
Very Deep Convolutional Networks for Large-Scale Image Recognition—VGG论文翻译
Very Deep Convolutional Networks for Large-Scale Image Recognition
摘要
在这项工作中,我们研究了在大规模的图像识别环境下卷积网络的深度对识别的准确率的影响。我们的主要贡献是使用非常小的(3×3)卷积滤波器架构对网络深度的不断增加并进行全面评估,这表明通过将深度增加到16-19层可以实现对现有技术配置的显著改进。这些发现是我们ImageNet Challenge 2014提交的基础,我们的团队在定位和分类过程中分别获得了第一名和第二名。我们还证明了我们的研究可以很好的推广到其他数据集上,从而在其它数据集上取得了最好的结果。我们已公开了两个性能最好的ConvNet模型,以便促进对于计算机视觉中深度视觉表示的进一步研究。
1 引言
卷积网络(ConvNets)近来在大规模图像和视频识别方面取得了巨大成功(Krizhevsky等,2012;Zeiler&Fergus,2013;Sermanet等,2014;Simonyan&Zisserman,2014)因为大的公开图像数据集,例如ImageNet,以及高性能计算系统的出现,例如GPU或大规模分布式集群(Dean等,2012),所以这成为了可能。特别是,在深度视觉识别架构的进步中,ImageNet大型视觉识别挑战(ILSVRC)(Russakovsky等,2014)发挥了重要作用,它已经成为几代大规模图像分类系统的实验平台,从高维度浅层特征编码(Perronnin等,2010)(ILSVRC-2011的获胜者)到深层ConvNets(Krizhevsky等,2012)(ILSVRC-2012的获奖者)。
随着ConvNets在计算机视觉领域越来越商品化,为了达到更好的准确性,已经进行了许多尝试来改进Krizhevsky等人(2012)最初的架构。例如,ILSVRC-2013(Zeiler&Fergus,2013;Sermanet等,2014)表现最佳的提交中使用了更小的感受窗口尺寸和更小的第一卷积层步长。另一条改进措施在整个图像和多个尺度上对网络进行密集地训练和测试(Sermanet等,2014;Howard,2014)。在本文中,我们解决了ConvNet架构设计的另一个重要方面——深度。为此,我们修正了架构的其它参数,并稳定的添加更多的卷积层来增加网路的深度,这是可行的,因为在所有层中都使用非常小的(3×3)卷积滤波器。
因此,我们提出更为精确的ConvNet架构,不仅可以在ILSVRC分类和定位任务上取得的最优的准确性,而且还适用于其它的图像识别数据集,它们可以获得优异的性能,即使用相对简单流程的一部分(例如,通过线性SVM分类深度特征而不进行微调)。我们公开了两款表现最好的模型1,以便促进一步研究。
本文的其余部分组织如下。在第2节,我们描述了我们的ConvNet配置。图像分类训练和评估的细节在第3节,并在第4节中在ILSVRC分类任务上对配置进行了比较。第5节总结了论文。为了完整起见,我们还将在附录A中描述和评估我们的ILSVRC-2014目标定位系统,并在附录B中讨论了非常深的特征在其它数据集上的泛化。最后,附录C包含了主要的论文修订列表。
2. ConvNet配置
