

kibana使用
1.下载
地址 https://www.elastic.co/cn/downloads/kibana
2.启动
解压,进入bin目录,执行
kibana
浏览器打开http://localhost:5601
3.使用
(1)插入两条数据
curl -XPOST 'localhost:9200/store/category/1?pretty' -H 'Content-type:application/json' -d'{"name":"soap","type":"cleaning","postDate":"2019-9-15","message":"this is a first data"}'
curl -XPOST 'localhost:9200/store/category/2?pretty' -H 'Content-type:application/json' -d'{"name":"soap1","type":"cleaning","postDate":"2019-9-15","message":"this is a second data"}'
A.建立所以
在kibana界面建立一个索引,和elaticsearch建立的索引进行配对
kibana中的management管理
单击index patterns索引模块
选择create index pattern模块,建立索引
注:
建立的索引名要和elasticsearch建立的索引对应,否则,无法创建kibana的索引

B.查看
索引建立完成后,点击【Discover】,选择建立的索引,查看数据
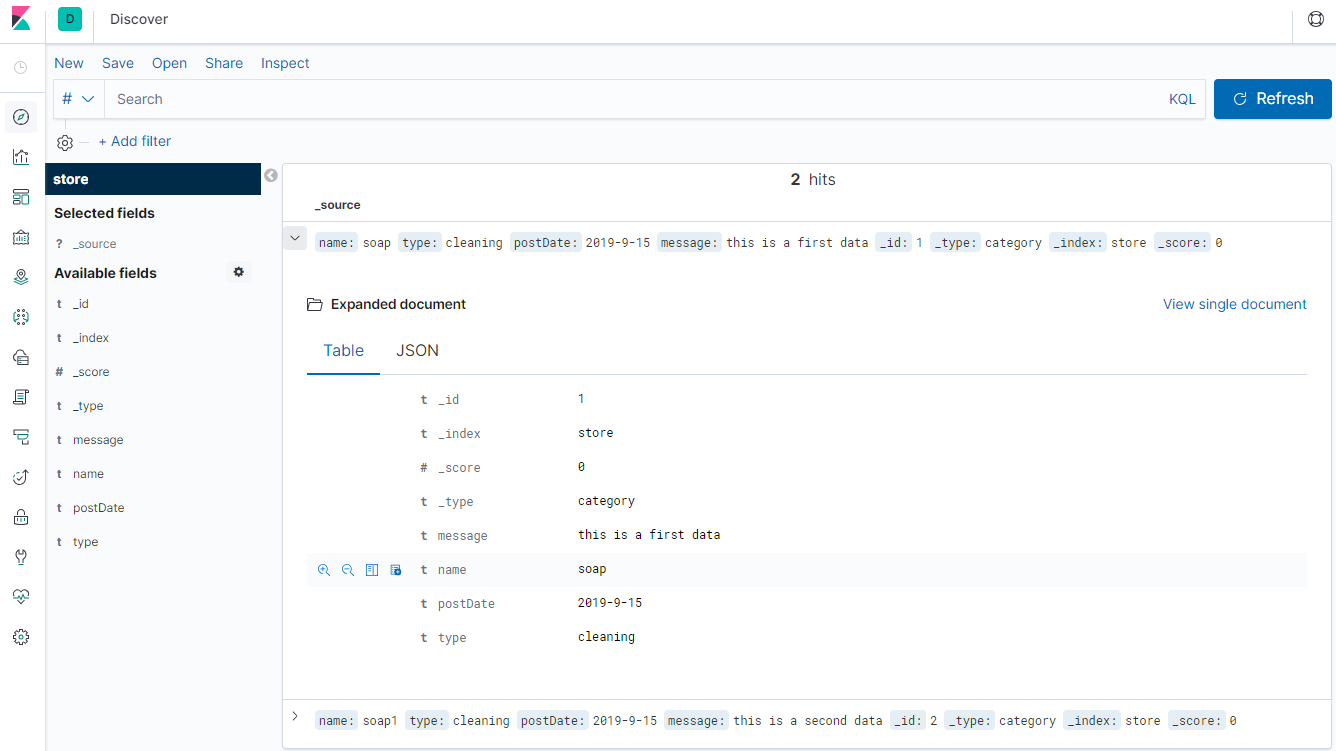
数据太少,没办法充分发挥Kibana的作用,很多高级的数据分析和图形化界面都没法展示出来,所以需要导入一些测试数据到Elasticsearch中
(2)导入数据
