
R语言学习笔记-Corrplot相关性分析
示例图像
首先安装需要的包
install.packages("Corrplot") #安装Corrplot
install.packages("RColorBrewer ") #安装RColorBrewer
install.packages("showtext")#安装showtext
install.packages("sysfonts")#安装sysfonts
install.packages("showtextdb")#安装showtextdb
install.packages("showtext")#安装RColorBrewer
加载需要的包
lapply(c("corrplot","showtex","RColorBrewer","showtextdb","sysfonts"))
如果需要更换字体,就加载系统内字体
font.families() #查看添加的字体 showtext.begin() #加载字体 **showtext.end() #停止加载字体
导入数据[示例]
mydataframe<-read.csv(file,header=logical_value,sep="delimiter",row.names="name")
mydataframe:自定义数据名称,此处将集合名称定义为mydataframe table:指读取文件格式为表格 file: csv文件的名称或路径夹名称 header:其后面逻辑值,可填写TRUE或FALSE,表示文件是否读取横列标题 sep:指文件分隔符,如csv用英文逗号分隔 "," row.names:指定表示行标识符的变量(作为行名的表头)
本次利用自带的mtcars作为示例data(mtcars)#加载数据集
mydata <- mtcars[, c(1:7)]#使用前7行数据
查看数据
head(mydata)#查看数据
绘制图像
pic01<-cor(mydata) corrplot(pic01)
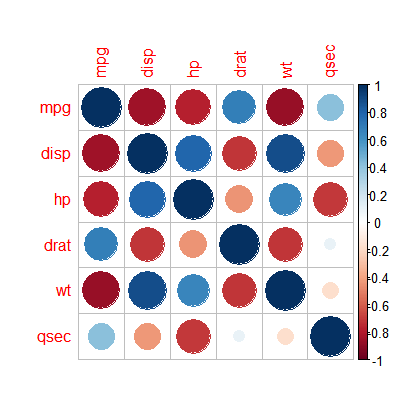
corrplot(mydata)
可以在括号内加入如下定义,改变图像。
