【硬盘数据恢复】使用 dd ddrescue ntfs-3g ddrutility 各种工具来恢复【包含坏道的】移动硬盘【NTFS分区】上的数据
- #前提
朋友的移动硬盘,插入电脑识别很慢很慢,求救与我,让我帮忙恢复其中的照片。
硬盘信息为:
# sudo fdisk -l /dev/sdb Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: dos Disk identifier: 0x24711ea6 Device Boot Start End Sectors Size Id Type /dev/sdb1 63 1953520064 1953520002 931.5G 7 HPFS/NTFS/exFAT
硬盘为1TiB的机械硬盘,西部数据,2013年购买的,使用很多年了。
- #首次尝试
windows下检测与恢复坏道,使用工具:Diskgenius ,winhex ,hddtune pro ,以及winPE 工具箱(大白菜,老毛桃,微PE,PE工具箱) ,还有一个修复坏道的古老神器 硬盘再生器 hdd regeneration 。
发现windows反应很慢,说明windows在加载硬盘信息,但是读取很慢,还把windows给卡住了(说明,某些IO操作没有进行异步处理,导致UI界面假死)。
检测很慢,进度未知,软件卡死,于是不操作,等待UI 界面恢复。检测坏道不是很多,就是读取很慢。
有时候 使用windows自带的 chkdsk 很管用,所以 使用 chkdsk /f /x /r I: 来修复,大约等待2-4个小时候(电脑重启,在开机界面进行移动硬盘分区的错误检查 chkdsk),chkdsk程序异常终止退出,无法完全修复,但是也修复了一部分。
进入到windows以后,等待一段时间(大概十几分钟),盘符显示容量了,文件列表也可以查看了,直接开始复制数据。
大约有 600GB数据 / 931GB总数据 ,根目录就三个目录,于是进入三级目录,开始复制到本地硬盘,尝试用了fastcopy,但是硬盘会断线重连,就是与电脑断开连接,等过段时间又恢复连接,结果这种 设备IO错误,导致这些软件大量报错,无法恢复进度。
于是,我干脆使用windows explorer 自带的复制功能,当出现错误,会弹出报错,等待一段时间后,点击重试,可以继续复制。
但是文件数量很多,发生这种设备断线重连的情况也比较多,我必须一直在电脑面前看着,不能够自动化,但就这样,恢复了几天,大概恢复了接近100GB 的数据,然后就恢复不动了,错误更频繁,没办法自动化。
- #尝试使用linux下的工具,dd 命令进行恢复
安装了一个ubuntu,开始尝试dd命令
发现 linux 真是好,设备IO是异步,你不会感觉很卡。
首先用dd命令来复制到文件中,命令大致为:
sudo dd if=/dev/sdb1 of=seagate_disk2.img iflag=skip_bytes oflag=seek_bytes skip=187097939968 seek=187097939968
其中skip和seek 为失败或取消后,要继续恢复的进度,这里是连续恢复的,不能断。大小根据 ls *.img文件来获取的。
linux也有设备断线重连的情况,并且有时候 设备名称还发生了变化,变成 /dev/sdd1 sde1,所以写脚本,优化输入设备为:
devAbs=/dev/disk/by-uuid/4458199458198638 devAbs=/dev/disk/by-path/pci-0000:00:1d.0-usb-0:1.1:1.0-scsi-0:0:0:0-part1 devAbs=/dev/disk/by-id/usb-ATA_WDC_WD10JPVT-00A_0123456789AE036-0:0-part1
发现,还是 by-id 好,设备连接和设备基础信息不会变,由于要自己控制 skip 和seek 也就是进度情况,恢复了几天,脚本不断优化,恢复了200多GB的数据了。
后来突然发现脚本有bug,断线后判断文件大小错了,进度中有空白了,哎,麻烦,准备换工具。
花了几天,已经恢复的200多GB的文件,使用 dd 来写入到准备好的 2TiB移动硬盘的第四个分区 ,专门准备了硬盘,腾出1TiB空间,来写入
dd if=/dev/disk/by-id/usb-ATA_WDC_WD10JPVT-00A_0123456789AE036-0:0-part1 of=/dev/sdc4 status=progress
开始使用其他方法,来简化,来提高可靠性和效率。
- #尝试不用dd,使用 ddrescue
看到网上说linux 硬盘恢复工具,有个ddrescue 可以有很好的进度控制,与我的想法不谋而合,于是切换到 ddrescue。
大致命令是:
dev="/dev/disk/by-id/usb-ATA_WDC_WD10JPVT-00A_0123456789AE036-0:0-part1" dev="/dev/disk/by-id/ata-WDC_WD10JPVT-00A1YT0_WD-WX51AA2L2462-part1" backupdev="/dev/disk/by-id/usb-WD_Elements_1048_575831314532334459363036-0:0-part4" mapFile=test.map while true;do echo "-----------start--------" # maxsize --size=1000204886016 # -R 反序,从后向前 # -P3 预览16*3字节数据,1-32 范围限制; -P domainFile 是对比的意思 # -d 直接io -D equal output-direct-io sudo ddrescue --cpass=1,5 -v -v -P4 -v -i 200GiB --size 931GiB --log-events=test.event.log --log-rates=test.rate.log --log-reads=test.read.log --force $dev $backupdev $mapFile ret=$?;echo result=$ret; if test $ret -eq 0;then exit 0;fi; sleep 6; done
