基于Redis的分布式锁和Redlock算法
1 前言
前面写了4篇Redis底层实现和工程架构相关文章,感兴趣的读者可以回顾一下:
今天开始来和大家一起学习一下Redis实际应用篇,会写几个Redis的常见应用。
在我看来Redis最为典型的应用就是作为分布式缓存系统,其他的一些应用本质上并不是杀手锏功能,是基于Redis支持的数据类型和分布式架构来实现的,属于小而美的应用。
结合笔者的日常工作,今天和大家一起研究下基于Redis的分布式锁和Redlock算法的一些事情。
 图片来自网络
图片来自网络
2.初识锁
1. 锁的双面性
现在我们写的程序基本上都有一定的并发性,要么单台多进线程、要么多台机器集群化,在仅读的场景下是不需要加锁的,因为数据是一致的,在读写混合或者写场景下如果不加以限制和约束就会造成写混乱数据不一致的情况。
如果业务安全和正确性无法保证,再多的并发也是无意义的。
这个不由得让我想起一个趣图:

图片来自网络
高并发多半是考验你们公司的基础架构是否强悍,合理正确地使用锁才是个人能力的体现。
凡事基本上都是双面的,锁可以在一定程度上保证数据的一致性,但是锁也意味着维护和使用的复杂性,当然也伴随着性能的损耗,我见过的最大的锁可能就是CPython解释器的全局解释器锁GIL了。
没办法 好可怕 那个锁 不像话--《说锁就锁》
锁使用不当不但解决不了数据混乱问题,甚至会带来诸如死锁等更多问题,通俗地说死锁现象:
几年前会出现这样的场景:在异地需要买火车票回老家,但是身份证丢了无法购票,补办身份证又需要本人坐火车回老家户籍管理处,就这样生活太难。
2. 无锁化编程
既然锁这么难以把控,那不得不思考有没有无锁的高并发。
无锁编程也是一个非常有意思的话题,后续可以写一篇聊聊这个话题,本次就只提一下,要打开思路,不要被困在凡是并发必须加锁的思维定势。
在某些特定场景下会选择一种并行转串行的思路,从而尽量避免锁的使用,举个栗子:
Post请求:http://abc.def/setdata?reqid=abc123789def&dbname=bighero
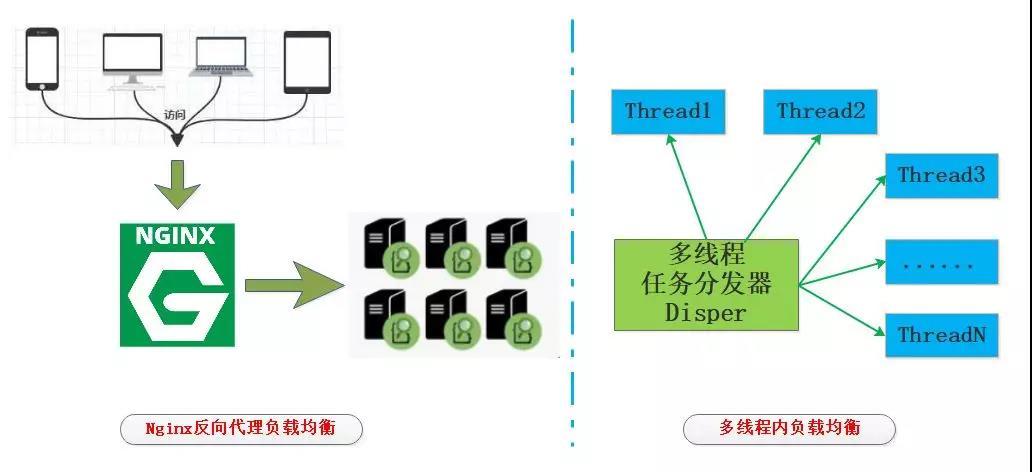
假如有一个上述的post请求的URI部分是个覆盖写操作,reqid=abc123789def,服务部署在多台机器,在大前端将流量转发到Nginx之后根据reqid进行哈希,Nginx的配置大概是这样的:
upstream myservice { #根据参数进行Hash分配 hash $urlkey; server localhost:5000; server localhost:5001; server localhost:5002; }
经过Nginx负载均衡相同reqid的请求将被转发到一台机器上,当然你可能会说如果集群的机器动态调整呢?我只能说不要考虑那么多那么充分,工程化去设计即可。
然而转发到一台机器仍然无法保证串行处理,因为单机仍然是多线程的,我们仍然需要将所有的reqid数据放到同一个线程处理,最终保证线程内串行,这个就需要借助于线程池的管理者Disper按照reqid哈希取模来进行多线程的负载均衡。
