

Python爬取唐人街探案3豆瓣短评并生成词云






爬取唐人街探案3短评过程
要爬取的URL:
https://movie.douban.com/subject/27619748/comments?start=20&limit=20&status=P&sort=new_score

url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P % (movie_id, (i - 1) * 20)
其中i代表当前页码,从0开始。
在谷歌浏览器中按F12进入开发者调试模式,查看源代码,找到短评的代码位置,查看位于哪个div,哪个标签下
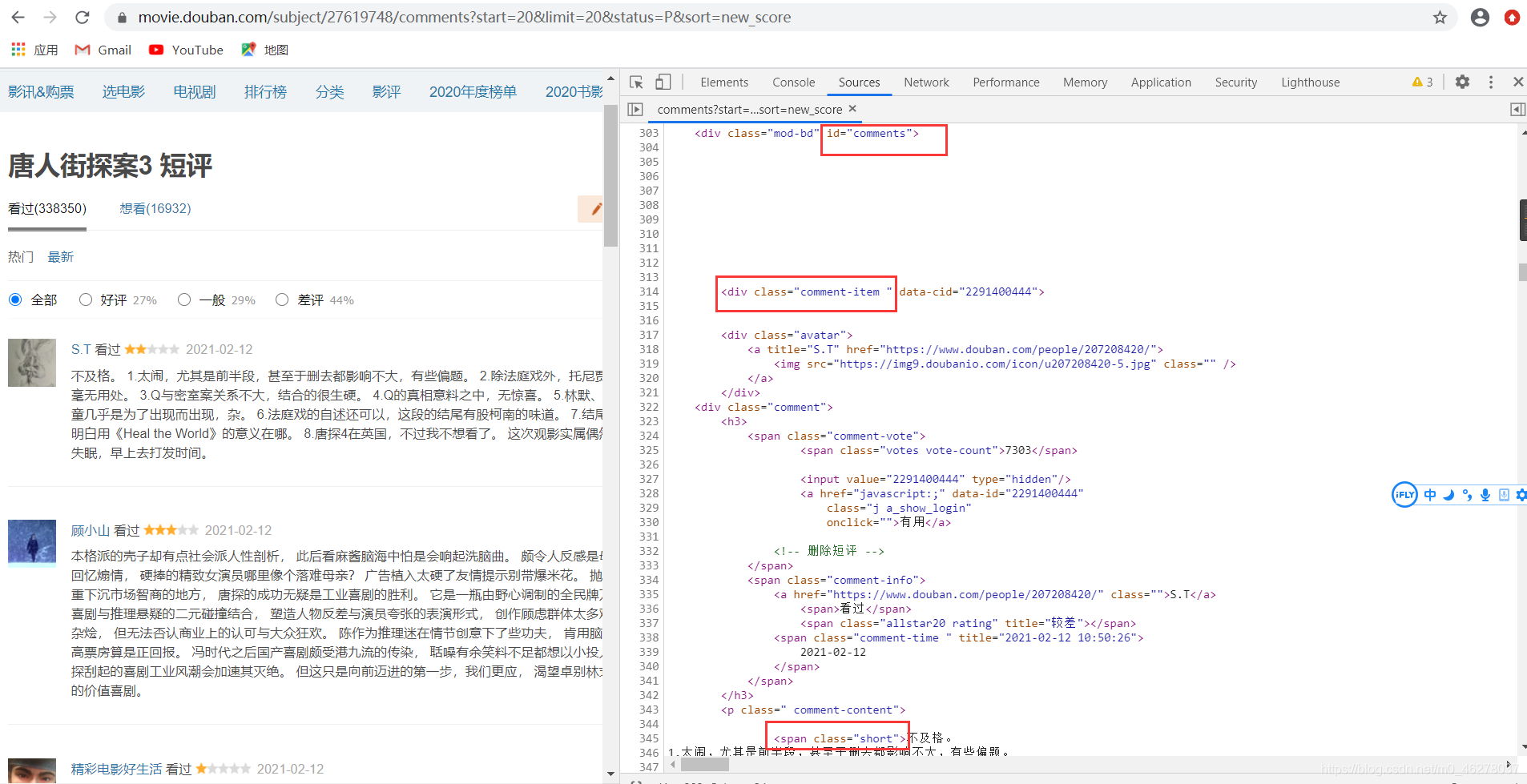
分析源码
可以看到评论在div[id=‘comments’]下的div[class=‘comment-item’]中的第一个span[class=‘short’]中,使用正则表达式提取短评内容,即代码为:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \ % (movie_id, (i - 1) * 20) req = requests.get(url, headers=headers) req.encoding = 'utf-8' comments = re.findall('<span class="short">(.*)</span>', req.text)
使用jieba分词,jieba按照中文习惯把很多文字进行分词
with open(file_name, 'r', encoding='utf8') as f: word_list = jieba.cut(f.read()) result = " ".join(word_list) # 分词用 隔开
生成wordcloud词云:
if icon_name is not None and len(icon_name) > 0: gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic) else: gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
完整代码:
1 # 分析豆瓣唐探3的影评,生成词云 2 3 # https://movie.douban.com/subject/27619748/comments?start=20&limit=20&status=P&sort=new_score 4 5 # url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P '\ 6 7 # % (movie_id, (i - 1) * 20) 8 9 import requests 10 from stylecloud import gen_stylecloud 11 import jieba 12 import re 13 14 from bs4 import BeautifulSoup 15 16 17 headers = { 18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0' 19 } 20 21 22 23 def jieba_cloud(file_name, icon): 24 with open(file_name, 'r', encoding='utf8') as f: 25 word_list = jieba.cut(f.read()) 26 27 result = " ".join(word_list) # 分词用 隔开 28 # 制作中文词云 29 icon_name = " " 30 if icon == "1": 31 icon_name = '' 32 elif icon == "2": 33 icon_name = "fas fa-dragon" 34 elif icon == "3": 35 icon_name = "fas fa-dog" 36 elif icon == "4": 37 icon_name = "fas fa-cat" 38 elif icon == "5": 39 icon_name = "fas fa-dove" 40 elif icon == "6": 41 icon_name = "fab fa-qq" 42 pic = str(icon) + '.png' 43 if icon_name is not None and len(icon_name) > 0: 44 gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic) 45 else: 46 gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic) 47 return pic 48 49 50 # 爬取短评 51 def spider_comment(movie_id, page): 52 comment_list = [] 53 with open("douban.txt", "a+", encoding='utf-8') as f: 54 for i in range(1,page+1): 55 56 url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \ 57 % (movie_id, (i - 1) * 20) 58 59 req = requests.get(url, headers=headers) 60 req.encoding = 'utf-8' 61 comments = re.findall('<span class="short">(.*)</span>', req.text) 62 63 64 f.writelines('\n'.join(comments)) 65 print(comments) 66 67 68 # 主函数 69 if __name__ == '__main__': 70 movie_id = '27619748' 71 page = 10 72 spider_comment(movie_id, page) 73 jieba_cloud("douban.txt", "1") 74 jieba_cloud("douban.txt", "2") 75 jieba_cloud("douban.txt", "3") 76 jieba_cloud("douban.txt", "4") 77 jieba_cloud("douban.txt", "5") 78 79 jieba_cloud("douban.txt", "6")
生成的 douban.txt (部分):
生成的词云:






虽然看似有点炫,然而无用词太多,需要经过词云清洗才能得到有用的信息,开篇是经过清洗和定制后的效果图,具体方法参见:
Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号