
字节缓冲流

减少底层调用,提高效率





用缓冲区写数据
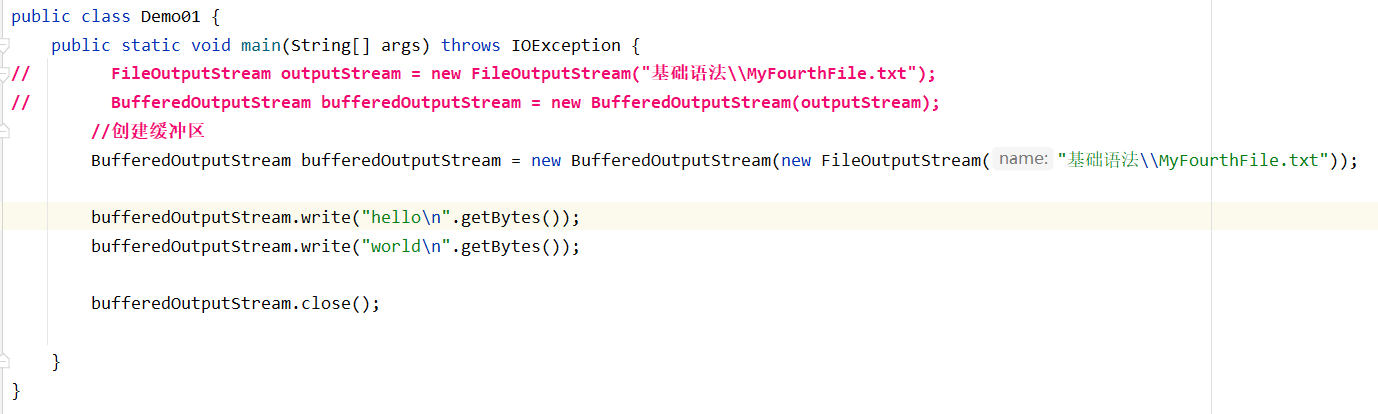
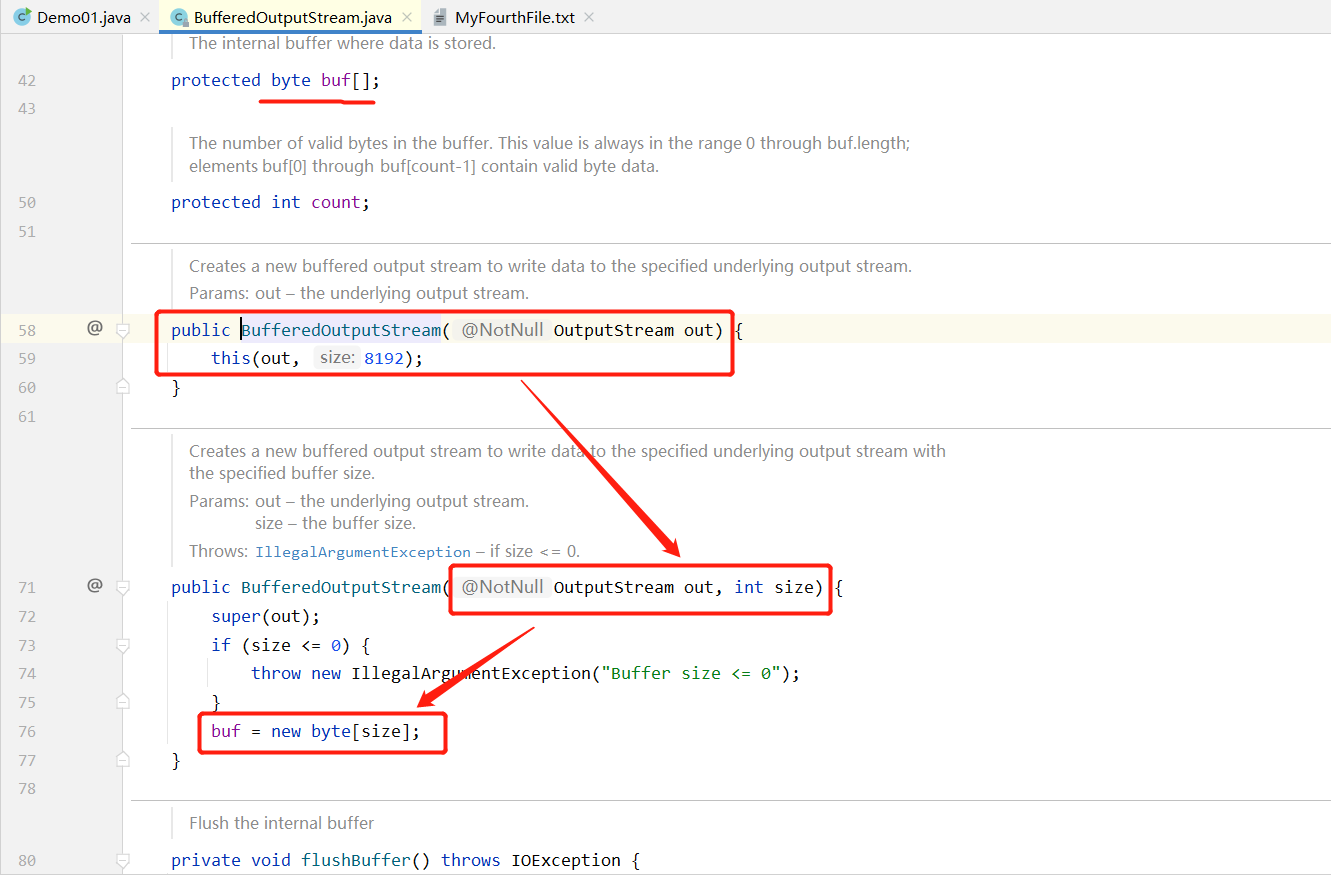
看源码,调用缓冲区构造器的时候创建了一个大小为8192字节的数组存数据作为缓冲
缓冲区读数据

复制avi视频
使用System.currentTimeMillis();计算时长

字符流
为什么要用字符流?
GBK编码占用2个字节,UTF-8编码占用3个字节

这种拿到一个字节就读了就出问题了
字节流复制中文不出问题的原因:
因为中文无论是按照GBK--2字节还是UTF-8--3字节编码,第一个字节都会是负数,这样系统按照编码方式转译

字符流的底层还是字节流
编码表








编码解码问题

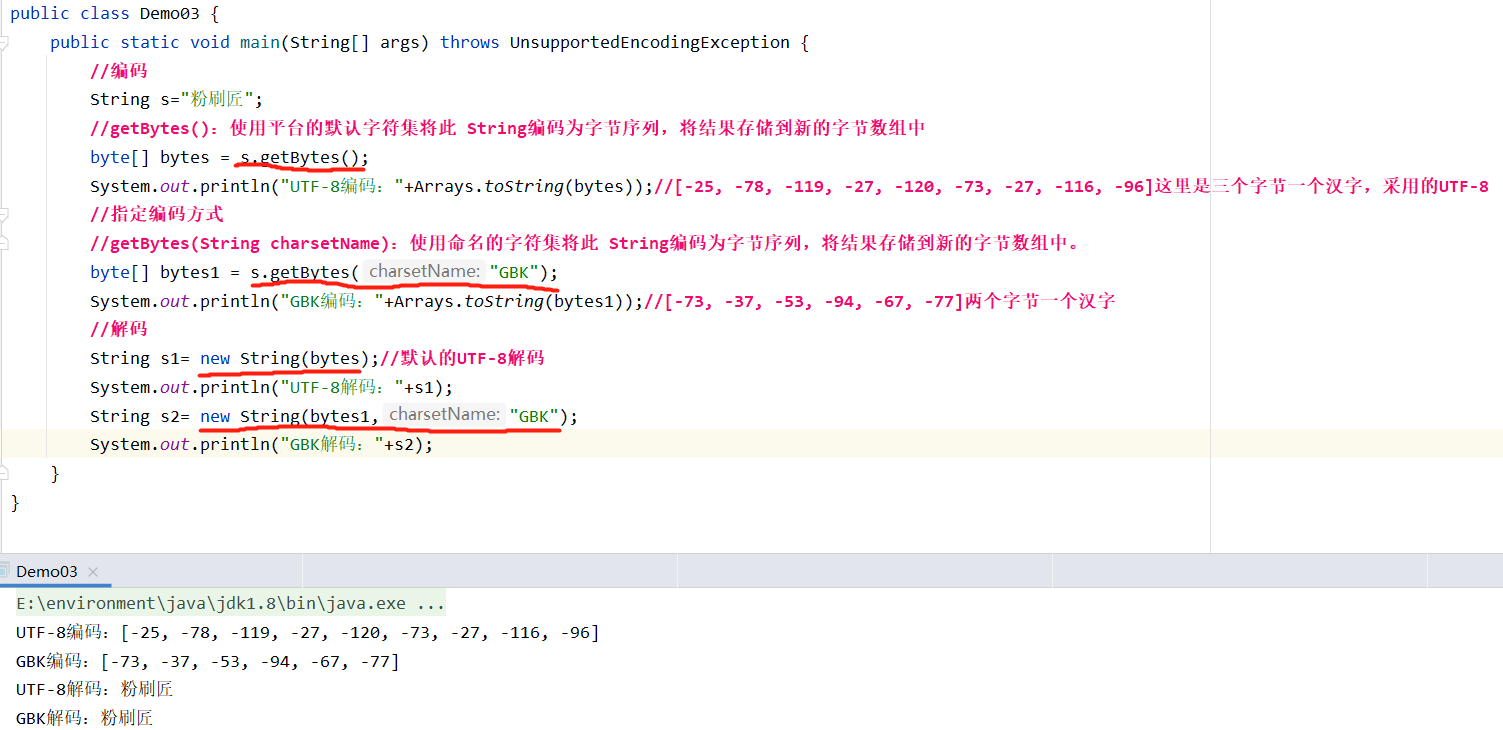
字符流的编码解码问题

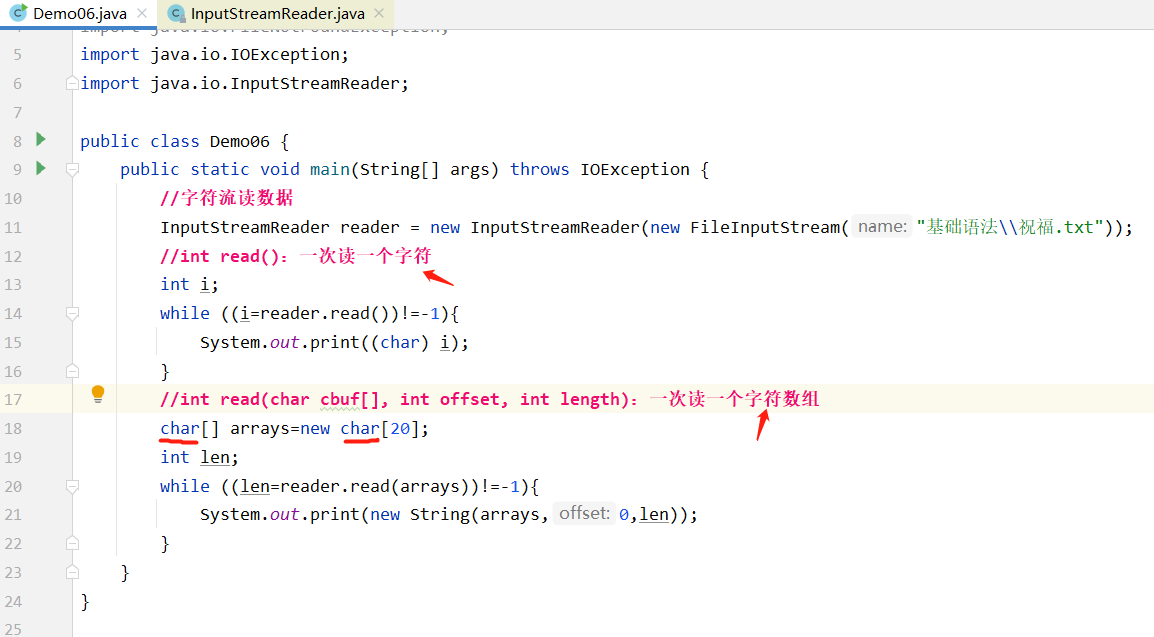
InputStreamReader类
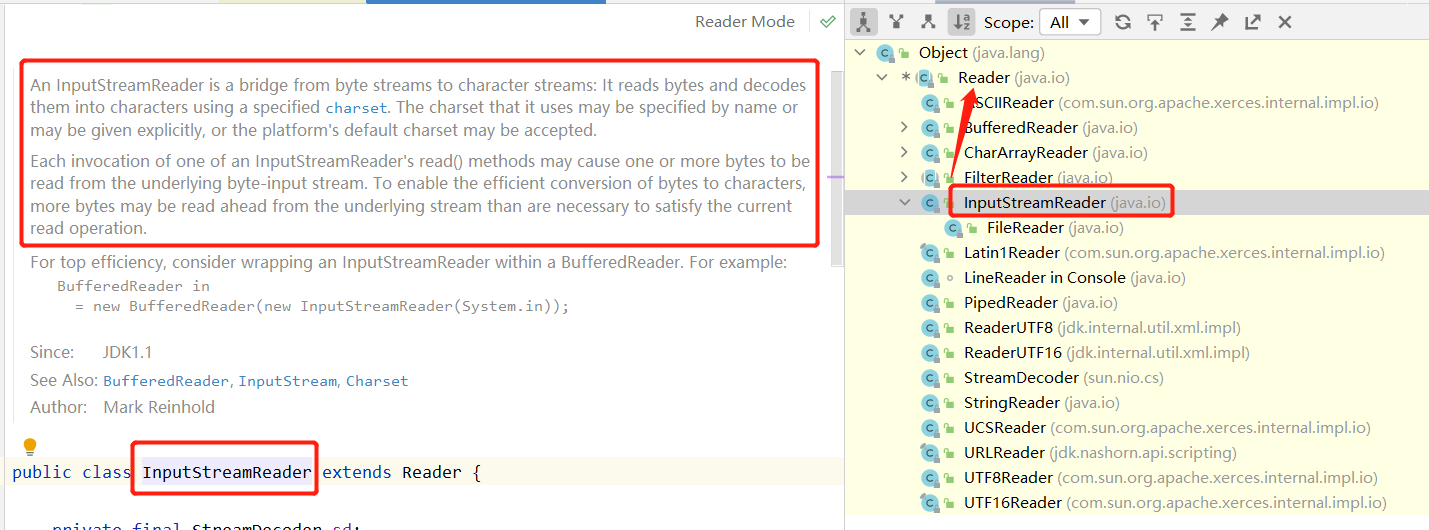

同理OutputStreamWriter类

编码构造器

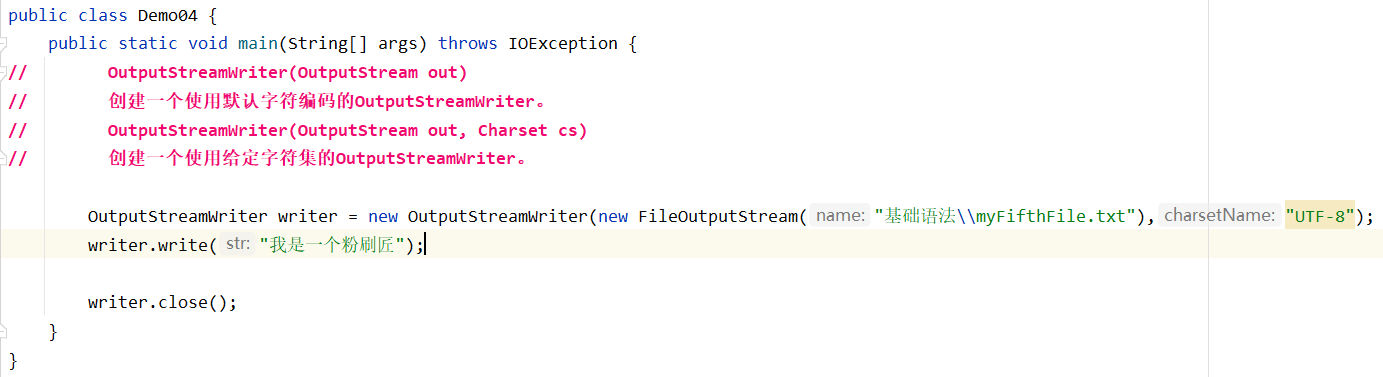
如果后面是GBK,打开文件就会出现乱码,因为文件的编码方式是UTF-8,而指定了GBK的编码方式,所以出现乱码
但如果用GBk的方式去解码就能顺利读出来
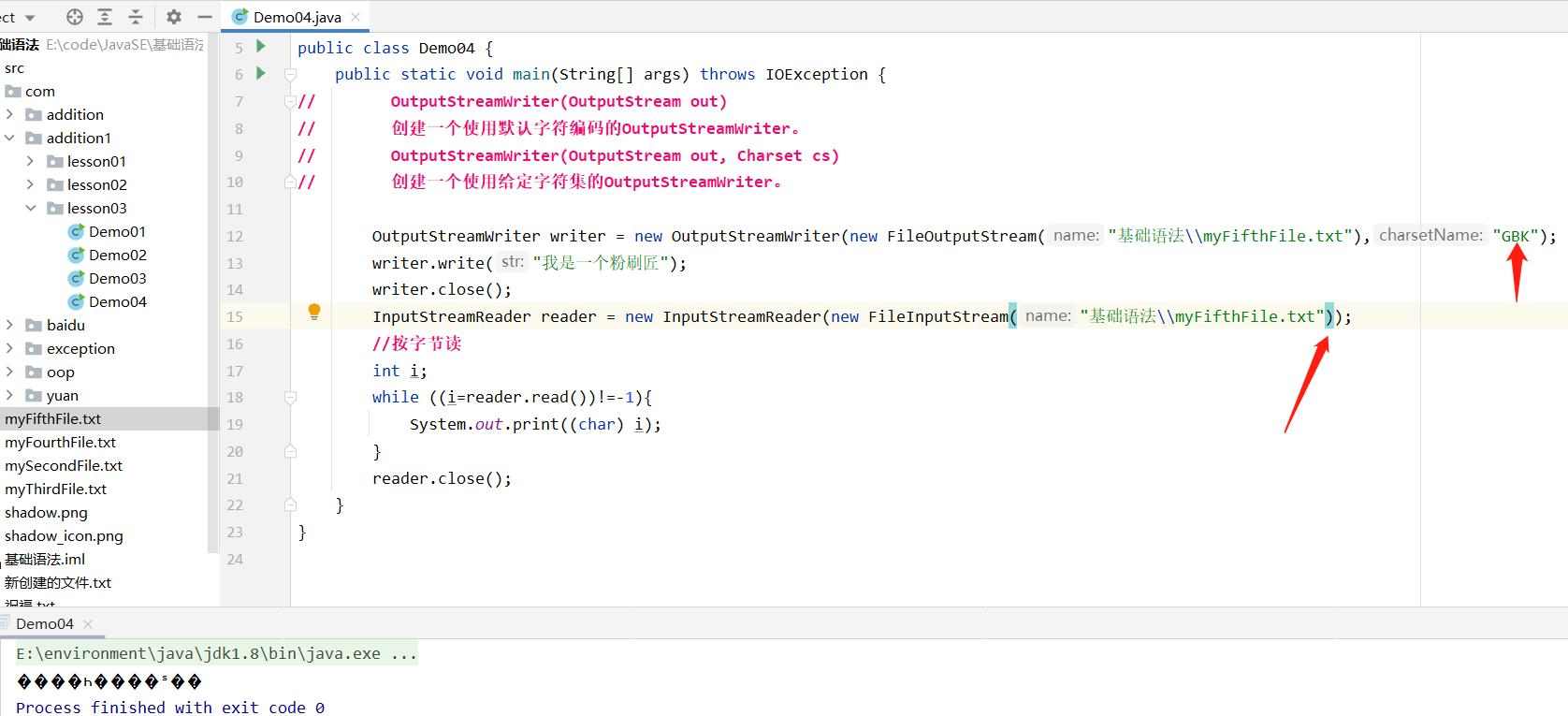
-
把用GBK编码的文件按默认UTF-8解码
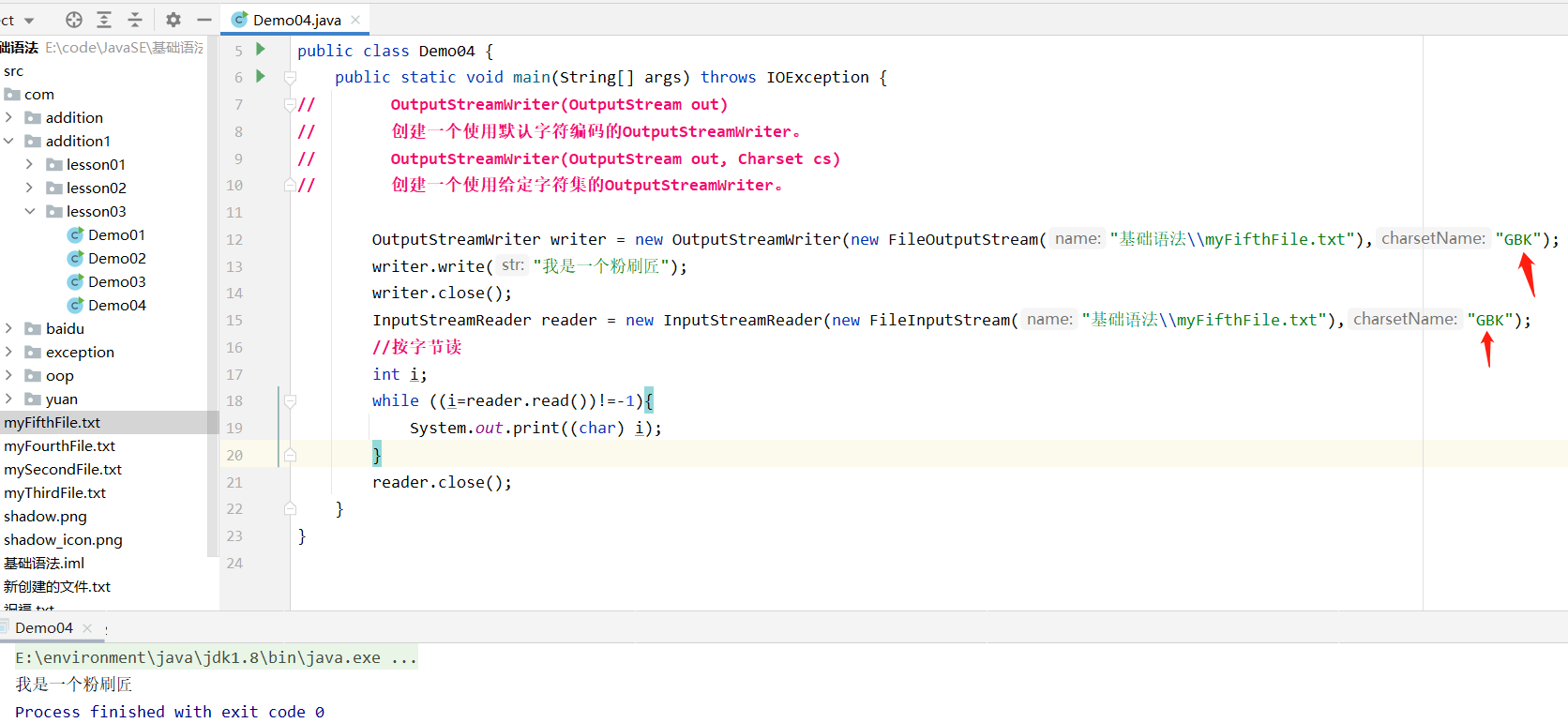
-
把用GBK编码的文件按GBK解码
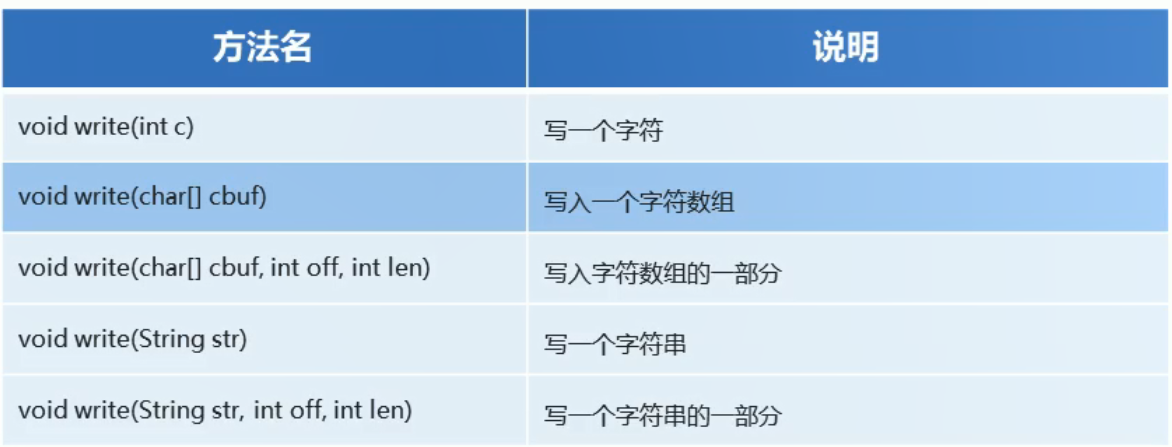
字符流写数据

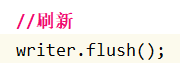
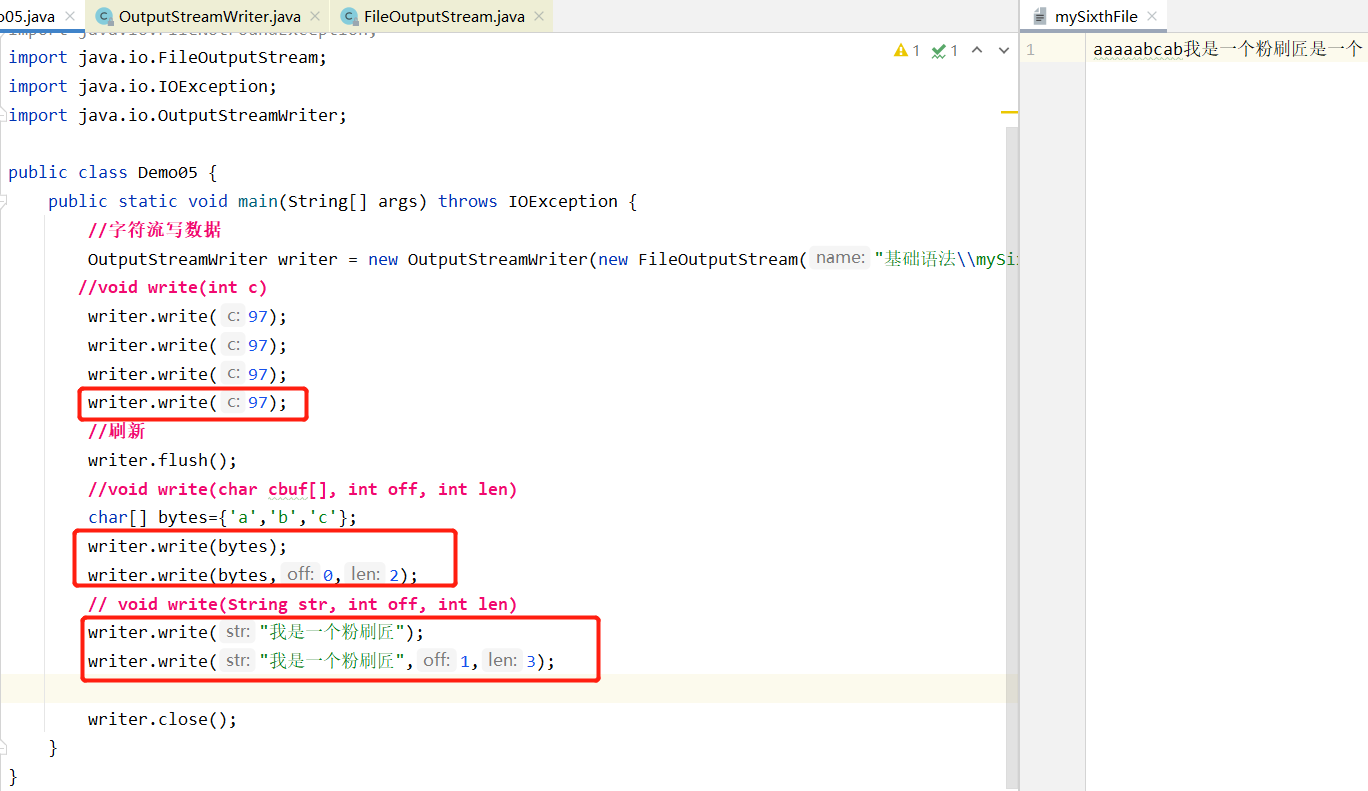
直接这么写写不进去文件,因为字符流通过字节流去写,数据现在存在缓冲区里,需要刷新缓冲,用flush()方法
但如果不写刷新在后面写关闭也行,因为close方法是先刷新缓冲再释放资源,但close方法后面不能继续写数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号