method = c("circle"/"square"/"ellipse"/"number"/ "shade"/"color"/"pie"),
method:指定可视化的方法,可以是圆形、方形、椭圆形、数值、阴影、颜色或饼图形
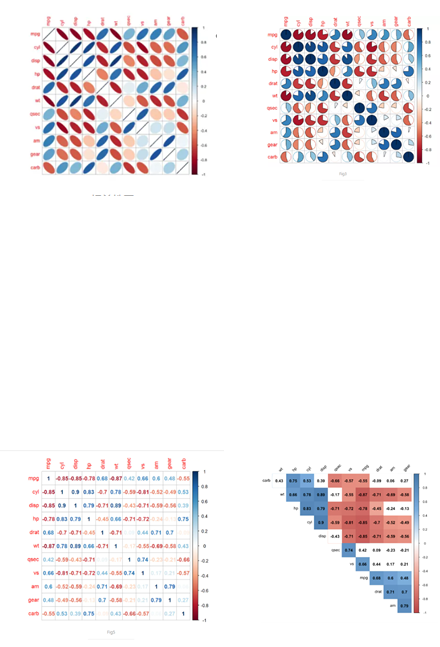
type = c("full"/"lower"/"upper"),
type:指定展示的方式,可以是完全的图形、上三角或下三角(不填时默认为“full”)
col:指定图像的几种颜色,默认以均匀的颜色展示,以col = c("purple", "green","white")),为例,即指图标在(-1,1)区间以紫色、绿色、白色三种颜色的改变表示。
****可以通过colorRampPalette定义
COLOR01<- colorRampPalette(c("#5081ff","#638dff","#b1c6ff","#c3d5ff" ,"#ffffff", "#f7cccc","#f1aeac","#eb8b8a","#e66a68"))(10)
corrplot(pic01,col = COLOR01)
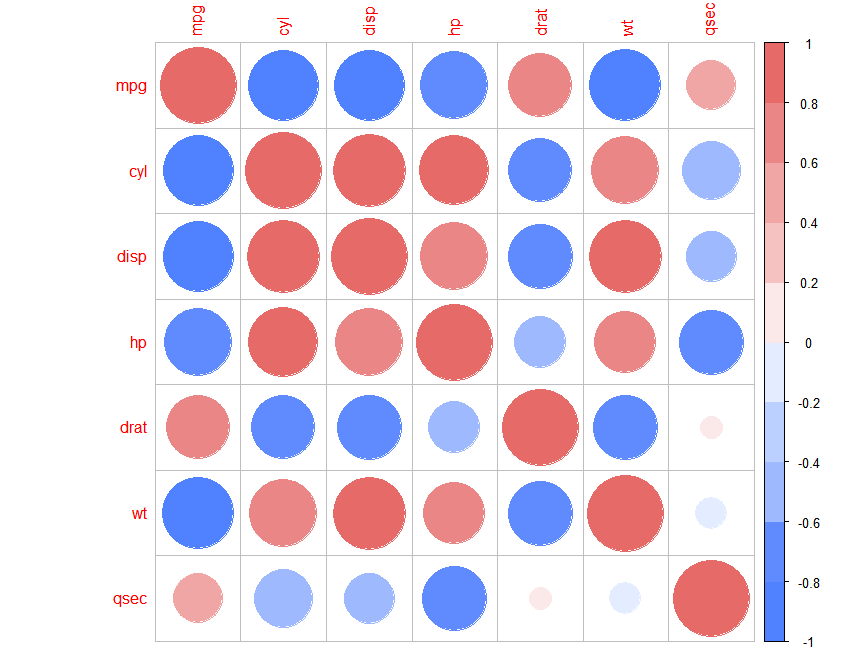
bg = c("white"/"black"/"pink"/……),
bg:指定图的背景色
title = "HokkaidoM",
mar=c(0, 0, 1, 0)
title:为图形添加标题
mar=c(0, 0, 1, 0) :设置图距离(下,左,上,右)四个边缘的距离
*****若使用标题title必须加mar=c(0, 0, 1, 0),不然标题显示不全
is.corr = TRUE,
is.corr:是否为相关系数绘图,默认为TRUE,同样也可以实现非相关系数的可视化,只需使该参数设为FALSE即可
diag = TRUE,
diag:是否展示对角线上的结果,默认为TRUE
outline = FALSE,
outline:是否绘制圆形、方形或椭圆形的轮廓,默认为FALSE
addgrid.col = NULL,
addgrid.col:当选择的方法为颜色或阴影时,默认的网格线颜色为白色,否则为灰色
addCoef.col = NULL,
