

转:Selenium文摘
Selenium 是 thoughtworks公司的一个集成测试的强大工具。最近参与了一个系统移植的项目,正好用到这个工具,
把一些使用心得分享给大家,希望大家能多多使用这样的强大的,免费的工具,来保证我们的质量。
Selenium 的文档现存的不少,不过都太简单了。使用Selenium的时候,我更多的是直接去看API文档,好在API不错,
一个一个看,就能找到所需要的 :-) 官方网站:http://www.openqa.org/selenium/
好,下面进入正题!
一、Selenium 的版本
Selenium 现在存在2个版本,一个叫 selenium-core, 一个叫selenium-rc 。
selenium-core 是使用HTML的方式来编写测试脚本,你也可以使用 Selenium-IDE来录制脚本,但是目前Selenium-IDE
只有 FireFox 版本。
Selenium-RC 是 selenium-remote control 缩写,是使用具体的语言来编写测试类。
selenium-rc 支持的语言非常多,这里我们着重关注java的方式。这里讲的也主要是 selenium-rc,因为个人还是喜欢这种
方式 :-)
二、一些准备工作
1、当然是下载 selenium 了,到 http://www.openqa.org/selenium/ 下载就可以了,记得选择selenium-rc 的版本。
2、学习一下 xpath 的知识。有个教程:http://www.zvon.org/xxl/XPathTutorial/General_chi/examples.html
一定要学习这个,不然你根本看不懂下面的内容!
3、安装 jdk1.5
三、selenium-rc 一些使用方法
在 selenium-remote-control-0.9.0\server 目录里,我们运行 java -jar selenium-server.jar
之后你就会看到一些启动信息。要使用 selenium-rc ,启动这个server 是必须的。
当然,启动的时候有许多参数,这些用法可以在网站里看看教程,不过不加参数也已经足够了。
selenium server 启动完毕了,那么我们就可以开始编写测试类了!
我们先有个概念,selenium 是模仿浏览器的行为的,当你运行测试类的时候,你就会发现selenium 会打开一个
浏览器,然后浏览器执行你的操作。
好吧,首先生成我们的测试类:
代码十分简单,作用就是初始化一个 Selenium 对象。其中:
url : 就是你要测试的网站
localhost: 可以不是localhost,但是必须是 selenium server 启动的地址
*iexplore : 可以是其它浏览器类型,可以在网站上看都支持哪些。
下面我就要讲讲怎么使用selenium 这个对象来进行测试。
1、测试文本输入框
假设页面上有一个文本输入框,我们要测试的内容是 在其中输入一些内容,然后点击一个按钮,看看页面的是否跳转
到需要的页面。
上面的代码是这个意思:
1、调用 selenium.open 方法,浏览器会打开相应的页面
2、使用 type 方法来给输入框输入文字
3、等待页面载入
4、看看新的页面标题是不是我们想要的。
2、测试下拉框
可以看到,我们可以使用 select 方法来确定选择下拉框中的哪个选项。
select 方法还有很多用法,具体去看看文档吧。
3、测试check box
java 代码
我们可以使用 check 方法来确定选择哪个radio button
4、得到文本框里的文字
getValue 方法就是得到文本框里的数值,可不是 getText 方法,用错了可就郁闷了。
5、判断页面是否存在一个元素
一般这个是用来测试当删除一些数据后,页面上有些东西就不会显示的情况。
6、判断下拉框里选择了哪个选项
这个可以用来判断下拉框显示的选项是否是期望的选项。
7、如果有 alert 弹出对话框怎么办?
这个问题弄了挺长时间,可以这样来关闭弹出的对跨框:
其实当调用 selenium.getAlert() 时,就会关闭 alert 弹出的对话框。
也可以使用 System.out.println(selenium.getAlert()) 来查看对跨框显示的信息。
在测试的时候,有的人会显示许多alert 来查看运行时的数据,那么我们可以用下面的方式来关闭那些 alert:
8、如何测试一些错误消息的显示?
