

机器学习——线性回归的原理,推导过程,源码,评价
0.线性回归
做为机器学习入门的经典模型,线性回归是绝对值得大家深入的推导实践的,而在众多的模型中,也是相对的容易。线性回归模型主要是用于线性建模,假设样本的特征有n个,我们通常将截距项也添加到特征向量x中,即在x中添加一个全为1的列,这是,我们就能够将模型表示为如下的形式:
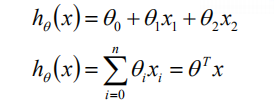
1.残差的解释
根据上述的模型,我们可以表示出样本的标签值与模型预测值之间的表达式,如下所示:
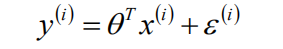
上述式子中,根据残差的定义:实际值和预测值之间的差值,可知,![]() 即为模型的残差。那么,我们想知道的是,
即为模型的残差。那么,我们想知道的是,![]() 在模型中是怎么样的分布呢?
在模型中是怎么样的分布呢?
1,残差是由模型中的许多误差的积累的结果,即模型中许多的误差的累加作用的结果。
2,假定这些误差的分布是相同的。
那么,根据中心极限定理,![]() 是多个独立同分布的变量的累加结果,则
是多个独立同分布的变量的累加结果,则![]() 是服从均值为某值,方差为某值的高斯分布,对于均值,我们总是可以通过改变模型的截距,是的模型得到的平面上下移动,是的得到的残差的分布的均值为0,假设方差为定值
是服从均值为某值,方差为某值的高斯分布,对于均值,我们总是可以通过改变模型的截距,是的模型得到的平面上下移动,是的得到的残差的分布的均值为0,假设方差为定值![]() 。
。

2.中心极限定理
在实际的问题中,很多的随机现象可以看做是众多因素的独立影响的综合反应,往往可以看做是服从正态分布。比如,城市的耗电量:大量用户的用电量总和。测量误差:许多观察不到的,微小误差的总和。中心极限定理的关键是多个随机变量的和,在有些问题中是乘积误差,这时则需要鉴别后再使用。
3.极大似然估计
我们得到了残差的分布函数,因而我们可以对残差进行极大似然估计,就能够得到似然函数,而似然函数中应该是含有参数,因而我们就能够通过似然函数求极大值,得到参数的表达式,进而得到模型的解。

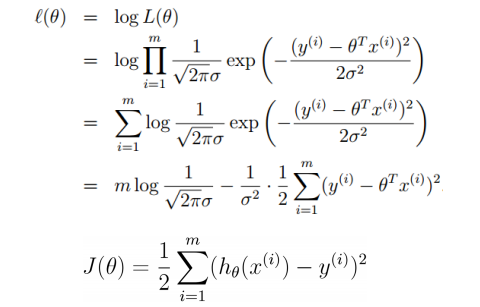
在上述推导过程中,我们先是对似然函数求极大值,得到的结果中,发现是一个减法计算,因而只需对后面的式子求最小值,则能够得到线性回归的代价函数,这也和我们的理解是相符合的,即模型的预测值应该使得它和实际值相差越小越好。
4.解析解
在得到的代价函数中,计算极小值,我们发现这是一个复合函数,二次函数和线性函数的复合函数,根据凸函数的性质:凸函数和仿射函数的复合函数还是凸函数,因而代价函数是凸函数,存在极小值也是最小值。我们通过求极值点就能够得到最优解。
我们可以将M个N维样本组成矩阵X,m行n列,每一行对应一个样本,每一列对应所有样本的一个维度,由于还有截距项,因而有一列全为1。
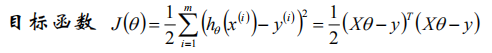
计算梯度
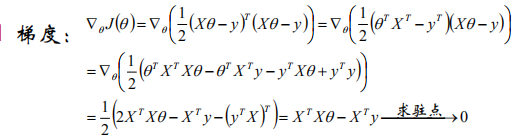
可得到参数的解析解:
![]()
当上述式子不可逆时,可以添加扰动,使其是可逆的
![]()
看到上述的式子,自然想到了正则化,我们在代价函数里面添加正则项,进行求解刚好得到上述的式子。

L2正则化
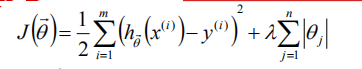
L1正则化
对于L2正则我们可以计算梯度,但是L1正则中我们是无法计算梯度的,一种可行的办法是使用泰勒公式对后半部分进行近似计算。
5.梯度下降
除了用解析解,在机器学习中,我们更多的时候使用的是学习方法,通过优化的方式得到最优解,下面我们是用梯度下降来进行模型的求解。
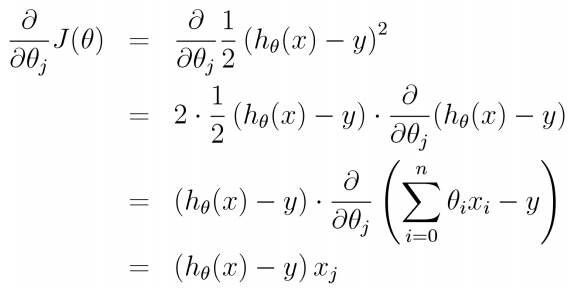
得到了梯度之后,我们可以通过梯度下降的方式不断更新参数得到最优解。
6.模型的评价
对于m个样本,通过得到的模型,我们可以计算出m估计值,下面我们定义总平方和TSS:

得到了总平方和后,我们可以计算残差平方和SSE
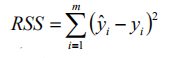
由得到的总平方和与残差平方和,我们定义R方统计量:
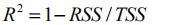
R方的值越大,拟合的效果越好,最优值是1。
7.源码
def getLinearData(lamda): x1 = np.random.random(50) * 20 - 10 x2 = np.random.random(50) * 7 - 2 x3 = np.random.random(50) * 36 - 13 x4 = np.random.random(50) * 9 - 3 x = np.stack((x1, x2, x3, x4), axis=1) b = np.ones((50)) x = np.c_[x, b] y = np.sum(x*lamda, axis=1) + np.random.random(50) * 50 - 25 return x, y def predict_y(x, k): return np.sum(x*k, axis=1) def cal_loss(x, y, k): y_predict = np.sum(x*k, axis=1) loss = 0.5 * np.sum(np.square(y - y_predict)) return loss def mini_batch_GD(): return def BGD(x, y, k, n, s, loss): losslist = [] for i in range(n): y_hat = predict_y(x, k) for j, dk in enumerate(k): xi = x[:, j] dk = dk + s * np.sum((y-y_hat) * xi, axis=0) k[j] = dk new_loss = cal_loss(x, y, k) print(new_loss) losslist.append(new_loss) if new_loss < loss or (i > 10 and np.abs(new_loss - losslist[-2])< 0.0001): return k, new_loss, losslist new_loss = cal_loss(x, y, k) return k, new_loss, losslist def SGD(x, y, k, n, s, loss): losslist = [] for i in range(n): for j, xi in enumerate(x): y_predict = np.sum(xi*k) k = k + s * (y[j] - y_predict) * xi new_loss = cal_loss(x, y, k) losslist.append(new_loss) print(new_loss) if new_loss < loss : return k, new_loss, losslist new_loss = cal_loss(x, y_train, k) return k, new_loss, losslist def linear_Regression(x, y): size = np.shape(x)[1] k = np.ones(size) # k, loss, losslist = BGD(x, y, k, 20000000, 0.000005, 10) k, loss, losslist = SGD(x, y, k, 20, 0.0005, 10) return k, loss, losslist if __name__ == '__main__': lamda = [2, -5, 3, 7, 15] # a1, a2, a3, a4, b x, y = getLinearData(lamda) x_train, y_train = x[0:40, :], y[0:40] x_test, y_test = x[40:, :], y[40:] k, loss, losslist = linear_Regression(x_train, y_train) print(k) print(loss) i = np.arange(np.size(losslist)) plt.figure() # plt.plot(i, losslist, 'r-', label='BGD') plt.plot(i, losslist, 'r-', label='SGD') plt.legend() plt.show()
模型运行的结果:
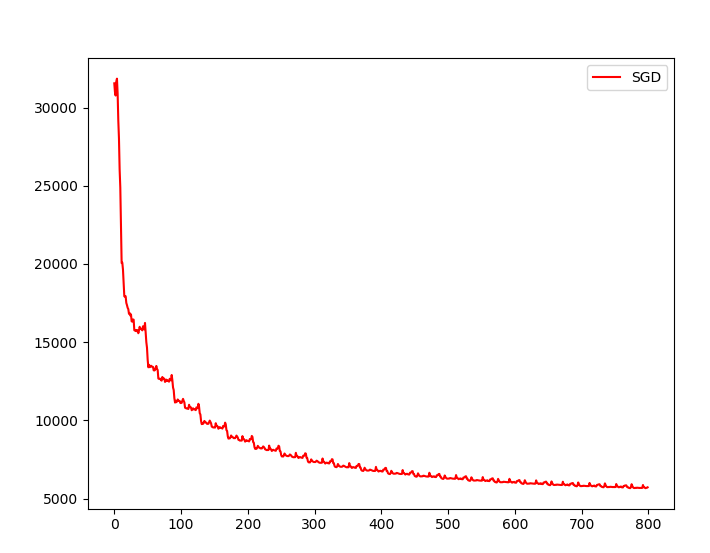
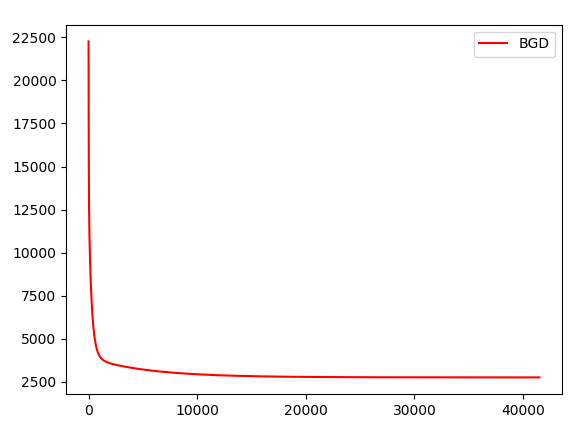


在写梯度下降的代码中,由于是用所有的样本计算梯度进行更新的,所以每次得到的梯度值很大,开始时我给出的步长是0.1-0.01,结果出现了跨越极值的情况,最后的到无穷大的结果。以为是代码的问题,找半天代码一直没想通,后面才想到是因为学习率太大的问题。

