玩转TCP
玩转TCP
目前已经有了Netty基础,正在学习Go的net包,以此出发进行TCP的学习。
沾包和半包
当不存在任何的处理方式的时候
- 一份数据可能会超出MSS,那这样可能就会超出我们的一个包的范围,那就会导致半包的出现。
- 一份数据太小了,所以TCP没想着直接给它传出去,性价比太低,所以和其他的一起传过去了,如果没有区分的办法,这样就会导致沾包
- 说道沾包就不得不提到Nagle算法
Nagle算法
由于TCP觉得说单独发一份很小的数据,太亏了,所以他想着堆积着很多数据的时候才发送出去。
具体策略为:
- 如果现在没有已发送但没有接受到的数据,直接发送
- 如果现在有已发送但没有接受到的数据,就等待收到这个数据,或者TCP包达到了MTU大小,一起发出去
- 在接受的时候,又有一种东西叫延迟确认
延迟确认
延迟确认的意思就是,TCP也觉得单独发一个ACK太亏了,想把数据一起发送出去,所以它要等待一下,看看有没有附带的数据一起发送出去,所以它有一个延迟确认时间。
- 最大延迟确认时间:超过了这个时间还没有数据就发送
- 最小延迟确认时间:如果到了这个时间,有数据就发送,没有就等着最大延迟确认
如何解决沾包和半包
在Netty中解决
在Netty中,加入了几个编码解码器,就约定俗成的对这些数据进行了拆分,知道了哦,这一块有这个结束符号,我可以知道这是属于这份数据的。

Go中进行TCP连接
Go的TCP服务端
package main
import (
"bufio"
"fmt"
"io"
"learngo/tcp/proto"
"net"
)
func process(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
for {
msg, err := proto.Decode(reader)
if err == io.EOF {
return
}
if err != nil {
fmt.Println("decode message, err: ", err)
return
}
fmt.Println("收到消息: ", msg)
}
}
func main() {
fmt.Println("服务器监听开始")
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed : ", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn)
}
}
Go的TCP客户端
package main
import (
"fmt"
"learngo/tcp/proto"
"net"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("connected failed: ", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := "Hello, hi, im your daddy do you know"
data, err := proto.Encode(msg)
if err != nil {
fmt.Println("encode failed :", err)
return
}
conn.Write(data)
}
}
编码,消息头带上消息长度
package proto
import (
"bufio"
"bytes"
"encoding/binary"
)
func Encode(message string) ([]byte, error) {
// 读取消息的长度
var length = int32(len(message)) //32位的int为4B
var pkg = new(bytes.Buffer)
// 把长度先写到消息头里面
err := binary.Write(pkg, binary.LittleEndian, length)
if err != nil {
return nil, err
}
// 写入消息
err = binary.Write(pkg, binary.LittleEndian, []byte(message))
if err != nil {
return nil, err
}
return pkg.Bytes(), nil
}
func Decode(reader *bufio.Reader) (string, error) {
// 读一下消息的长度
lengthByte, _ := reader.Peek(4) // 32位int是4字节
lengthBuff := bytes.NewBuffer(lengthByte)
var length int32
err := binary.Read(lengthBuff, binary.LittleEndian, &length)
if err != nil {
return "", err
}
// 出错了,没有这么多内容
if int32(reader.Buffered()) < length+4 {
return "", err
}
pkg := make([]byte, int(4+length))
_, err = reader.Read(pkg)
if err != nil {
return "", err
}
return string(pkg[4:]), nil
}
TCP连接-三次握手
三次握手真的也是特别经典的面试题了。
三次握手过程:
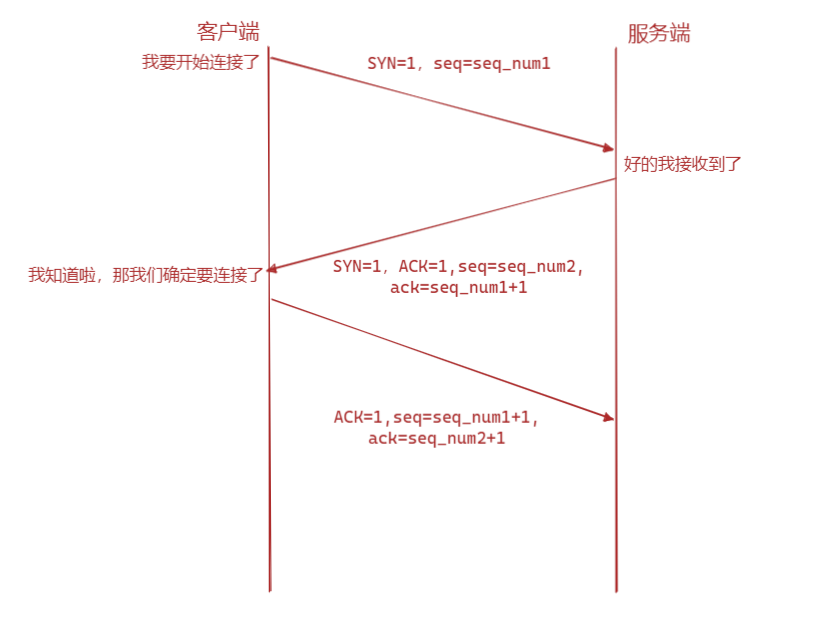
三次握手就是一个双重确认!
