
std::get<C++11多线程库~线程间共享数据>(10):使用互斥量保护共享数据(5)
1 /* 2 * 话题1:使用互斥量保护共享数据 3 * 4 * 接下来学习第五个小话题:避免死锁的进阶指导 5 * 6 * 这一小节的内容,完全引用,只在最后补充上我对这部分的理解,以及更多一点的想法 7 */
!!! 非常有意思的是下面讲到的 “使用锁的层次结构”。 锁的层次的意义在于提供对运行时约定是否被坚持的检查。它做到了运行时出现死锁的检查。
死锁通常是由于对锁的不当操作造成,但也不排除死锁出现在其他地方。无锁的情况下,仅需要每个std::thread对象调用join(),两个线程就能产生死锁。这种情况下,没有线程可以继续运行,因为他们正在互相等待。这种情况很常见,一个线程会等待另一个线程,其他线程同时也会等待第一个线程结束,所以三个或更多线程的互相等待也会发生死锁。为了避免死锁,这里的指导意见为:当机会来临时,不要拱手让人。以下提供一些个人的指导建议,如何识别死锁,并消除其他线程的等待。
避免嵌套锁
第一个建议往往是最简单的:一个线程已获得一个锁时,再别去获取第二个。因为每个线程只持有一个锁,锁上就不会产生死锁。即使互斥锁造成死锁的最常见原因,也可能会在其他方面受到死锁的困扰(比如:线程间的互相等待)。当你需要获取多个锁,使用一个std::lock来做这件事(对获取锁的操作上锁),避免产生死锁。
避免在持有锁时调用用户提供的代码
第二个建议是次简单的:因为代码是用户提供的,你没有办法确定用户要做什么;用户程序可能做任何事情,包括获取锁。你在持有锁的情况下,调用用户提供的代码;如果用户代码要获取一个锁,就会违反第一个指导意见,并造成死锁(有时,这是无法避免的)。当你正在写一份通用代码,例如3.2.3中的栈,每一个操作的参数类型,都在用户提供的代码中定义,就需要其他指导意见来帮助你。
使用固定顺序获取锁
当硬性条件要求你获取两个或两个以上的锁,并且不能使用std::lock单独操作来获取它们;那么最好在每个线程上,用固定的顺序获取它们(锁)。3.2.4节中提到,当需要获取两个互斥量时,避免死锁的方法,关键是如何在线程之间,以一定的顺序获取锁。一些情况下,这种方式相对简单。比如,3.2.3节中的栈——每个栈实例中都内置有互斥量,但是对数据成员存储的操作上,栈就需要调用用户提供的代码。虽然,可以添加一些约束,对栈上存储的数据项不做任何操作,对数据项的处理仅限于栈自身。这会给用户提供的栈增加一些负担,但是一个容器很少去访问另一个容器中存储的数据,即使发生了也会很明显,所以这对于通用栈来说并不是一个特别沉重的负担。
其他情况下,这就没那么简单了,例如:3.2.4节中的交换操作,这种情况下你可能同时锁住多个互斥量(有时不会发生)。回看3.1节中那个链表连接例子时,会看到列表中的每个节点都会有一个互斥量保护。为了访问列表,线程必须获取他们感兴趣节点上的互斥锁。当一个线程删除一个节点,它必须获取三个节点上的互斥锁:将要删除的节点,两个邻接节点(因为他们也会被修改)。同样的,为了遍历链表,线程必须保证在获取当前节点的互斥锁前提下,获得下一个节点的锁,要保证指向下一个节点的指针不会同时被修改。一旦下一个节点上的锁被获取,那么第一个节点的锁就可以释放了,因为没有持有它的必要性了。
这种“手递手”锁的模式允许多个线程访问列表,为每一个访问的线程提供不同的节点。但是,为了避免死锁,节点必须以同样的顺序上锁:如果两个线程试图用互为反向的顺序,使用“手递手”锁遍历列表,他们将执行到列表中间部分时,发生死锁。当节点A和B在列表中相邻,当前线程可能会同时尝试获取A和B上的锁。另一个线程可能已经获取了节点B上的锁,并且试图获取节点A上的锁——经典的死锁场景,如图3.2所示。
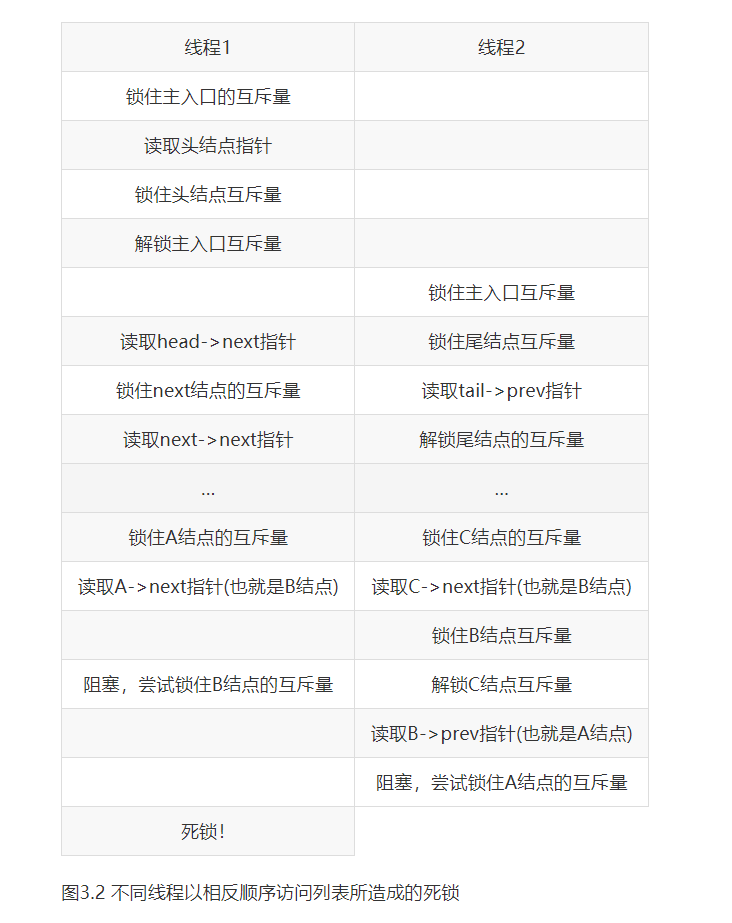
当A、C节点中的B节点正在被删除时,如果有线程在已获取A和C上的锁后,还要获取B节点上的锁时,当一个线程遍历列表的时候,这样的情况就可能发生死锁。这样的线程可能会试图首先锁住A节点或C节点(根据遍历的方向),但是后面就会发现,它无法获得B上的锁,因为线程在执行删除任务的时候,已经获取了B上的锁,并且同时也获取了A和C上的锁。