切记: getBodyText 返回的时浏览器页面上的文字,不回包含html 代码的,如果要显示html 代码,用下面这个:
- System.out.println(selenium.getHtmlSource());
以上就是最常用的几个方法了,例如 click, type, getValue 等等。
还有就是一定要学习 xpath, 其实xpath 也可以有“与、或、非”的操作:
四、其他
selenium 还有更多的用法,例如弹出页面等等。当面对没见过的测试要求时,我最笨的方法就是按照api文档一个一个找,
好在不多,肯定能找到。
------------------------------------------------------------------------------------------
Selenium是thoughtworks公司的一个集成测试的强大工具,关于它的好处网络随处可以搜到,我就不一一介绍,在之前见到一个系列是Selenium Remote Control For Java,在这里模仿一下,主要以Python来实现。一是我比较喜欢用Python,二是刚好可以练手,熟悉熟悉Python开发Selenium RC脚本。
What is Selenium?
Selenium is a testing tool for web applications that uses JavaScript and Iframes to run tests directly in a browser. There are several test tools based on this technology: Selenium Core, Selenium IDE, Selenium Remote Control, and Selenium on Rails.
下面的是第一个例子:
在http://www.bitmotif.com/上点击link=Test Page For Selenium Remote Control,检查新页面的标题

 代码
代码
import unittest
class ExampleTest(unittest.TestCase):
MAX_WAIT_TIME_IN_MS = 60000
BASE_URL = "http://www.bitmotif.com"
def setUp(self):
self.verificationErrors = []
self.selenium = selenium("localhost", 4444, "*firefox3 E:/Program Files/Mozilla Firefox/firefox.exe", self.BASE_URL)
self.selenium.start()
def tearDown(self):
self.selenium.stop()
def testClinckinglink(self):