加三个-v可以查看更详细的显示信息,-P4可以预览数据,太棒了。
ddrescue的一个最大的好处是 mapFile 他可以记录进度,即使中断,下次在执行这个命令,他会检测已恢复的进度,并继续恢复。
但是这个硬盘是在是太慢了,ddrescue 显示的进度如下(这个仅供参考):
GNU ddrescue 1.25 About to copy 1991 MBytes from '/dev/sdb1' [UNKNOWN] (1_000_202_241_024) to 'mft.img' (501_887_852_544) Starting positions: infile = 0 B, outfile = 0 B Copy block size: 128 sectors Initial skip size: 19584 sectors Sector size: 512 Bytes Direct in: no Direct out: no Sparse: no Truncate: no Trim: no Scrape: no Max retry passes: 0 Reverse mode Press Ctrl-C to interrupt Initial status (read from mapfile) current position: 500183 MB, current sector: 976920960 last block size: 498314 MB (sizes limited to domain from 0 B to 501_887_852_544 B of 1_000_202_241_024 B) rescued: 336711 kB, tried: 655360 B, bad-sector: 0 B, bad areas: 0 Current status Data preview: 74A8580000 46 49 4C 45 2A 00 03 00 00 00 00 00 00 00 00 00 FILE*........... 74A8580010 01 00 00 00 30 00 00 00 28 01 00 00 00 04 00 00 ....0...(....... 74A8580020 00 00 00 00 00 00 00 00 06 00 04 00 00 00 00 00 ................ 74A8580030 10 00 00 00 60 00 00 00 00 00 00 00 00 00 00 00 ....`........... ipos: 501040 MB, non-trimmed: 1015 kB, current rate: 16384 B/s opos: 501040 MB, non-scraped: 0 B, average rate: 41707 B/s non-tried: 995950 kB, bad-sector: 0 B, error rate: 0 B/s rescued: 994070 kB, bad areas: 0, run time: 4h 22m 41s pct rescued: 49.92%, read errors: 6, remaining time: 9h 56m time since last successful read: 0s Copying non-tried blocks... Pass 1 (backwards)
速度到了一百多Kb甚至更低,有时候快,有时候慢,感觉要恢复2年的时间。
由于这个ddrescue是全盘克隆,一些不是用的空间也会克隆,极大的浪费了时间。
分区克隆,全盘克隆也有一些其他的软件,比如ghost,diskgenius等,但是他们光是打开就卡住了,不像linux的ddrescue等软件,完全不卡,所以没办法用ghost等工具。
- #新想法,这个是NTFS分区,我想按照文件来恢复,而不是全盘恢复。
之前通过apt安装了 ntfs相关的软件,以及文件恢复相关的软件,有下面的这些命令
anmingwei@ubuntu-wubi1:~$ ntfs ntfs-3g ntfscmp ntfsinfo ntfsresize ntfswipe ntfs-3g.probe ntfscp ntfslabel ntfssecaudit ntfscat ntfsdecrypt ntfsls ntfstruncate ntfsclone ntfsfallocate ntfsmove ntfsundelete ntfscluster ntfsfix ntfsrecover ntfsusermap anmingwei@ubuntu-wubi1:~$ ddr ddrescue ddrescueview ddru_findbad ddru_ntfsfindbad ddrescuelog ddru_diskutility ddru_ntfsbitmap ddrutility
我想研究下NTFS结构,把$MFT里面记录的文件所占用的磁盘扇区给打印出来,然后按照扇区恢复文件,这样岂不是很好。
通过 ntfsls ntfscat ntfsclone 命令,我发现可以,只是ntfs-3g 无法保存进度,一旦设备断线重连,一切就白费了。我想是不是可以研究下源码,改造下。
于是下载了ntfs-3g的源码,编译很简单,标准的linux configure makefile 方式。