这里提供一种避免死锁的方式,定义遍历的顺序,一个线程必须先锁住A才能获取B的锁,在锁住B之后才能获取C的锁。这将消除死锁发生的可能性,不允许反向遍历的列表上。类似的约定常被用来建立其他的数据结构。
使用锁的层次结构
虽然,定义锁的顺序是一种特殊情况,但锁的层次的意义在于提供对运行时约定是否被坚持的检查。这个建议需要对你的应用进行分层,并且识别在给定层上所有可上锁的互斥量。当代码试图对一个互斥量上锁,在该层锁已被低层持有时,上锁是不允许的。你可以在运行时对其进行检查,通过分配层数到每个互斥量上,以及记录被每个线程上锁的互斥量。下面的代码列表中将展示两个线程如何使用分层互斥。
清单3.7 使用层次锁来避免死锁
1 hierarchical_mutex high_level_mutex(10000); // 1 2 hierarchical_mutex low_level_mutex(5000); // 2 3 hierarchical_mutex other_mutex(6000); // 3 4 int do_low_level_stuff(); 5 int low_level_func() 6 { 7 std::lock_guard<hierarchical_mutex> lk(low_level_mutex); // 4 8 return do_low_level_stuff(); 9 } 10 void high_level_stuff(int some_param); 11 void high_level_func() 12 { 13 std::lock_guard<hierarchical_mutex> lk(high_level_mutex); // 6 14 high_level_stuff(low_level_func()); // 5 15 } 16 void thread_a() // 7 17 { 18 high_level_func(); 19 } 20 void do_other_stuff(); 21 void other_stuff() 22 { 23 high_level_func(); // 10 24 do_other_stuff(); 25 } 26 void thread_b() // 8 27 { 28 std::lock_guard<hierarchical_mutex> lk(other_mutex); // 9 29 other_stuff(); 30 }
这段代码有三个hierarchical_mutex实例(①,②和③),其通过逐渐递减的层级数量进行构造。根据已经定义好的机制,如你已将一个hierarchical_mutex实例进行上锁,那么你只能获取更低层级hierarchical_mutex实例上的锁,这就会对代码进行一些限制。
假设do_low_level_stuff不会对任何互斥量进行上锁,low_level_func为层级最低的函数,并且会对low_level_mutex④进行上锁。high_level_func调用low_level_func⑤的同时,也持有high_level_mutex⑥上的锁,这也没什么问题,因为high_level_mutex(①:10000)要比low_level_mutex(②:5000)更高级。
thread_a()⑦遵守规则,所以它运行的没问题。
另一方面,thread_b()⑧无视规则,因此在运行的时候肯定会失败。
首先,thread_b锁住了other_mutex⑨,这个互斥量的层级值只有6000③。这就意味着,中层级的数据已被保护。当other_stuff()调用high_level_func()⑧时,就违反了层级结构:high_level_func()试图获取high_level_mutex,这个互斥量的层级值是10000,要比当前层级值6000大很多。因此hierarchical_mutex将会产生一个错误,可能会是抛出一个异常,或直接终止程序。在层级互斥量上产生死锁,是不可能的,因为互斥量本身会严格遵循约定顺序,进行上锁。这也意味,当多个互斥量在是在同一级上时,不能同时持有多个锁,所以“手递手”锁的方案需要每个互斥量在一条链上,并且每个互斥量都比其前一个有更低的层级值,这在某些情况下无法实现。
