
Python爬虫之小米应用商店
小米应用商店的爬虫,提取各个App的下载链接。
源码:
1 # -*- coding: UTF-8 -*- 2 import requests 3 import csv 4 import queue 5 6 7 class XiaoMiShop(): 8 9 def __init__(self, category): 10 self.base_url = 'http://app.mi.com/categotyAllListApi' 11 self.base_download = 'http://app.mi.com/download/' 12 self.header = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' 13 self.csv_header = ['ID', '应用名称', '下载链接'] 14 self.max_page = 70 15 self.category = category 16 self.queue = queue.Queue() 17 18 def clean_data(self, data): 19 ''' 20 提取数据,放入队列中 21 :param data: 22 :return: 23 ''' 24 for i in data: 25 app = {} 26 app['ID'] = i.get('appId') 27 app['应用名称'] = i.get('displayName') 28 app['下载链接'] = self.base_download + str(i.get('appId')) 29 self.queue.put(app) 30 31 def request(self, page): 32 parame = { 33 'page': page, 34 'categoryId': int(self.category), 35 'pageSize': 30 36 } 37 req = requests.get(url=self.base_url, params=parame) 38 req.encoding = req.apparent_encoding 39 return req 40 41 def spider_by_page(self, page, retry=3): 42 ''' 43 失败页数重新爬取 44 :param page: 失败页数 45 :param retry: 重试次数 46 :return: 47 ''' 48 if retry > 0: 49 print('重试第{}页'.format(page)) 50 req = self.request(page=page) 51 try: 52 data = req.json()['data'] 53 if data: 54 self.clean_data(data) 55 print('第{}页重试成功'.format(page)) 56 except: 57 self.spider_by_page(page=page, retry=retry - 1) 58 59 def spider(self): 60 ''' 61 :param category: 模块id,如游戏:15 62 :return: 63 ''' 64 fail_page = [] 65 for _ in range(self.max_page): 66 print('正在爬取第{}页'.format(_)) 67 req = self.request(_) 68 try: 69 data = req.json()['data'] 70 except: 71 data = [] 72 fail_page.append(_) 73 if data: 74 self.clean_data(data) 75 else: 76 continue 77 if fail_page: 78 print('出错的页数:', fail_page) 79 for _ in fail_page: 80 self.spider_by_page(page=_) 81 else: 82 print('没有出错') 83 84 def run(self): 85 self.spider() 86 data_list = [] 87 while not self.queue.empty(): 88 data_list.append(self.queue.get()) 89 with open('{}.csv'.format(self.category), 'w', newline='', encoding='utf-8-sig') as f: 90 f_csv = csv.DictWriter(f, self.csv_header) 91 f_csv.writeheader() 92 f_csv.writerows(data_list) 93 print('文件保存成功,打开{}.csv查看'.format(self.category)) 94 95 96 if __name__ == '__main__': 97 a = XiaoMiShop(15).run()
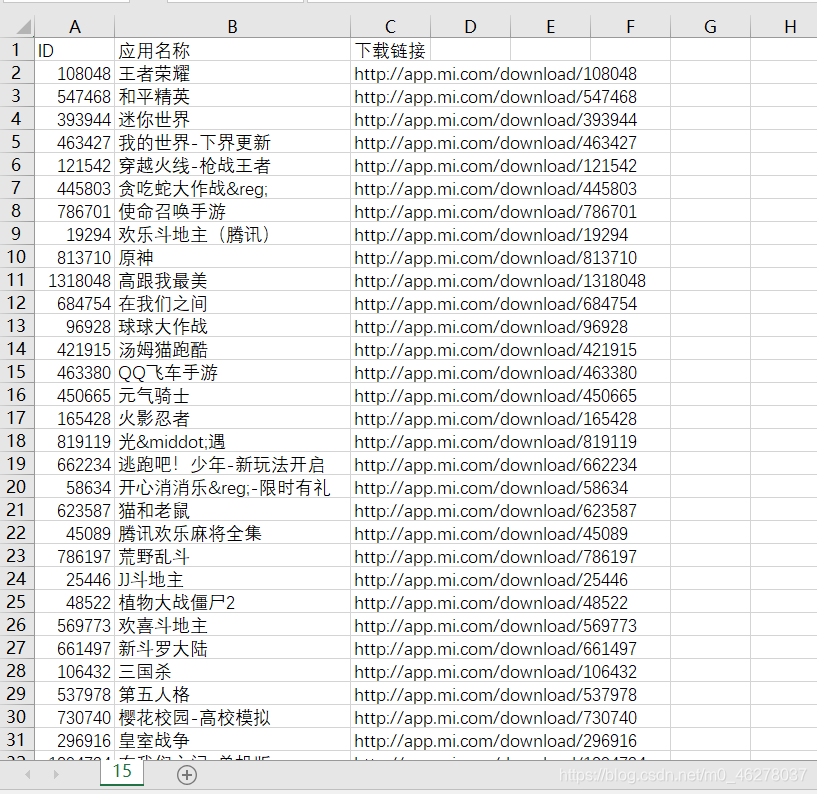
爬取结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号