

Zipkin+Sleuth 链路追踪整合
1.Zipkin
是一个开放源代码分布式的跟踪系统
它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示多少跟踪请求经过了哪些服务,该系统让开发者可通过一个web前端轻松地收集和分析数据,可非常方便的监测系统中存在的瓶颈
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch
生产数据量大的情况则推荐使用Elasticsearch
2.Spring Cloud Sleuth
为服务之间的调用提供链路追踪,通过使用Sleuth可以让我们快速定位某个服务的问题
分布式服务追踪系统包括:数据收集、数据存储、数据展示
通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台不太方便查看
Sleuth和Zipkin结合,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin UI来展示信息
1.使用curl下载
curl -sSL https://zipkin.io/quickstart.sh | bash -s
下载了文件zipkin-server-2.19.1-exec.jar
2.启动服务
java -jar zipkin-server-2.19.1-exec.jar

通过http://localhost:9411可访问zipkin的监控页面
因为还没有客户端,所以还没有数据
默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据,可以使用es进行持久化存储
3.应用
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
spring-cloud-dependencies

<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Finchley.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
配置
spring.application.name=demo spring.zipkin.base-url=http://localhost:9411 spring.sleuth.sampler.probability=1.0
样本采集量,默认为0.1,为了测试修改为1,正式环境一般使用默认值
package com.example.demo.controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class Demo { @RequestMapping("hello") public String hello() { return "Hello World!"; } }