sel = self.selenium
sel.open(self.BASE_URL)
sel.click("link=Test Page For Selenium Remote Control")
sel.wait_for_page_to_load(self.MAX_WAIT_TIME_IN_MS)
expectedTitle = u"Test Page For Selenium Remote Control « Bit Motif"
#sel.get_title()
self.assertEquals(expectedTitle, sel.get_title())
if __name__ == '__main__':
unittest.main()
-----------------------------------------------------------------------------------------
Use Python to Drive Selenium RC(转)
上一篇 / 下一篇 2010-02-25 10:13:35 / 个人分类:应用配置
转自:http://www.cnblogs.com/oscarxie/archive/2008/07/20/1247004.html
Selenium RC支持多种编程语言驱动客户端浏览器,这里主要介绍使用Python在Windows下驱动Selenium RC。Python是一种面向对象的解释性的计算机程序设计语言。
1、准备工作:
下载Java:目前是1.6 update7,下载地址:http://www.java.com/zh_CN/
下载Python:目前稳定版本为2.5.2,下载地址:http://www.python.org/download/,Python的相关信息参见:http://www.python.org/
下载Selenium RC:目前是1.0 Beta1版本,下载地址:http://selenium-rc.openqa.org/download.html,Selenium RC相关信息参见:http://selenium-rc.openqa.org/
2、开始运行
- 首先启动Selenium Server,把下载的Selenium RC解压后,会有一个selenium-server-1.0-beta-1的文件夹,就是Selenium Server的存放目录,通过命令行Java -jar selenium-server.jar来启动Selenium Server端的服务,
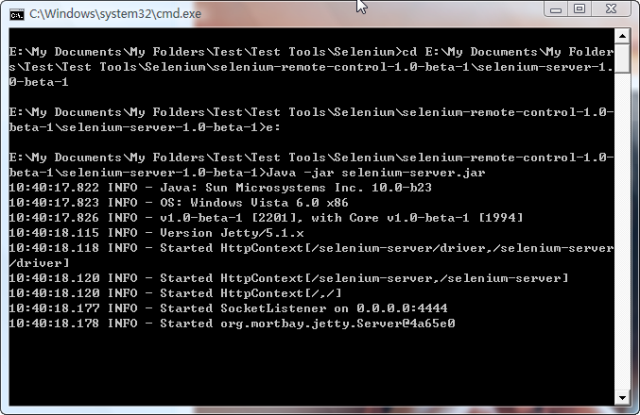
- 以在Google上搜索Hello World为例,Python的脚本如下:
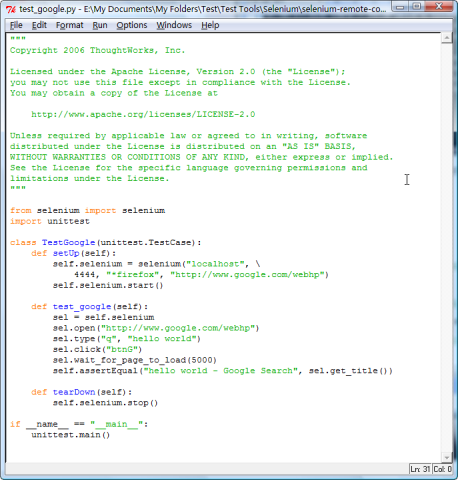
