
- 源端查看t100w表创表语句
mysql> show CREATE TABLE test.t100w;
CREATE TABLE `t100w` (
`id` int(11) DEFAULT NULL,
`num` int(11) DEFAULT NULL,
`k1` char(2) DEFAULT NULL,
`k2` char(4) DEFAULT NULL,
`dt` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 目标端创建test库和t100w空表
mysql> CREATE database test charset=utf8mb4;
mysql> CREATE TABLE `t100w` (
`id` int(11) DEFAULT NULL,
`num` int(11) DEFAULT NULL,
`k1` char(2) DEFAULT NULL,
`k2` char(4) DEFAULT NULL,
`dt` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 目标端删除空的表空间文件
mysql> alter table test.t100w discard tablespace;
- 拷贝源端ibd文件到目标端目录,并设置权限
[root@db01 ~]# cp /data/3306/data/test/t100w.ibd /data/3307/data/test/
[root@db01 ~]# chown -R mysql.mysql /data/*
- 目标端导入表空间
mysql> alter table test.t100w import tablespace;
- 目标端验证结果
mysql> select count(*) from test.t100w;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
- 源端解锁数据表
mysql> unlock tables;
案例4
环境:
联想服务器(IBM),磁盘500G,没有raid,centos 6.8,mysql 5.6.33 innodb,没有备份,没开二进制日志,没有主从,LNMT架构。开发用户专用库:jira(bug追踪) 、 confluence(内部知识库)
故障描述:
突然断电,启动后发现文件系统/只读,fsck 修复文件系统并重启,系统成功启动,mysql启动不了。结果:confulence库在,jira库不见了
需求:
暂时把confulence库先打开用着,直接访问时访问不了的,需要将生产库confulence,拷贝到1:1虚拟机上的/var/lib/mysql
解决方案:独立表空间迁移
create table confulence.t1;
alter table confulence.t1 discard tablespace;
alter table confulence.t1 import tablespace;
处理流程:
/*1、confulence库中一共有107张表,创建107张和原来一模一样的空表。
他有2016年的历史库,我让他去他同时电脑上mysqldump备份confulence库*/
# mysqldump -uroot -ppassword -B confulence --no-data >test.sql
-- 拿到你的测试库,进行恢复,到这步为止,表结构有了。
-- 2、删除表空间。
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discard.sql
-- 3、拷贝生产中confulence库下的所有表的ibd文件到准备好的环境中,导入表空间
select concat('alter table ',table_schema,'.'table_name,' import tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discad.sql
-- 4、验证数据
-- 表都可以访问了,数据挽回到了出现问题时刻的状态
获取表结构
8.0之前
可以使用MySQL Utilities提供的mysqlfrm用来读取.frm文件,并从该文件中找到表定义数据,生成CREATE语句。
cd /opt
wget https://downloads.mysql.com/archives/get/p/30/file/mysql-utilities-1.6.5.tar.gz
tar -xvzf mysql-utilities-1.6.5.tar.gz
python /opt/mysql-utilities-1.6.5/setup.py build
python /opt/mysql-utilities-1.6.5/setup.py install
# 获取独立表空间的表结构
mysqlfrm --diagnostic 表名.frm | grep -v "^#" > /tmp/db_table.sql
注意:.frm文件中没有外键约束和自增长序列的信息
删除表空间前可以设置跳过外键检查来规避问题
set foreign_key_checks=0
8.0之后
可以使用ibd2sdi离线的将ibd文件中的冗余存储的SDI信息提取出来,并以json的格式输出到终端。
- 把 表名.ibd 中的表结构以json的格式输出到 dbsdi.json文件
ibd2sdi --dump-file=dbsdi.json 表名.ibd
注意:当存在中文注释时,解析出来的注释可能是乱码的,而且大概率会触发ibd2sdi的bug(中文乱码导致json格式错误,比如缺少引号)。
此时可以使用vscode打开dbsdi.json,vscode会高亮json文件格式正确的部分,手动修复不正确的格式,保存。
-
使用jq提取json里的数据
-
CentOS 使用yum安装
通用命令
ibd2sdi 表名.ibd |jq '.[]?|.[]?|.dd_object?|({table:.name?},(.columns?|.[]?|{name:.name,type:.column_type_utf8}))' > dbsdi-jq.json -
Windows 下载可执行文件安装
Powershell调用jq解析json文件
Get-Content -Path dbsdi.json |jq '.[]?|.[]?|.dd_object?|({table:.name?},(.columns?|.[]?|{name:.name,type:.column_type_utf8}))' > dbsdi-jq.json
-
撤销表空间
存储撤消日志,用来回滚事务。
撤销表空间查看配置参数
-- 打开独立undo模式,并设置undo的个数,建议3-5个,8.0弃用