例子也展示了另一点,std::lock_guard<>模板与用户定义的互斥量类型一起使用。虽然hierarchical_mutex不是C++标准的一部分,但是它写起来很容易;一个简单的实现在列表3.8中展示出来。尽管它是一个用户定义类型,它可以用于std::lock_guard<>模板中,因为它的实现有三个成员函数为了满足互斥量操作:lock(), unlock() 和 try_lock()。虽然你还没见过try_lock()怎么使用,但是其使用起来很简单:当互斥量上的锁被一个线程持有,它将返回false,而不是等待调用的线程,直到能够获取互斥量上的锁为止。在std::lock()的内部实现中,try_lock()会作为避免死锁算法的一部分。
列表3.8 简单的层级互斥量实现
1 class hierarchical_mutex 2 { 3 std::mutex internal_mutex; 4 unsigned long const hierarchy_value; 5 unsigned long previous_hierarchy_value; 6 static thread_local unsigned long this_thread_hierarchy_value; // 1 7 void check_for_hierarchy_violation() 8 { 9 if(this_thread_hierarchy_value <= hierarchy_value) // 2 10 { 11 throw std::logic_error(“mutex hierarchy violated”); 12 } 13 } 14 void update_hierarchy_value() 15 { 16 previous_hierarchy_value=this_thread_hierarchy_value; // 3 17 this_thread_hierarchy_value=hierarchy_value; 18 } 19 public: 20 explicit hierarchical_mutex(unsigned long value): 21 hierarchy_value(value), 22 previous_hierarchy_value(0) 23 {} 24 void lock() 25 { 26 check_for_hierarchy_violation(); 27 internal_mutex.lock(); // 4 28 update_hierarchy_value(); // 5 29 } 30 void unlock() 31 { 32 if(this_thread_hierarchy_value!=hierarchy_value) 33 throw std::logic_error(“mutex hierarchy violated”); // 9 34 this_thread_hierarchy_value=previous_hierarchy_value; // 6 35 internal_mutex.unlock(); 36 } 37 bool try_lock() 38 { 39 check_for_hierarchy_violation(); 40 if(!internal_mutex.try_lock()) // 7 41 return false; 42 update_hierarchy_value(); 43 return true; 44 } 45 }; 46 thread_local unsigned long 47 hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX); // 8