"*firefox"是指支持的浏览器或是通过Selenium RC调用的浏览器,Selenium支持以下的浏览器类型,
Supported browsers include:
*iexplore
*konqueror
*firefox
*mock
*pifirefox
*piiexplore
*chrome
*safari
*opera
*iehta
*custom
在这里,仅使用*iexplore或*firefox则表示浏览器安装在默认的路径,即IE安装在"C:\Program Files\Internet Explorer\iexplore.exe",Firefox安装在"C:\Program Files\Mozilla Firefox\firefox.exe"。如果不是安装在默认的路径,需要指明浏览器安装的地址,如:"*firefox D:\Program Files\Mozilla Firefox\\firefox.exe"。
"def tearDown(self):
self.selenium.stop()"
这段表示浏览器运行结束后直接关闭浏览器,这里可以注释掉。
- 首先,使用IE为浏览器运行一次,代码如下:
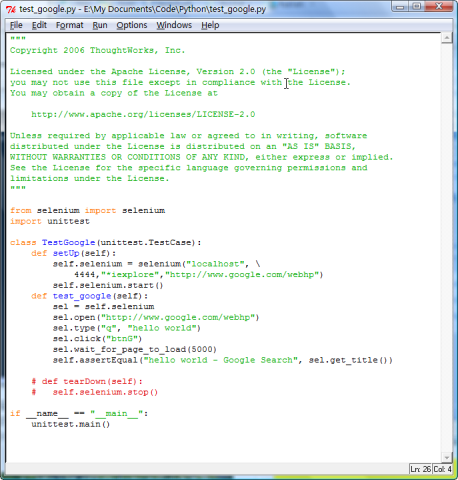
点击Python IDE上的Run菜单下拉中的Run Module或是快捷键F5,开始运行Python代码。通过Selenium直接调用IE浏览器进行客户端运行。
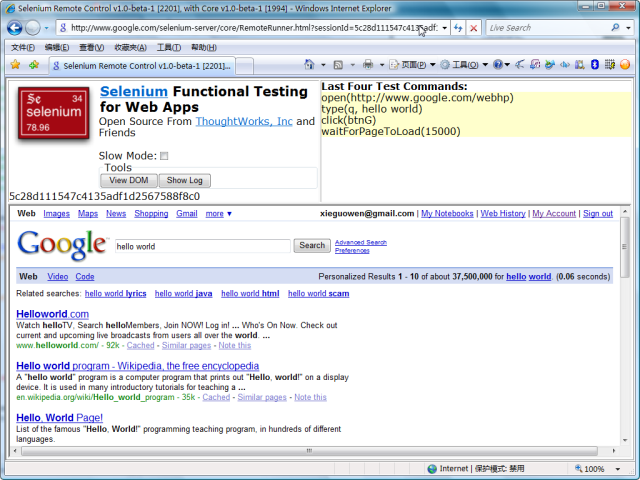
同时命令行窗口显示Selenium Server进行的每个步骤操作
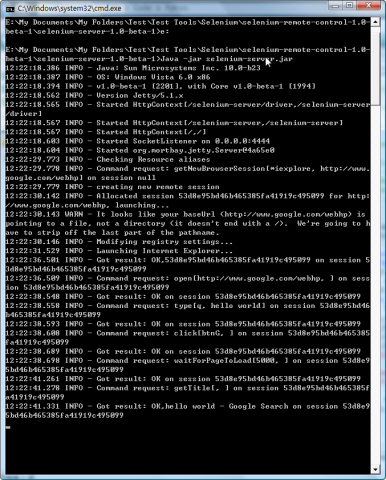
- 接下来使用Firefox作为浏览器进行访问
修改代码,*iexplore"修改为"*custom D:\Program Files\Mozilla Firefox\\firefox.exe",因为我电脑上的Firefox为3.0版本,目前Selenium RC不支持此版本,不管是使用"*chrome"还是"*firefox",都无法把Firefox调出;但是如果你机器上使用的Firefox是低于 3.0版本,那么可以直接使用"*chrome"这个参数。
在运行之前,需要将Firefox中的代理设置成和Selenium Server一致,Localhost,端口为4444。
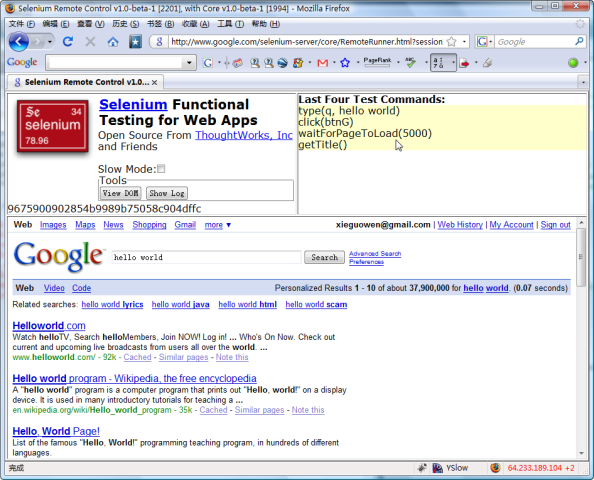
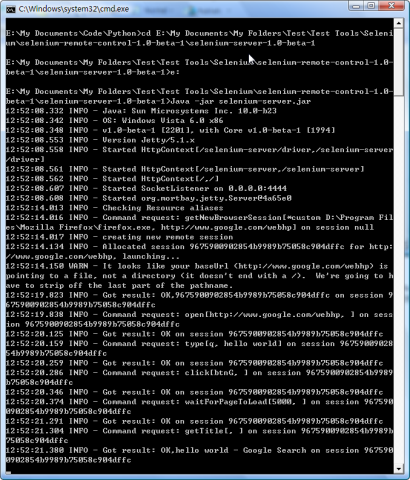
对于其他的浏览器只需要相应的修改参数为如*safari或*opera等,就能调用访问,实现一个多浏览器的兼容性测试。
其他相关文章:
Running Selenium in Python Driven Mode
http://agiletesting.blogspot.com/2006/01/running-s...
