
GAN的前身——VAE模型原理
GAN的前身——VAE模型
今天跟大家说一说VAE模型相关的原理,首先我们从判别模型和生成模型定义开始说起:
判别式模型:已知观察变量X和隐含变量z,它对p(z|X)进行建模,它根据输入的观察变量X得到隐含变量z出现的可能性。
在图像模型中,比如根据原始图像推测图像具备的一些性质,例如根据数字图像推测数字的名称等等图像分类问题。
生成式模型:与判别式模型相反,它对p(X|z)进行建模,输入变量是隐含变量,输出是观察变量的概率。
在图像中,通常是输入图像具备的性质,输出是性质对应的图像。
生成式模型通常用于解决如下问题:
1.构建高维、复杂概率分布,2.数据缺失,3.多模态输出,4.真实输出模型,5.未来数据预测,等系列问题
VAE
在经典的自编码机中,编码网络把原始图像编码卷积成向量,解码网络则能够将向量解码成原始图像,通过使用尽可能多的图像来训练网络,如果保存了某张图像的编码向量,那么就能够随时用解码组建来重建该图像。
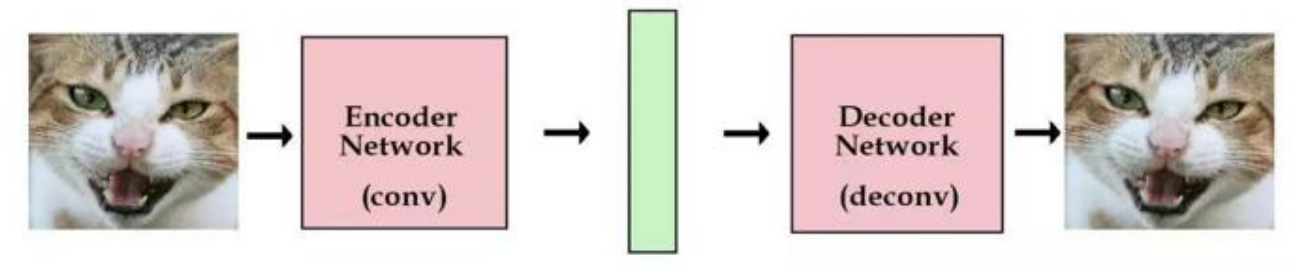
那么,问题就来了,潜在向量除了从已有图像中编码得到,能否凭空创造出这些潜在的向量来呢? 我们可以这样做,在编码网络中,增加一个约束,使得编码网络所生成的潜在向量大体上服从单位高斯分布。那么,解码器经过训练之后,能是能够解码服从单位高斯分布的解码器了,于是我们只需要从单位高斯分布中菜样出一个潜在向量,并将其传到解码器中即可。
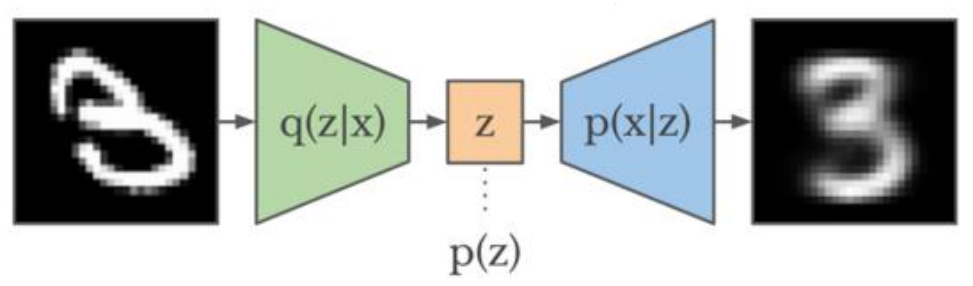
在VAE中,假定认为输入数据的数据集D(显示变量)的分布完全有一组隐变量z操控,而这组隐变量之间相互独立而且服从高斯分布,那么VAE让encoder去学习输入数据的隐变量模型,也就是去学习这组隐变量的高斯概率分布的参数均值和方差,而隐变量z就可以从这组分布参数的正态分布中采样得到z~N,再通过decoder对z隐变量进行解码来重构输入,本质上是实现了连续的,平滑的潜在空间表示。
对于目标函数,误差项精度与潜在变量在单位高斯分布上的契合程度,包括两部分的内容:1、生成误差,用以衡量网络在重构图像精度的均方误差,2、潜在误差,用以衡量潜在变量在单位高斯分布上契合程度的KL散度,总的目标函数如下:
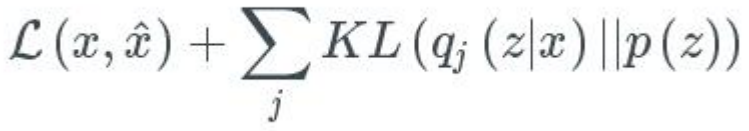
假设现在有一个样本集中两个概率分布p,q,其中p为真实分布,q为非真实分布,那么,按照真实分布p来衡量识别一个样本所需的编码长度的期望为:
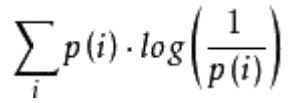
如果采用错误的分布q来表示来自真实分布p的平均编码长度,则应该是:

此时,就将H(p,q)称之为交叉熵。
对于KL散度,又称为相对熵,就是两个概率分布P和Q差别的非对称性度量。典型情况下,P表示数据的真实分布,Q表示数据的理论分布,那么D(P||Q)的计算如下:

KL散度不是对称的,并不满足距离的性质,即D(P||Q) != D(Q||P)。为了解决对称问题,我们引入JS散度。
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度的非对称的问题,一般的,JS散度是对称的,其取值是0到1之间,计算如下:
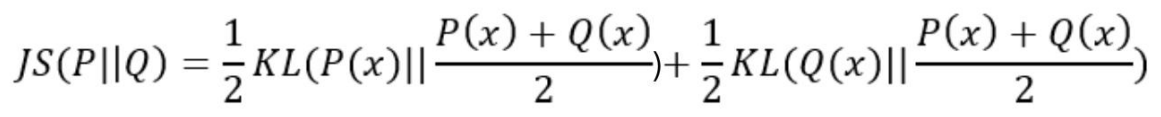
明白了度量之后,在VAE模型中并没有真正的用z~N来采样得到z变量,因为采样之后,无法进行求导。其做法是先采样一个标准高斯分布(正态分布),然后通过变换得到z~N分布,这样就能够对参数进行正常的求导计算了:
![]()
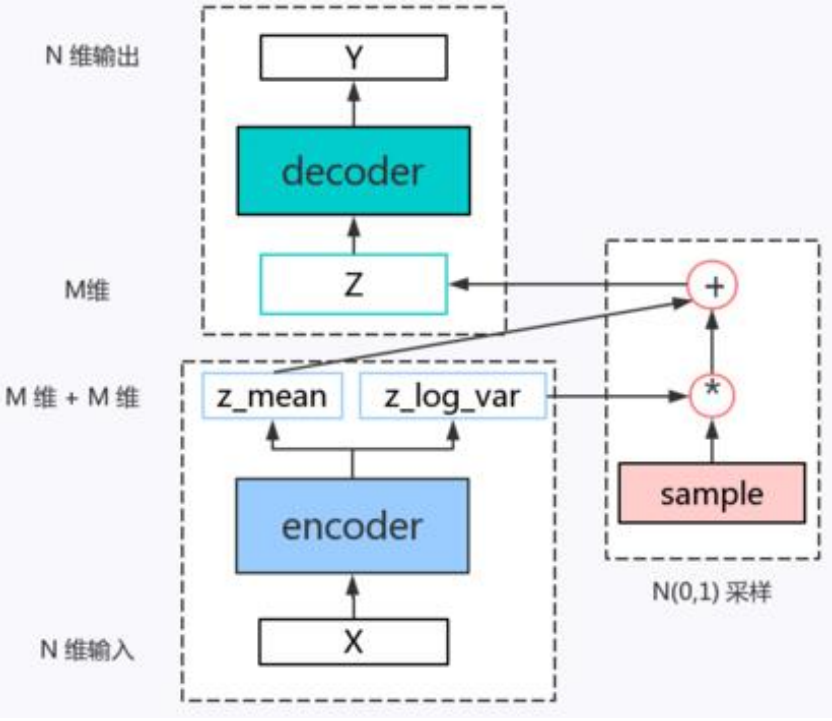

VAE遵循 编码-解码 的模式,能直接把生成的图像同原始图像进行对比,不足的是由于它是直接均方误差,其神经网络倾向于生成模糊的图像。


