

mysql日常及优化
字段
1.尽量使用 TINYINT、 SMALLINT、 MEDIUM_INT 作为整数类型而非 INT,如果非负则加上 UNSIGNED 2.VARCHAR 的长度只分配真正需要的空间 3.使用枚举或整数代替字符串类型 4.尽量使用 TIMESTAMP 而非 DATETIME 5.单表不要有太多字段,建议在 20 以内 6.避免使用 NULL 字段,很难查询优化且占用额外索引空间 7.用整型来存 IP
索引

1.索引并不是越多越好,要根据查询有针对性的创建,考虑在 WHERE 和 ORDER BY 2.命令上涉及的列建立索引,可根据 EXPLAIN 来查看是否用了索引还是全表扫描 3.应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描 4.值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段 5.字符字段只建前缀索引 6.字符字段最好不要做主键 7.不用外键,由程序保证约束 8.尽量不用 UNIQUE,由程序保证约束 9.使用多列索引时主意顺序和查询条件保持一致,同时删除不必要的单列索引
查询
1.可通过开启慢查询日志来找出较慢的 SQL 2.不做列运算: SELECT id WHERE age+1=10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边 3.sql 语句尽可能简单:一条 sql 只能在一个 cpu 运算;大语句拆小语句,减少锁时间;一条大sql 可以堵死整个库 4.不用 SELECT * 5.OR 改写成 IN: OR 的效率是 n 级别, IN 的效率是 log(n) 级别,IN 的个数建议控制在 200 以内 6.不用函数和触发器,在应用程序实现 7.避免 %xxx 式查询 8.少用 JOIN 9.使用同类型进行比较,比如用 '123' 和 '123' 比, 123 和 123 比 10.尽量避免在 WHERE 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描 11.对于连续数值,使用 BETWEEN 不用 IN: SELECT id FROM t WHERE num BETWEEN 1 AND 5 12.列表数据不要拿全表,要使用 LIMIT 来分页,每页数量也不要太大
引擎
MyISAM
1.不支持行锁,读取时对需要读到的所有表加锁,写入时则对表加排它锁 2.不支持事务 3.不支持外键 4.不支持崩溃后的安全恢复 5.在表有读取查询的同时,支持往表中插入新纪录 6.支持 BLOB 和 TEXT 的前 500 个字符索引,支持全文索引 7.支持延迟更新索引,极大提升写入性能 8.对于不会进行修改的表,支持压缩表,极大减少磁盘空间占用
InnoDB
1.支持行锁,采用 MVCC 来支持高并发 2.支持事务 3.支持外键 4.支持崩溃后的安全恢复 5.不支持全文索引
总结:
MyISAM 适合 SELECT 密集型的表,而 InnoDB 适合 INSERT 和 UPDATE 密集型的表
测试工具
- sysbench:一个模块化,跨平台以及多线程的性能测试工具
- iibench-mysql:基于 Java 的 MySQL/Percona/MariaDB 索引进行插入性能测试工具
- tpcc-mysql:Percona 开发的 TPC-C 测试工具
分区
是一种简单的水平拆分,用户需要在建表的时候加上分区参数,对应用是透明的无需修改代码
分类
RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区
LIST 分区:类似于按 RANGE 分区,区别在于 LIST 分区是基于列值匹配一个离散值集合中的某个值来进行选择
HASH 分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含 MySQL 中有效的、产生非负整数值的任何表达式
KEY 分区:类似于按 HASH 分区,区别在于 KEY 分区只支持计算一列或多列,且 MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值
应用场景:
时间序列性比较强,则可以按时间来分区
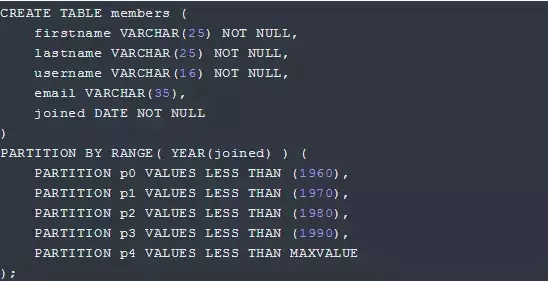
查询时加上时间范围条件效率会非常高,同时对于不需要的历史数据能很容的批量删除
垂直拆分
垂直分库是根据数据库里面的数据表的相关性进行拆分
把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联
水平拆分
水平拆分是通过某种策略将数据分片来存储,分库内分表和分库两部分,每片数据会分散到不同的 MySQL 表或库,达到分布式的效果,能够支持非常大的数据量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)