Web app testing with Python part 1: MaxQ
http://agiletesting.blogspot.com/2005/02/web-app-testing-with-python-part-1.html
Web app testing with Python part 2: Selenium and Twisted
http://agiletesting.blogspot.com/2005/03/web-app-testing-with-python-part-2.html
----------------------------------------------------------------------------------------------
Python中使用selenium作为Web Browser引擎
 Comments(9)
Comments(9) 由于目前的Web开发中AJAX、Javascript、CSS的大量使用,一些网站上的重要数据是由Ajax或Javascript动态生成的,并不能直接通过解析html页面内容就能获得(例如采用mechanize、lxml、Beautiful Soup )。要实现对这些页面数据的爬取,爬虫必须支持Javacript、DOM、HTML解析等一些浏览器html、javascript引擎的基本功能。
正如Web Browser Programming in Python总结的,在python程序中,有如下一些项目提供能类似功能:
其中Pyv8主要是Google Chrome V8 Javascript引擎的Python封装,侧重在Javacript操作上,并不是完整的Web Browser 引擎,而诸如PythonWebKit、Python-Spidermonkey、PyWebKitGtk等几个主要在Linux平台上比较方便,而HulaHop、Pamie处理MS IE 。因此从跨平台、跨浏览器、易用性等角度考虑,以上方案并不是最好的。
Selenium、Windmill 原本主要用于Web自动化测试上,对跨操作系统、跨浏览器有较好的支持。其对Javacript、DOM等操作的支持主要依赖操作系统本地的浏览器引擎来实现,因此爬虫所必须的大部分功能,Selenium、Windmill 都有较好的支持。在性能要求不高的情况下,可以考虑采用Selenium、Windmill的方案,从评价来看,Windmill比Selenium功能更加全面。
争取其他语言一些类似的软件还有:
1、应用场景
关于Selenium的详细说明,可以参考其文档, 这里使用Python+Selenium Remote Control (RC)+Firefox 来实现如下几个典型的功能:
1)、Screen Scraping,也即由程序自动将访问网页在浏览器内显示的图像保存为图片,类似那些digg站点的网页缩略图。Screen Scraping有分成两种:只Scraping当前浏览器页面可视区域网页的图片(例如google.com首页),Scraping当前浏览器完整页面的图片(页面有滚动,例如www.sina.com.cn的首页有多屏,需要完整保存下来)
2)、获取Javascript脚本生成的内容
例如要用程序自动爬取并下载百度新歌TOP100 的所有新歌,以下载萧亚轩的《抱紧你》为例,大致步骤可以如下:
a)、进入百度新歌TOP100http://list.mp3.baidu.com/top/top100.html,通过正则表达式匹配<a target=”_blank” href=”http://mp3.baidu.com/m?(.*)” class=”search”></a> 或采用mechanize、Beautiful Soup之类的htmlparser解析页面获得每一首歌后面的查询地址
b)、在查询结果页面,获得第一条结果的地址<a href=”http://202.108.23.172(.*)” title=”(.*)</a>,进入mp3的实际下载地址
c)、在歌曲实际下载页面,解析html页面内容,会发现mp3的实际现在地址为空
<a id="urla" href="" onmousedown="sd(event,0)" target="_blank"></a>
实际的下载地址是由javascript脚本设置的:
var encurl = "…", newurl = "";
var urln_obj = G("urln"), urla_obj = G("urla");
newurl = decode(encurl);
urln_obj.href = urla_obj.href = song_1287289709 = newurl;
其中函数G(str)为:
function G(str){
return document.getElementById(str);
};
因此直接解析页面并不能获得下载地址,必须通过python调用浏览器引擎来解析javascript代码后获得对应的下载地址。
2、Selenium RC基础
Selenium RC的运行机制及架构在官方文档中有详细说明。
Selenium RC主要包括两部分:Selenium Server、Client Libraries,其中:
- The Selenium Server which launches and kills browsers, interprets and runs the Selenese commands passed from the test program, and acts as an HTTP proxy, intercepting and verifying HTTP messages passed between the browser and the AUT.
Selenium Server 对应Selenium RC 开发包中的selenium-server-xx目录,其中
xx对应相应的版本
- Client libraries which provide the interface between each programming language and the Selenium-RC Server.