为了衡量ConvNet深度在公平环境中所带来的改进,我们所有的ConvNet层配置都使用相同的规则,灵感来自Ciresan等(2011);Krizhevsky等人(2012年)。在本节中,我们首先描述我们的ConvNet配置的通用设计(第2.1节),然后详细说明评估中使用的具体配置(第2.2节)。最后,我们的设计选择将在2.3节进行讨论并与现有技术进行比较。
2.1 体系架构
在训练期间,我们的ConvNet的输入是固定大小的224×224 RGB图像。我们唯一的预处理是从每个像素中减去在训练集上计算的RGB均值。图像通过一堆卷积(conv.)层,我们使用感受野很小的滤波器:3×3(这是捕获左/右,上/下,中心概念的最小尺寸)。在其中一种配置中,我们还使用了1×1卷积滤波器,可以看作输入通道的线性变换(后面是非线性)。卷积步长固定为1个像素;卷积层输入的空间填充要满足卷积之后保留空间分辨率,即3×3卷积层的填充为1个像素。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。
一堆卷积层(在不同架构中具有不同深度)之后是三个全连接(FC)层:前两个每个都有4096个通道,第三个执行1000维ILSVRC分类,因此包含1000个通道(一个通道对应一个类别)。最后一层是soft-max层。所有网络中全连接层的配置是相同的。
所有隐藏层都配备了修正(ReLU(Krizhevsky等,2012))非线性。我们注意到,我们的网络(除了一个)都不包含局部响应规范化(LRN)(Krizhevsky等,2012):将在第4节看到,这种规范化并不能提高在ILSVRC数据集上的性能,但增加了内存消耗和计算时间。在应用的地方,LRN层的参数是(Krizhevsky等,2012)的参数。
2.2 配置
本文中评估的ConvNet配置在表1中列出,每列一个。接下来我们将按网站名称(A-E)来提及网络。所有配置都遵循2.1节提出的通用设计,并且仅是深度不同:从网络A中的11个加权层(8个卷积层和3个FC层)到网络E中的19个加权层(16个卷积层和3个FC层)。卷积层的宽度(通道数)相当小,从第一层中的64开始,然后在每个最大池化层之后增加2倍,直到达到512。
表1:ConvNet配置(以列显示)。随着更多的层被添加,配置的深度从左(A)增加到右(E)(添加的层以粗体显示)。卷积层参数表示为“conv⟨感受野大小⟩-通道数⟩”。为了简洁起见,不显示ReLU激活功能。
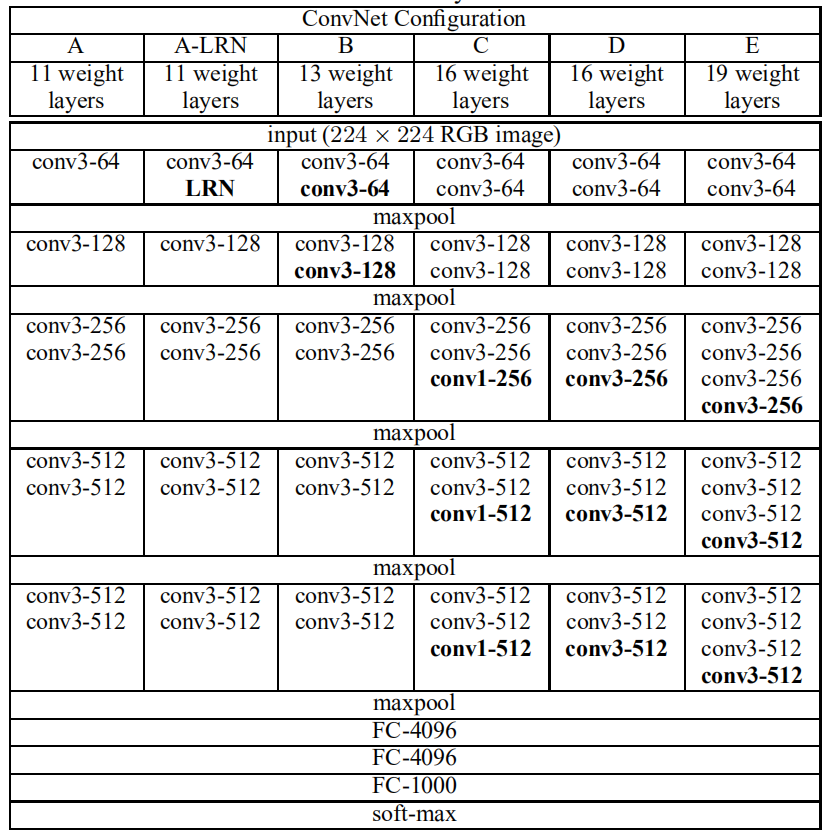
在表2中,我们报告了每个配置的参数数量。尽管深度很大,我们的网络中权重数量并不大于具有更大卷积层宽度和感受野的较浅网络中的权重数量(144M的权重在(Sermanet等人,2014)中)。
表2:参数数量(百万级别)

2.3 讨论
我们的ConvNet配置与ILSVRC-2012(Krizhevsky等,2012)和ILSVRC-2013比赛(Zeiler&Fergus,2013;Sermanet等,2014)表现最佳的参赛提交中使用的ConvNet配置有很大不同。不是在第一卷积层中使用相对较大的感受野(例如,在(Krizhevsky等人,2012)中的11×11,步长为4,或在(Zeiler&Fergus,2013;Sermanet等,2014)中的7×7,步长为2),我们在整个网络使用非常小的3×3感受野,与输入的每个像素(步长为1)进行卷积。很容易看到两个3×3卷积层堆叠(没有空间池化)有5×5的有效感受野;三个这样的层具有7×7的有效感受野。那么我们获得了什么?例如通过使用三个3×3卷积层的堆叠来替换单个7×7层。首先,我们结合了三个非线性修正层,而不是单一的,这使得决策函数更具判别性。其次,我们减少参数的数量:假设三层3×3卷积堆叠的输入和输出有$C$个通道,堆叠卷积层的参数为$3(32C2)=27C2$个权重;同时,单个7×7卷积层将需要$72C2=49C2$个参数,即参数多81%。这可以看作是对7×7卷积滤波器进行正则化,迫使它们通过3×3滤波器(在它们之间注入非线性)进行分解。
