
嗨!请查收这道有趣的面试题
1. 前言
今天和大家一起看一道以前遇到的面试题,之所以印象深刻是因为大白在两家公司面试都被问到了,分别是蔚来汽车和旷视科技。
这道题目描述比较简单,大致是这样的:
使用你喜欢或者擅长的语言实现一个矩阵乘法,为了简单起见,当做两个n维的方阵相乘。
描述简单的题目往往做起来并不简单,冷静想想,这道题其实有三层考察点:
- 面试者对矩阵及其基本运算的掌握
- 面试者实现基础版本的矩阵乘法运算
- 面试者分析和优化实现高效版本
这道题应该算是白银题,而不是青铜题,一起来搞一下吧,铁定会有收获!
2.矩阵及其基本运算
说到矩阵想必各位都不陌生,大白在大一的《线性代数》和研一的《矩阵分析》两门课都曾比较深入的学过,但是目前基本上都还给老师了。
遗忘不要紧,只要肯捡起,(伪)学霸的光环还是可以暂时回来的...
2.1 矩阵的历史
阿瑟·凯莱被公认为矩阵论的奠基人,他开始将矩阵作为独立的数学对象研究时,许多与矩阵有关的性质已经在行列式的研究中被发现了,这也使得凯莱认为矩阵的引进是十分自然的。
他从1858年开始,发表了《矩阵论的研究报告》等一系列关于矩阵的专门论文,研究了矩阵的运算律、矩阵的逆以及转置和特征多项式方程。
此后更多的数学家开始对矩阵进行研究,埃尔米特证明了如果矩阵等于其复共轭转置,则特征根为实数。这种矩阵后来被称为埃尔米特矩阵。
弗罗贝尼乌斯对矩阵的特征方程、特征根、矩阵的秩、正交矩阵、矩阵方程等方面做了大量工作。1878年,在引进了不变因子、初等因子等概念的同时,弗罗贝尼乌斯给出了正交矩阵、相似矩阵和合同矩阵的概念。
2.2 矩阵的用途
矩阵是高等代数学中的常见工具,矩阵的一个重要用途是解线性方程组,线性方程组中未知量的系数可以排成一个矩阵,加上常数项,则称为增广矩阵,另一个重要用途是表示线性变换,矩阵的特征值和特征向量可以揭示线性变换的深层特性。
在物理学中,矩阵于力学、电路学、光学和量子物理中都有应用,计算机科学中,三维动画制作也需要用到矩阵。矩阵的运算是数值分析领域的重要问题。将矩阵分解为简单矩阵的组合可以在理论和实际应用上简化矩阵的运算。在天体物理、量子力学等领域,也会出现无穷维的矩阵,是矩阵的一种推广。
2.3 矩阵的基本运算
矩阵的运算主要包括:加减、数乘、转置、相乘等。其中加减、数乘比较简单,转置运算本文用不到,重点说一下矩阵乘法运算。
两个矩阵相乘需要满足一定的条件:
- 矩阵A的列数等于矩阵B的行数
eg:A是m*n的矩阵,B是n*p的矩阵 则二者相乘后的矩阵C=A*B为m*p的矩阵 - 矩阵乘法不满足交换律
也就是说C=A*B,不一定存在D=B*A,因为B的列数并不一定等于A的行数,并且即使B*A可以相乘,那么C和D也不一定相等
矩阵的运算过程:
以C=A*B为例来说明,矩阵相乘的运算过程本质上就是求得新矩阵的每个位置上的值,然而这个值取决于A特定行的全部元素和B特定列的全部元素的交叉乘积之和,听起来有点绕,不要怕,写个表达式就清楚了:

举个栗子:
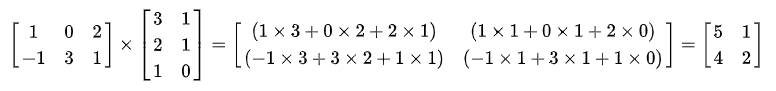
矩阵的运算图示:
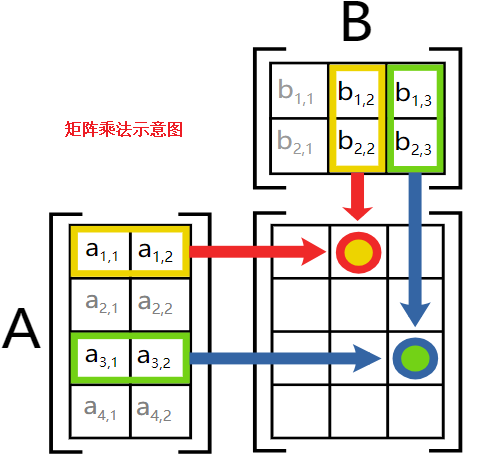
再来一个清晰版的(摘自维基百科):
2.4 阶段一小结
通过前面的一些描述,我们知道矩阵这个东西历史不算短,并且在解线性方程、电子学、力学、光学等诸多领域都有非常广泛的用途,是个基础的数学工具。
矩阵也包含了一些运算,本文只针对矩阵乘法做了一些描述,这些知识储备也足够我们完成今天的面试题啦!
3.基础版本矩阵乘法的实现
有了前面的数学知识储备,我们就可以放心大胆的Coding了,首先摆在眼前的问题是如何将数学模型转换为程序代码?
3.1 矩阵的多维数组表示
一维数组我们用的非常多,多维数组本质上就是一维数组的集合,用STL里面的vector表示就是:
vector<vector<int>>
不过这里我们暂时不使用vector表示多维数组了,而是使用C语言中多维数组来表示,这样确定了大小操作比较方便,那我们来写一个4*4的数组来表示4维的方阵:
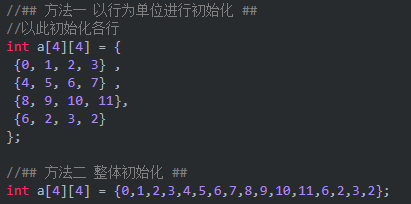
3.2 多维数组的存储
理解多维数组的存储是解决和优化本题的关键,由于数组是连续内存存储的,多维数组看做是装载数组的数组,换句话说多维数组的元素就是数组,以a[4][4]为例就是存储了4个一维数组,且一维数组的空间大小是4。
多维数组在内存存储时是连续存储的,因此面临一个问题就是先存储行还是先存储列?
- 行优先存储
- 列优先存储
画个图表示一下:
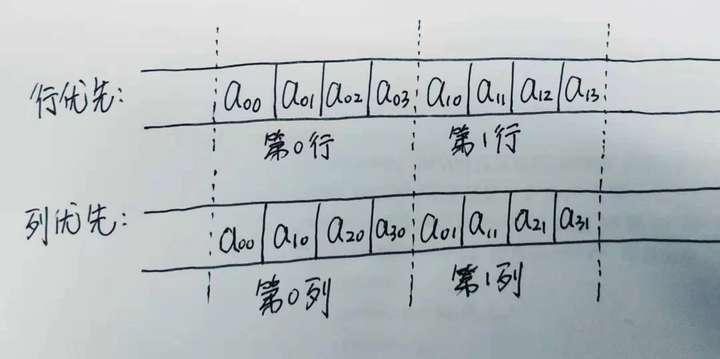
在C语言中使用的是行优先存储,也就是a[0][1]和a[0][2]是相邻的,但是a[0][1]和a[1][1]是不相邻的,中间相隔了整个第一行的存储长度。
3.3 基础版本的代码实现
Talk Is Cheap,Show You The Code.
在开始写代码之前,大白先自己人脑算了一遍,作为标准对照答案,简单起见只写了3维方阵,人脑版计算过程如图(手机拍的 凑合一下吧):

由于微信显示代码效果不好,因此改为贴图片了,大白是VIM&Notepad++党,所以其他的IDE统统不常用,看下代码吧:

写好之后开始编译,不开任何优化后执行bin文件:
g++ martrix.cpp -o exe
./exe
输出结果:
基础版本输出矩阵乘法结果:
4 20 35
24 83 144
19 76 128
这个结果对比人脑版二者是一样的,所以基础版本代码是无误的,到这里这道题在面试官那边算勉强通过了。
但是这还没完,精益求精是我猿的本色,接来下开始灵魂发问:
- 扩大数据规模,现在给定1000维的方阵能很快搞定吗?
- 这个基础版本性能ok吗?
- 是否还有优化空间呢?
3.4 基础版本的性能分析
前面我们分析了多维数组的行优先存储,从基础版本的代码可以知道对于矩阵A是按照行遍历的,但是对于矩阵B却是按照列来遍历的,这样的话貌似性能不是最好的。
因为CPU也是有缓存的呀!这种情况下矩阵B的CacheMiss率非常高,但是有人可能会问从CPU缓存和从内存读取性能差别有多大呀?
这个问题,问的非常好,那我们就一起来看看吧!
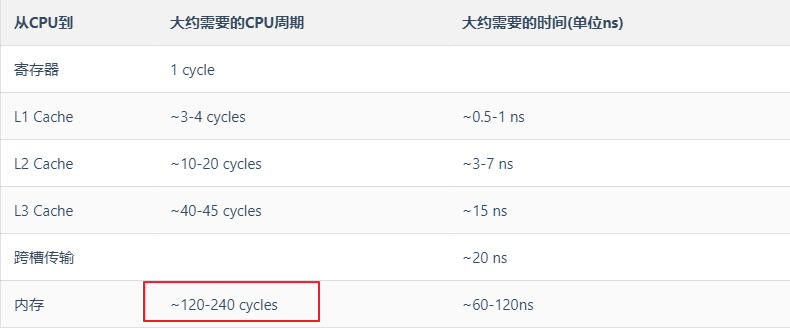
1.CPU、缓存、主存架构
我们以现在主流的CPU3级缓存的处理器为例,看一下这个结构图:

CPU缓存通常分为L1,L2,L3三个级别:
- L1是最接近CPU但是它容量最小,速度最快,L1缓存分为数据缓存L1d和指令缓存L1i
- L2缓存比L1大一些并且速度要慢一些
- L3缓存是三级缓存中容量最大的,也是最慢的一级缓存
从各级缓存读取数据的时钟周期消耗如图:
2.优化方向
从上面的分析可以知道,各级缓存和内存的存取时间差距还是非常大的,内存的耗时是L1的40-60倍,因此有效降低CacheMiss可以降低时钟周期,也就是降低程序的时间消耗。
但是对于矩阵乘法运算而言,是必然会存在列的上下移动,这样的话CacheMiss貌似是不可避免了,一时间大白慌了神。

4.高效版本的实现
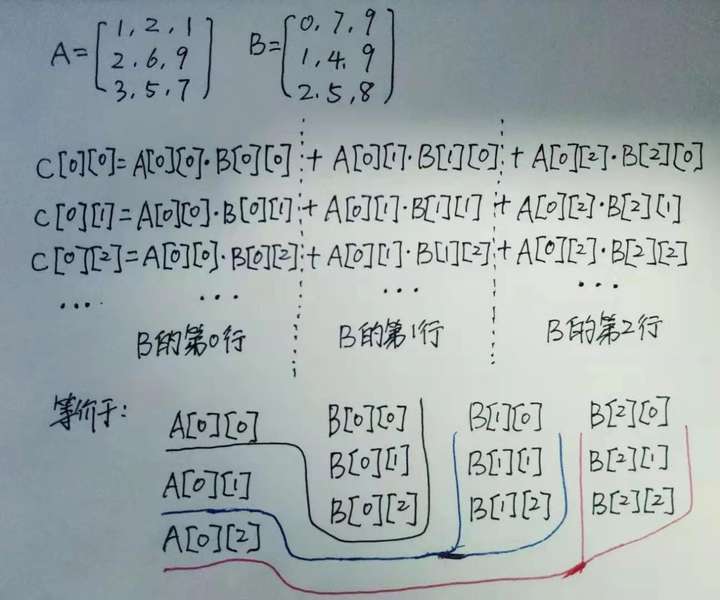
路子总是人想的,我们从数学的等价运算上来考虑试一试:
- 之前的做法是将C[i][j]的一个元素正确算完才算结束,然后进行下一个,这样就造成了跳着的CacheMiss
- 换一种思路,每次都尽量沿着两个矩阵的行走,但是不算完C[i][j],只算一点,循环结束最终就算完了
上面说的算是心法吧,大白面试时确实没有想出来这种做法,事后研究了一下,觉得办法很不错,我来写一写来详细说明一下这个过程吧:
优化版本代码实现
大白试着实现了上述优化过程的代码,写完之后感觉和基础版本很像,不仔细看都区分不出来,本质上却有很大不同,代码如下:

写好之后开始编译,不开任何优化后执行bin文件:
g++ martrix_v2.cpp -o exe
./exe
输出结果:
优化版本输出矩阵乘法结果:
4 20 35
24 83 144
19 76 128
优化思维
说到底优化版本就是将常见的交叉相乘累加一次算完转换为两个行运算拆分成子结果最终累加,本质上是一样的结果,但是在计算机看来区别却很大,所以有时候要将人的思维等价转换为符合计算机的思维。

5.总结
本文从一道面试题作为出发点,展开了关于矩阵乘法的实现,文章中使用了两个版本来实现,鉴于验证正确性考虑并没有扩展到更大的数据规模。
不过我想应该是有在线的矩阵运算器,这样可以做个标准答案,然后使用两个版本扩大到1000唯甚至更多来看两个版本的耗时更有说服力,这个后面弄一下吧,时间关系本次就只能写这么多啦!
重要的是一种思维方式:人的思维方式不一定适用于计算机,因此有时候为了提高程序的性能我们要做等价转换,让计算机觉得很nice,这样写出了的代码才是精益求精的。
暂时就写这么多吧,昨晚修bug太晚,早上匆忙爬起继续码字,太困了...
最后希望各位读者觉得本文还不错,那就转发分享一下吧,这样大白会更加有动力,提高产量的同时保证质量!
6.巨人的肩膀
https://lwn.net/Articles/252125/
https://blog.slinuxer.com/2014/10/cache-optimization
7.关于我
 欢迎关注
欢迎关注
专注于分享和探讨后端技术点
涵盖编程语言、数据结构、算法、操作系统、数据库、分布式系统、大数据、中间件等专题
追求有深度且具表达力的文字,记录所思所得。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号