经过Nginx和线程内负载均衡,最终相同的reqid都将在线程内串行处理,有效避免了锁的使用,当然这种设计可能在reqid不均衡时造成线程饥饿,不过高并发大量请求的情况下还是可以的。
只描述不画图 就等于没说:
3. 单机锁和分布式锁
锁依据使用范围可简单分为:单机锁和分布式锁。
Linux提供系统级单机锁,这类锁可以实现线程同步和互斥资源的共享,单机锁实现了机器内部线程之间对共享资源的并发控制。
在分布式部署高并发场景下,经常会遇到资源的互斥访问的问题,最有效最普遍的方法是给共享资源或者对共享资源的操作加一把锁。
分布式锁是控制分布式系统之间同步访问共享资源的一种方式,用于在分布式系统中协调他们之间的动作。
3.分布式锁
1. 分布式锁的实现简介
分布式CAP理论告诉我们需要做取舍:
任何一个分布式系统有三大特性:一致性Consistency、可用性Availability和分区容错性Partition Tolerance,但是由于网络分区不受人为控制,在网络发生分区时,我们必须在可用性和一致性二者中选择之一。
在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只保证最终一致性。在很多场景中为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。
分布式锁一般有三种实现方式:
- 基于数据库
在数据库中创建一张表,表里包含方法名等字段,并且在方法名字段上面创建唯一索引,执行某个方法需要使用此方法名向表中插入数据,成功插入则获取锁,执行结束则删除对应的行数据释放锁 - 基于缓存数据库Redis
Redis性能好并且实现方便,但是单节点的分布式锁在故障迁移时产生安全问题,Redlock是Redis的作者 Antirez 提出的集群模式分布式锁,基于N个完全独立的Redis节点实现分布式锁的高可用 - 基于ZooKeeper
ZooKeeper 是以 Paxos 算法为基础的分布式应用程序协调服务,为分布式应用提供一致性服务的开源组件
2. 分布式锁需要具备的条件
分布式锁在应用于分布式系统环境相比单机锁更为复杂,本文讲述基于Redis的分布式锁实现,该锁需要具备一些特性:
- 互斥性
在任意时刻,只有一个客户端能持有锁 其他尝试获取锁的客户端都将失败而返回或阻塞等待 - 健壮性
一个客户端持有锁的期间崩溃而没有主动释放锁,也需要保证后续其他客户端能够加锁成功,就像C++的智能指针来避免内存泄漏一样 - 唯一性
加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给释放了,自己持有的锁也不能被其他客户端释放 - 高可用
不必依赖于全部Redis节点正常工作,只要大部分的Redis节点正常运行,客户端就可以进行加锁和解锁操作
3. 基于单Redis节点的分布式锁
本文的重点是基于多Redis节点的Redlock算法,不过在展开这个算法之前,有必要提一下单Redis节点分布式锁原理以及演进,因为Redlock算法是基于此改进的。
最初分布式锁借助于setnx和expire命令,但是这两个命令不是原子操作,如果执行setnx之后获取锁但是此时客户端挂掉,这样无法执行expire设置过期时间就导致锁一直无法被释放,因此在2.8版本中Antirez为setnx增加了参数扩展,使得setnx和expire具备原子操作性。