Selenium RC提供了包括java、python、ruby、perl、.net、php等语言的client driver,分别如下:
selenium-dotnet-client-driver-xx
selenium-java-client-driver-xx
selenium-perl-client-driver-xx
selenium-php-client-driver-xx
selenium-python-client-driver-xx
selenium-ruby-client-driver-xx

Python等语言通过调用client driver来发出浏览器操作指令(例如打开制定url),由client driver把指令传递给Selenium Server解析。Selenium Server负责接收、解析、执行客户端执行的Selenium 指令,转换成各种浏览器的命令,然后调用相应的浏览器API来完成实际的浏览器操作。
Selenium Server实际充当了客户端程序与浏览器间http proxy。
3、例子:
1)、下载Selenium RC http://seleniumhq.org/download/,测试使用的selenium-remote-control-1.0.3.zip
2)、解压后selenium-remote-control-1.0.3.zip
3)、运行Selenium Server
cd selenium-remote-control-1.0.3\selenium-server-1.0.3
java -jar selenium-server.jar
Selenium Server缺省监听端口为4444,在org.openqa.selenium.server.RemoteControlConfiguration中设定
4)、测试代码
#coding=gbk
from selenium import selenium
def selenium_init(browser,url,para):
sel = selenium('localhost', 4444, browser, url)
sel.start()
sel.open(para)
sel.set_timeout(60000)
sel.window_focus()
sel.window_maximize()
return sel
def selenium_capture_screenshot(sel):
sel.capture_screenshot("d:\\singlescreen.png")
def selenium_get_value(sel):
innertext=sel.get_eval("this.browserbot.getCurrentWindow().document.getElementById('urla').innerHTML")
url=sel.get_eval("this.browserbot.getCurrentWindow().document.getElementById('urla').href")
print("The innerHTML is :"+innertext+"\n")
print("The url is :"+url+"\n")
def selenium_capture_entire_page_screenshot(sel):
sel.capture_entire_page_screenshot("d:\\entirepage.png", "background=#CCFFDD")
if __name__ =="__main__" :
sel1=selenium_init('*firefox3','http://202.108.23.172','/m?word=mp3,http://www.slyizu.com/mymusic/VnV5WXtqXHxiV3ZrWnpnXXdrWHhrW3h9VnRkWXZtXHp1V3loWnlrXXZlMw$$.mp3,,[%B1%A7%BD%F4%C4%E3+%CF%F4%D1%C7%D0%F9]&ct=134217728&tn=baidusg,%B1%A7%BD%F4%C4%E3%20%20&si=%B1%A7%BD%F4%C4%E3;;%CF%F4%D1%C7%D0%F9;;0;;0&lm=16777216&sgid=1')
selenium_get_value(sel1)
selenium_capture_screenshot(sel1)
sel1.stop()
sel2=selenium_init('*firefox3','http://www.sina.com.cn','/')
selenium_capture_entire_page_screenshot(sel2)
sel2.stop()
几点注意事项:
1)、在selenium-remote-control-1.0.3/selenium-python-client-driver-1.0.1/doc/selenium.selenium-class.html 中对Selenium支持的各种命令的说明,值得花点时间看看
2)、在__init__(self, host, port, browserStartCommand, browserURL) 中,browserStartCommand为使用的浏览器,目前Selenium支持的浏览器对应参数如下:
*firefox
*mock
*firefoxproxy
*pifirefox
*chrome
*iexploreproxy
*iexplore
*firefox3
*safariproxy
*googlechrome
*konqueror
*firefox2
*safari
*piiexplore
*firefoxchrome
*opera
*iehta
*custom
3)、capture_entire_page_screenshot目前只支持firefox、IE
使用firefox时候使用capture_entire_page_screenshot比较简单,不需要特别设置,Selenium会自动处理。因此如果使用capture_entire_page_screenshot推荐使用firefox。
IE必须运行在非HTA(non-HTA)模式下(browserStartCommand值为:*iexploreproxy ),并且需要安装http://snapsie.sourceforge.net/ 工具包,具体可以参考这篇文章:Using captureEntirePageScreenshot with Selenium
--------------------------------------------------------------------------------------------
Getting Started with Selenium and Python
Tags:| Pylons, Python, Web |
I thought I'd have a look at Selenium today. Here I my notes from my first outing.
Selenium
Selenium is a funcitonal testing framework which automates the browser to perform certain operations which in turn test the underlying actions of your code. It comes in a number of different versions:
Available Components
Selenium Core
The core HTML and JavaScript files which you can install on your server to program Selenium directly. No-one really uses these.
Selenium IDE
A firefox plugin which embeds Selenium Core into Firefox so that you don't need to install it on your server. It also provides a nice GUI for recording and re-playing tests as well as exporting them as Python code (and other formats) so that they can be used with Selenium RC
Selenium RC (Remote Control)
This is a server which can be controlled (via HTTP as it happens) to send Seleium commands to the browser. This effectively allows you to control a browser remotely from your ordinary Python test suite. The RC server also bundles Selenium Core, and automatically loads it into the browser.
Selenium Grid
This allows you to run your Selenium tests on multiple different browsers in parallel.