开始分析源码,从ntfsclone ntfscat 开始分析,发现有点困难,源码缺少注释,我缺少ntfs专业知识,只知道大概,改了一下,但是设备断线重连依旧继续报错,无法继续导出数据。
想要导出$MFT 但是一定会遇到设备自动断线重连,windows NTFS分区加载慢就是因为这些重要文件有坏道,我现在的目标就是$MFT。
之前恢复的200+数据,在windows用winhex查看,发现不完整,说明MFT所在扇区并没有克隆出来。
今天突然发现 ddru_ntfsbitmap 这个命令,查看了 sf.net 上 ddrutility的文档,发现这个工具就是我想要的。
通过ddru_ntfsbitmap 可以获取 ddrescue的 domain mapfile ,我一直琢磨这个 domain mapfile 根mapfile的区别呢?
这才发现: domain mapfile 中的rescue的数据,可以作为列表来让ddrescue使用,ddrescue只恢复列表指定的数据
比如:生成sdb1 NTFS分区的 $MFT 和 $bitmap 的 domain mapfile 就是下面的命令了
sudo ddru_ntfsbitmap -D -V -m ___mft.log /dev/sdb1 ddru_ntfsbitmap.log


ddru_ntfsbitmap 1.5 20150111 Reading boot sector... command = ddrescue -i0 -o0 -s512 /dev/sdb1 '__bootsec' '__bootsec.log' GNU ddrescue 1.25 Press Ctrl-C to interrupt Initial status (read from mapfile) (sizes limited to domain from 0 B to 512 B of 1_000_202_241_024 B) rescued: 512 B, tried: 0 B, bad-sector: 0 B, bad areas: 0 Current status ipos: 0 B, non-trimmed: 0 B, current rate: 0 B/s opos: 0 B, non-scraped: 0 B, average rate: 0 B/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 512 B, bad areas: 0, run time: 0s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished Reading bitmap inode from mft... command = ddrescue -i3221225472 -o0 -s16384 /dev/sdb1 '__mftshort' '__mftshort.log' GNU ddrescue 1.25 Press Ctrl-C to interrupt Initial status (read from mapfile) (sizes limited to domain from 3_221_225_472 B to 3_221_241_856 B of 1_000_202_241_024 B) rescued: 16384 B, tried: 0 B, bad-sector: 0 B, bad areas: 0 Current status ipos: 0 B, non-trimmed: 0 B, current rate: 0 B/s opos: -3221 MB, non-scraped: 0 B, average rate: 0 B/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 16384 B, bad areas: 0, run time: 0s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished Creating MFT domain logfile... total mft fragments = 2 mft part 0 offset=0xC0000000 size=0xE000000 mft part 1 offset=0x74722C2000 size=0x68ACC000 ............Reading part 0 of $Bitmap........... command = ddrescue -i500101173248 -o0 -s30527488 /dev/sdb1 '__bitmapfile' '_part0__bitmapfile.log' GNU ddrescue 1.25 Press Ctrl-C to interrupt Initial status (read from mapfile) (sizes limited to domain from 500_101_173_248 B to 500_131_700_736 B of 1_000_202_241_024 B) rescued: 30527 kB, tried: 0 B, bad-sector: 0 B, bad areas: 0 Current status ipos: 0 B, non-trimmed: 0 B, current rate: 0 B/s opos: -500101 MB, non-scraped: 0 B, average rate: 0 B/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 30527 kB, bad areas: 0, run time: 0s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished ............ Done reading part 0 of $Bitmap........... Creating ddrescue domain logfile... end = 1000202305536 total_size = 1000202241024 Finished creating logfile total= 1000202305536 bytes used= 687635582976 (68.75%) free= 312566722560 (31.25%) ddru_ntfsbitmap took 3.713145 seconds to complete