这里重点是使用了thread_local的值来代表当前线程的层级值:this_thread_hierarchy_value①。它被初始化为最大值⑧,所以最初所有线程都能被锁住。因为其声明中有thread_local,所以每个线程都有其拷贝副本,这样线程中变量状态完全独立,当从另一个线程进行读取时,变量的状态也完全独立。参见附录A,A.8节,有更多与thread_local相关的内容。
所以,第一次线程锁住一个hierarchical_mutex时,this_thread_hierarchy_value的值是ULONG_MAX。由于其本身的性质,这个值会大于其他任何值,所以会通过check_for_hierarchy_vilation()②的检查。在这种检查方式下,lock()代表内部互斥锁已被锁住④。一旦成功锁住,你可以更新层级值了⑤。
当你现在锁住另一个hierarchical_mutex时,还持有第一个锁,this_thread_hierarchy_value的值将会显示第一个互斥量的层级值。第二个互斥量的层级值必须小于已经持有互斥量检查函数②才能通过。
现在,最重要的是为当前线程存储之前的层级值,所以你可以调用unlock()⑥对层级值进行保存;否则,就锁不住任何互斥量(第二个互斥量的层级数高于第一个互斥量),即使线程没有持有任何锁。因为保存了之前的层级值,只有当持有internal_mutex③,且在解锁内部互斥量⑥之前存储它的层级值,才能安全的将hierarchical_mutex自身进行存储。这是因为hierarchical_mutex被内部互斥量的锁所保护着。为了避免无序解锁造成层次结构混乱,当解锁的互斥量不是最近上锁的那个互斥量,就需要抛出异常⑨。其他机制也能做到这点,但目前这个是最简单的。
try_lock()与lock()的功能相似,除了在调用internal_mutex的try_lock()⑦失败时,不能持有对应锁,所以不必更新层级值,并直接返回false。
虽然是运行时检测,但是它没有时间依赖性——不必去等待导致死锁出现的罕见条件。同时,设计过程需要去拆分应用,互斥量在这种情况下可以消除导致死锁的可能性。这样的练习很有必要去做一下,即使你之后没有去做,代码也会在运行时进行检查。
超越锁的延伸扩展
如我在本节开头提到的那样,死锁不仅仅会发生在锁之间;死锁也会发生在任何同步构造中(可能会产生一个等待循环),因此这方面也需要有指导意见,例如:要去避免获取嵌套锁等待一个持有锁的线程是一个很糟糕的决定,因为线程为了能继续运行可能需要获取对应的锁。类似的,如果去等待一个线程结束,它应该可以确定这个线程的层级,这样一个线程只需要等待比其层级低的线程结束即可。用一个简单的办法便可确定,以添加的线程是否在同一函数中被启动,如同在3.1.2节和3.3节中描述的那样。
代码已能规避死锁,std::lock()和std::lock_guard可组成简单的锁,并覆盖大多数情况,但是有时需要更多的灵活性。在这种情况下,可以使用标准库提供的std::unique_lock模板。如std::lock_guard,这是一个参数化的互斥量模板类,并且它提供很多RAII类型锁用来管理std::lock_guard类型,可以让代码更加灵活。
死锁通常是由于对锁的不当操作造成,但也不排除死锁出现在其他地方。无锁的情况下,仅需要每个std::thread对象调用join(),两个线程就能产生死锁。这种情况下,没有线程可以继续运行,因为他们正在互相等待。这种情况很常见,一个线程会等待另一个线程,其他线程同时也会等待第一个线程结束,所以三个或更多线程的互相等待也会发生死锁。为了避免死锁,这里的指导意见为:当机会来临时,不要拱手让人。以下提供一些个人的指导建议,如何识别死锁,并消除其他线程的等待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号