SELECT @@innodb_undo_tablespaces;
-- undo日志的大小,默认1G
SELECT @@innodb_max_undo_log_size;
-- 开启undo自动回收的机制(undo_purge)
SELECT @@innodb_undo_log_truncate;
-- 触发自动回收的条件,单位是检测次数
SELECT @@innodb_purge_rseg_truncate_frequency;
-- undo文件存储路径
SELECT @@innodb_undo_directory;
撤销表空间配置
默认存储在共享表空间中(ibdataN),生产中必须手工独立出来,否则影响高并发效率。
只能在初始化时配置undo个数,并且是固定的。
# 1.创建目录
[root@db01 ~]# mkdir /data/3357/{data,etc,socket,log,pid,undologs} -pv
[root@db01 ~]# chown -R mysql. /data/*
# 2.添加参数
[root@db01 ~]# vim /data/3357/my.cnf
[mysqld]
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=ON
innodb_purge_rseg_truncate_frequency=32
innodb_undo_directory=/data/3357/undologs
# 3.初始化数据库
[root@db01 ~]# /usr/local/mysql57/bin/mysqld --defaults-file=/data/3357/my.cnf --initialize-insecure --user=mysql --basedir=/usr/local/mysql57 --datadir=/data/3357/data
# 4.启动数据库
[root@db01 ~]# /etc/init.d/mysqld start
# 5.查看结果
[root@db01 ~]# ll /data/3357/undologs/
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo001
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo002
-rw-r----- 1 mysql mysql 10485760 May 11 15:39 /data/3357/undologs/undo003
默认就是独立的(undo_001-undo_002),可以随时配置,innodb_undo_tablespaces选项已过时。
-- 查询所以表空间文件
SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES;
-- 查询undo表空间
SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE LIKE 'UNDO LOG';
-- 添加undo表空间
CREATE UNDO TABLESPACE tablespace_name ADD DATAFILE 'file_name.ibu';
-- 删除undo表空间
-- 必须为空,先标记为非活动状态,再删除
ALTER UNDO TABLESPACE tablespace_name SET INACTIVE;
DROP UNDO TABLESPACE tablespace_name;
-- 监视undo表空间的状态
SELECT NAME, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME LIKE 'tablespace_name';
临时表空间
临时表空间(ibtmp1)用于存储临时表。建议数据初始化之前设定好,一般2-3个,大小512M-1G。
临时表空间查看配置参数
mysql> select @@innodb_temp_data_file_path;
+------------------------------+
| @@innodb_temp_data_file_path |
+------------------------------+
| ibtmp1:12M:autoextend |
+------------------------------+
配置文件设置,重启生效
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
innodb_temp_data_file_path=ibtmp1:12M;ibtmp2:128M:autoextend:max:500M
分为会话临时表空间和全局临时表空间
-
会话临时表空间(
temp_N.ibt)用于存储临时表。位置参数
mysql> select @@innodb_temp_tablespaces_dir; +-------------------------------+ | @@innodb_temp_tablespaces_dir | +-------------------------------+ | ./#innodb_temp/ | +-------------------------------+ -
全局临时表空间(
ibtmp1)用于存储对用户创建的临时表进行更改的回滚段。配置同5.7版本的临时表空间
重做日志(Redo Log)
Redo Log 记录内存数据页的变化(数据页的变化信息+数据页当时的LSN号)。实现“前滚”的功能。
存储在数据路径下(ib_logfile0,ib_logfile1,...),轮序覆盖记录日志。
刷新策略:commit提交后,刷新当前事务的 redo buffer 到磁盘,还会顺便将一部分 redo buffer 中没有提交的事务日志也刷新到磁盘。
WAL(write ahead log):保证 Redo Log 优先于数据写入磁盘。
查询配置参数
mysql> show variables like '%innodb_log_file%';
+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
+---------------------------+----------+
设置
生产建议: 设置3-5组,512M-4G
配置文件添加参数,重启生效
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
innodb_log_file_size=100M
innodb_log_files_in_group=3
回滚日志(undo log)