ddru_ntfsbitmap 这个程序好,调用了 ddrescue 以及 ntfs-3g 来分析ntfs信息,并保存了 domain mapfile,那么接下来就可以用 domain mapfile来恢复NTFS最重要的数据了
我先用我的 2TiB移动硬盘的第四个分区 (也就是作之前镜像的载体,目前还不完整)作实验
sudo ddrescue -m ___mft.log /dev/sdc4 mft_2.img mft_2.map.log -v -v -v -P4 GNU ddrescue 1.25 About to copy 1991 MBytes from '/dev/sdc4' [UNKNOWN] (1_036_170_297_344) to 'mft_2.img' (0) Starting positions: infile = 0 B, outfile = 0 B Copy block size: 128 sectors Initial skip size: 20352 sectors Sector size: 512 Bytes Direct in: no Direct out: no Sparse: no Truncate: no Trim: yes Scrape: yes Max retry passes: 0 Press Ctrl-C to interrupt Data preview: 74DAD80000 42 61 64 53 65 63 74 6F 52 00 3F 3F 3F 3F 3F 3F BadSectoR.?????? 74DAD80010 3F 3F 3F 3F 3F 3F 3E 3F 3F 3F 3F 3F 3F 3F 3F 3F ??????>????????? 74DAD80020 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F ???????????????? 74DAD80030 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F ???????????????? ipos: 501887 MB, non-trimmed: 0 B, current rate: 29548 kB/s opos: 501887 MB, non-scraped: 0 B, average rate: 26905 kB/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 1991 MB, bad areas: 0, run time: 1m 13s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished
可以看到 1991MB 就是$MFT 的大小,花了1分钟13妙。由于这个分区MFT是不完整的,所以只是测试而以。可以看到数据预览有点 BadSectoR 字样(但并不是坏道,不知道是什么时候克隆MFT失败,被克隆程序写入的信息吧)
按照这个套路,我就把坏道硬盘的NTFS分区的MFT先恢复处理,处理以下,只保留想要的文件,然后再导出 ntfsbitmap domain mapfile ,只恢复bitmap 使用到的数据。
但是现在这个坏道硬盘用ddrescue导出这个1991MB的时间就要十几个小时:
$ sudo ddrescue -P4 -v -v -v -d -r2 -m ___mft.log /dev/sdb1 mft.img mft.map.log
GNU ddrescue 1.25 About to copy 1991 MBytes from '/dev/sdb1' [UNKNOWN] (1_000_202_241_024) to 'mft.img' (501_887_852_544) Starting positions: infile = 0 B, outfile = 0 B Copy block size: 128 sectors Initial skip size: 19584 sectors Sector size: 512 Bytes Direct in: no Direct out: no Sparse: no Truncate: no Trim: no Scrape: no Max retry passes: 0 Reverse mode Press Ctrl-C to interrupt Initial status (read from mapfile) current position: 500183 MB, current sector: 976920960 last block size: 498314 MB (sizes limited to domain from 0 B to 501_887_852_544 B of 1_000_202_241_024 B) rescued: 336711 kB, tried: 655360 B, bad-sector: 0 B, bad areas: 0 Current status Data preview: 74A48F0000 46 49 4C 45 2A 00 03 00 00 00 00 00 00 00 00 00 FILE*........... 