软件工程导论作业 2:python实现论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 通过Python开发个人项目,实现项目单元测试 |
1.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 350 | 400 |
| Analysis | 需求分析 (包括学习新技术) | 80 | 120 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 70 |
| Coding | 具体编码 | 80 | 110 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 60 | 70 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 30 |
| 合计 | 1000 | 1115 |
2.运行环境
IDE:PyCharm Community Edition 2022.2.2
3.接口的设计与实现
一、代码组织
函数的数量及作用:
read_file(file_path):用于读取指定文件路径的文本内容。preprocess_text(text):对输入的文本进行预处理,包括去除特定字符和使用 jieba 库进行分词处理。calculate_similarity(original_text, plagiarized_text):计算两个文本的相似度,通过预处理文本、使用 TfidfVectorizer 进行向量化并计算余弦相似度。main():程序的主入口函数,负责处理命令行参数、读取文件、计算相似度并将结果写入输出文件。
函数之间的关系:
main()函数调用了read_file、preprocess_text和calculate_similarity函数,形成了一个完整的处理流程。首先通过命令行参数获取文件路径,然后分别读取原文和抄袭版论文的文件内容,接着对两个文本进行预处理,最后计算相似度并输出结果。
二、算法关键及独到之处
- 文本预处理:使用正则表达式去除文本中的字母、数字、下划线和空白字符以外的字符,然后利用 jieba 库进行分词,将文本转化为适合后续处理的格式。
- 文本向量化:采用
TfidfVectorizer将预处理后的文本转化为 TF-IDF 向量表示,这种表示方法可以突出文本中的重要词汇,同时考虑词汇在整个文本集合中的重要性。 - 相似度计算:通过计算余弦相似度来衡量两个文本向量之间的相似程度,余弦相似度取值范围在 0 到 1 之间,值越接近 1 表示两个文本越相似。
4.性能改进
使用cproflie进行性能分析,使用snakeviz进行可视化,运行
命令行运行snakeviz.exe -p 8080 .\performance_analysis_result
得出如下图结果。可以得知,使用时间最长的函数为preprocess_text


5.单元测试
单元测试代码存放在test_cases.py
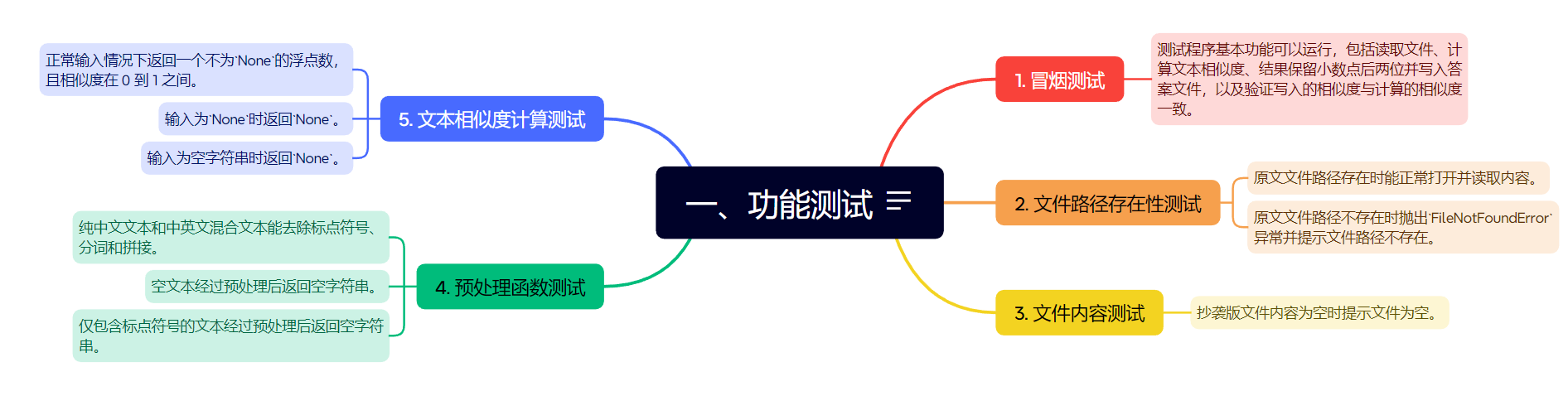
部分测试代码如下:
冒烟测试,设置三个断言
def test_smoke(self):
"""
冒烟测试: 测试程序基本功能可以运行
"""
# 模拟三个命令行参数
original_file_path = r"D:\pythonProject\MyProject1\3122004748\examples\orig.txt"
plagiarized_file_path = r"D:\pythonProject\MyProject1\3122004748\examples\orig_0.8_add.txt"
output_file_path = r"D:\pythonProject\MyProject1\3122004748\answer.txt"
# 读文件
original_text = main.read_file(original_file_path)
plagiarized_text = main.read_file(plagiarized_file_path)
# 计算文本相似度
similarity = main.calculate_similarity(original_text, plagiarized_text)
assert similarity is not None, "计算文本相似度失败"
# 结果保留小数点后两位
rounded_similarity = round(similarity, 2)
assert 0 < rounded_similarity < 1, "相似度不在合理范围内"
# 打开答案文件并写入答案
with open(output_file_path, 'w', encoding='utf-8') as f:
f.write(str(rounded_similarity))
with open(output_file_path, 'r', encoding='utf-8') as f:
text = f.read()
text = text.strip()
assert float(text) == rounded_simila
读文件函数的部分单元测试
def test_file_context_empty(self):
"""
抄袭版文件内容为空(预期:提示文件为空)
"""
plagiarized_file_path = r"D:\pythonProject\MyProject1\3122004748\examples\orig_empty.txt"
exception_name = main.read_file(plagiarized_file_path)
assert exception_name == "EmptyFile"
预处理函数的部分单元测试
def test_preprocess_normal_text(self):
"""
纯中文文本,中英文混合文本(预期:去除标点符号、分词和拼接)
"""
text = "这是一个测试文本,用于检查预处理函数的效果。"
processed_text = main.preprocess_text(text)
assert processed_text == "这是 一个 测试 文本 用于 检查 预处理 函数 的 效果"
text = "This is a test text. 这是另一个测试文本。"
processed_text = main.preprocess_text(text)
assert processed_text == "This is a test text 这 是 另 一个 测试 文本"
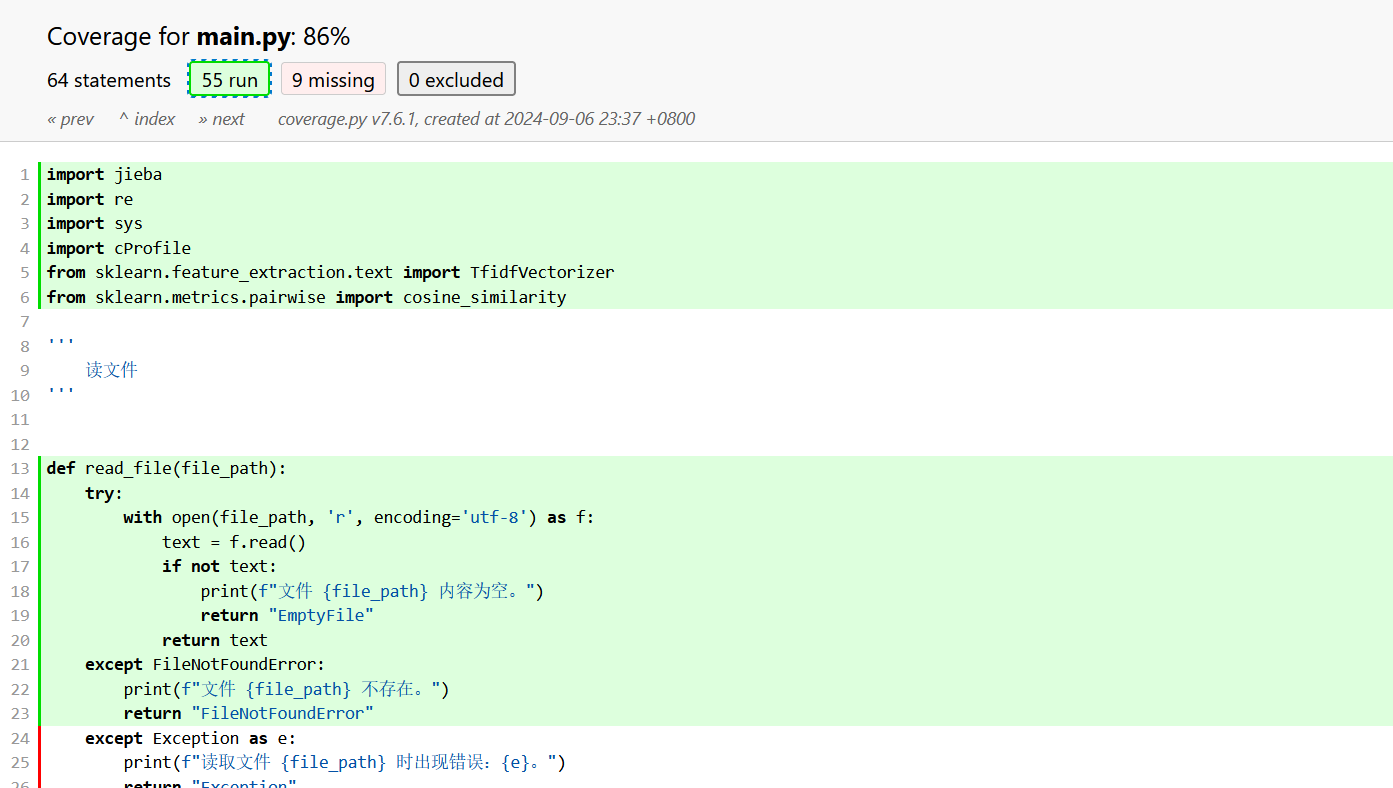
代码覆盖率
6.异常处理
FileNotFoundError
测试代码:
def test_file_path_not_exist(self):
"""
原文文件路径不存在(预期:抛出异常FileNotFoundError,提示文件路径不存在)
"""
original_file_path = r"D:\pythonProject\MyProject1\3122004748\examples\345.txt"
exception_name = main.read_file(original_file_path)
assert exception_name == "FileNotFoundError"
场景:输入的文件路径不存在
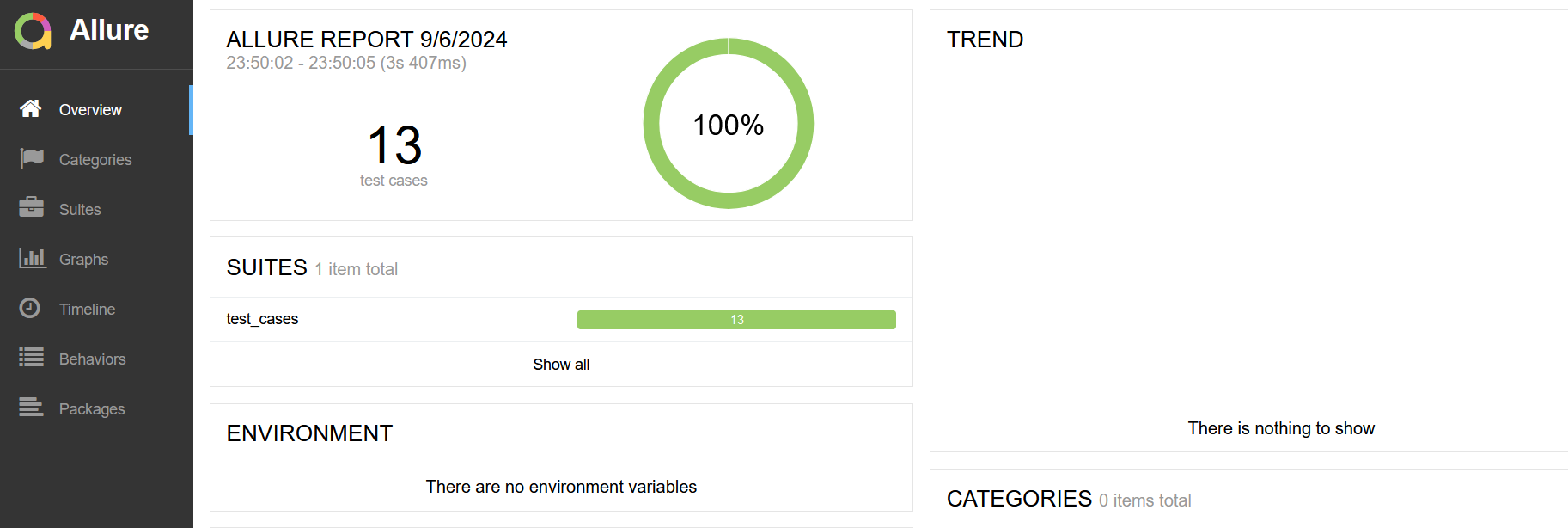
7.测试报告
使用allure自动生成
# 命令行输入
pytest .\test_cases.py --alluredir ./result
# 最后一个路径指定了json文件输出的目录
allure generate ./result -o ./resport_allure --clean
# 从json文件路径中提取数据,输出一个html网页到指定路径
allure open .\resport_allure
# 打开测试报告网页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号