问题:
- 为什么两次挥手不行
- 从上面的过程可以发现第三次握手是可以携带数据的,前两次握手是不可以携带数据的,这也是面试常问的题,第三次就不再是SYN包
为什么一定是三次握手
接下来,以三个方面分析三次握手的原因:
三次握手才可以阻止重复历史连接的初始化(主要原因)
三次握手才可以同步双方的初始序列号
三次握手才可以避免资源浪费
阻止重复历史连接
假设客户端先发了一个SYN给服务端,这时候这个客户端挂了,并且这个SYN也由于网络环境没有发到服务端
然后客户端重启了,这时候它有发SYN过去,此时两个SYN的seq_num是不同的。如果只有两次连接,服务端遇到了之前的SYN,发送了一个ACK过去,这时候客户端发现了不对劲,但是连接已经建立起来了,没办法了,所以需要第三次去判断,这个服务端返回的连接对不对。是不是历史重复连接。
同步序列号
关键就在于这个ack值,每次tcp连接都是靠ack值告诉对面我期望接受到的seq_num是什么,这样可以确保连接同步。
资源消耗
由于第一次握手可能会导致重发,而也许之前的报文没有丢,这样每次没丢的报文,就可能会导致新建一次连接,新建连接是要耗费资源的,没必要
总结下来其实就是三次握手是为了保证这次连接只发送这次连接的同步发送数据,并不受其他数据包的影响
TCP断开连接-四次挥手
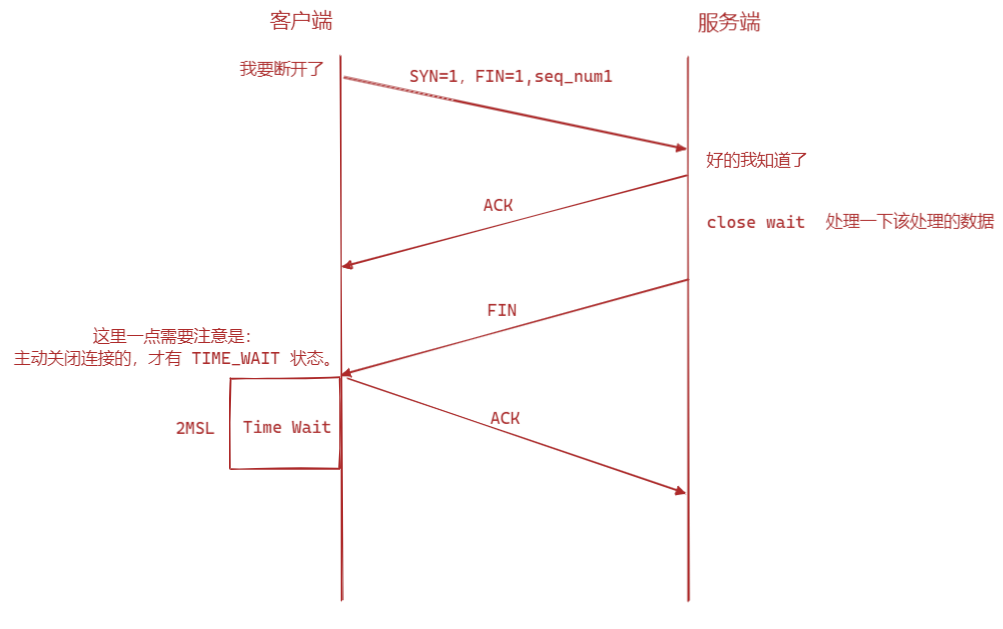
什么时候是三次挥手/CloseWait的必要的吗
- 当服务端没有东西要发送的时候,或者是close暴力处理,直接让客户端没有接受和发送能力了,shutdown就不会。然后开启了TCP延迟发送,这时候他可能就会导致只有三次挥手
TimeWait状态
- 让所有的报文都死掉,保证这次连接的报文不会影响到下一次
- 确保ack报文让服务端能够接受到
TCP某一方异常断开会发生什么
回想到锁
如果一个线程获取到了锁,但是它由于某种卡了,这时候设置好了心跳检测,觉得它故障了,所以把锁释放了。然后B去获得了锁,但是这时候A其实没坏,它回过来把B好不容易获得的锁给释放了。
所以当“异常断开”的时候,怎么处理也是一门学问。
TCP的处理
客户端崩溃
TCP的保活机制:
如果开启了 TCP 保活,需要考虑以下几种情况:
第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
第二种,对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
第三种,是对端程序崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡
这就关乎于心跳检测了,服务器会去检测客户端是不是还活着,设置了一个keepalive_timeout,超过了这个时间还不反应,那就说明它挂了,断开连接
服务端崩溃
服务端崩溃就比较有意思了。
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP四次挥手的过程。
我自己做了个实验,使用 kill -9 来模拟进程崩溃的情况,发现在 kill 掉进程后,服务端会发送 FIN 报文,与客户端进行四次挥手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号