

python工具——jieba
jieba 是目前最好的 Python 中文分词组件
1.安装
pip install jieba
2.简单使用
支持3 种分词模式:
精确模式
import jieba seg_list = jieba.cut("再回首恍然如梦,再回首我心依旧", cut_all=False) print("【精确模式】:" + "/ ".join(seg_list))

全模式
import jieba seg_list = jieba.cut("再回首恍然如梦,再回首我心依旧", cut_all=True) print("【全模式】:" + "/ ".join(seg_list))

搜索引擎模式
import jieba seg_list = jieba.cut_for_search("再回首恍然如梦,再回首我心依旧") print("【搜索引擎模式】:" + "/ ".join(seg_list))

说明:
使用 jieba.cut 和 jieba.cut_for_search 方法进行分词,所返回的都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语
使用 jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
import jieba seg_list = jieba.lcut("再回首恍然如梦,再回首我心依旧", cut_all=True) print("【返回列表】:{0}".format(seg_list))

import jieba seg_list = jieba.lcut_for_search("再回首恍然如梦,再回首我心依旧") print("【返回列表】:{0}".format(seg_list))

3.关键词提取
基于TF-IDF
import jieba import jieba.analyse as anls s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。" for x, w in anls.extract_tags(s, topK=20, withWeight=True): print('%s %s' % (x, w))
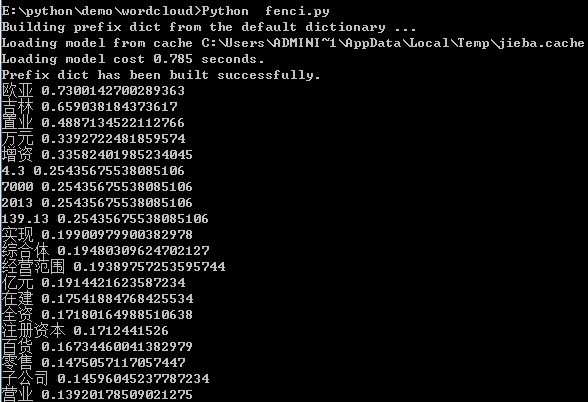
基于TextRank
import jieba import jieba.analyse as anls s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。" for x, w in anls.textrank(s, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'n')): print('%s %s' % (x, w))
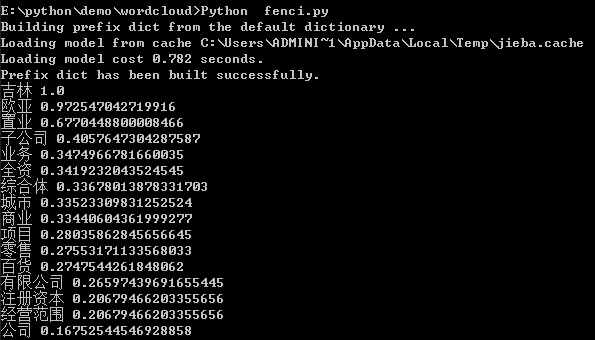
4.词语在原文的起止位置
import jieba result = jieba.tokenize(u'再回首恍然如梦,再回首我心依旧') print("【普通模式】") for tk in result: print("word: {0} \t\t start: {1} \t\t end: {2}".format(tk[0],tk[1],tk[2]))
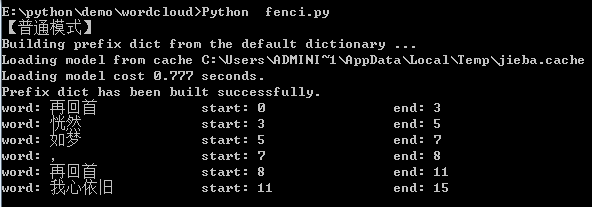
import jieba result = jieba.tokenize(u'再回首恍然如梦,再回首我心依旧', mode='search') print("【搜索模式】") for tk in result: print("word: {0} \t\t start: {1} \t\t end: {2}".format(tk[0],tk[1],tk[2]))
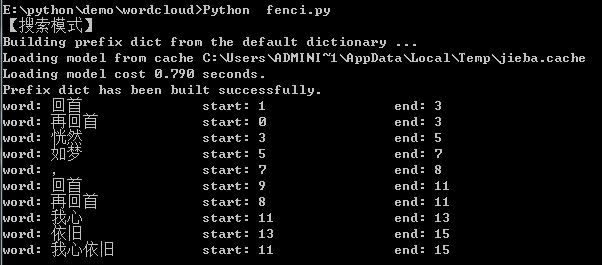
https://gitee.com/babybeibeili/python-tool/tree/master/wordcloud


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)