addCoef.col:为相关系数添加颜色,默认不添加相关系数,只有方法为number时,该参数才起作用
addCoefasPercent = FALSE,
addCoefasPercent:为节省绘图空间,是否将相关系数转换为百分比格式,默认为FALSE
order = c("original", "AOE", "FPC", "hclust", "alphabet"),
hclust.method = c("complete", "ward", "single", "average", "mcquitty", "median", "centroid"),
order:指定相关系数排序的方法,可以是原始顺序(original)、特征向量角序(AOE)、第一主成分顺序(FPC)、层次聚类顺序(hclust)和字母顺序,一般”AOE”排序结果都比”FPC”要好
hclust.method:当order为hclust时,该参数可以是层次聚类中ward法、最大距离法等7种之一
addrect = NULL,
rect.col = "black",
rect.lwd = 2,
addrect:当order为hclust时,可以为添加相关系数图添加矩形框,默认不添加框,如果想添加框时,只需为该参数指定一个整数即可
rect.col:指定矩形框的颜色
rect.lwd:指定矩形框的线宽
tl.pos = NULL,
tl.pos:指定文本标签(变量名称)的位置,当type=full时,默认标签位置在左边和顶部(lt),当type=lower时,默认标签在左边和对角线(ld),当type=upper时,默认标签在顶部和对角线,l、r代表左右,d表示对角线,n表示不添加文本标签
tl.cex = 1,
tl.cex:指定文本标签的大小
tl.col = "red",
tl.col:指定文本标签的颜色
tl.offset = 0.4,
tl.offset:设置文本标签偏移量,即文本标签和图像的距离
tl.srt = 90,
tl.srt:文本标签角度
cl.pos = "b"/"r"/"n"
cl.pos:图例(颜色)位置,r图例在右表,b图例在底部,不需要图例时,只需指定该参数为n
cl.lim = (x1,x2),
颜色区间限制
cl.length = 数字