We will use Selenium IDE with Firefox and Selenium RC.
Selenium IDE
Now would be a great time to watch the introductory video at http://seleniumhq.org to understand how Selenium IDE works. It is only a minute or two long and exaplins how everything works with a demo much better than I could with words.
Now you've seen the video its time to create and run your own test. Here's what you need to do:
- Download and install Selenium IDE from http://seleniumhq.org/download/ It is a .xpi file which will be installed as a Friefox plugin.
- Start the IDE by clicking Tools -> Selenium IDE from the menu.
- Recording will have started automatically so perform some actions. For this first example, try searching for something in Google, follow a link and then perform some more actions on the site you arrive at. Then press the record button to stop.
- Press the play all tests button to see the actions re-performed
- Choose Options->Format->Python to see a Selenium RC test suite written in Python which will re-perform those actions. Save the Test Case as First Test and save the Python as first_test.py
Although the Selenium IDE you've just used to record your tests only works in Firefox, the tests it produces can be used with Selenium RC to run tests in most modern JavaScript browsers.
Selenium RC
The Selenium RC server is written in Java even though it can be controlled from many languages. To run it you will need a recent version of Java installed. Here's how to install it on Debian/Ubuntu:
sudo apt-get install openjdk-6-jdk
Now download the latest version from http://seleniumhq.org/download/ and run these commands to install it:
unzip selenium-remote-control-1.0-beta-2-dist.zip
cd selenium-remote-control-1.0-beta-2
cd selenium-server-1.0-beta-2
java -jar selenium-server.jar
The options for the server are documented at: http://seleniumhq.org/documentation/remote-control/options.html
If you visit http://localhost:4444/selenium-server/tests/html/test_click_page1.html you'll see some of the tests. You can run these automatically with these commnads with the server still running:
cd selenium-remote-control-1.0-beta-2
cd selenium-python-client-driver-1.0-beta-2
python test_default_server.py
This will take a few seconds to load some browser windows and then output the following to show that the test passed:
Using selenium server at localhost:4444
.
----------------------------------------------------------------------
Ran 1 test in 18.695s
OK
There will be plenty of output on the Selenium RC server's console explaining what it is up to.
Now try running the script you saved earlier. You'll need to copy the selenium.py file from selenium-remote-control-1.0-beta-2/selenium-python-client-driver-1.0-beta-2 into the same directory as first_test.py and then run this:
python first_test.py
You'll see the following error output after 3 seconds:
E
======================================================================
ERROR: test_new (__main__.NewTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "first_test.py", line 12, in test_new
sel.open("/")
File "/home/james/Desktop/GRP/code/trunk/GRP/test/selenium.py", line 764, in open
self.do_command("open", [url,])
File "/home/james/Desktop/GRP/code/trunk/GRP/test/selenium.py", line 215, in do_command
raise Exception, data
Exception: Timed out after 30000ms
----------------------------------------------------------------------
Ran 1 test in 44.308s
FAILED (errors=1)
This is because you need to specify the URL where Selenium should start its testing. Ordinarily Selenium can't test across multiple domains so the domain you start at is the only one which can be testes. Selenium is able to work around this limitation in certain browsers such as Firefox and IE as you can read about at http://seleniumhq.org/documentation/remote-control/experimental.html
Since we are using Firefox Selenium RC can test multiple domains at once but it still needs to be given the URL to start at. Since the test you performed in the Selenium IDE section started at http://google.com you should change the URL http://change-this-to-the-site-you-are-testing/ to http://google.com in the code. If you run the test again you should see Selenium repeat all the actions and this time confirm the output was a success:
.
----------------------------------------------------------------------
Ran 1 test in 37.098s
OK
If you want to examine the windows which pop-up during the tests, just add these lines to the end of the test_new() method to make the test wait for 10 seconds after it has been run:
import time
time.sleep(10)
You can now remote control the browser from Python which means you can perform other tasks in-between the tests you are running. For example, you might want to remove all data from your test database before the tests are run.