在单Matster-Slave的Redis系统中,正常情况下Client向Master获取锁之后同步给Slave,如果Client获取锁成功之后Master节点挂掉,并且未将该锁同步到Slave,之后在Sentinel的帮助下Slave升级为Master但是并没有之前未同步的锁的信息,此时如果有新的Client要在新Master获取锁,那么将可能出现两个Client持有同一把锁的问题,来看个图来想下这个过程:
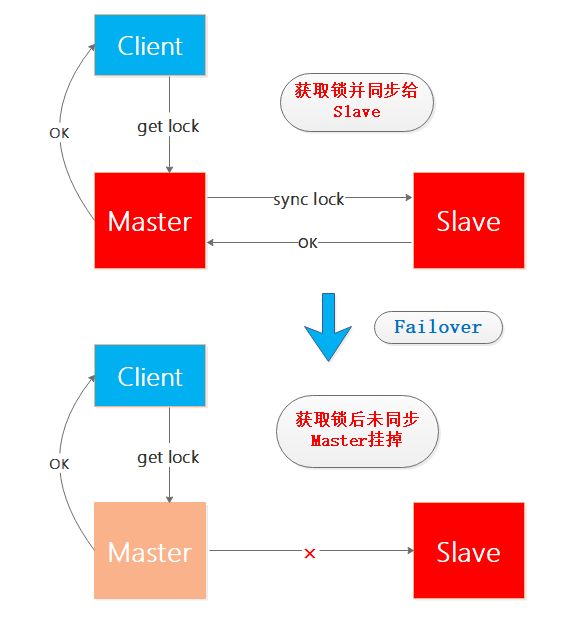
为了保证自己的锁只能自己释放需要增加唯一性的校验,综上基于单Redis节点的获取锁和释放锁的简单过程,使用lua脚本实现如下:
// 获取锁 unique_value作为唯一性的校验 SET resource_name unique_value NX PX 30000 // 释放锁 比较unique_value是否相等 避免误释放 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
这就是基于单Redis的分布式锁的几个要点。
4.Redlock算法过程
Redlock算法是Antirez在单Redis节点基础上引入的高可用模式。
在Redis的分布式环境中,我们假设有N个完全互相独立的Redis节点,在N个Redis实例上使用与在Redis单实例下相同方法获取锁和释放锁。
现在假设有5个Redis主节点(大于3的奇数个),这样基本保证他们不会同时都宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
- 1.获取当前Unix时间,以毫秒为单位
- 2.依次尝试从5个实例,使用相同的key和具有唯一性的value获取锁
当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间,这样可以避免客户端死等 - 3.客户端使用当前时间减去开始获取锁时间就得到获取锁使用的时间。当且仅当从半数以上的Redis节点取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功
- 4.如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间,这个很重要
- 5.如果因为某些原因,获取锁失败(没有在半数以上实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失了但是实际成功了,毕竟多释放一次也不会有问题
上述的5个步骤是Redlock算法的重要过程,也是面试的热点,有心的读者还是记录一下吧!
5.Redlock算法是否安全的争论
1.关于马丁·克莱普曼博士
2016年2月8号分布式系统的专家马丁·克莱普曼博士(Martin Kleppmann)在一篇文章How to do distributed locking 指出分布式锁设计的一些原则并且对Antirez的Redlock算法提出了一些质疑。
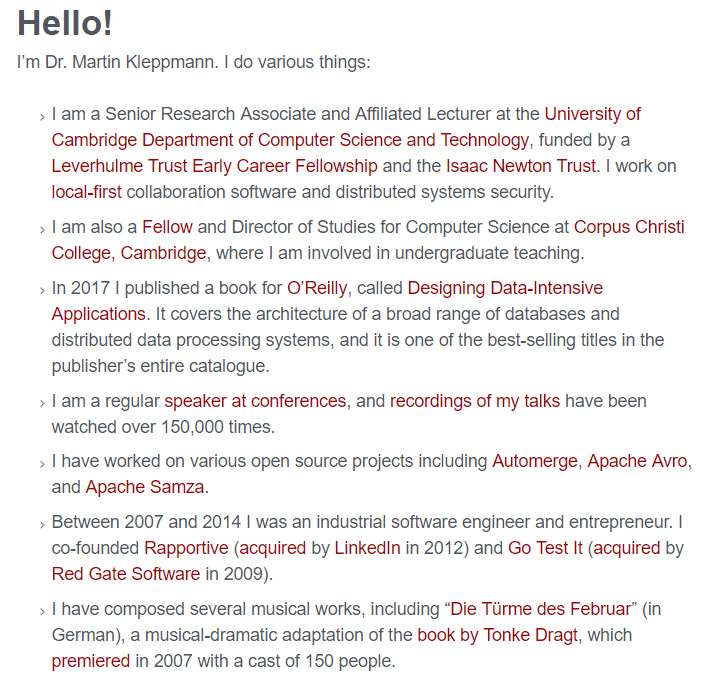