数据 https://pan.baidu.com/s/139UlJ2RcCOUwKunR6R0yDA
curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' -H 'Content-type:application/json' --data-binary @shakespeare.json
建立索引shakespeare,点击【Discover】菜单进行查看
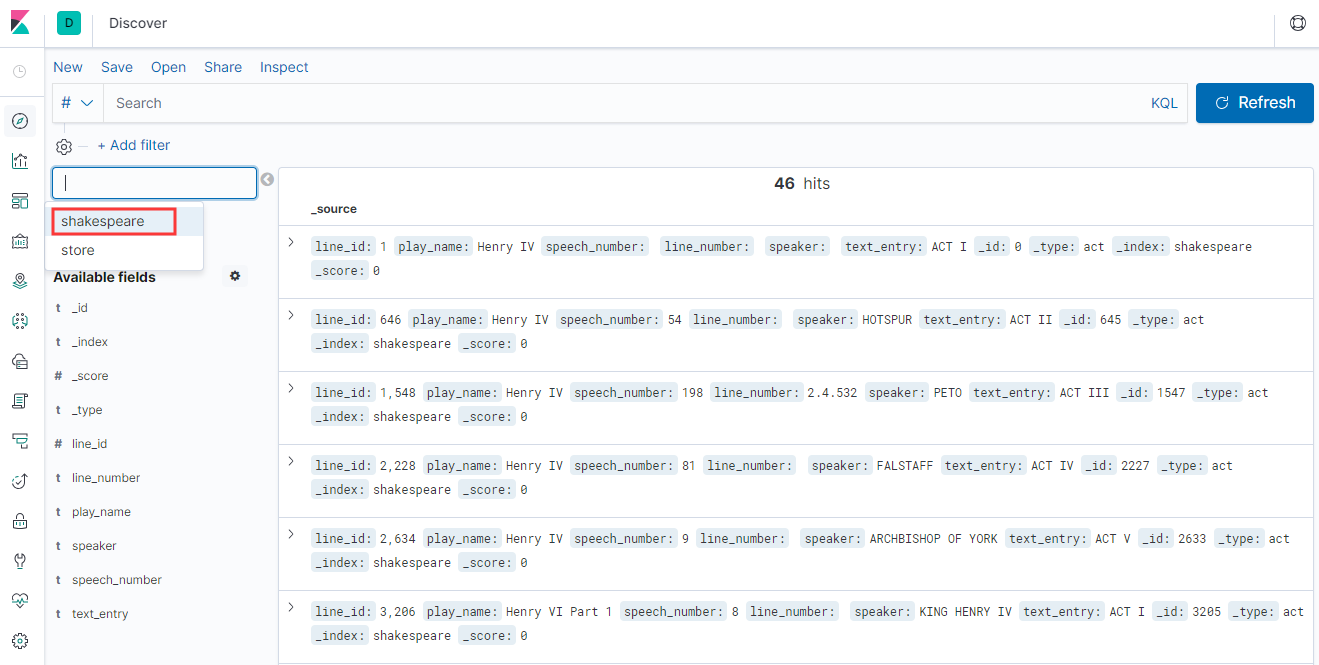
点击【Visualize】Create new visualization,选择折线图Line来展示 Shakespeare数据集并比较剧中的speaking发言部分数量
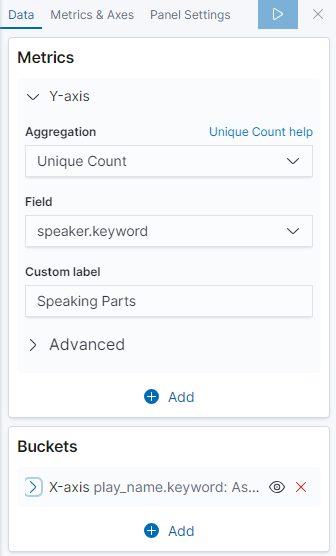
在“ Metrics”窗格中,展开“ Y-Axis”
将Aggregation聚合设置为Unique Count唯一计数
将Field字段设置为speaker.keyword发言
在“ Custom Label 自定义标签”框中,输入Speaking Parts
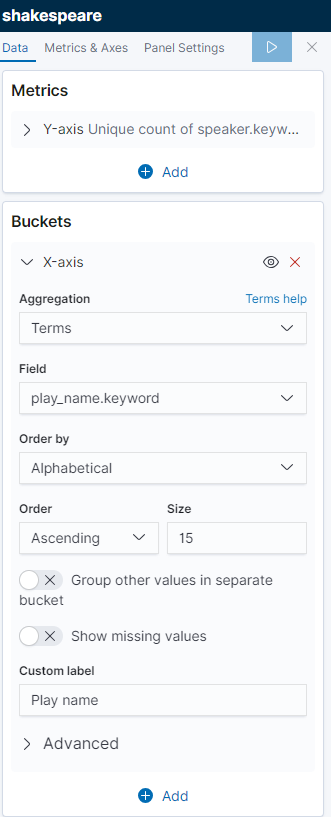
在“ Buckets”窗格中,单击“ X-Axis”
将Aggregation聚合设置为Terms条款和 Field字段为play_name.keyword
要按字母顺序列出表演,请在“ Order”下拉菜单中选择“ Ascending”
为轴提供自定义标签Play Name
单击Apply changes

有多种图表可供选择
注:
Kibana 的版本需要和 Elasticsearch 的版本一致,否则会出现Kibana server is not ready yet


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)