

在kettle使用循环来处理表中的数据
有时候,如果kettle事务中源表的数据非常大的时候,一下子把源表中的数据全部读入内存的方式是不可取的。在mysql中,我们可以通过循环的方式,使用limit来定量取得一部分数据来处理。即,关键的sql是:select * from table_name limit current_value, step_value; 以下做一个思路演示。
1:取得记录中的所有的数量,初始化当前循环值等;
2:循环的判断条件是:当前的循环值小于最大的循环值
2.1:修改sql语句中查询的起始值
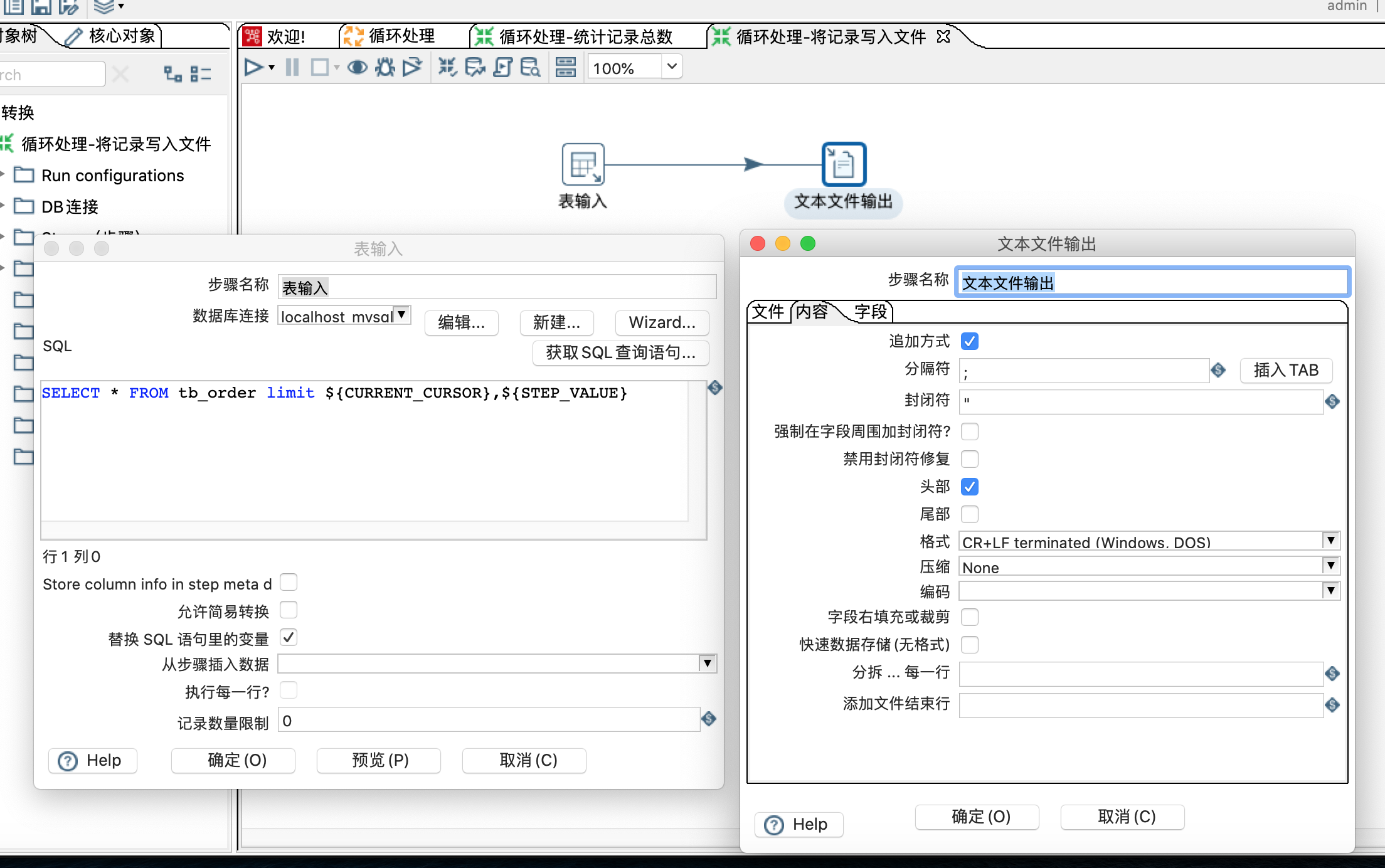
2.2:用一个转换来处理查询结果,这个例子是将结果追加到文件中;
2.3:将当前的循环值加1;
顶层job的配置

第1步的配置信息
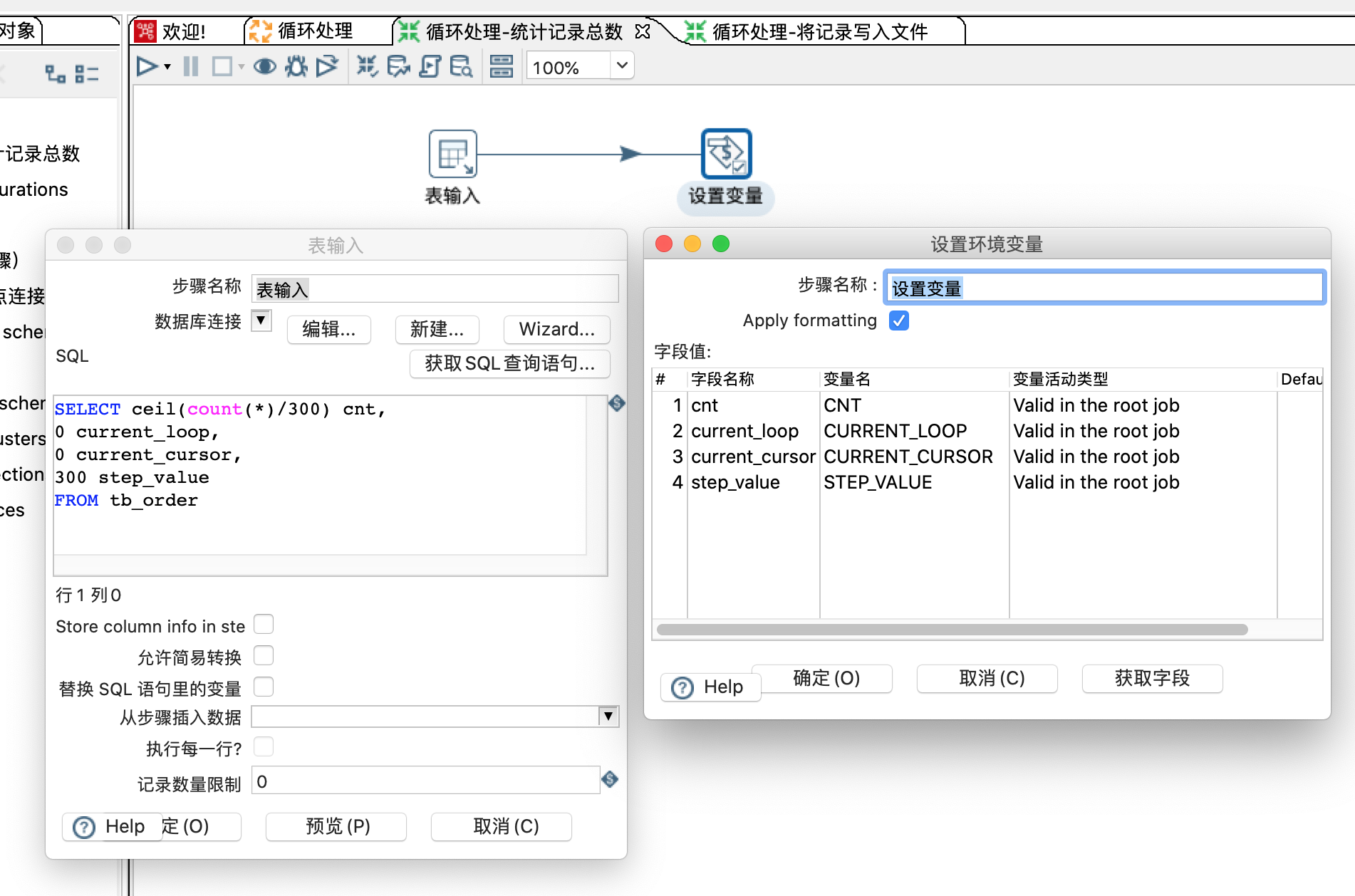
第2步的配置信息
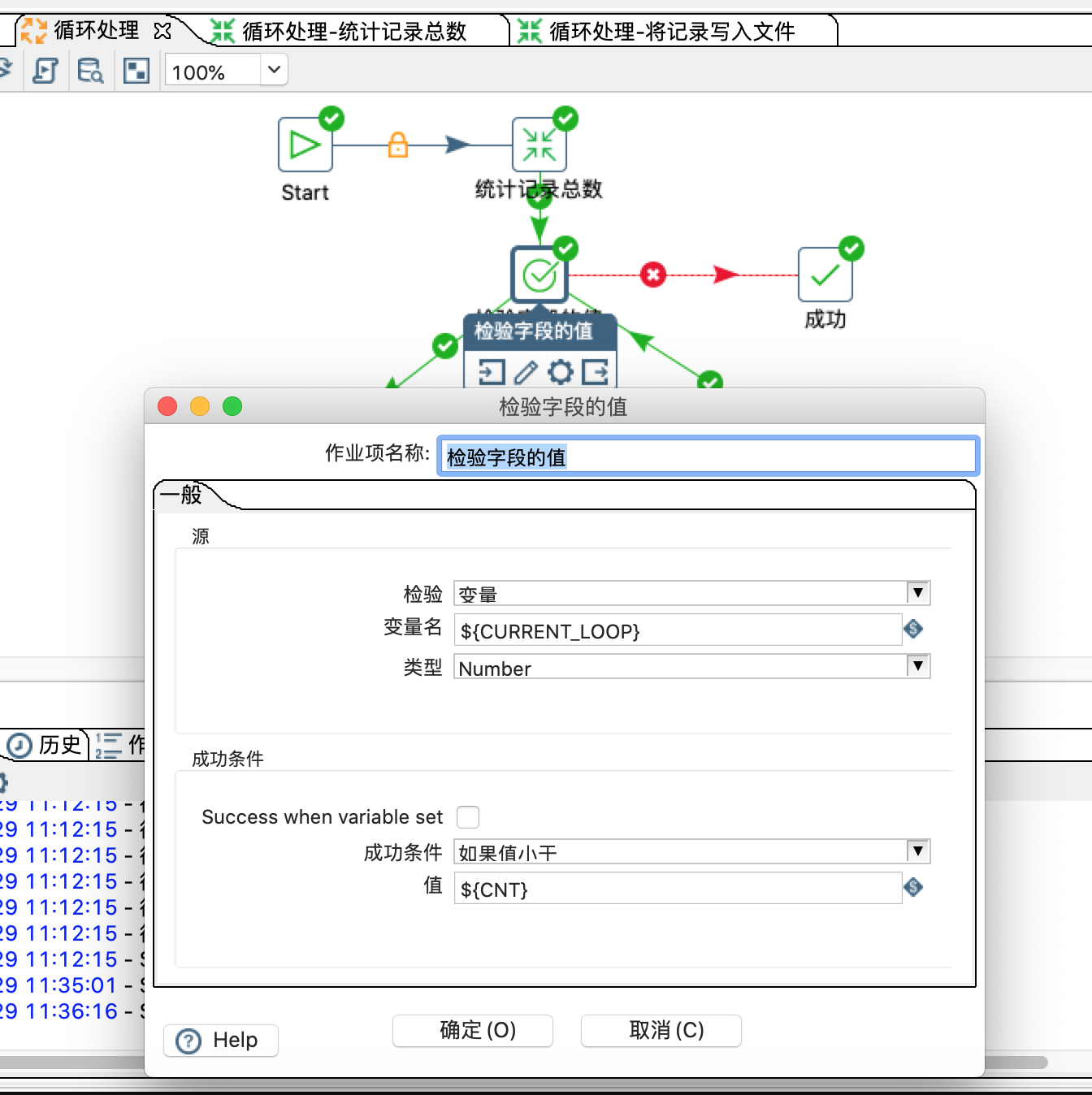
第2.1步的配置信息
var stepValue = new Number(parent_job.getVariable("STEP_VALUE"));
var i = new Number(parent_job.getVariable("CURRENT_LOOP"))*stepValue;
parent_job.setVariable("CURRENT_CURSOR",i);
true;
第2.2步的配置信息
第2.3步的配置信息
var i = new Number(parent_job.getVariable("CURRENT_LOOP"))+1;
parent_job.setVariable("CURRENT_LOOP",i);
true;