笔者找到了马丁·克莱普曼博士的个人网站以及一些简介,一起看下:
用搜狗翻译看一下:
1.我是剑桥大学计算机科学与技术系的高级研究助理和附属讲师,由勒弗乌尔姆信托早期职业奖学金和艾萨克牛顿信托基金资助。我致力于本地优先的协作软件和分布式系统安全。
2.我也是剑桥科珀斯克里斯蒂学院计算机科学研究的研究员和主任,我在那里从事本科教学。
3.2017年,我为奥雷利出版了一本名为《设计数据密集型应用》的书。它涵盖了广泛的数据库和分布式数据处理系统的体系结构,是该出版社最畅销书之一。
4.我经常在会议上发言,我的演讲录音已经被观看了超过15万次。
5.我参与过各种开源项目,包括自动合并、Apache Avro和Apache Samza。
6.2007年至2014年间,我是一名工业软件工程师和企业家。我共同创立了Rapportive(2012年被领英收购)和Go Test(2009年被红门软件收购)。
7.我创作了几部音乐作品,包括《二月之死》(德语),这是唐克·德拉克特对该书的音乐戏剧改编,于2007年首映,共有150人参与。
大牛就是大牛,能教书、能出书、能写开源软件、能创业、能写音乐剧,优秀的人哪方面也优秀,服气了。
 图片来自网络
图片来自网络
2.马丁博士文章的主要观点
马丁·克莱普曼在文章中谈及了分布式系统的很多基础问题,特别是分布式计算的异步模型,文章分为两大部分前半部分讲述分布式锁的一些原则,后半部分针对Redlock提出一些看法:
- Martin指出即使我们拥有一个完美实现的分布式锁,在没有共享资源参与进来提供某种fencing栅栏机制的前提下,我们仍然不可能获得足够的安全性
- Martin指出,由于Redlock本质上是建立在一个同步模型之上,对系统的时间有很强的要求,本身的安全性是不够的
针对fencing机制马丁给出了一个时序图:
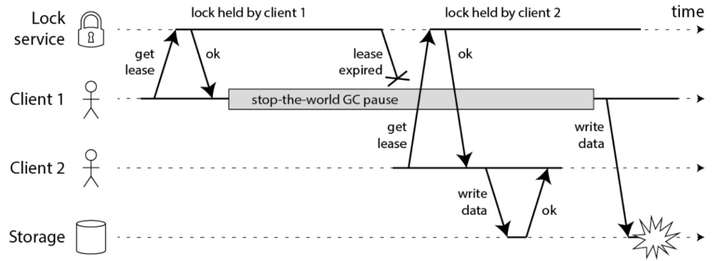
获取锁的客户端在持有锁时可能会暂停一段较长的时间,尽管锁有一个超时时间,避免了崩溃的客户端可能永远持有锁并且永远不会释放它,但是如果客户端的暂停持续的时间长于锁的到期时间,并且客户没有意识到它已经到期,那么它可能会继续进行一些不安全的更改,换言之由于客户端阻塞导致的持有的锁到期而不自知。
针对这种情况马丁指出要增加fencing机制,具体来说是fencing token隔离令牌机制,同样给出了一张时序图:
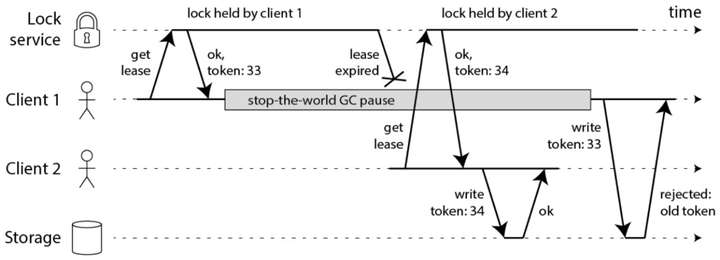
客户端1获得锁并且获得序号为33的令牌,但随后它进入长时间暂停,直至锁超时过期,客户端2获取锁并且获得序号为34的令牌,然后将其写入发送到存储服务。随后,客户端1复活并将其写入发送到存储服务,然而存储服务器记得它已经处理了具有较高令牌号的写入34,因此它拒绝令牌33的请求。
Redlock算法并没有这种唯一且递增的fencing token生成机制,这也意味着Redlock算法不能避免由于客户端阻塞带来的锁过期后的操作问题,因此是不安全的。
这个观点笔者觉得并没有彻底解决问题,因为如果客户端1的写入操作是必须要执行成功的,但是由于阻塞超时无法再写入同样就产生了一个错误的结果,客户端2将可能在这个错误的结果上进行操作,那么任何操作都注定是错误的。
