Innodb-缓冲池
缓冲池

缓存这个东西是在开发当中使用特别多的东西,理解他也特别重要
虽然我们现在工业开发都是使用的第三方的缓存如redis,但是Mysql的缓存也是比较重要的东西。
如果出现了update,redis无法解决要到Mysql里去改,那就可能会命中Mysql的缓存,这个时候就能帮上大忙。
对于这些在缓存中修改过的页,我们称之为脏页,这些脏页需要刷新回磁盘,但不是一修改就刷新到磁盘,这样的效率太低了,而是有个checkpoint去修改。
缓冲池有两个比较重要的参数:
- 缓冲池大小 innodb_buffer_pool_size 默认128MB
- 缓冲池实例个数 innodb_buffer_pool_instances 默认为8
但是缓冲池实例个数只有在缓冲池大小大于1G的时候才会生效,所以还只有一个。因为当缓存池默认为128MB的时候你还给人家分成8个,那突然来了一个大的数据,都没办法存下了。
缓冲池的管理
缓冲池的管理简而言之就是有一个链维系着缓存页,有一个链维系着脏链。用了LRU算法去进行淘汰。
在其中它的LRU算法是经过了改善的。它不是放到队首了,而是放到挤掉了3/8(innodb_old_blocks_pct)的元素,这就避免一个新来的页,一下子就当成了热点页,热点页还是热点页
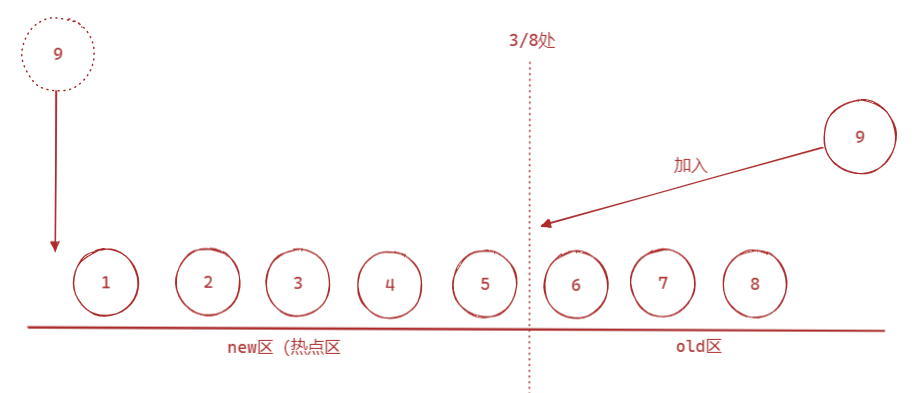
具体策略:
- 第一次加载的页会被放到old区的头部,那这样就不会说冲掉了热点区的数据
- 第二次读取的时候,如果时间间隔超过了innodb_old_blocks_time(默认1000、ms),那就顺理成章的放到new区的头部
- 为什么要这么做的,是为了提高缓存的命中率,由于有预读和全表扫描的存在。缓存中容易冲入一些可能用不到的时候,却占据了new区。所以需要分区处理,第一次去old区头部。再加上全表扫描的特点是短时间内频繁访问同一个页,那我们只要控制超过这个时间才算热点,那就合理了。而且说不准在这个时间范围内,它已经被冲走了,都不存在old区了。
页的管理
默认页的大小是16KB,但是也会有被压缩的页,碎片页。
例如对需要从缓冲池中申请页为4KB的大小,其过程如下:
1)检查4KB的unzip_LRU列表,检查是否有可用的空闲页;
2)若有,则直接使用;
3)否则,检查8KB的unzip_LRU列表;
4)若能够得到空闲页,将页分成2个4KB页,存放到4KB的unzip_LRU列表;
5)若不能得到空闲页,从LRU列表中申请一个16KB的页,将页分为1个8KB的页、2个4KB的页,分别存放到对应的unzip_LRU列表中。
什么时候刷新脏页
- 重做日志满了
- 缓冲池不够用了,比如LRU算法淘汰了一个脏页,那怎么行,必须先checkpoint
重做日志缓冲
理解到重做日志其实是一直在被复用的,就位置那么大,用完我也不主动清理,你可以把我覆盖掉。
在Innodb里面的处理是,如果有页被修改,先写重做日志,再去修改页,极大可能的保证了持久性
它配置参数innodb_log_buffer_size控制,默认为8MB
- 每一秒Master Thread都会进行一次重做日志刷新
- 事务提交的时候
- 重做日志超过了1/2的内存
checkpoint
检查点也就是规定了从哪里开始算是需要被刷新的东西,之前的都是已经在磁盘里面了。
- 重做日志满了,赶紧checkpoint,因为修改页先写重做日志,都写不了重做日志了,那不完蛋
- 缓冲池不够用了,比如LRU算法淘汰了一个脏页,那怎么行,必须先checkpoint
checkpoint是通过lsn来控制哪些页,哪些重做日志需要被刷新回磁盘的。
在InnoDB存储引擎中,Checkpoint发生的时间、条件及脏页的选择等都非常复杂。而Checkpoint所做的事情无外乎是将缓冲池中的脏页刷回到磁盘。不同之处在于每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发Checkpoint。在InnoDB存储引擎内部,有两种Checkpoint,分别为:
❑Sharp Checkpoint -全量
❑Fuzzy Checkpoint -增量
Sharp Checkpoint发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,即参数innodb_fast_shutdown=1。
但是若数据库在运行时也使用Sharp Checkpoint,那么数据库的可用性就会受到很大的影响。故在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号