RNN & LSTM 循环神经网络简述
由于笔者水平有限,如有错,欢迎指正。
CNN和RNN几乎占据着深度学习的半壁江山,CNN在CV领域更加出彩,而RNN在NLP的很多任务中都展示出了很好的效果。
如机器翻译、语音识别、视频标记、图片问答等场景,RNN都能起到很好的效果。
为什么是RNN?
密集连接网络和卷积神经网络都有一个主要特点,那 就是它们都没有记忆。但当我们需要处理序列数据时,这样的结构只能孤立的理解每个词或是每一帧。
而循环神经网络(RNN,recurrent neural network)处理序列的方式是:遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息。总之,RNN 是一个 for 循环,它重复使用循环前一次迭代的计算结果。
这样的结构使得我们可以有效的处理序列数据。
RNN是什么?
基础的RNN结构:
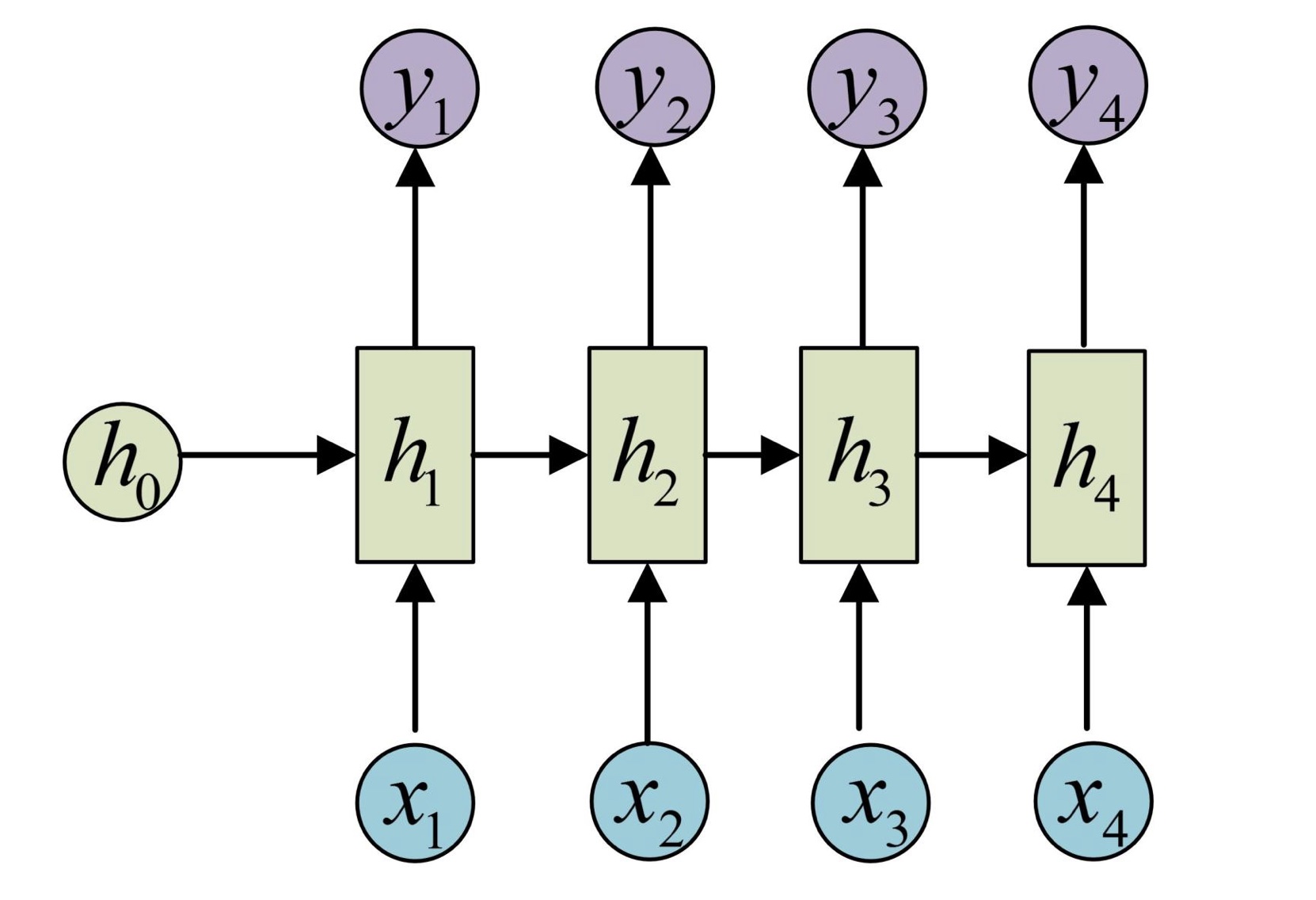
该图中X为数据鹅输入,h(hidden state)用特定的公式来提取特征并输出y,并传递向下一层,使得每个前一层都在后一层有体现。
SimpleRNN in keras:
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
#输入为 (batch_size, timesteps, input_features) / (batch_size, output_ features) 这两种模式由 return_sequences 控制