74A48F0010 01 00 00 00 30 00 00 00 28 01 00 00 00 04 00 00 ....0...(....... 74A48F0020 00 00 00 00 00 00 00 00 06 00 04 00 00 00 00 00 ................ 74A48F0030 10 00 00 00 60 00 00 00 00 00 00 00 00 00 00 00 ....`........... ipos: 500976 MB, non-trimmed: 1015 kB, current rate: 32768 B/s opos: 500976 MB, non-scraped: 0 B, average rate: 40664 B/s non-tried: 932446 kB, bad-sector: 0 B, error rate: 0 B/s rescued: 1057 MB, bad areas: 0, run time: 4h 55m 27s pct rescued: 53.11%, read errors: 6, remaining time: 11h 23m time since last successful read: 0s Copying non-tried blocks... Pass 1 (backwards)
还有1015MB 的数据没有尝试恢复,等在过一天,恢复了大部分,我再尝试恢复这小部分数据。
----append
经过一夜和一上午的恢复,已经恢复了99.99% 的MFT数据了,剩下4KB无论如何也恢复不了了 (期间要用 while true; do $CMD; done 的方式重复运行这个命令)。
$ sudo ddrescue -P4 -v -v -v -d -r2 -m ___mft.log /dev/sdb1 mft.img mft.map.log; GNU ddrescue 1.25 About to copy 1991 MBytes from '/dev/sdb1' [UNKNOWN] (1_000_202_241_024) to 'mft.img' (501_887_852_544) Starting positions: infile = 0 B, outfile = 0 B Copy block size: 128 sectors Initial skip size: 19584 sectors Sector size: 512 Bytes Direct in: yes Direct out: no Sparse: no Truncate: no Trim: yes Scrape: yes Max retry passes: 2 Press Ctrl-C to interrupt Initial status (read from mapfile) current position: 500213 MB, current sector: 976978626 last block size: 498314 MB (sizes limited to domain from 0 B to 501_887_852_544 B of 1_000_202_241_024 B) rescued: 1991 MB, tried: 4096 B, bad-sector: 4096 B, bad areas: 4 Current status Data preview: No data available ipos: 500213 MB, non-trimmed: 0 B, current rate: 0 B/s opos: 500213 MB, non-scraped: 0 B, average rate: 0 B/s non-tried: 0 B, bad-sector: 4096 B, error rate: 128 B/s rescued: 1991 MB, bad areas: 4, run time: 1m 7s pct rescued: 99.99%, read errors: 16, remaining time: n/a time since last successful read: n/a
Retrying bad sectors... Retry 1 (forwards) Retrying bad sectors... Retry 2 (backwards) Finished
###恢复到 我的2TiB硬盘的第四个分区
$ sudo ddrescue -m ___mft.log -v -v -v -P4 --force mft.img /dev/sdc4 GNU ddrescue 1.25 About to copy 1991 MBytes from 'mft.img' (501_887_852_544) to '/dev/sdc4' [UNKNOWN] (1_036_170_297_344) Starting positions: infile = 0 B, outfile = 0 B Copy block size: 128 sectors Initial skip size: 9856 sectors Sector size: 512 Bytes Direct in: no Direct out: no Sparse: no Truncate: no Trim: yes Scrape: yes Max retry passes: 0 Press Ctrl-C to interrupt Data preview: 74DAD80000 46 49 4C 45 30 00 03 00 87 60 3A 36 00 00 00 00 FILE0....