Undo Log 是撤消日志的集合,提供快照技术,保存事务修改之前的数据状态,保证了MVCC,隔离性,mysqldump的热备。
- 在rolback时,将数据恢复到修改之前的状态。
- 在实现CSR时,回滚到redo当中记录的未提交的时候。
5.7版本,存储在共享表空间中 (ibdata1~ibdataN)
8.0版本
对常规表执行操作的事务的撤消日志存储在撤消表空间中(undo_001-undo_002)。
对临时表执行操作的事务的撤消日志存储在全局临时表空间中(ibtmp1)。
每个撤消表空间和全局临时表空间分别支持最多128个回滚段。
配置回滚段的数量
select @@innodb_rollback_segments;
双写缓冲区 Double Write Buffer(DWB)
双写缓冲区是一个存储区域,InnoDB先将从页面缓冲池中刷新的页面写入双写缓冲区,然后再将页面写入InnoDB数据文件中。
如果在页面写入过程中,发生操作系统,存储子系统或mysqld进程的意外退出,则InnoDB可以在崩溃恢复期间从doublewrite缓冲区中找到页面的良好副本。
8.0.19前默认位于ibdataN中,8.0.20后就独立出来位于#*.dblwr。
预热文件(ib_buffer_pool)
用来缓冲和缓存“热”(经常查询或修改)数据页,减少物理IO。MySQL 5.7默认启用。
当关闭数据库的时候,缓冲和缓存会失效。5.7版本后,MySQL正常关闭时,会将内存的热数据存放(流方式)至ib_buffer_pool。下次重启直接读取ib_buffer_pool加载到内存中。
查询配置参数
指定在关闭MySQL服务器时是否记录InnoDB 缓冲池中缓存的页面 ,以缩短下次重启时的预热过程。innodb_buffer_pool_dump_pct 选项定义要转储的最近使用的缓冲池页面的百分比。
select @@innodb_buffer_pool_dump_at_shutdown;
select @@innodb_buffer_pool_load_at_startup;
InnoDB内存结构
缓冲池 InnoDB BUFFER POOL(IBP)
缓冲池主要用来缓冲、缓存MySQL的数据页和索引页,还有AHI、Change buffer。MySQL中最大的、最重要的内存区域。
-- 查看缓存池大小,默认128M
mysql> select @@innodb_buffer_pool_size;
+---------------------------+
| @@innodb_buffer_pool_size |
+---------------------------+
| 134217728 |
+---------------------------+
生产建议:物理内存的:50-80%
全局设置: 重新连接mysql生效。
set global innodb_buffer_pool_size=268435456;
永久设置:配置文件添加参数,重启mysql生效
vim /etc/my.cnf
[mysqld]
innodb_buffer_pool_size=256M
-- 查询缓冲池实例数量,默认1,最大为64
mysql> select @@innodb_buffer_pool_instances;
+--------------------------------+
| @@innodb_buffer_pool_instances |
+--------------------------------+
| 1 |
+--------------------------------+
注意:仅当您将innodb_buffer_pool_size大小设置为1GB或更大时,此选项才生效,是所有缓冲池实例大小之和。
为了获得最佳效率,请组合 innodb_buffer_pool_instances 和innodb_buffer_pool_size使得每个缓冲池实例是至少为1GB。
日志缓冲区 InnoDB LOG BUFFER (ILB)
用于保存要写入磁盘上的日志文件(Redo Log)的数据。
查询配置参数
select @@innodb_log_buffer_size;
默认大小:16M
生产建议:innodb_log_file_size的1-N倍
永久设置:配置文件添加参数,重启mysql生效
vim /etc/my.cnf
[mysqld]
innodb_log_buffer_size=33554432
事务(Transactions)
事务:一组原子性的SQL语句,或一个独立工作单元,由一系列动作组合起来的一个完整的整体。
事务日志:记录事务信息,实现undo,redo等故障恢复功能
redo:当我们正在想数据库中存放数据,或写入数据时,此时出现断电情况,数据只执行了一半,电源连上之后发现此时的两个数据都只做了一半,就会执行redo功能,重新执行。
undo:当我们正在想数据库中存放数据,或写入数据时,此时出现断电情况,前两个数据已经执行完毕,但是第三个数据未传完,电源连上之后发现此时还有后续的完整数据未执行,就会执行undo功能,就会取消执行。
事务的ACID特性
- Atomic(原子性)
整个事务中的所有操作要么全部成功执行,要么全部失败后回滚。不能出现中间状态。
- Consistent(一致性)
如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态,总是从一个一致性状态转换为另一个一致性状态。
- Isolated(隔离性)
事务之间不相互影响。
- Durable(持久性)
事务成功完成后,所做的所有更改都会永久地记录在数据库中。
事务的生命周期(控制语句)
标准事务控制语句
启动事务
BEGIN;
START TRANSACTION;
结束事务
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
注意:事务生命周期中,只能使用DML语句(select、update、delete、insert)
自动提交(autocommit)
-- 查询自动提交设置状态,默认开启值为1
select @@autocommit;
-- 临时会话设置
set autocommit=0;
-- 临时全局设置
set global autocommit=0;
-- 永久设置
vim /etc/my.cnf
autocommit=0
如果开启自动提交,则对表的所有更改将立即生效。每个SQL语句形成一个事务,如果该SQL语句未返回错误,则MySQL在每个SQL语句之后进行提交。如果一条语句返回错误,则提交或回滚行为取决于该错误。
要使用多语句事务,请关闭自动提交功能。要保留自动提交功能,请显式使用事务控制语句。
- DDL语句: ALTER、CREATE 和 DROP、TRUNCATE TABLE、...