To test your code in a different browser you would change this line:
self.selenium = selenium("localhost", 4444, "*chrome", "http://google.com/")
To something like this:
self.selenium = selenium(
"localhost",
4444,
"c:\\program files\\internet explorer\\iexplore.exe",
"http://google.com/"
)
Happy testing.
- Selenium Website:
- http://seleniumhq.org
- Python Documentation:
- http://release.seleniumhq.org/selenium-remote-control/1.0-beta-2/doc/python/
mechanize
Stateful programmatic web browsing in Python, after Andy Lester’s Perl module WWW::Mechanize.
-
mechanize.Browserandmechanize.UserAgentBaseimplement the interface ofurllib2.OpenerDirector, so:-
any URL can be opened, not just
http: -
mechanize.UserAgentBaseoffers easy dynamic configuration of user-agent features like protocol, cookie, redirection androbots.txthandling, without having to make a newOpenerDirectoreach time, e.g. by callingbuild_opener().
-
-
Easy HTML form filling.
-
Convenient link parsing and following.
-
Browser history (
.back()and.reload()methods). -
The
RefererHTTP header is added properly (optional). -
Automatic observance of
robots.txt. -
Automatic handling of HTTP-Equiv and Refresh.
让 Mechanize 也能 “跑”javascript
http://www.javaeye.com/topic/599446
Alternative Tools For Web Testing
http://wiki.openqa.org/display/WTR/Alternative+Tools+For+Web+Testing
在python中利用selenium实现提高的qq群的“参与值”,助推qq群快速升级
管理提醒: 本帖被 amxking 从 八卦趣闻{Hearsay} 移动到本区(2010-07-21)
在python中利用selenium实现提高的qq群的“参与值”,助推qq群快速升级!
2009年11月11日,QQ群等级正式推出,分为人气值、贡献值、参与值。其中人气值通过聊天就可以提高,贡献值主要通过上传文件可以提高,唯有参与制主要要通过回帖等方式来提高,比较难以提高。
qq群对一般的帖子都要输入字符串验证码,但是对“新人报到”的帖子没有这个要求,而且回帖产生的积分为 每日积分上限 20分,但是实际上可以达到40分(严重怀疑腾讯的测试水平,哈哈),为此可以简单的在python中利用selenium实现提高的qq群的“参与值”,助推qq群快速升级!步骤如下:
1,利用录制python脚本
录制好的脚本修改为如下:
#!/usr/bin/env python
# -*- coding: gbk -*-
#在python中利用selenium实现提高的qq群的“参与值”,助推qq群快速升级!
#gtalk: ouyangchongwu#gmail.com
from selenium import selenium
import unittest, time, re
class Untitled(unittest.TestCase):
def setUp(self):
self.verificationErrors = []
self.selenium = selenium("localhost", 4444, "*iexplore", "http://qun.qq.com/")
self.selenium.start()
def test_untitled(self):
sel = self.selenium
sel.open("/air/#66250781/bbs/view/cd/8/td/19")
for i in range(10):
sel.type("rePost", "welcome!")
sel.click(u"//input[@value='回复']")
def tearDown(self):
self.selenium.stop()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
2,启动selenium-server
3,运行python脚本
实际运行中要求你先登录群社区,当然这部分本身也可以集成到脚本中,在此不赘述。存在的问题有,在网速较慢的环境中,打开网页可能会超时,需要调整selenium的超时时间设置。另外也基本上没有做例外处理,腾讯的空间感觉稳定性还是很不好的。
#!/usr/bin/env python
# -*- coding: gbk -*-
from selenium import selenium
import unittest, time, re
class Untitled(unittest.TestCase):
def setUp(self):
self.verificationErrors = []
self.selenium = selenium("localhost", 4444, "*iexplore", "http://qun.qq.com/")
self.selenium.start()
def test_untitled(self):
sel = self.selenium
time.sleep(5)
sel.open("/air/#6089740/bbs/view/cd/7/td/3")
for i in range(40):
time.sleep(5)
sel.type("rePost", "welcome!")
sel.click(u"//input[@value='回复']")
def tearDown(self):
self.selenium.stop()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
本文来自: 红科网安官方网络安全论坛 http://bbs.honkwin.com