结合1×1卷积层(配置C,表1)是增加决策函数非线性而不影响卷积层感受野的一种方式。即使在我们的案例下,1×1卷积基本上是在相同维度空间上的线性投影(输入和输出通道的数量相同),由修正函数引入附加的非线性。应该注意的是1×1卷积层最近在Lin等人(2014)的“Network in Network”架构中已经得到了使用。
Ciresan等人(2011)以前使用小尺寸的卷积滤波器,但是他们的网络深度远远低于我们的网络,他们并没有在大规模的ILSVRC数据集上进行评估。Goodfellow等人(2014)在街道号识别任务中采用深层ConvNets(11个权重层),显示出增加的深度导致了更好的性能。GooLeNet(Szegedy等,2014),ILSVRC-2014分类任务的表现最好的项目,是独立于我们工作之外的开发的,但是类似的是它是基于非常深的ConvNets(22个权重层)和小卷积滤波器(除了3×3,它们也使用了1×1和5×5卷积)。然而,它们的网络拓扑结构比我们的更复杂,并且在第一层中特征图的空间分辨率被更积极地减少,以减少计算量。正如将在第4.5节显示的那样,我们的模型在单网络分类精度方面胜过Szegedy等人(2014)。
3 分类框架
在上一节中,我们介绍了我们的网络配置的细节。在本节中,我们将介绍分类ConvNet训练和评估的细节。
3.1 训练
ConvNet训练过程通常遵循Krizhevsky等人(2012)(除了从多尺度训练图像中对输入裁剪图像进行采样外,如下文所述)。也就是说,通过使用具有动量的小批量梯度下降(基于反向传播(LeCun等人,1989))优化多项式逻辑回归目标函数来进行训练。批量大小设为256,动量为0.9。训练通过权重衰减(L2惩罚乘子设定为5·10{−4})进行正则化,前两个全连接层执行丢弃正则化(丢弃率设定为0.5)。学习率初始设定为10^{−2},然后当验证集准确率停止改善时,减少10倍。学习率总共降低3次,学习在37万次迭代后停止(74个epochs)。我们推测,尽管与(Krizhevsky等,2012)相比我们的网络参数更多,网络的深度更大,但网络需要更小的epoch就可以收敛,这是由于(a)由更大的深度和更小的卷积滤波器尺寸引起的隐式正则化,(b)某些层的预初始化。
网络权重的初始化是重要的,因为由于深度网络中梯度的不稳定,不好的初始化可能会阻碍学习。为了规避这个问题,我们开始训练配置A(表1),足够浅以随机初始化进行训练。然后,当训练更深的架构时,我们用网络A的层初始化前四个卷积层和最后三个全连接层(中间层被随机初始化)。我们没有减少预初始化层的学习率,允许他们在学习过程中改变。对于随机初始化(如果应用),我们从均值为0和方差为10^{−2}的正态分布中采样权重。偏置初始化为零。值得注意的是,在提交论文之后,我们发现可以通过使用Glorot&Bengio(2010)的随机初始化程序来初始化权重而不进行预训练。
训练图像大小,令S是等轴归一化的训练图像的最小边,ConvNet输入从S中裁剪(我们也将S称为训练尺度)。虽然裁剪尺寸固定为224×224,但原则上S可以是不小于224的任何值:对于S=224,裁剪图像将捕获整个图像的统计数据,完全扩展训练图像的最小边;对于S»224,裁剪图像将对应于图像的一小部分,包含小对象或对象的一部分。
我们考虑两种方法来设置训练尺度S。第一种是修正对应单尺度训练的S(注意,采样裁剪图像中的图像内容仍然可以表示多尺度图像统计)。在我们的实验中,我们评估了以两个固定尺度训练的模型:S = 256(已经在现有技术中广泛使用(Krizhevsky等人,2012;Zeiler&Fergus,2013;Sermanet等,2014))和S = 384。给定ConvNet配置,我们首先使用S=256来训练网络。为了加速S = 384网络的训练,用S = 256预训练的权重来进行初始化,我们使用较小的初始学习率10^{−3}。
设置S的第二种方法是多尺度训练,其中每个训练图像通过从一定范围[S_{min},S_{max}](我们使用S_{min} = 256和S_{max} = 512)随机采样S来单独进行归一化。由于图像中的目标可能具有不同的大小,因此在训练期间考虑到这一点是有益的。这也可以看作是通过尺度抖动进行训练集增强,其中单个模型被训练在一定尺度范围内识别对象。为了速度的原因,我们通过对具有相同配置的单尺度模型的所有层进行微调,训练了多尺度模型,并用固定的S = 384进行预训练。
3.2 测试
在测试时,给出训练的ConvNet和输入图像,它按以下方式分类。首先,将其等轴地归一化到预定义的最小图像边,表示为Q(我们也将其称为测试尺度)。我们注意到,Q不一定等于训练尺度S(正如我们在第4节中所示,每个S使用Q的几个值会导致性能改进)。然后,网络以类似于(Sermanet等人,2014)的方式密集地应用于归一化的测试图像上。即,全连接层首先被转换成卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层)。然后将所得到的全卷积网络应用于整个(未裁剪)图像上。结果是类得分图的通道数等于类别的数量,以及取决于输入图像大小的可变空间分辨率。最后,为了获得图像的类别分数的固定大小的向量,类得分图在空间上平均(和池化)。我们还通过水平翻转图像来增强测试集;将原始图像和翻转图像的soft-max类后验进行平均,以获得图像的最终分数。
由于全卷积网络被应用在整个图像上,所以不需要在测试时对采样多个裁剪图像(Krizhevsky等,2012),因为它需要网络重新计算每个裁剪图像,这样效率较低。同时,如Szegedy等人(2014)所做的那样,使用大量的裁剪图像可以提高准确度,因为与全卷积网络相比,它使输入图像的采样更精细。此外,由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。虽然我们认为在实践中,多裁剪图像的计算时间增加并不足以证明准确性的潜在收益,但作为参考,我们还在每个尺度使用50个裁剪图像(5×5规则网格,2次翻转)评估了我们的网络,在3个尺度上总共150个裁剪图像,与Szegedy等人(2014)在4个尺度上使用的144个裁剪图像。
3.3 实现细节
我们的实现来源于公开的C++ Caffe工具箱(Jia,2013)(2013年12月推出),但包含了一些重大的修改,使我们能够对安装在单个系统中的多个GPU进行训练和评估,也能训练和评估在多个尺度上(如上所述)的全尺寸(未裁剪)图像。多GPU训练利用数据并行性,通过将每批训练图像分成几个GPU批次,每个GPU并行处理。在计算GPU批次梯度之后,将其平均以获得完整批次的梯度。梯度计算在GPU之间是同步的,所以结果与在单个GPU上训练完全一样。