颜色区间刻度间隔的数量
cl.cex = 0.8,
颜色刻度标签数字大小
cl.ratio = 0.15,
颜色刻度粗细
cl.align.text = "l","c","r",
刻度标签数字显示在每个刻度的靠左处/中央/靠右处
cl.offset = 0.5,
刻度标签与颜色刻度条的距离
addshade = c("negative", "positive", "all"),
addshade:只有当method=shade时,该参数才有用,参数值可以是negtive/positive和all,分表表示对负相关系数、正相关系数和所有相关系数添加阴影。注意:正相关系数的阴影是45度,负相关系数的阴影是135度
shade.lwd = 1,
shade.lwd:指定阴影的线宽
shade.col = "white",
shade.col:指定阴影线的颜色
addCoef.col=”颜色”
addCoef.col:增加p值
add = TRUE
add = :是否与另一图片拼接,默认为false
p.mat 分析/显著性分析
cor.mtest <- function(mat, ...) {
mat <- as.matrix(mat)
n <- ncol(mat)
p.mat<- matrix(NA, n, n)
diag(p.mat) <- 0
for (i in 1:(n - 1)) {
for (j in (i + 1):n) {
tmp <- cor.test(mat[, i], mat[, j], ...)
p.mat[i, j] <- p.mat[j, i] <- tmp$p.value
}
}
colnames(p.mat) <- rownames(p.mat) <- colnames(mat)
p.mat
}
#构建cor.mtest函数
mydatap<- cor.mtest(mydata) #计算原始数据的p.mat并定义此数据集合
sig.level = 0.05,
筛选的标准以0.05为界
sig.level = c(0.001,0.01,0.05)
设置筛选的各个区间值
insig = c("pch","p-value","blank", "n"),
被筛选的不显著值为叉叉、p值数字、不显示任何东西、n