`:6.... 74DAD80010 01 00 02 00 38 00 01 00 00 02 00 00 00 04 00 00 ....8........... 74DAD80020 00 00 00 00 00 00 00 00 09 00 00 00 F8 AA 1D 00 ................ 74DAD80030 56 01 47 11 00 00 00 00 10 00 00 00 60 00 00 00 V.G.........`... ipos: 501887 MB, non-trimmed: 0 B, current rate: 19849 kB/s opos: 501887 MB, non-scraped: 0 B, average rate: 37566 kB/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 1991 MB, bad areas: 0, run time: 52s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished
这个就快了,后续修改了硬盘的MFT 后不满意,还可以恢复,这个 mft.img 镜像文件一定要保留着。
- #补充 和 mapfile 相关的命令
可以通过这个命令来查看 mapfile 的概况 (命令行)
$ ddrescuelog -t ddru_ntfsbitmap.log current pos: 0 B, current status: finished mapfile extent: 1000 GB, in 39077 area(s) non-tried: 312566 MB, in 19538 area(s) ( 31.25%) rescued: 687635 MB, in 19539 area(s) ( 68.74%) non-trimmed: 0 B, in 0 area(s) ( 0%) non-scraped: 0 B, in 0 area(s) ( 0%) bad-sector: 0 B, in 0 area(s) ( 0%)
上面作为domain mapfile 的话,只会恢复 rescued: 687635 MB 这么多的数据。但还是太多,所以我要先恢复MFT 想办法删除一些文件,再生成新的ntfsbitmap 的mapfile。
也可以通过 ddrescueview 来通过GUI 的方式来查看 mapfile (内心泪流满面)
下面 就是我恢复了这么久的map图(我嫌顺序恢复慢,尝试跳着恢复的,还是慢,今天合并了mapfile,就是下图的进度了)
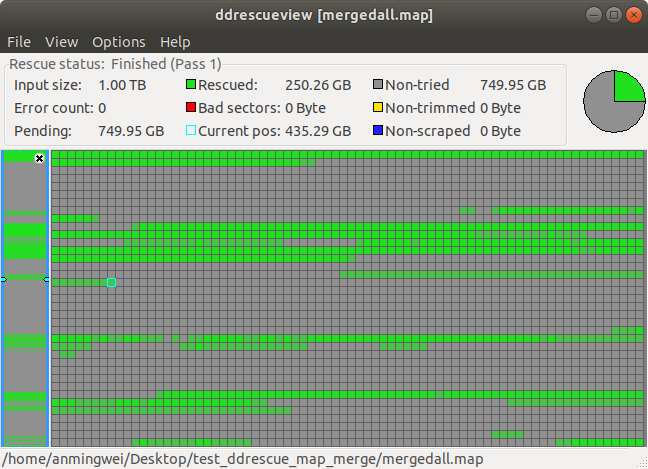
合并多个mapfile的方式为:
for d in `find . -maxdepth 1 -type d `;do ddrescue -v -v -v --force --same-file -s 1TiB -m $d/test.map /dev/zero /dev/zero mergedall.map ;done
通过 dev/zero 假设性的恢复别的mapfile(当作 domain mapfile) 指定恢复到一个 mergeall.map 中,就可以实现 合并mapfile 了。之前还想写个程序呢,这样就不用了,一行命令搞定。
----append
发现 ddrescuelog 程序也可以作这个事情:
$ ddrescuelog -h ... Usage: ddrescuelog [options] mapfile Options: ... -A, --annotate-mapfile add comments with human-readable pos/sizes -x, --xor-mapfile=<file> XOR the finished blocks in file with mapfile -y, --and-mapfile=<file> AND the finished blocks in file with mapfile -z, --or-mapfile=<file> OR the finished blocks in file with mapfile
其中 -A 选项可以对mapfile 增加注释,关于起始位置可读性的,比如
$ ddrescuelog -v -v -v -A ddru_ntfsbitmap.log ... 0xE86429C000 0x000CA000 + # 998112 MB 827392 0xE864366000 0x0002E000 ? # 998113 MB 188416 0xE864394000 0x7C79A000 + # 998113 MB 2088 MB 0xE8E0B2E000 0x00002000 ? # 1000 GB 8192 0xE8E0B30000 0x00010000 + # 1000 GB 65536
------------------------------------------------------------------------------------------------
一定要专业!本博客定位于 ,C语言,C++语言,Java语言,Android开发和少量的Web开发,之前是做Web开发的,其实就是ASP维护,发现EasyASP这个好框架,对前端后端数据库 都很感觉亲切啊。. linux,总之后台开发多一点。以后也愿意学习 cocos2d-x 游戏客户端的开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号