该结构输入是x1, x2, .....xn,输出为y1, y2, ...yn,输入与输出等长。但是这种限制使得这种结构使用范围很小,故在此基础上衍生了一些改良:
- 输入一个序列,输出一个值

2. 输入一个值,输出一个序列
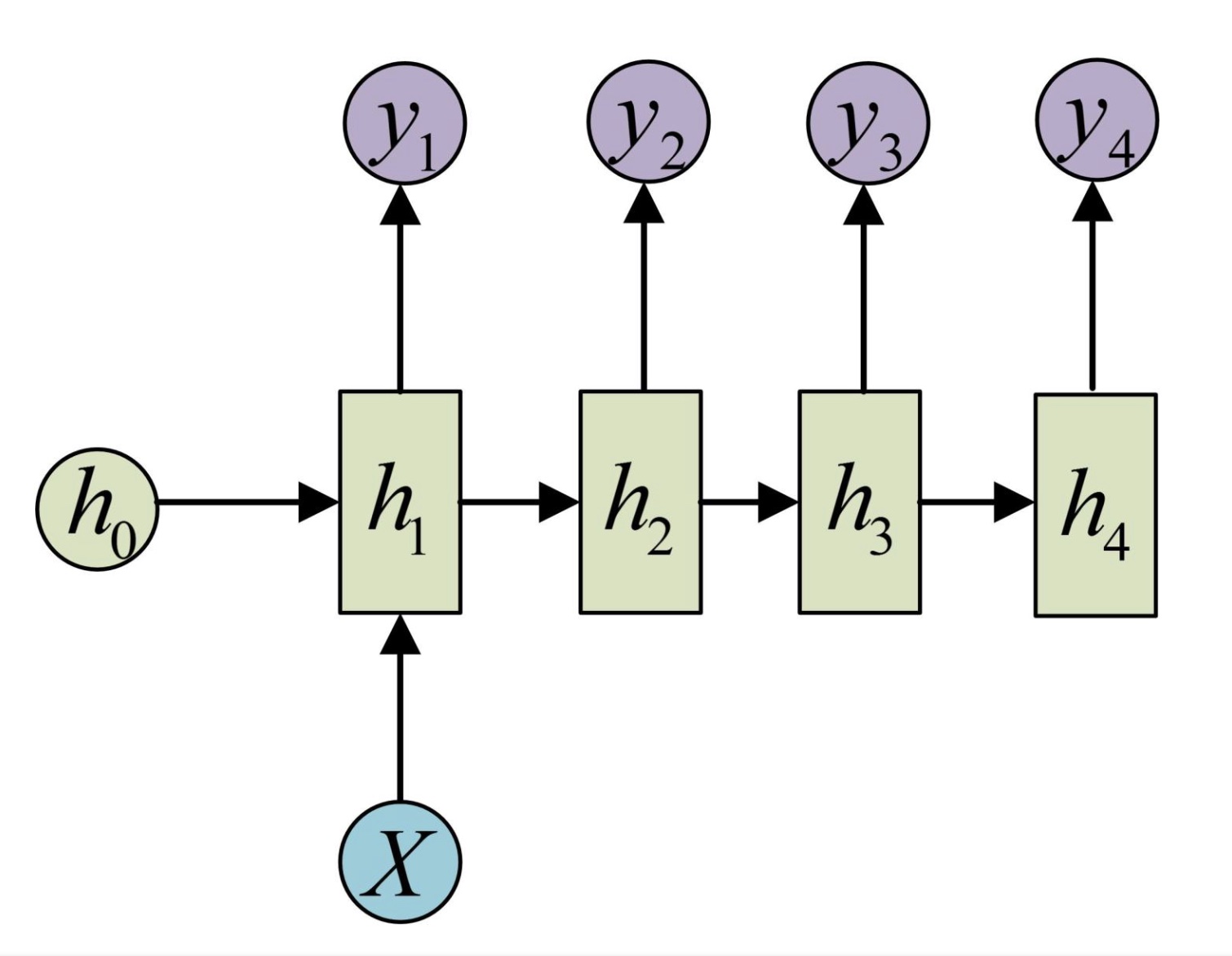
还有一些更复杂衍生结构,例如Encoder-Decoder、Attention机制。
LSTM网络(Long Short Term Memory networks):
基础的RNN结构通常短期的记忆影响较大,但是长期的记忆影响就很小,即后输入的数据产生的影响大,前输入的产生的影响小,继而产生了梯度消失问题:随着层数的增加,网络最终变得无法训练。
为了解决这个问题,诞生了机器学习领域发展出了长短时记忆单元LSTM,简单概括LSTM就是:抓重点。
LSTM可以保留较长序列数据中的「重要信息」,忽略不重要的信息。
LSTM的结构如下:
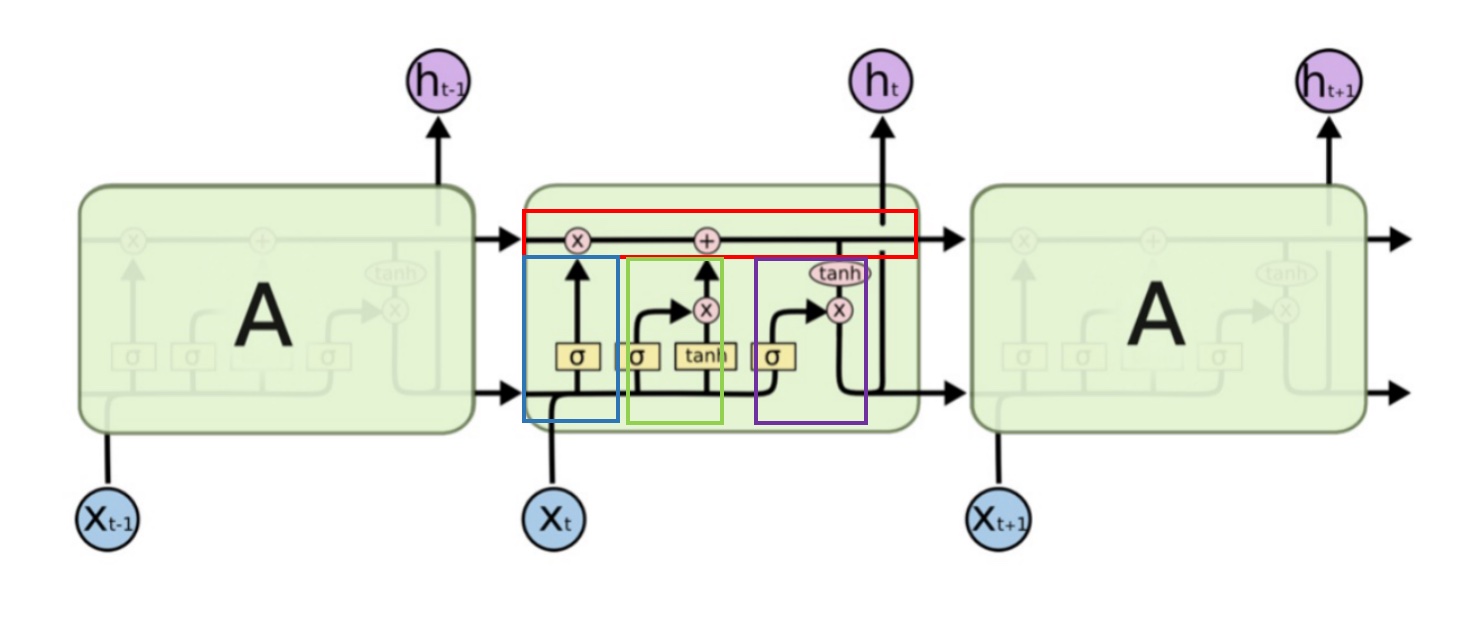
LSTMs的核心是细胞状态,上图中红框表示,用贯穿细胞的水平线表示。
LSTM 可以通过所谓“门”的精细结构向细胞状态添加或移除信息。
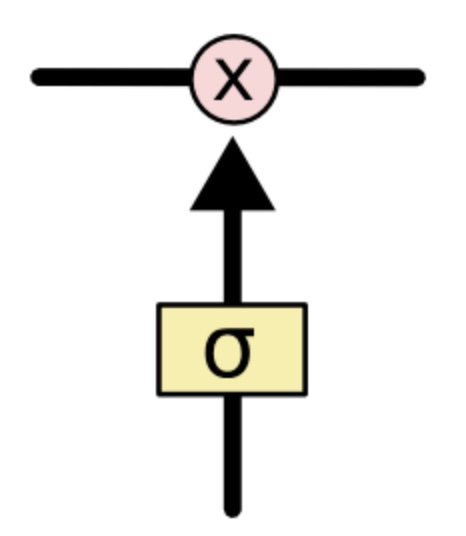
门可以选择性地以让信息通过。它们由 S 形神经网络层和逐点乘法运算组成。
LSTM内部主要有三个阶段:
-
忘记阶段 / 遗忘门(上图中蓝框)
利用上一个节点的输出和输入X的信息,输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态中的哪些信息保留或丢弃多少。
-
选择记忆阶段 / 输入门(上图中绿框)
这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入
进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。
-
输出阶段 / 输出门(上图中紫框)
将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。
当然LSTM也存在许多变种,例如由Gers & Schmidhuber (2000)提出,它在LSTM的结构中加入了“peephole connections.”。
各种变种都对原结构的使用产生了很大的进步,还有很多方面可以深入研究。
LSTM in keras:
model = Sequential() model.add(Embedding(max_features, 32)) model.add(LSTM(32)) #与 SimpleRNN 网络类似,只需指定 LSTM 层的输出维度,很多参数都使用 Keras 默认值。
model.add(Dense(1, activation='sigmoid'))
结语
事实上,不论是那种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别。不难想象随着深度学习热度的延续,更灵活的组合方式、更多的网络结构将被发展出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号