insig = "label_sig"
设置被筛选出的为显著值
pch = 4, pch.col = "black", pch.cex = 3,
plotCI = c("n","square", "circle", "rect"),
lowCI.mat = NULL,
uppCI.mat = NULL, ...)
corrplot(pic01, type = "upper", order = "hclust", p.mat=mydatap, sig.level = 0.05, insig = "label_sig")#绘图,标记显著值
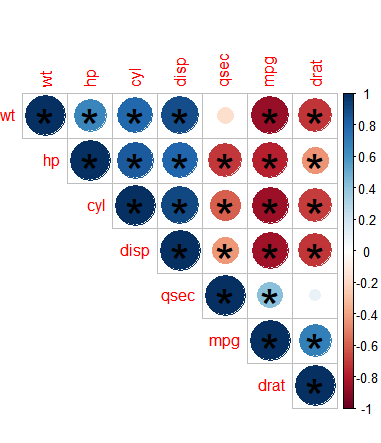
corrplot(pic01, type="upper", order="hclust", p.mat = mydatap, sig.level = 0.05)#绘图,把不显著的叉掉

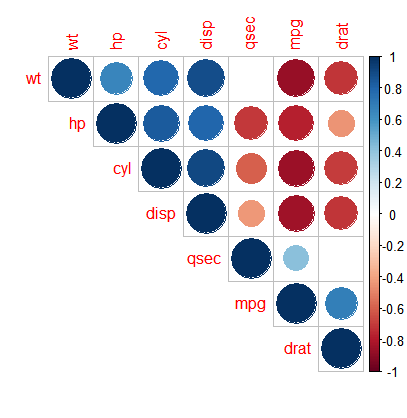
corrplot(pic01, type = "upper", order = "hclust", p.mat=mydatap, sig.level = 0.05, insig="blank") #绘图,把不显著的空掉
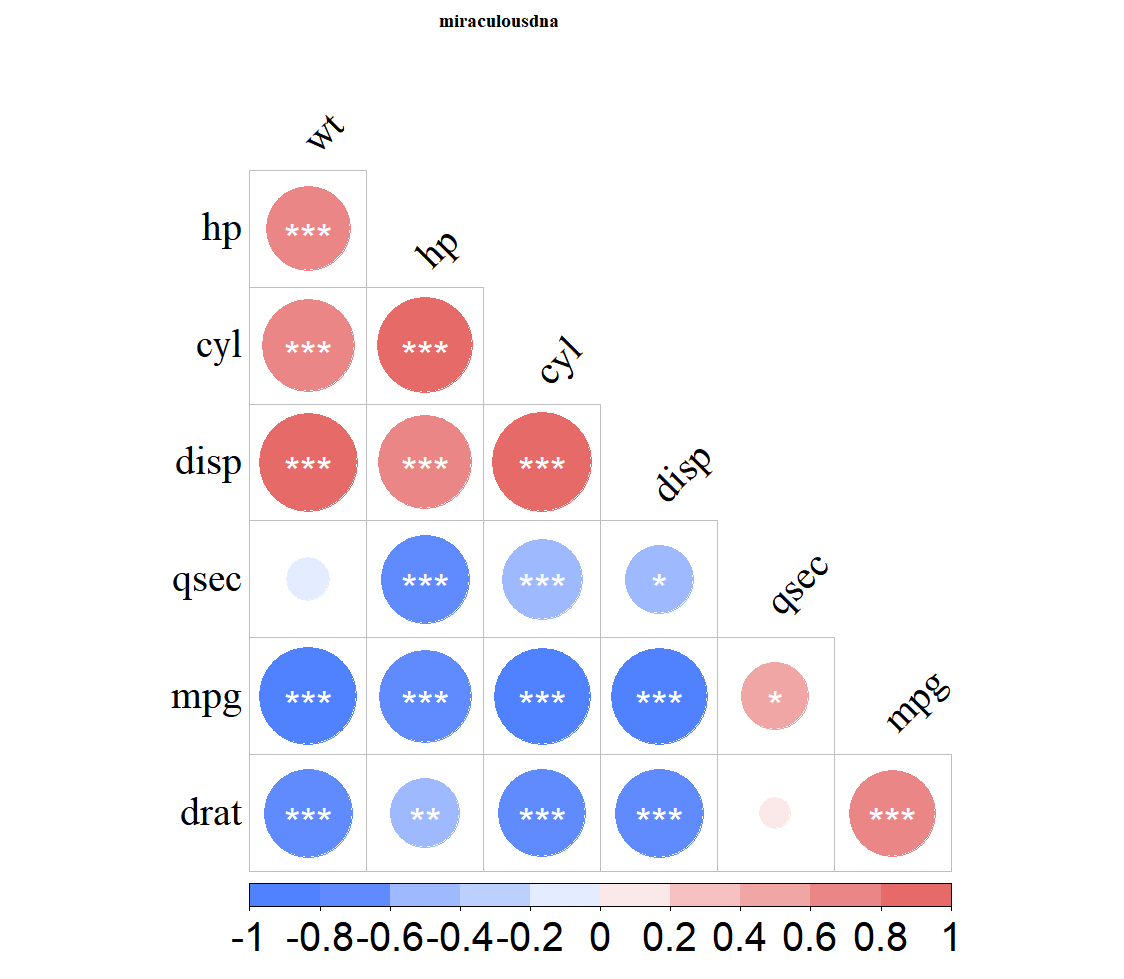
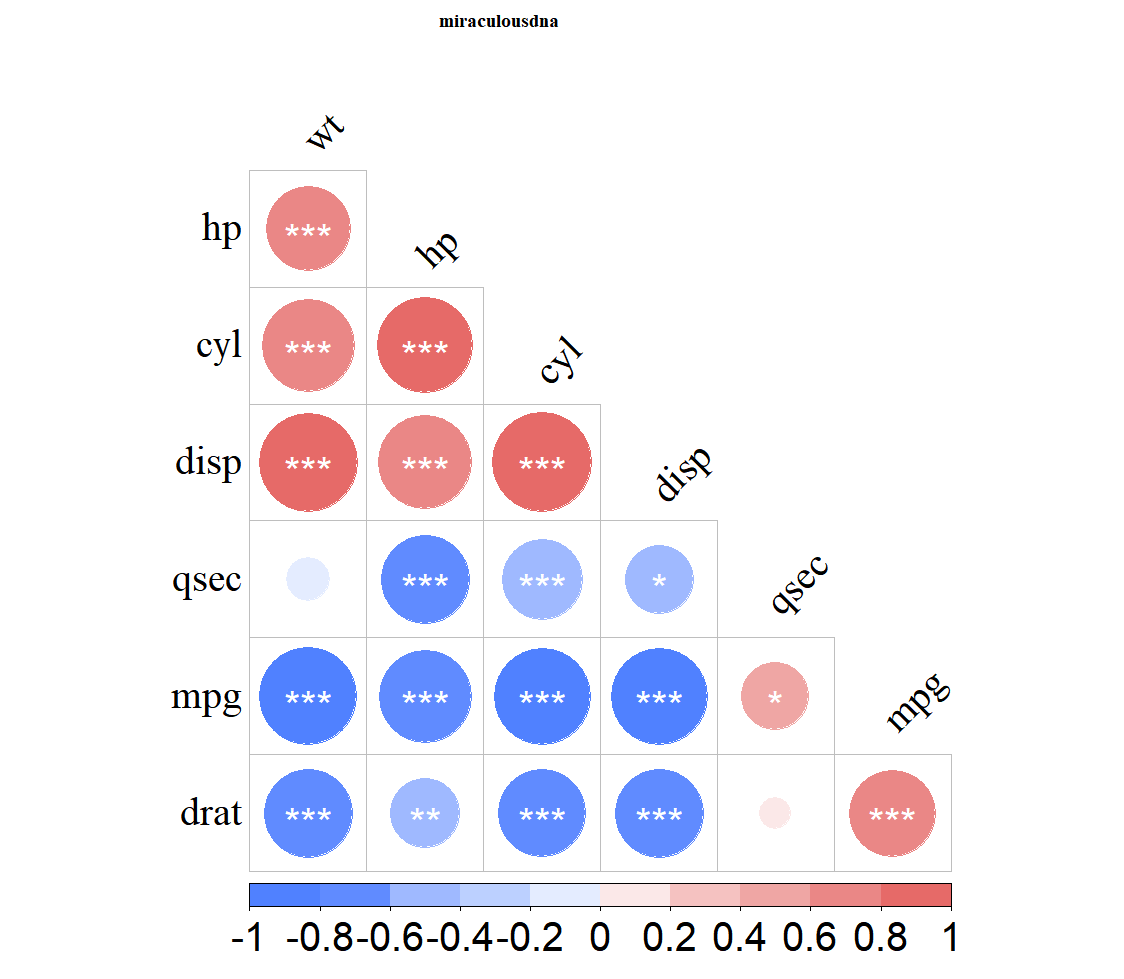
corrplot(pic01, type="lower", order="hclust", p.mat=mydatap, insig = "label_sig", sig.level = c(0.001,0.01,0.05), pch.cex = 2.5,pch.col="white", diag = FALSE,tl.srt =45,tl.col = "black", family="serif",col = COLOR01, tl.cex = 2.5,title = "miraculousdna", mar=c(0, 0, 1, 0),cl.cex = 2.5 )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号