3.马丁博士对Redlock的质疑
马丁·克莱普曼指出Redlock是个强依赖系统时间的算法,这样就可能带来很多不一致问题,他给出了个例子一起看下:
假设多节点Redis系统有五个节点A/B/C/D/E和两个客户端C1和C2,如果其中一个Redis节点上的时钟向前跳跃会发生什么?
- 客户端C1获得了对节点A、B、c的锁定,由于网络问题,法到达节点D和节点E
- 节点C上的时钟向前跳,导致锁提前过期
- 客户端C2在节点C、D、E上获得锁定,由于网络问题,无法到达A和B
- 客户端C1和客户端C2现在都认为他们自己持有锁
分布式异步模型:
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性对Redis节点系统时钟有强依赖,一旦系统时钟变得不准确,算法的安全性也就无法保证。
马丁其实是要指出分布式算法研究中的一些基础性问题,好的分布式算法应该基于异步模型,算法的安全性不应该依赖于任何记时假设。
分布式异步模型中进程和消息可能会延迟任意长的时间,系统时钟也可能以任意方式出错。这些因素不应该影响它的安全性,只可能影响到它的活性,即使在非常极端的情况下,算法最多是不能在有限的时间内给出结果,而不应该给出错误的结果,这样的算法在现实中是存在的比如Paxos/Raft,按这个标准衡量Redlock的安全级别是达不到的。
4.马丁博士文章结论和基本观点
马丁表达了自己的观点,把锁的用途分为两种:
- 效率第一
使用分布式锁只是为了协调多个客户端的一些简单工作,锁偶尔失效也会产生其它的不良后果,就像你收发两份相同的邮件一样,无伤大雅 - 正确第一
使用分布式锁要求在任何情况下都不允许锁失效的情况发生,一旦发生失效就可能意味着数据不一致、数据丢失、文件损坏或者其它严重的问题,就像给患者服用重复剂量的药物一样,后果严重
最后马丁出了如下的结论:
- 为了效率而使用分布式锁
单Redis节点的锁方案就足够了Redlock则是个过重而昂贵的设计 - 为了正确而使用分布式锁
Redlock不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分
马丁认为Redlock算法是个糟糕的选择,因为它不伦不类:出于效率选择来说,它过于重量级和昂贵,出于正确性选择它又不够安全。
6.Antirez的反击
马丁的那篇文章是在2016.2.8发表之后Antirez反应很快,他发表了"Is Redlock safe?"进行逐一反驳,文章地址如下:http://antirez.com/news/101
Antirez认为马丁的文章对于Redlock的批评可以概括为两个方面:
- 带有自动过期功能的分布式锁,必须提供某种fencing栅栏机制来保证对共享资源的真正互斥保护,Redlock算法提供不了这样一种机制
- Redlock算法构建在一个不够安全的系统模型之上,它对于系统的记时假设有比较强的要求,而这些要求在现实的系统中是无法保证的
Antirez对这两方面分别进行了细致地反驳。
关于fencing机制
Antirez提出了质疑:既然在锁失效的情况下已经存在一种fencing机制能继续保持资源的互斥访问了,那为什么还要使用一个分布式锁并且还要求它提供那么强的安全性保证呢?