运行示例,在postman里执行http://localhost:8080/hello
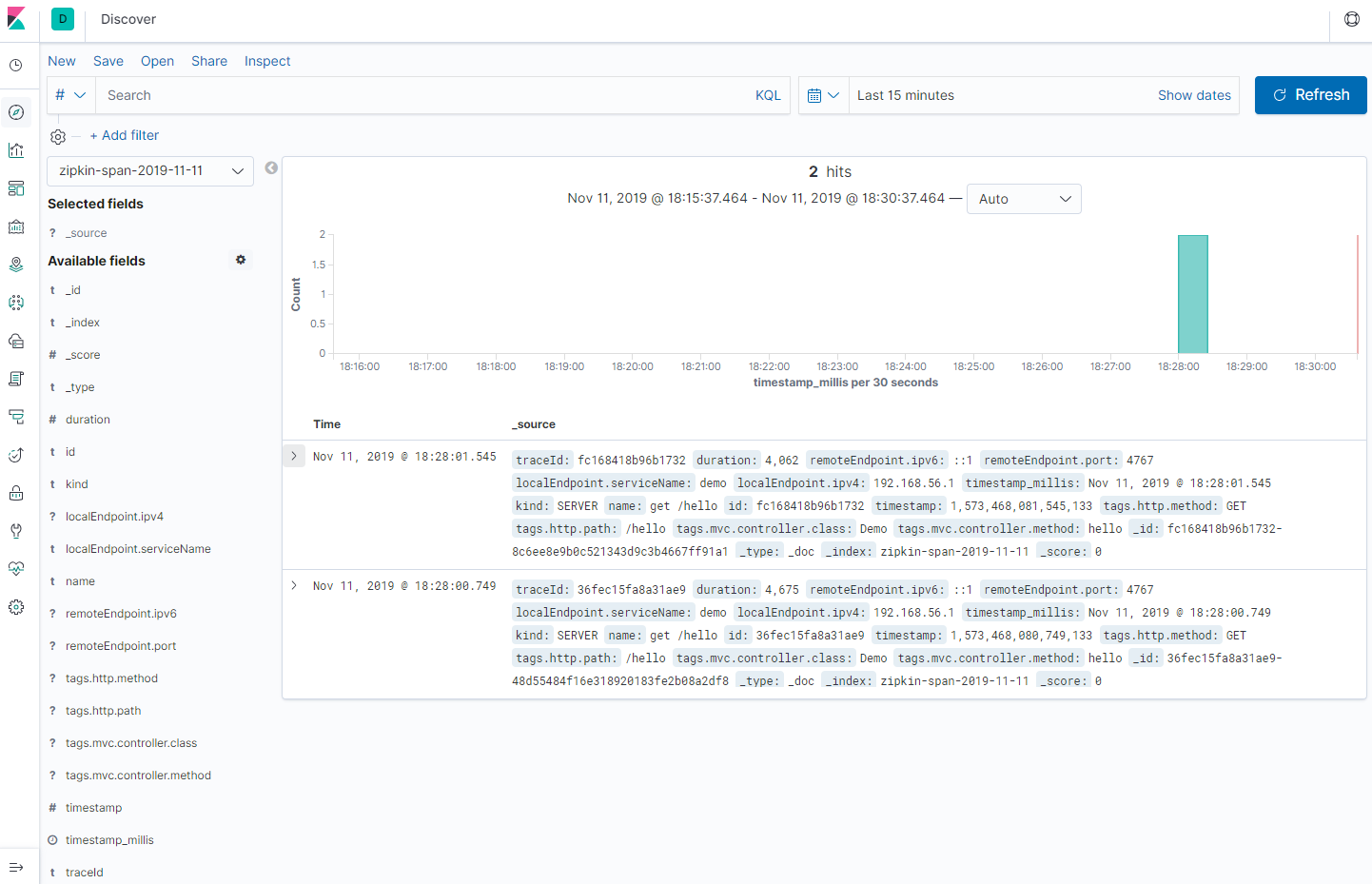
再查看http://localhost:9411,出现了刚刚访问的服务,选择并点击追踪
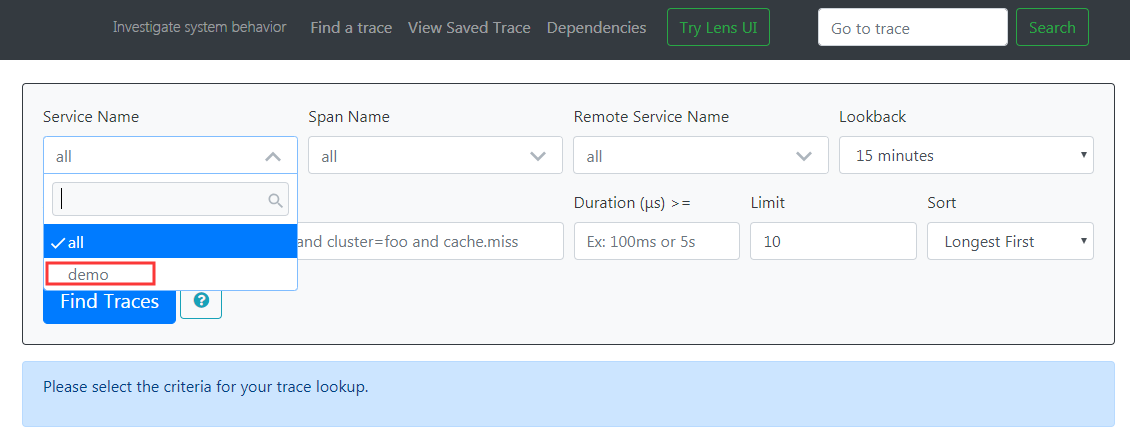
选择demo服务,点击Find Traces
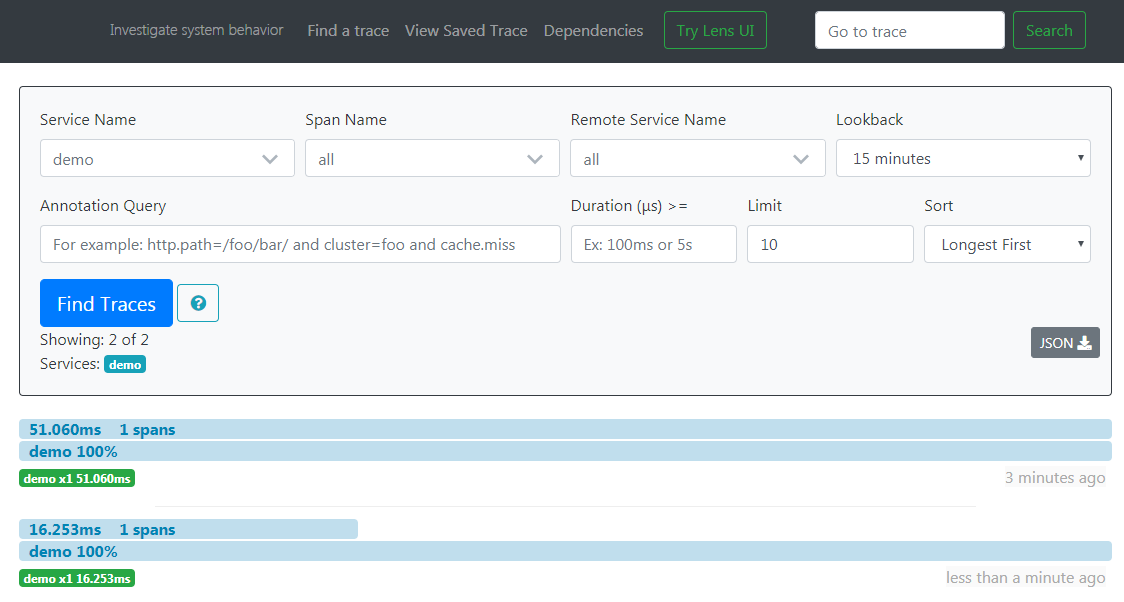
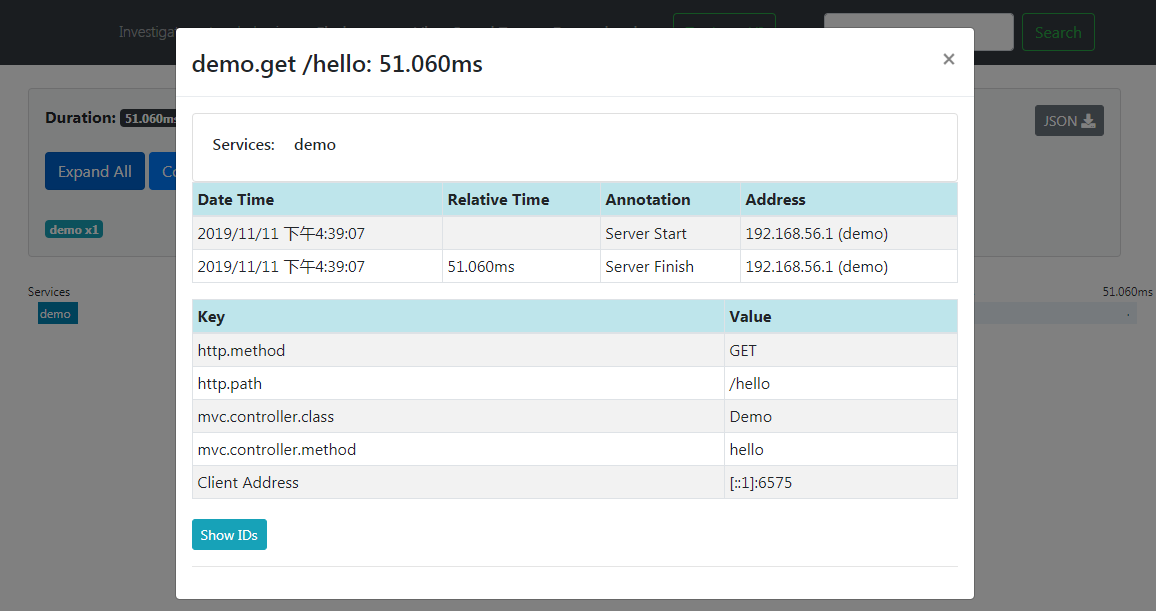
点击调用记录查看详情页面,可以看到每一个服务所耗费的时间和顺序
3.通过ElasticSearch进行存储
ElasticSearch安装启动(安装说明)
zipkin服务启动命令改为
java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://localhost:9200 -jar zipkin-server-2.19.1-exec.jar
zipkin会在es中创建以zipkin开头日期结尾的index,并且默认以天为单位分割
使用kibana查看数据(kibana使用)


https://zipkin.io/pages/quickstart.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)