Spark设计与运行原理,基本操作
Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。

组件介绍
Spark Core:
Spark的核心组件,其操作的数据对象是RDD(弹性分布式数据集),图中在Spark Core上面的四个组件都依赖于Spark Core,可以简单认为Spark Core就是Spark生态系统中的离线计算框架。
Spark Streaming:
Spark生态系统中的流式计算框架,其操作的数据对象是DStream,其实Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(批次间隔时长)(如1秒)分成一段一段的数据系列(DStream),每一段数据都转换成Spark Core中的RDD,然后将Spark Streaming中对DStream的转换计算操作变为针对Spark中对RDD的转换计算操作,如下官方提供的图。
Spark Sql:
可以简单认为可以让用户使用写SQL的方式进行数据计算,SQL会被SQL解释器转化成Spark core任务,让懂SQL不懂spark的人都能通过写SQL的方式进行数据计算,类似于hive在Hadoop生态圈中的作用,提供SparkSql CLI(命令行界面),可以再命令行界面编写SQL。
Spark Graphx:
Spark生态系统中的图计算和并行图计算,目前较新版本已支持PageRank、数三角形、最大连通图和最短路径等6种经典的图算法。
Spark Mlib:
一个可扩展的Spark机器学习库,里面封装了很多通用的算法,包括二元分类、线性回归、聚类、协同过滤等。用于机器学习和统计等场景。
Tachyon:
Tachyon是一个分布式内存文件系统,可以理解为内存中的HDFS.
Local,Standalone,Yarn,Mesos:
Spark的四种部署模式,其中Local是本地模式,一般用来开发测试,Standalone是Spark 自带的资源管理框架,Yarn和Mesos是另外两种资源管理框架,Spark用哪种模式部署,也就是使用了哪种资源管理框架
请详细阐述Spark的几个主要概念及相互关系:
Master、Worker
Master和Worker是Spark独立集群里用到的类。如果是yarn环境部署,是不需要这两个类的。
Master是Spark独立集群的控制者,Worker是工作者,一个Spark独立集群需要启动一个Master和多个Worker。
Spark提供了Master选举功能,保障Master挂掉的时候能选出另一个Master,做一个切换的动作,这块原理和ZooKeeper类似。
Master节点常驻Master守护进程,负责管理Worker节点,从Master节点提交应用。
Worker节点常驻worker守护进程,与Master节点通信,并且管理executor进程。
RDD、DAG
RDD:Resillient Distributed Dataset(弹性分布式数据集),是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:Directed Acyclic Graph(有向无环图),反映RDD之间的依赖关系。
Application、Job、Stage、Task
RDD任务切分中间分为:Application、Job、Stage和Task
(1)Application(应用)
用户编写的Spark应用程序。
(2)Job(作业)
Job是用户程序一个完整的处理流程,是逻辑的叫法。
一个作业可以包含多个RDD及作用于相应RDD上的各种操作。
(3)Stage(阶段)
是作业的基本调度单位,每个作业会因为RDD之间的依赖关系拆分成多组任务集合TaskSet,称为调度阶段。
调度阶段的划分是由DAGScheduler来划分的,有Shuffle Map Stage和Result Stage两种。
(4)Task(任务)
分发到Executor上的工作任务,是spark实际执行应用的最小单元,一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
一个Stage可以包含多个task,比如sc.textFile("/xxxx").map().filter(),其中map和filter就分别是一个task。
每个task的输出就是下一个task的输出。
Driver、Executor、Claster Manager
Driver进程应用 main() 函数并且构建sparkContext对象。
当我们提交了应用之后,便会启动一个对应的Driver进程,Driver本身会根据我们设置的参数占有一定的资源就是Executor。
然后集群管理者会分配一定数量的Executor,每个Executor都占用一定数量的cpu和memory。
这里Executors其实是一个独立的JVM进程,在每个工作节点上会起一个,主要用来执行task,一个executor内,可以同时并行的执行多个task。
而Claster Manager主要负责整个程序的资源调度目前的主要调度器有:YARN、Spark Standalone、Mesos。
DAGScheduler、TaskScheduler
DAGScheduler:面向调度阶段的任务调度器,负责接收spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交调度阶段给TaskScheduler.