最近提出了更加复杂的加速ConvNet训练的方法(Krizhevsky,2014),它们对网络的不同层之间采用模型和数据并行,我们发现我们概念上更简单的方案与使用单个GPU相比,在现有的4-GPU系统上已经提供了3.75倍的加速。在配备四个NVIDIA Titan Black GPU的系统上,根据架构训练单个网络需要2-3周时间。
4 分类实验
数据集。在本节中,我们介绍了描述的ConvNet架构(用于ILSVRC 2012-2014挑战)在ILSVRC-2012数据集上实现的图像分类结果。数据集包括1000个类别的图像,并分为三组:训练(130万张图像),验证(5万张图像)和测试(留有类标签的10万张图像)。使用两个措施评估分类性能:top-1和top-5错误率。前者是多类分类误差,即不正确分类图像的比例;后者是ILSVRC中使用的主要评估标准,并且计算为图像真实类别在前5个预测类别之外的图像比例。
对于大多数实验,我们使用验证集作为测试集。在测试集上也进行了一些实验,并将其作为ILSVRC-2014竞赛(Russakovsky等,2014)“VGG”小组的输入提交到了官方的ILSVRC服务器。
4.1 单尺度评估
我们首先评估单个ConvNet模型在单尺度上的性能,其层结构配置如2.2节中描述。测试图像大小设置如下:对于固定S的Q = S,对于抖动S ∈ [S_{min}, S_{max}],Q = 0.5(S_{min} + S_{max})。结果如表3所示。
表3:在单测试尺度的ConvNet性能
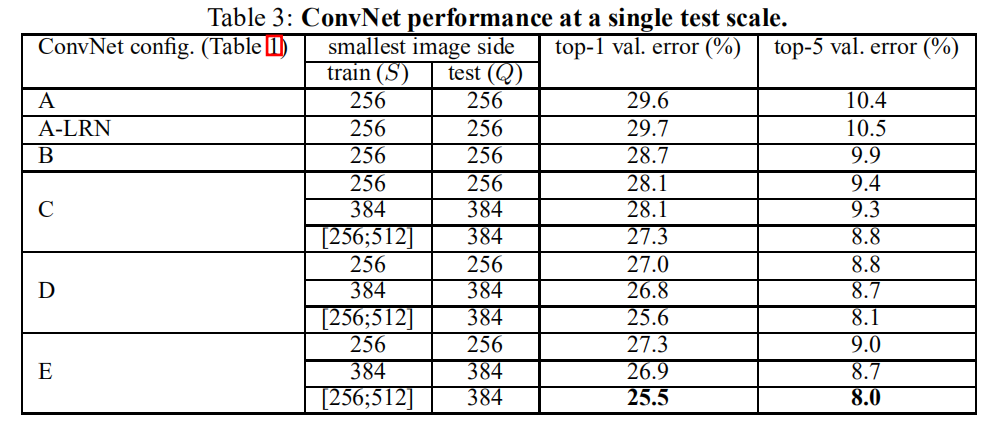
首先,我们注意到,使用局部响应归一化(A-LRN网络)在没有任何归一化层的情况下,对模型A没有改善。因此,我们在较深的架构(B-E)中不采用归一化。
第二,我们观察到分类误差随着ConvNet深度的增加而减小:从A中的11层到E中的19层。值得注意的是,尽管深度相同,配置C(包含三个1×1卷积层)比在整个网络层中使用3×3卷积的配置D更差。这表明,虽然额外的非线性确实有帮助(C优于B),但也可以通过使用具有非平凡感受野(D比C好)的卷积滤波器来捕获空间上下文。当深度达到19层时,我们架构的错误率饱和,但更深的模型可能有益于较大的数据集。我们还将网络B与具有5×5卷积层的浅层网络进行了比较,浅层网络可以通过用单个5×5卷积层替换B中每对3×3卷积层得到(其具有相同的感受野如第2.3节所述)。测量的浅层网络top-1错误率比网络B的top-1错误率(在中心裁剪图像上)高7%,这证实了具有小滤波器的深层网络优于具有较大滤波器的浅层网络。
最后,训练时的尺度抖动(S∈[256; 512])得到了与固定最小边(S = 256或S = 384)的图像训练相比更好的结果,即使在测试时使用单尺度。这证实了通过尺度抖动进行的训练集增强确实有助于捕获多尺度图像统计。
4.2 多尺度评估
在单尺度上评估ConvNet模型后,我们现在评估测试时尺度抖动的影响。它包括在一张测试图像的几个归一化版本上运行模型(对应于不同的Q值),然后对所得到的类别后验进行平均。考虑到训练和测试尺度之间的巨大差异会导致性能下降,用固定S训练的模型在三个测试图像尺度上进行了评估,接近于训练一次:Q = {S − 32, S, S + 32}。同时,训练时的尺度抖动允许网络在测试时应用于更广的尺度范围,所以用变量S ∈ [S_{min}; S_{max}]训练的模型在更大的尺寸范围Q = {S_{min}, 0.5(S_{min} + S_{max}), S_{max}上进行评估。
表4中给出的结果表明,测试时的尺度抖动导致了更好的性能(与在单一尺度上相同模型的评估相比,如表3所示)。如前所述,最深的配置(D和E)执行最佳,并且尺度抖动优于使用固定最小边S的训练。我们在验证集上的最佳单网络性能为24.8%/7.5% top-1/top-5的错误率(在表4中用粗体突出显示)。在测试集上,配置E实现了7.3% top-5的错误率。
表4:在多个测试尺度上的ConvNet性能

4.3 多裁剪图像评估
在表5中,我们将稠密ConvNet评估与多裁剪图像评估进行比较(细节参见第3.2节)。我们还通过平均其soft-max输出来评估两种评估技术的互补性。可以看出,使用多裁剪图像表现比密集评估略好,而且这两种方法确实是互补的,因为它们的组合优于其中的每一种。如上所述,我们假设这是由于卷积边界条件的不同处理。
表5:ConvNet评估技术比较。在所有的实验中训练尺度S从[256;512]采样,三个测试适度Q考虑:{256, 384, 512}。

4.4 卷积网络融合
到目前为止,我们评估了ConvNet模型的性能。在这部分实验中,我们通过对soft-max类别后验进行平均,结合了几种模型的输出。由于模型的互补性,这提高了性能,并且在了2012年(Krizhevsky等,2012)和2013年(Zeiler&Fergus,2013;Sermanet等,2014)ILSVRC的顶级提交中使用。
结果如表6所示。在ILSVRC提交的时候,我们只训练了单规模网络,以及一个多尺度模型D(仅在全连接层进行微调而不是所有层)。由此产生的7个网络组合具有7.3%的ILSVRC测试误差。在提交之后,我们考虑了只有两个表现最好的多尺度模型(配置D和E)的组合,它使用密集评估将测试误差降低到7.0%,使用密集评估和多裁剪图像评估将测试误差降低到6.8%。作为参考,我们表现最佳的单模型达到7.1%的误差(模型E,表5)。
表6:多个卷积网络融合结果

4.5 与最新技术比较
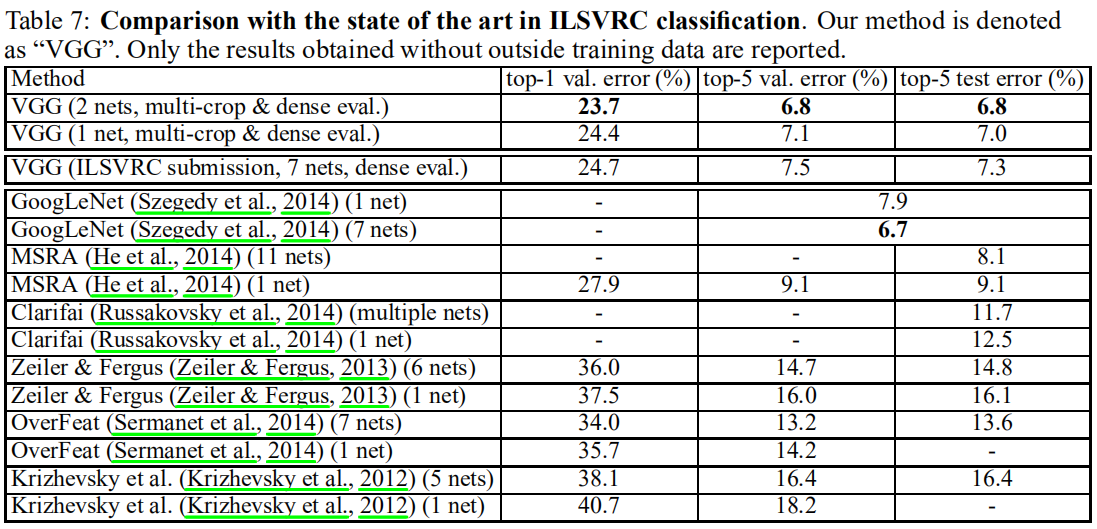
最后,我们在表7中与最新技术比较我们的结果。在ILSVRC-2014挑战的分类任务(Russakovsky等,2014)中,我们的“VGG”团队获得了第二名,
使用7个模型的组合取得了7.3%测试误差。提交后,我们使用2个模型的组合将错误率降低到6.8%。
表7:在ILSVRC分类中与最新技术比较。我们的方法表示为“VGG”。报告的结果没有使用外部数据。
5 结论
在这项工作中,我们评估了非常深的卷积网络(最多19个权重层)用于大规模图像分类。已经证明,表示深度有利于分类精度,并且深度大大增加的传统ConvNet架构(LeCun等,1989;Krizhevsky等,2012)可以实现ImageNet挑战数据集上的最佳性能。在附录中,我们还显示了我们的模型很好地泛化到各种各样的任务和数据集上,可以匹敌或超越更复杂的识别流程,其构建围绕不深的图像表示。我们的结果再次证实了深度在视觉表示中的重要性。
致 谢
这项工作得到ERC授权的VisRec编号228180的支持.我们非常感谢NVIDIA公司捐赠GPU为此研究使用。
参考文献
Bell, S., Upchurch, P., Snavely, N., and Bala, K. Material recognition in the wild with the materials in context database. CoRR, abs/1412.0623, 2014.
Chatfield, K., Simonyan, K., Vedaldi, A., and Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
Cimpoi, M., Maji, S., and Vedaldi, A. Deep convolutional filter banks for texture recognition and segmentation. CoRR, abs/1411.6836, 2014.
Ciresan, D. C., Meier, U., Masci, J., Gambardella, L. M., and Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In IJCAI, pp. 1237–1242, 2011.
Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Mao, M., Ranzato, M., Senior, A., Tucker, P., Yang, K., Le, Q. V., and Ng, A. Y. Large scale distributed deep networks. In NIPS, pp. 1232–1240, 2012.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proc. CVPR, 2009.
Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., and Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. CoRR, abs/1310.1531, 2013.
Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C., Winn, J., and Zisserman, A. The Pascal visual object classes challenge: A retrospective. IJCV, 111(1):98–136, 2015.
Fei-Fei, L., Fergus, R., and Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In IEEE CVPR Workshop of Generative Model Based Vision, 2004.
Girshick, R. B., Donahue, J., Darrell, T., and Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR, abs/1311.2524v5, 2014. Published in Proc. CVPR, 2014.
Gkioxari, G., Girshick, R., and Malik, J. Actions and attributes from wholes and parts. CoRR, abs/1412.2604, 2014.
Glorot, X. and Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proc. AISTATS, volume 9, pp. 249–256, 2010.
Goodfellow, I. J., Bulatov, Y., Ibarz, J., Arnoud, S., and Shet, V. Multi-digit number recognition from street view imagery using deep convolutional neural networks. In Proc. ICLR, 2014.
Griffin, G., Holub, A., and Perona, P. Caltech-256 object category dataset. Technical Report 7694, California Institute of Technology, 2007.
He, K., Zhang, X., Ren, S., and Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. CoRR, abs/1406.4729v2, 2014.
Hoai, M. Regularized max pooling for image categorization. In Proc. BMVC., 2014.
Howard, A. G. Some improvements on deep convolutional neural network based image classification. In Proc. ICLR, 2014.
Jia, Y. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe.berkeleyvision.org/, 2013.
Karpathy, A. and Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. CoRR, abs/1412.2306, 2014.
Kiros, R., Salakhutdinov, R., and Zemel, R. S. Unifying visual-semantic embeddings with multimodal neural language models. CoRR, abs/1411.2539, 2014.
Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. CoRR, abs/1404.5997, 2014.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 1106–1114, 2012.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
Lin, M., Chen, Q., and Yan, S. Network in network. In Proc. ICLR, 2014.
Long, J., Shelhamer, E., and Darrell, T. Fully convolutional networks for semantic segmentation. CoRR, abs/1411.4038, 2014.
Oquab, M., Bottou, L., Laptev, I., and Sivic, J. Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks. In Proc. CVPR, 2014.
Perronnin, F., Sa ́nchez, J., and Mensink, T. Improving the Fisher kernel for large-scale image classification. In Proc. ECCV, 2010.
Razavian, A., Azizpour, H., Sullivan, J., and Carlsson, S. CNN Features off-the-shelf: an Astounding Baseline for Recognition. CoRR, abs/1403.6382, 2014.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. ImageNet large scale visual recognition challenge. CoRR, abs/1409.0575, 2014.
Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., and LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In Proc. ICLR, 2014.
Simonyan, K. and Zisserman, A. Two-stream convolutional networks for action recognition in videos. CoRR, abs/1406.2199, 2014. Published in Proc. NIPS, 2014.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. CoRR, abs/1409.4842, 2014.
Wei, Y., Xia, W., Huang, J., Ni, B., Dong, J., Zhao, Y., and Yan, S. CNN: Single-label to multi-label. CoRR, abs/1406.5726, 2014.
Zeiler, M. D. and Fergus, R. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013. Published in Proc. ECCV, 2014.
声明:本文翻译论文目的只是为了学习,若有侵权之处,请联系作者删除博文,感谢!