退一步讲Redlock虽然提供不了递增的fencing token隔离令牌,但利用Redlock产生的随机字符串可以达到同样的效果,这个随机字符串虽然不是递增的,但却是唯一的。
关于记时假设
Antirez针对算法在记时模型假设集中反驳,马丁认为Redlock失效情况主要有三种:
- 1.时钟发生跳跃
- 2.长时间的GC pause
- 3.长时间的网络延迟
后两种情况来说,Redlock在当初之处进行了相关设计和考量,对这两种问题引起的后果有一定的抵抗力。
时钟跳跃对于Redlock影响较大,这种情况一旦发生Redlock是没法正常工作的。
Antirez指出Redlock对系统时钟的要求并不需要完全精确,只要误差不超过一定范围不会产生影响,在实际环境中是完全合理的,通过恰当的运维完全可以避免时钟发生大的跳动。
7.马丁的总结和思考
分布式系统本身就很复杂,机制和理论的效果需要一定的数学推导作为依据,马丁和Antirez都是这个领域的专家,对于一些问题都会有自己的看法和思考,更重要的是很多时候问题本身并没有完美的解决方案。
这次争论是分布式系统领域非常好的一次思想的碰撞,很多网友都发表了自己的看法和认识,马丁博士也在Antirez做出反应一段时间之后再次发表了自己的一些观点:
For me, this is the most important point: I don’t care who is right or wrong in this debate — I care about learning from others’ work, so that we can avoid repeating old mistakes, and make things better in future. So much great work has already been done for us: by standing on the shoulders of giants, we can build better software.
By all means, test ideas by arguing them and checking whether they stand up to scrutiny by others. That’s part of the learning process. But the goal should be to learn, not to convince others that you are right. Sometimes that just means to stop and think for a while.
简单翻译下就是:
对马丁而言并不在乎谁对谁错,他更关心于从他人的工作中汲取经验来避免自己的错误重复工作,正如我们是站在巨人的肩膀上才能做出更好的成绩。
另外通过别人的争论和检验才更能让自己的想法经得起考验,我们的目标是相互学习而不是说服别人相信你是对的,所谓一人计短,思考辩驳才能更加接近真理。
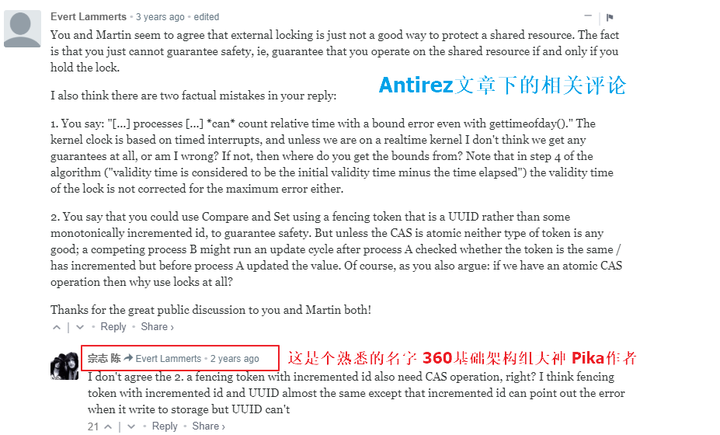
在Antirez发表文章之后世界各地的分布式系统专家和爱好者都积极发表自己的看法,笔者在评论中发现了一个熟悉的名字:
8.巨人的肩膀
- https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
- http://antirez.com/news/101
- http://zhangtielei.com/posts/blog-redlock-reasoning.html
- http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html
铁蕾大神的两篇文章写的非常好,本文从中做了很多参考,也是铁蕾大神的文章让笔者了解到这场精彩的华山论剑,感兴趣的可以直接搜索阅读参考3和4。
9.关于我
专注于分享和探讨后端技术点
涵盖编程语言、数据结构、算法、操作系统、数据库、分布式系统、大数据、中间件等专题
追求有深度且具表达力的文字,记录所思所得。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号