TaskScheduler:面向任务的调度器,它接受DAGScheduler提交过来的调度阶段,然后把任务分发到work节点运行,由Worker节点的Executor来运行该任务
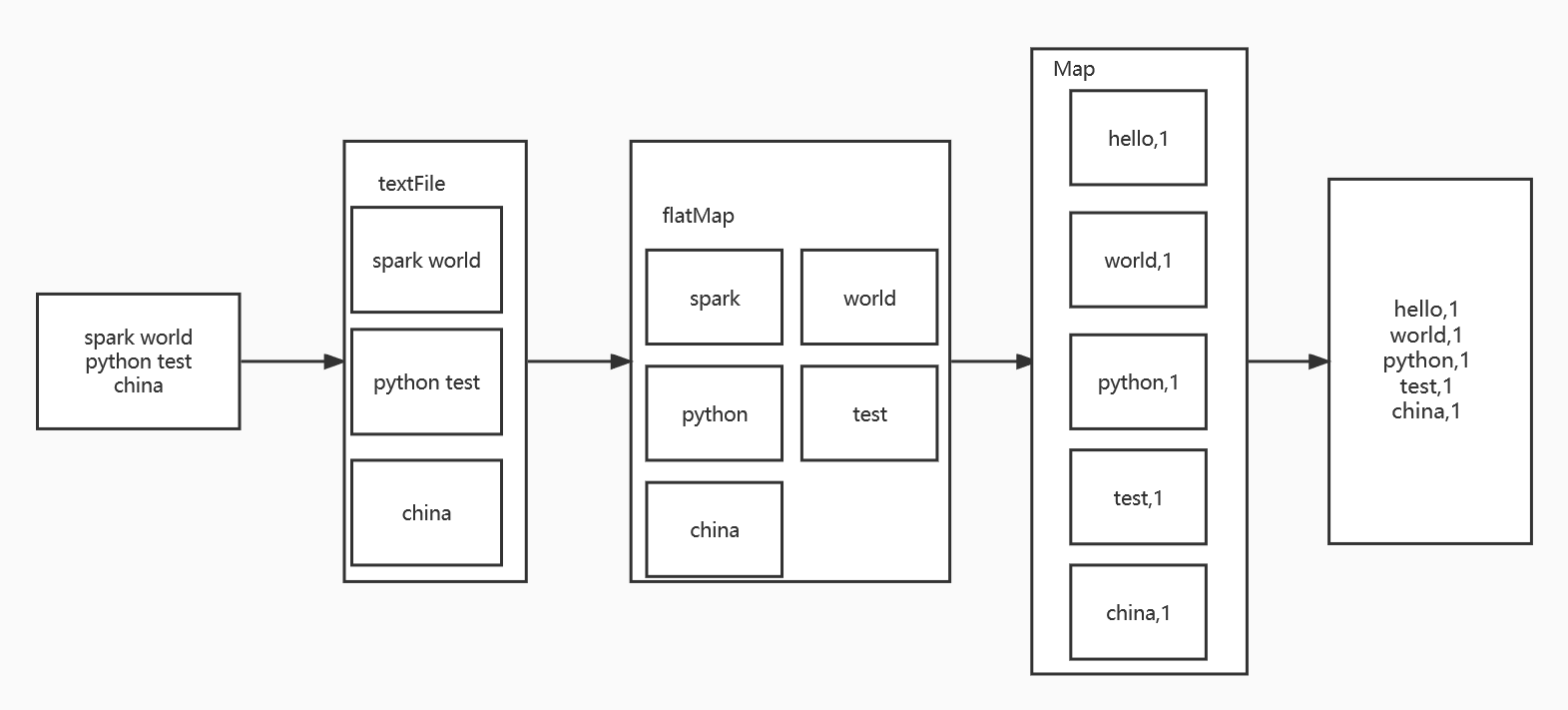
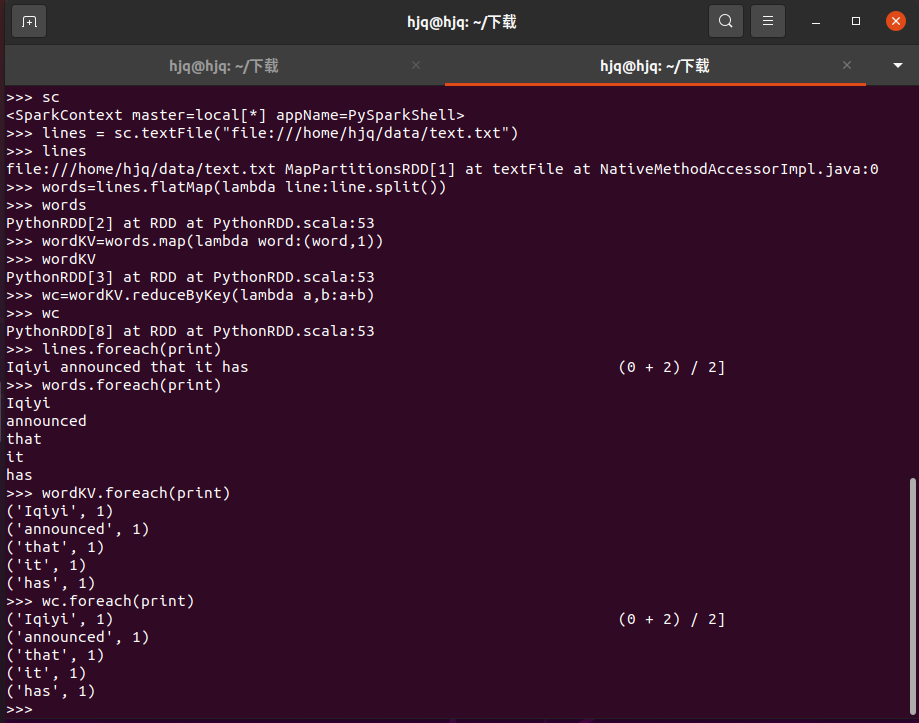
在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
sc lines = sc.textFile("file:///home/sjx/下载/EN/test.txt") lines words=lines.flatMap(lambda line:line.split()) words wordKV=words.map(lambda word:(word,1)) wordKV wc=wordKV.reduceByKey(lambda a,b:a+b) wc lines.foreach(print) words.foreach(print) wordKV.foreach(print) wc.foreach(print)
生成结果如下图所示:
转换关系图如下: