
TensorFlow——卷积神经网络的相关函数
在TensorFlow中,使用tr.nn.conv2d来实现卷积操作,使用tf.nn.max_pool进行最大池化操作。通过闯传入不同的参数,来实现各种不同类型的卷积与池化操作。
卷积函数tf.nn.conv2d
TensorFlow里使用tf.nn.conv2d函数来实现卷积,其格式如下:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None),参数的含义如下:
input:需要进行卷积操作的图像,它要求是一个Tensor,具有[ batch, in_height, in_width, in_channels ]的形状,这是一个四维的数据,其中各个位置参数的具体含义是:训练时一个batch的图片数量,图片高度,图片宽度,图片通道数,数据的类型是float。
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[ filter_height,filter_width,in_channels,out_channels ]这样的shape,其中具体的含义是“卷积核的高度,卷积核宽度,图片的通道数,滤波器的个数”,要求类型与参数input相同。有一个地方需要关注意,第三维in_channels就是参数input的第四维。
strides:卷积是在图像每一位的步长,这是一个一维的向量,长度为4。
padding:定义元素边框与元素内容之间的空间。string类型的量,只能是SAME和VALID其中之一,这个值决定不同的卷积方式,padding的值VALID时,表示边缘不填充,当其为SAME时,表示填充
到滤波器可以到达图像边缘。
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true。
返回值:函数的返回值仍然是一个Tensor,就是feature map。
import tensorflow as tf import numpy as np # [batch, im_height, im_weight, in_channels] input = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 1])) input2 = tf.Variable(tf.constant(1.0, shape=[1, 5, 5, 2])) input3 = tf.Variable(tf.constant(1.0, shape=[1, 4, 4, 1])) # [filter_height, filter_weight, in_channels, in_channels] filter1 = tf.Variable(tf.constant([-1.0, 0, 0, -1], shape=[2, 2, 1, 1])) filter2 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1, 0, 0, 1], shape=[2, 2, 1, 2])) filter3 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1.0, 0, 0, -1, -1.0, 0, 0, -1], shape=[2, 2, 1, 3])) filter4 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1.0, 0, 0, -1, -1.0, 0, 0, -1, -1.0, 0, 0, -1], shape=[2, 2, 2, 2])) filter5 = tf.Variable(tf.constant([-1.0, 0, 0, -1, -1.0, 0, 0, -1], shape=[2, 2, 2, 1])) op1 = tf.nn.conv2d(input, filter1, strides=[1, 2, 2, 1], padding='SAME') op2 = tf.nn.conv2d(input, filter2, strides=[1, 2, 2, 1], padding='SAME') op3 = tf.nn.conv2d(input, filter3, strides=[1, 2, 2, 1], padding='SAME') op4 = tf.nn.conv2d(input2, filter4, strides=[1, 2, 2, 1], padding='SAME') op5 = tf.nn.conv2d(input2, filter5, strides=[1, 2, 2, 1], padding='SAME') vop1 = tf.nn.conv2d(input, filter1, strides=[1, 2, 2, 1], padding='VALID') op6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding='SAME') vop6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding='VALID') init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) print('-op1:\n', sess.run([op1, filter1])) print('-------------------------------') print('-op2:\n', sess.run([op2, filter2])) print('-op3:\n', sess.run([op3, filter3])) print('-------------------------------') print('-op4:\n', sess.run([op4, filter4])) print('-op5:\n', sess.run([op5, filter5])) print('-------------------------------') print('-op1:\n', sess.run([op1, filter1])) print('-vop1:\n', sess.run([vop1, filter1])) print('-op6:\n', sess.run([op6, filter1])) print('-vop6:\n', sess.run([vop6, filter1])) print('-------------------------------')
根据上述程序的运行结果,仔细的分析就能理解卷积是如何的工作的,需要注意的是SAME padding补0的情况,
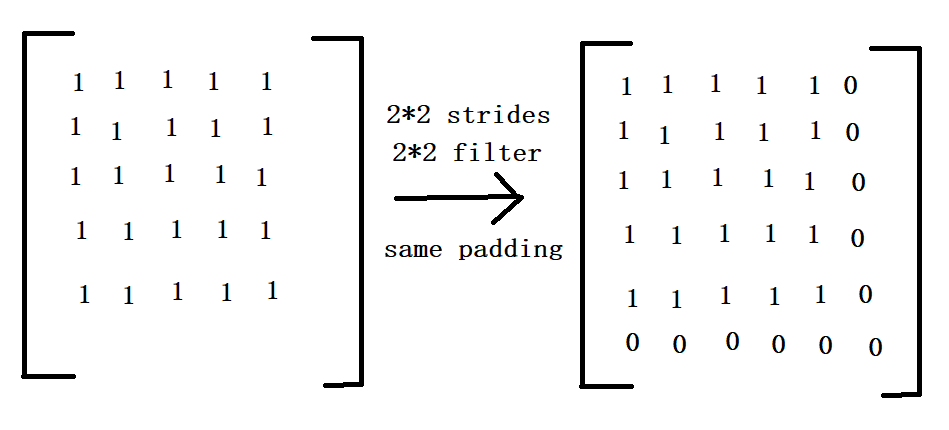
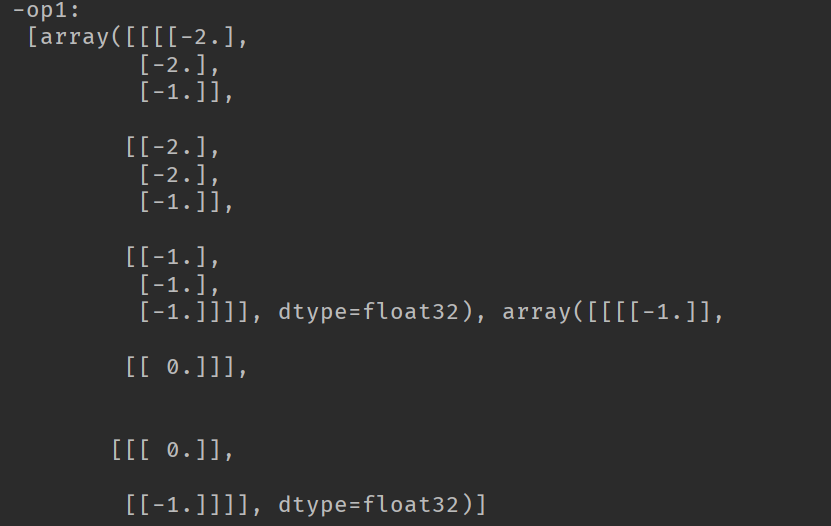
由于可知,op1的卷积操作的结果是3*3的feature map,其他的结果也是类似的情况。当图像是多通道的情况时,卷积操作的结果是将各个通道的feature map的结果相加,作为输出的一张feature map。
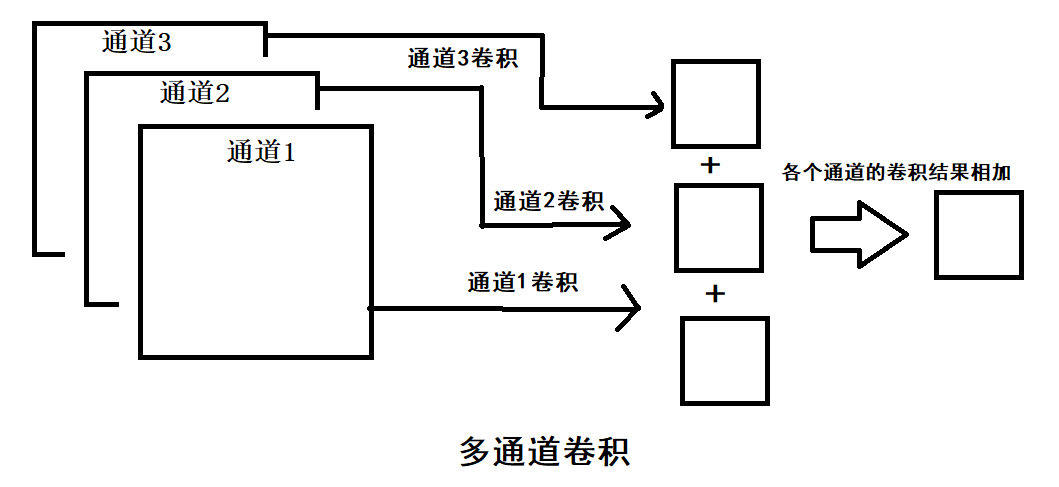
图像卷积示例
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mping path = 'image/1.jpg' img = mping.imread(path) plt.imshow(img) plt.axis('off') plt.show() print(img.shape) full = np.reshape(img, [1, 374, 560, 3]) inputfull = tf.Variable(tf.constant(1.0, shape=[1, 374, 560, 3])) filter = tf.Variable(tf.constant([[-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0], [-2.0, -2.0, -2.0], [0, 0, 0], [2.0, 2.0, 2.0], [-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0]], shape=[3, 3, 3, 1])) op = tf.nn.conv2d(inputfull, filter, strides=[1, 1, 1, 1], padding='SAME') o = tf.cast(((op - tf.reduce_min(op))/(tf.reduce_max(op)-tf.reduce_min(op)))*255, tf.uint8) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) t, f = sess.run([o, filter], feed_dict={inputfull: full}) t = np.reshape(t, [374, 560]) plt.imshow(t, cmap='Greys_r') plt.axis('off') plt.show()

池化函数tf.nn.max_pool(avg_pool)
TensorFlow里的池化函数如下:
tf.nn.max_pool(input, ksize, strides, padding, name)
tf.nn.avg_pool(input, ksize, strides, padding, name)
上述的两个池化函数中,4个参数的意义如下:
input:进行池化操作的数据,一般的池化层是在卷积层之后,所以通常的输入是feature map,依然是[ batch, height, width, channels ]的形状。
ksize:池化窗口的大小,4维的向量,一般是[1, height, width, 1],在batch和channles通常是不做池化的。
strides:和卷积参数含义类似,窗口在每一个维度上面滑动,一般也是[1, strides,strides,1]
padding:和卷积参数含义一样,也是取VALID或者SAME。
返回的Tensor:类型不变,shape仍然是[ batch, height, width, channels ]的形状。
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mping path = 'image/1.jpg' img = mping.imread(path) plt.imshow(img) plt.axis('off') plt.show() print(img.shape) full = np.reshape(img, [1, 374, 560, 3]) inputfull = tf.Variable(tf.constant(1.0, shape=[1, 374, 560, 3])) pooling = tf.nn.max_pool(inputfull, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME') pooling1 = tf.nn.max_pool(inputfull, [1, 2, 2, 1], [1, 1, 1, 1], padding='SAME') pooling2 = tf.nn.max_pool(inputfull, [1, 4, 4, 1], [1, 1, 1, 1], padding='SAME') pooling3 = tf.nn.max_pool(inputfull, [1, 4, 4, 1], [1, 4, 4, 1], padding='SAME') pooling4 = tf.nn.max_pool(inputfull, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME') o = tf.cast(((pooling - tf.reduce_min(pooling))/(tf.reduce_max(pooling)-tf.reduce_min(pooling)))*255, tf.uint8) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) t = sess.run(o, feed_dict={inputfull: full}) print(t.shape) t = np.reshape(t, [187, 280, 3]) plt.imshow(t) plt.axis('off') plt.show()
池化操作的作用是将特征图中的信息进行放大,使得特性信息更加的明显。