- DCL语句: GRANT、REVOKE 和 SET PASSWORD、...
- 事务控制和锁定语句:BEGIN、LOCK TABLES 和 UNLOCK TABLES、...
- 数据加载语句:LOAD DATA、...
- 行政声明:FLUSH、LOAD INDEX INTO CACHE 和 OPTIMIZE TABLE、...
- 复制控制语句:START REPLICA | SLAVE, STOP REPLICA | SLAVE, RESET REPLICA | SLAVE, CHANGE MASTER TO.
- 磁盘空间不足,回滚失败的语句
- 重复键错误,回滚失败的语句
- row too long error,回滚失败的语句
- 出现事务冲突(死锁),回滚整个事务
- 会话窗口被关闭
- 数据库关闭
建议:生产中显式请求和提交事务,不要使用“自动提交”功能,可以很大程度上提高数据库性能
事务使用流程
-- 检查autocommit是否为关闭状态
select @@autocommit;
-- 开始事务
begin;
-- DML语句
delete from student where name='alexsb';
-- 建立保存点sp1
savepoint sp1
-- DML语句
update student set name='alexsb' where name='alex';
-- 回滚到保存点sp1
ROLLBACK To sp1
-- 回滚结束
ROLLBACK;
-- 或者
-- 提交结束
commit;
事务的隔离级别
事务隔离实现事务工作期间的“读”的隔离,处理MVCC,读一致性问题
隔离级别类型
- RU:
READ-UNCOMMITTED读未提交,可以读取到事务未提交的数据。- 优点:事务的并发度最高
- 缺点:隔离性差,会出现脏读(当前内存读),不可重复读,幻读问题
- RC:
READ-COMMITTED读已提交(常用),可以读取到事务已提交的数据。- 优点:事务的并发度较好,防止脏读
- 缺点:隔离性一般,会出现不可重复读,幻读问题
- RR:
REPEATABLE-READ可重复读(默认)- 优点:事务的并发度一般,防止脏读,防止不可重复读
- 缺点:隔离性较好,会出现幻读问题
- SR:
SERIALIZABLE可串行化- 优点:隔离性最好,可以防止死锁,主要用于InnoDB存储引擎的分布式事务。
- 缺点:事务没有并发
RC 可以减轻GAP+NextLock锁的问题,一般在为了读一致性会在正常select后添加for update语句,记住执行完一定要commit,否则容易出现严重锁等待。 RR 利用的是undo的快照技术+GAP(间隙锁)+NextLock(下键锁)实现隔离机制的方法主要有两种:
- 加读写锁
- 一致性快照读,即
MVCC本质上,隔离级别是一种在并发性能和并发产生的副作用间的妥协,通常数据库均倾向于采用
Weak Isolation。
隔离级别参数
select @@transaction_isolation;
set global transaction_isolation='READ-UNCOMMITTED';
set global transaction_isolation='READ-COMMITTED';
set global transaction_isolation='REPEATABLE-READ';
set global transaction_isolation='SERIALIZABLE';
vim /etc/my.cnf
[mysqld]
transaction_isolation='READ-COMMITTED';
问题现象演示
-- 创建测试库
create database test;
-- 创建测试表
create table test.t1 (
id int not null primary key auto_increment ,
a int not null ,
b varchar(20) not null,
c varchar(20) not null
)charset=utf8mb4 engine=innodb;
begin;
insert into test.t1(a,b,c)
values
(1,'a','aa'),
(2,'c','ab'),
(3,'d','ae'),
(4,'e','ag'),
(5,'f','at');
commit;
-- 关闭自动提交
set global autocommit=0;
-- 打开两个会话窗口:
-- sessionA:
-- sessionB:
脏读
脏读又称无效数据的读出,当前内存读,可以读取到别人未提交的数据。
例如:事务T1修改某一值,未提交,但是事务T2却能读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。注意,脏读一般是针对于update操作。
-- RU级别下不可重读现象演示:
-- 第一步:设置隔离级别,重新连接数据库
mysql> set global transaction_isolation='READ-UNCOMMITTED';
mysql> exit
-- 第二步:检查隔离级别
-- sessionA:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-UNCOMMITTED |
+-------------------------+
-- sessionB:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-UNCOMMITTED |
+-------------------------+
-- 第三步:开启事务
-- sessionA:
mysql> begin;
-- sessionB:
mysql> begin;
-- 第四步:查看当前表数据
-- sessionA:
mysql> select * from test.t1 where id=2;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 2 | 2 | c | ab |
+----+---+---+----+
-- sessionB:
mysql> select * from test.t1 where id=2;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 2 | 2 | c | ab |
+----+---+---+----+
-- 第五步:
-- sessionA: 执行DML语句
mysql> update test.t1 set a=8 where id=2;
-- 第六步:
-- sessionB:查看当前表数据发现数据变化,脏读
mysql> select * from test.t1 where id=2;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 2 | 8 | c | ab |
+----+---+---+----+
-- 第七步:
-- sessionA: 回滚
mysql> rollback;
-- 第八步:
-- sessionB:查看当前表数据发现数据变化,不可重复读
mysql> select * from test.t1 where id=2;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 2 | 2 | c | ab |
+----+---+---+----+
不可重复读
不可重复读,指一个事务范围内两个相同的查询却返回了不同数据。
这是由于查询时系统中其他事务修改的提交而引起的。比如事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
-- RC级别下不可重读现象演示:
-- 第一步:设置隔离级别,重新连接数据库
mysql> set global transaction_isolation='READ-COMMITTED';
mysql> exit
-- 第二步:检查隔离级别
-- sessionA:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
-- sessionB:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
-- 第三步:开启事务
-- sessionA:
mysql> begin;
-- sessionB:
mysql> begin;
-- 第四步:查看当前表数据
-- sessionA:
mysql> select * from test.t1 where id=1;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 1 | 1 | a | aa |
+----+---+---+----+
-- sessionB:
mysql> select * from test.t1 where id=1;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 1 | 1 | a | aa |
+----+---+---+----+
-- 第五步:
-- sessionA: 执行DML语句并提交事务
mysql> update test.t1 set a=6 where id=1;
mysql> commit;
-- 第六步:
-- sessionB:查看当前表数据发现数据变化
mysql> select * from test.t1 where id=1;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 1 | 6 | a | aa |
+----+---+---+----+
幻读
幻读 ,指同一查询在不同时间产生不同的行集。
例如:第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样。
一般解决幻读的方法是增加范围锁RangeS,锁定检索范围为只读,这样就避免了幻读。
-- RC级别下幻读现象演示:
-- 第一步:设置隔离级别,重新连接数据库
mysql> set global transaction_isolation='READ-COMMITTED';
mysql> exit
-- 第二步:检查隔离级别
-- sessionA:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
-- sessionB:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
-- 第三步:开启事务
-- sessionA:
mysql> begin;
-- sessionB:
mysql> begin;
-- 第四步:查看当前表数据
-- sessionA:
mysql> select * from test.t1;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 1 | 6 | a | aa |
| 2 | 2 | c | ab |
| 3 | 3 | d | ae |
| 4 | 4 | e | ag |
| 5 | 5 | f | at |
+----+---+---+----+
-- sessionB:
mysql> select * from test.t1;
+----+---+---+----+
| id | a | b | c |
+----+---+---+----+
| 1 | 6 | a | aa |
| 2 | 2 | c | ab |
| 3 | 3 | d | ae |
| 4 | 4 | e | ag |
| 5 | 5 | f | at |
+----+---+---+----+
-- 第五步:
-- sessionA:执行DML语句,全部数据行修改
mysql> update test.t1 set a=10 where a<10;
-- 第六步:
-- sessionB:执行DML语句,插入一行数据,提交事务
mysql> insert into test.t1(a,b,c) values (1,'z','az');
mysql> commit;
-- 第七步:
-- sessionA:提交事务
mysql> commit;
-- 第八步:
-- sessionA:查看当前表数据,好像发生了幻觉
mysql> select * from test.t1;
+----+----+---+----+
| id | a | b | c |
+----+----+---+----+
| 1 | 10 | a | aa |
| 2 | 10 | c | ab |
| 3 | 10 | d | ae |
| 4 | 10 | e | ag |
| 5 | 10 | f | at |
| 6 | 1 | z | az |
+----+----+---+----+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号